
音楽におけるアノテーションとその応用に関する研究
概要
音楽はただ聴くだけではなく、教育や娯楽など広い分野で利用されている。音楽に対して、様々な観点からの利用に有用な注釈や意味属性などのメタ情報(アノテーション)を付与することができれば、高度な検索や要約などの情報サービスを容易に実現することができ、教育等における音楽利用を大いに促進することができるだろう。
本研究では、音楽に対してアノテーション情報を付与するシステムとしてMiXA (MusicXML Annotator)を実装した。このシステムは、楽曲情報をXMLで表現するMusicXMLを使用し、Webブラウザに楽譜を表示する。ユーザは楽譜に現れる音符や発想記号などの任意のオブジェクトに対してアノテーションを付与することができる。付与できるアノテーションの形式は、実現したいアプリケーションに応じて定義することが可能である。本システムを用いて多くのユーザからアノテーションを容易に収集することが可能となる。
また、本システムの評価実験を行い有効性を確認した。
本システムによって収集されたキーワードやコード進行などのアノテーションを用いて音楽コンテンツを検索するシステムと、曲の構成に関するアノテーションに基づいて曲を再構成するシステムを実装した。音楽検索システムは、キーワード検索に加え、コード進行による検索や曲の構成による絞り込み検索が可能である。音楽再構成システムは、曲の構成のアノテーションを利用し、ユーザが要求する構成に容易に変換することができるシステムである。
1 はじめに
1.1 デジタルコンテンツに対するアノテーション
近年、Web上に氾濫するWebページやマルチメディアコンテンツを、ただ見るだけでなく、高度に有効利用したいという欲求が高まってきた。そのため、現在それらのコンテンツに対してメタ的な情報を関連付けるアノテーションの研究が進められている。
その例としては、次世代のWebの形として提案されたSemantic Webの研究が挙げられる。元となるWeb上のコンテンツと、それに関連付けられた様々なメタ情報により、従来のWebでは実現が困難と思われる高度な検索を可能にするものである。
またWebにおけるアノテーションの研究には、他にセマンティック・トランスコーディングがある。コンテンツとあらかじめそのコンテンツに対して関連付けられた文章の係り受け構造などのメタ情報を用いて、ユーザの特性や環境に合わせ、要約、翻訳、音声での読み上げなどを行う高度なコンテンツを動的に作り出すというものである。
このように、コンテンツを検索、変換する際に有利になるようなメタ情報を関連付けておけば、ユーザの要求に対して動的にコンテンツを作成することが可能となり、Web の利用をさらに高度にすることができる。
マルチメディアコンテンツに対するアノテーション研究の例としては、MPEG-7が挙げられる。ビデオコンテンツには、符号化の形式やシーンの内容、映し出されているオブジェクトが何であるかなど、非常に多くのメタ情報を潜在的に含んでいる。MPEG-7により、ビデオコンテンツに潜在するこれらのメタ情報を記述する形式が定められている。ビデオコンテンツに十分なメタ情報が関連付けられていれば、例えば、誰々が何々をしているビデオはないか、といった検索や、コンピュータが自動で解析することが困難なオブジェクトやシーンの解析を容易に実現することができる。
1.2 デジタルコンテンツとしての音楽の記述形式
音楽もまた、インターネットで頻繁に流通しているデジタルコンテンツの一つである。デジタルコンテンツとしての音楽はテキストやビデオなどよりも多くの記述形式が存在する。
MP3は映像データ圧縮方式のMPEG-1で利用される音声圧縮方式の一つであり、オーディオCD並の音質を保ったままデータ量を約1/11に圧縮することができる。しかし、MP3は音声圧縮の形式であるため、楽曲としての情報、例えば、楽器の種類やメロディーなどは構造化されていない。
またMIDIはシンセサイザや音源とパソコンを接続して楽曲データをやりとりするための規格である。従来、楽曲の構造を解析し、変換するといった多くの研究には、MIDIが採用されてきた。しかし、MIDIは複雑な記述形式のため、構造解析や変換を容易に行うことはできない。また、MIDIは主に曲を演奏するための情報を記述するための形式であるため、音楽の代表的な表現形式である楽譜を生成するための十分な情報を含んではいない。
そこで、よりデジタルコンテンツとしての音楽を容易に扱える形式として、MusicXMLやWEDELMUSICといった、楽曲をXMLで記述する形式が提案された。XMLはJavaなどの多くのプログラミング言語で容易に解析することができ、要素の挿入や削除などといった変換も容易に行うことができるというメリットがある。さらに、これらの形式は、MIDIなどの従来使われてきた形式にも変換することができる。しかし、やはりMIDIと同様に、音楽を柔軟に扱うための情報がすべて含まれているわけではない。
1.3 音楽へのアノテーション
音楽はただ聴くだけではなく、娯楽、教育など非常に広い分野で利用されている。そして、その利用法も、BGMとして利用したり、カラオケで歌うために伴奏だけで流したり、などのように多様である。このように音楽は、他のマルチメディアコンテンツに比べて非常に利用頻度、利用形態の多いのが特徴であるが、音楽は他に、絵画や彫刻などと同様に芸術作品としての一面を持つ。芸術作品は教育的に大きな意味を持っており、それらを高度に利用するための研究には高い意義があると考える。検索、分類、引用、要約などといった高度な利用を実現するためには、オリジナルのコンテンツが持つ情報だけでは不十分な場合が多いが、図のように不足している情報をアノテーションとして補うことができれば、オリジナルのコンテンツとアノテーションにより高度な利用を実現することができる。
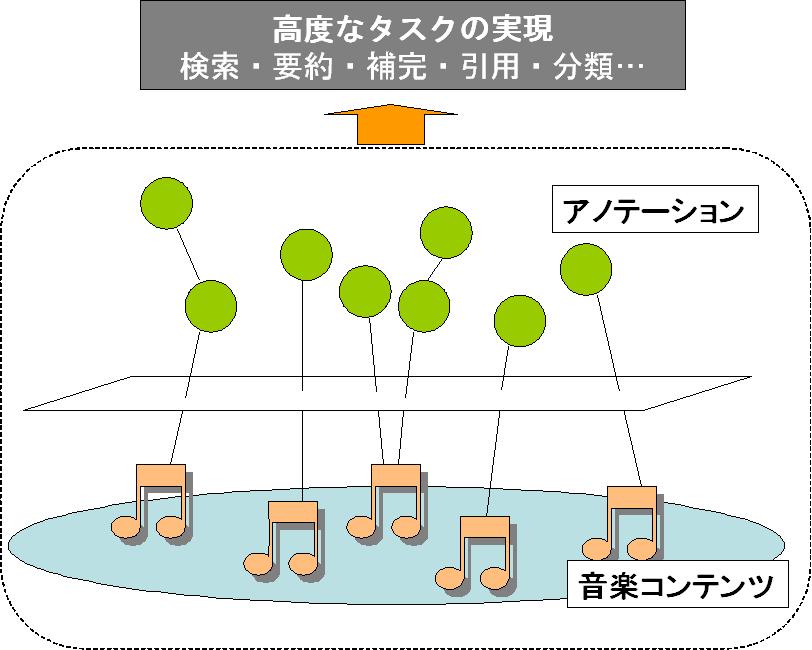
図1.1: 音楽コンテンツとそのアノテーション
また、作品を制作する側としては、芸術作品を間違った意図で捕らえられることを避けるために、正しい情報を見る側、聞く側に伝えたいと考える場合があるだろう。そのような時にも、アノテーションとして、作品に自分の意図している正しい解釈の情報を付与することができれば、その作品を曲解されることを避けることができる。
また、複数のユーザがその作品に対して、感想などの情報をアノテーションとして関連付けることができれば、その楽曲に対するユーザの反応を知ることができ、よりよい音楽コンテンツを提供するモチベーションにつながるだろう。
しかし現在、音楽を含め芸術作品に対するアノテーションの研究はまだ十分に行われていない。
音楽に対してメタ情報を関連付ける研究としては、曲の雰囲気を自動で認識して検索に役立てる研究などが挙げられる。この研究は、曲の音やリズムの情報などを解析し、曲の印象というメタ情報を自動的に生成するというものである。しかしクラシックやポップスなど、曲にある程度の長さがある場合は、ひとつの曲の中に、例えば楽しい曲調の部分があったり、悲しげなメロディーの部分もあったりといったように、認識する箇所によって印象が異なる場合が多い。つまり、この研究のように曲全体のに対する印象のほかに、それぞれのパートごとに印象の情報が関連付けられていれば、より詳細な情報を用いた検索などが実現できるだろう。
このようにタイトルや作詞、作曲者名のような情報は、音楽コンテンツそのものに対する情報であるが、曲の印象の情報に限らず、曲を構成する部分要素に対して関連付けたいメタ情報が多く存在する。そのため音楽コンテンツに対するアノテーションは、曲全体に対するメタ情報を関連付けるだけでは不十分であり、曲を構成する要素、または要素の集合に対してもメタ情報を関連付けることができなくてはならない。
1.4 アノテーションシステムが備えるべき機能
現在のデジタルコンテンツに対するアノテーションシステムにはいくつかの問題点がある。
まず、実現したい利用法によって、どのようなアノテーションを付与する必要があるかが変わってくるため、単に雑多な情報を集めてしまうだけのシステムでは、収集されたアノテーションを二次利用する際に、有効に扱うことができない。つまり、アノテーションシステムを構築する際には、そのシステムで付与されるアノテーションを使ってどのようなことを実現したいのかが明確であり、そのためには元のコンテンツにどのような情報が足りないのかをあらかじめ明らかにしておく必要がある。
また、コンテンツにメタ情報を付与することを考える際には、拡張性を重視するべきである。もしアノテーションによって、全てのタスクに十分なあらゆる情報を記述することが可能であれば、あらかじめ元のコンテンツの記述形式を拡張し、初めからそれらの情報を含む形式にしてしまえばよく、アノテーションの必要性が乏しくなる。しかし現実には、テキスト、ビデオ、絵画など、どのコンテンツも、オリジナルのコンテンツに任意のタスクに十分な情報を記述することは不可能である。アノテーションに関しても同様であり、コンテンツに対する単独のアノテーションが、必ずしも二次利用に有効な形式となることができない場合がある。そのような場合を考慮し、アノテーションシステムは、コンテンツに付与されたアノテーションに対して、さらにアノテーションを記述することができることが望ましい。こうして階層化されたコンテンツとアノテーションを用いることで、より容易に様々なアプリケーションを実現することができる。
アノテーションをどのような人が付与するかについても、考慮が必要である。少人数の専門家がアノテーションの作業をするのであれば、スタンドアロンのシステムでも問題ないが、多くの人から幅広く集めたいメタ情報があるならば、ネットワーク性を重視しつつ、アノテーションを行うまでの手続きをできるだけ簡略化する必要がある。ネットワーク上で容易にアノテーションの作業を行う際には、Webブラウザベースでシステムを構築すると、プログラムのインストール作業の必要も無く、ブラウザで特定のページに移動するだけでシステムが利用できる。さらに、Webブラウザであれば、サーバの構築も容易であり、クライアントであるWebブラウザからスムーズにメタ情報を収集することができる。
また、アノテーションを行う対象であるコンテンツをどのような形式でユーザに提示し、何に対して情報を関連付けるのかを考慮する必要がある。ビデオコンテンツに対するアノテーションの場合、ユーザがビデオを見ている最中にアノテーションをする方法や、あらかじめシーン解析を行ったうえで、そのシーンに対してアノテーションしていく方法などが存在する。音楽に対するアノテーションシステムを考えた場合、曲を聴いている最中に情報を付与するを行うという時間軸に依存した手法や、楽譜に対してアノテーションを行う手法などがある。どのような情報を収集したいか、また対象とするユーザによって、提示するコンテンツの形式を決定する必要がある。
1.5 本論文の構成
本研究は、音楽に対するアノテーションシステムを構築すること、またそのアノテーションを用いた応用システムを実装することを目的とした。本論文では、2章において、本研究で実装したシステムMiXAについて、3章と4章ではそれぞれMiXAを用いて収集されたアノテーションを基にした検索と再構成のシステムについて述べる。5章ではMiXAの評価実験の結果と、それに対して行った考察について述べ、6章と7章でそれぞれ本研究のまとめと今後の課題について述べる。
2 音楽アノテーションシステムMiXA
音楽コンテンツの検索、再構成、要約といった高度利用を実現するためには、オリジナルのコンテンツの情報だけでは不十分な場合がある。そういった不足している情報をアノテーションとして付与していくことが必要となる。
そこで本研究では、音楽に対しアノテーションを付与するシステムとしてMiXA (MusicXML Annotator)(ミキサと発音する)を実装した。以下で、本システムが備える機能とその実装を述べ、全体のシステム構成を説明する。
2.1 XMLベースのシステム
XMLは複数のプログラミング言語でで容易に解析することができ、要素の挿入や削除などといった変換も容易に行うことができる。また、XMLの検索言語であるXPathを利用することができ、コンテンツの特定の部分を指し示すことができる。そのため、アノテーションが関連付けられた音楽コンテンツの要素に容易にたどり着くことができる。このように、XML形式には様々なメリットがある。
まず音楽コンテンツの記述形式として、MusicXMLを採用した。MusicXMLは図のように、楽譜を形成するために十分な情報を記述できる。しかし、本研究で実現しようとしている検索や再構成システムを実装する際には、曲の印象や解説などの様々な情報が不足している。本システムは、MusicXMLに対して不足しているアノテーションを付与するシステムである。
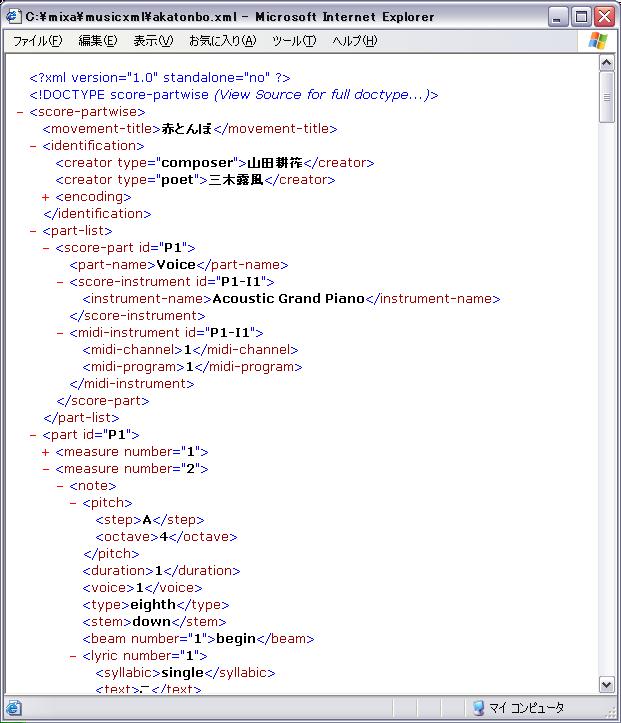
図2.1: MusicXMLの一部
また、MusicXMLに対するアノテーションの情報もXML形式とした。アノテーションの内容を記述したXMLには、どの音楽コンテンツの、どの要素集合に対して、どのような内容の情報が付与されているかが記述される。以後、MusicXMLに対するアノテーションドキュメントをアノテーションXMLと呼ぶ。
アノテーションXMLの具体的な例は、付録A-1にある。以下にアノテーションXMLの一部を抜き出して説明する。
<description
id="description(kaji,/score-partwise/identification/creator[1]|
/score-partwise/identification/creator[2])" x="428" y="83">
<source>
<group>
<object>/score-partwise/identification/creator[1]</object>
<object>/score-partwise/identification/creator[2]</object>
</group>
</source>
<information dataType="string">
<string>このコンビで春が来た、おぼろ月夜、紅葉など有名な童謡を数多く発表しています</string>
</information>
</description>
このXMLの一部は、曲の解説に関するアノテーションの情報を表している。アノテーションが関連付けられている先の要素は、sourceタグ内に、XPath として記述されている。上記のXMLの場合は、MusicXMLに記述されている作詞者、作曲者に対するアノテーションであることがわかる。また、アノテーションの内容はinformationタグ内に記述されている。dataType属性により解説の情報が、文字列型として記述されている。また、和音を表すコード型のアノテーションの場合、informationタグ内は次のように記述される。
<information dataType="chord">
<chord>
<root>
<step>A</step>
<alter>1</alter>
</root>
<suffix>m7</suffix>
<base>
<step>D</step>
<alter>1</alter>
</base>
</chord>
</information>
コードには、root、suffix、baseという複数の情報が同時に含まれている。そのため、アノテーションの記述形式もこのように構造化して表現する必要がある。
rootは、そのコードを構成する元となる和音でありさらにstepとalterという二つの情報から構成される。stepは音高を表す、A、B、C、D、E、F、Gのどれかの値をとる。また、alterはシャープやフラットといった情報を記述するためのもので、シャープの場合は1、フラットの場合は-1の値を取る。
suffixは、m(マイナー)やsus4(サスペンデッドフォース)、maj7(メジャーセブンス)といった接尾辞を記述するタグである。
baseは、和音が展開形になった場合のベースとなる音を表す。rootと同じく、step、alterから形成される。
上記の例では、A\#m7/D\#というコードの情報が表現されている。
本システムでは、このように文字列型やコード型といった複数のデータ型のアノテーションを作成することが可能である。データ型については、アノテーション定義XMLの節において詳しく述べる。
本システムではアノテーションの内容を、音楽コンテンツであるMusicXMLに直接書き込むということはしない。多くの人が一つのコンテンツに対するメタ情報を作成することを考えると、MusicXMLに直接メタ情報を書き込んでしまうということは、その曲を作成していない人がコンテンツを改変することになってしまう。また、様々なメタ情報が付与されたMusicXMLは、独自に拡張された仕様となってしまい、別のアプリケーションでそのMusicXMLを利用することができなくなってしまう。
以上の理由から、メタ情報を音楽コンテンツの内部に埋め込むということはせず、別のXMLドキュメントとして保存する。また、後述するマルチユーザによるアノテーションを可能にするために、各音楽コンテンツ対して、ユーザごとに個別に保存する。
2.2 アノテーション定義XML
高度なサービスを実現するためのメタ情報は、それぞれのサービスに応じて、最適な内容や構造が異なる。そこで、実現したいサービスに応じて、柔軟に収集するアノテーションの形式を定義することができる仕組みを実装した。
XMLドキュメントに、どの要素に対して、どのような形式のアノテーションを関連付けを許すかといった定義を記述することで、システムはXMLに記述されている情報を解析し、その記述どおりの形式のアノテーションを収集する。以降、このXMLドキュメントをアノテーション定義XMLと呼ぶ。
実際のアノテーション定義XMLの例は付録A-2に記述されている。このXMLは、実現したいサービスとして、高度な検索、再構成のシステムを想定して記述したものである。以下にアノテーション定義XMLの一部を挙げ、説明する。
<annotation id="part" type="reference">
<dataType>string</dataType>
<expression color="#F0D044">構成</expression>
<select>
<item expression="イントロ" name="intro"/>
<item expression="サビ" name="chorus"/>
<item expression="間奏" name="bridge"/>
<item expression="エンディング" name="ending"/>
<item expression="Aメロ" name="verse-a"/>
<item expression="Bメロ" name="verse-b"/>
<item expression="Cメロ" name="verse-c"/>
</select>
<group>
<item>
<object minOccurs="0" maxOccurs="unbounded">note</object>
<object minOccurs="0" maxOccurs="unbounded">rest</object>
<object minOccurs="0" maxOccurs="unbounded">lyric</object>
</item>
</group>
</annotation>
上記のXMLは、曲の構成に関するアノテーションの定義を記述したものである。
まず、アノテーションタイプとして、リファレンスとリレーションのどちらであるかがannotationタグのtype属性として記述されている。リファレンスは、ある要素、または要素集合に対するプロパティを記述することができる。一方リレーションは、複数のある要素、または要素集合に関して、その要素間の関係を記述するものである。
dataTypeタグではアノテーションのデータ型として以下の4種類のどれかを指定する。
- string(文字列型)
- numeric(数字型)
- boolean(真偽型)
- chord(コード型)
データ型とは、作成されるアノテーションの内容である。コード型は、音楽における和音を記述するための型である。MusicXMLには、現在それぞれの音符に対してコードを記述することができないが、コードは音楽を扱う際に頻繁に使用される情報であるため、本システムではコードをデータ型の一つとして実装した。
アノテーションとして作成することのできる内容を選択式にしたい場合には、selectタグ内に選択することのできるアノテーションを記述することができる。selectタグの存在は任意であり、無くてもかまわない。
本システムでは、楽譜上にそれぞれのユーザが作成したアノテーションの情報を重ね合わせて表示する。これらのオブジェクトのことを、以降アノテーションオブジェクトと呼ぶ。楽譜に表示する際のアノテーションオブジェクトの色、説明はexpressionタグに記述される。
どの要素に対してアノテーションを行うことができるかを記述したのがgroupタグである。
例えば、以下のようにgroupが記述されていた場合、そのアノテーションは、音符、休符、歌詞を同時に複数含む要素集合に対して関連付けることができる。
<group>
<item>
<object minOccurs="0" maxOccurs="unbounded">note</object>
<object minOccurs="0" maxOccurs="unbounded">rest</object>
<object minOccurs="0" maxOccurs="unbounded">lyric</object>
</item>
</group>
アノテーションタイプがリレーションの場合は、groupが複数記述することができ、その複数のgroup間の関係のアノテーションを関連付けることができる。
アノテーション定義XMLの詳しい記述形式は、付録A-3にある、アノテーション定義XMLの書式を定義するXML Schemaに記述されている。アノテーションを収集しようとするサービス提供者は、このスキーマに従ってアノテーション定義XMLを記述する。
2.3 Webブラウザを通したアノテーション
本システムではメタ情報を幅広いユーザから集め、その情報を様々に応用していくことを目的としている。しかしアノテーションシステムがスタンドアロンのシステムであった場合、ソフトウェアのインストール作業やサーバへの接続作業などに手間がかかるためユーザがそのシステムを利用する際の足かせとなり、結果多くの情報を集めることが困難である。
そこで、ネットワークにつながっている人なら煩雑な手続き無しでアノテーションが行えるように、Webブラウザベースシステムの形態をとった。Webブラウザを利用すると、サーバ側のシステムを容易に構築できるという利点もある。
多人数のユーザを対象とする場合、アノテーションの信頼性を考慮する必要がある。そのため前準備として、ユーザはあらかじめユーザ登録を行い、本システムを利用する際にはベーシック認証を通してログインする。誰がどのアノテーションを作成したかを全て保持するためである。付録A-4は、ユーザ登録により作成される個人プロファイルのXMLの例である。
このようにアノテータを特定する機能を持っているという事実により、間違った情報の書き込みが減り、アノテーションの信頼度を高めることができる。
2.4 楽譜に対するアノテーション
楽曲の各要素(タイトル、歌詞、音符、休符など)に対してアノテーションを行えるように、またユーザが、メタ情報を関連付ける部分を直感的に分かるようにするため、ユーザに提示する楽曲の形態は楽譜にした。楽曲の任意の部分にアノテーションができるようになれば、この部分はこのような意味がありますといったような解説や、この曲のこの部分が気に入っているという感想、この部分はこのように弾きましょうといったような演奏支援の情報などをアノテーションとして関連付けることができる。これらの情報は、高度な検索や音楽教育などの実現を助けるだろう。
前述のように、ブラウザから本システムを利用できるようにするため、ブラウザに表示することができる形式の楽譜にする必要がある。そこで、本システムでは、楽譜の表示形式として、XMLベースの2Dベクター画像記述言語であるSVG (Scalable Vector Graphics)を利用した。SVGにより、図のように楽譜をブラウザで表示することができ、さらに楽譜中に現れる音符などの要素に対するオペレーションに関しても、Webページに動きや対話性を付加することができるスクリプト言語であるJavaScript により記述することができるため、楽譜に対するアノテーションを実現することができる。
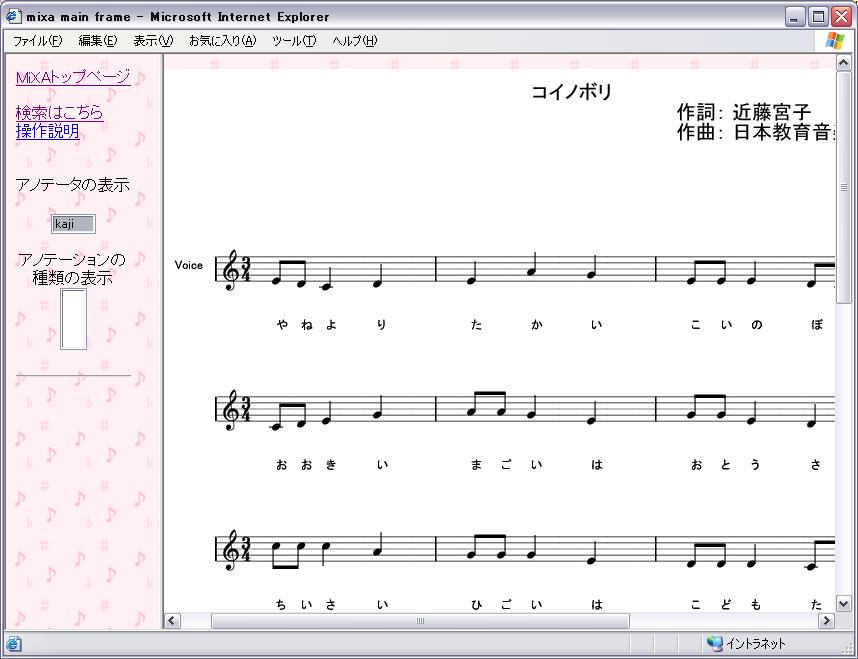
図2.2: ブラウザに表示される楽譜
ユーザに提示される楽譜には、その音楽コンテンツに関して作成されたアノテーションのオブジェクトも重ねあわせて表示される。
それぞれのアノテーションオブジェクトには、アノテーションの内容に加えて、誰が作成したアノテーションであるか、楽譜に現れるどの要素に対するアノテーションであるかといった情報も記述されている。アノテーションオブジェクトにマウスカーソルを合わせると、図のように、関連付けられている音楽オブジェクトも同時に強調表示し、一目でどの要素に対するアノテーションであるかを知ることができ、同時にそのアノテーションの詳細情報がポップアップで表示される。本システムは、ユーザ本人が作成したアノテーションオブジェクトと、他のアノテータが作成したアノテーションかにより、実行することのできるオペレーションに違いがある。表示される詳細のポップアップの色により、図、のように自分のアノテーションであるか、他人のアノテーションであるかを一目で識別することができる。
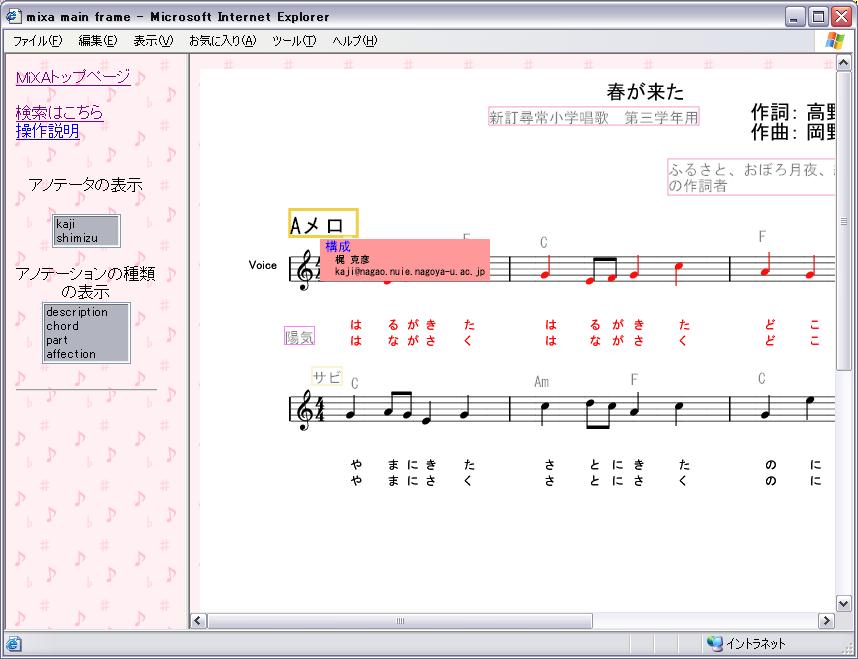
図2.3: 自分のアノテーションオブジェクトの強調
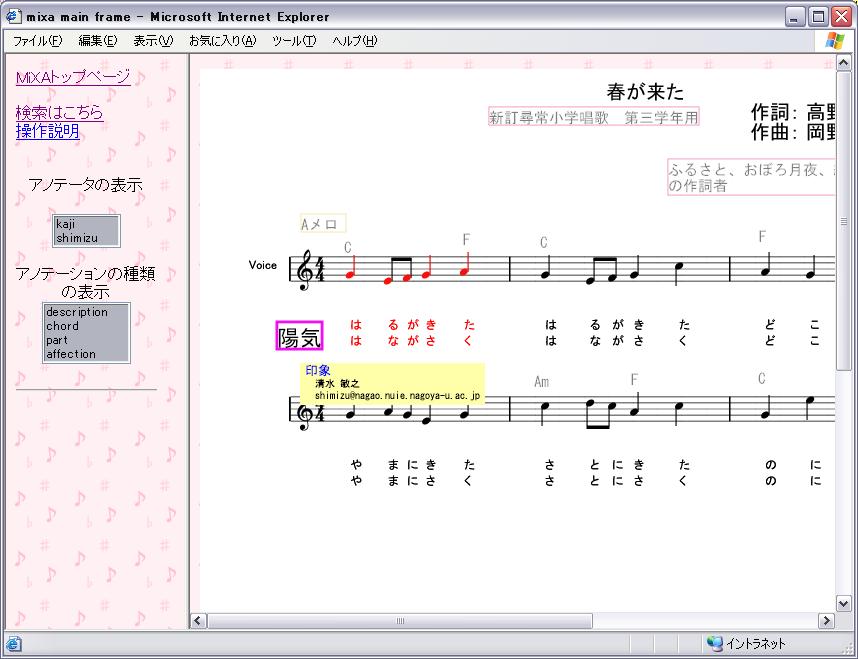
図2.4: 他人のアノテーションオブジェクトを強調
具体的に、どのようにアノテーションを付与するかについて説明する。
アノテーションには大きく分けて、リファレンスとリレーションの二つのタイプがある。リファレンスは、ある要素、または要素の集合に対するプロパティを記述することができる。リレーションは、複数のある要素、または要素集合に関して、その要素間の関係を記述するものである。
リファレンスの場合のアノテーションは以下のように行う。ユーザはブラウザ上に表示された楽譜を見ながら、まず関連付けたい音符や休符、タイトル、発想記号といった要素をマウスの操作により選択する。図は実際に音楽オブジェクトを範囲選択した状態の図である。次に図のようにどの種類のアノテーションを関連付けるかを決定し、その後具体的な情報を記述する。アノテーションの記述方式は、あらかじめアノテーション定義XMLに記述されているアノテーションのデータ型に依存する。
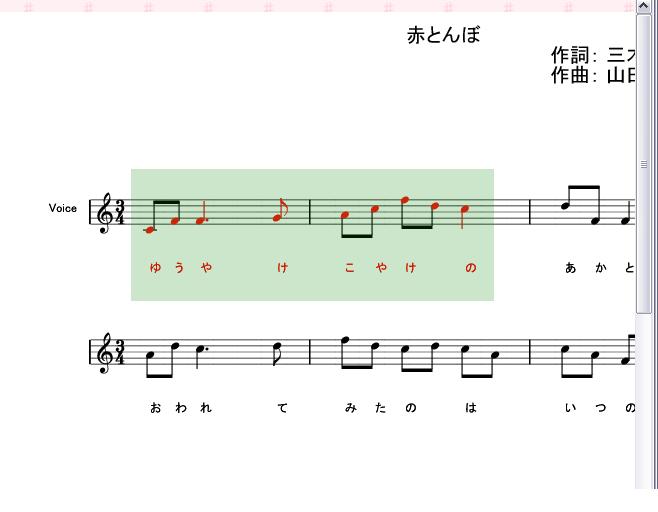
図2.5: 音楽オブジェクトの範囲選択
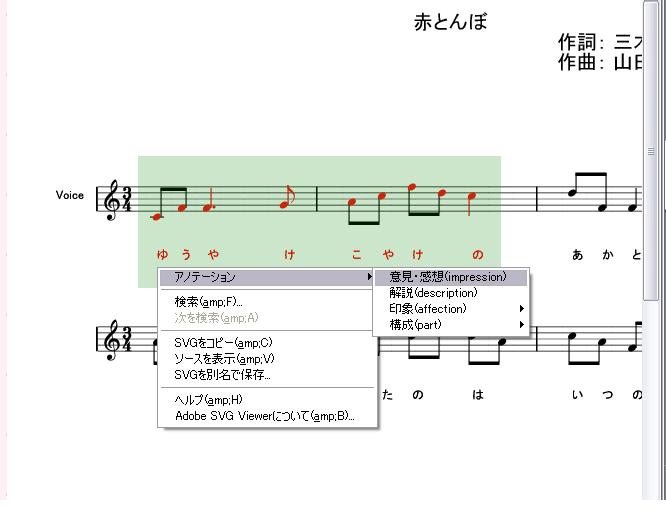
図2.6: 範囲選択したオブジェクトに対するアノテーション
文字列型のアノテーションは、図のようにJavaScriptのプロンプトから記入することができる。また、アノテーション定義XMLには、指定した内容から選択式のアノテーションを行うように記述することができるが、その場合、アノテーションは図のようにメニューからの選択により容易に作成することができる。

図2.7: 文字列型のアノテーション
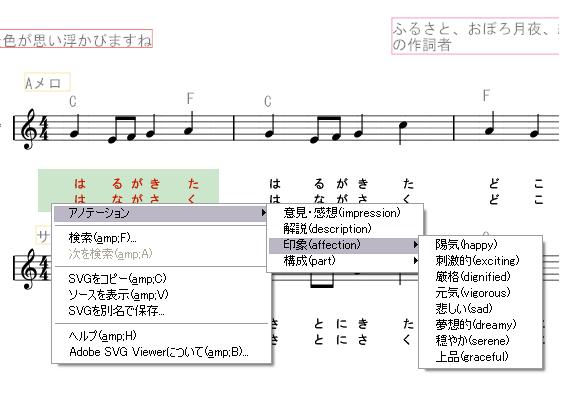
図2.8: 選択式アノテーション
一方、コード型のように複雑な構造を持つデータ型の場合は、図のように、別ウィンドウからアノテーションの内容を記入する。
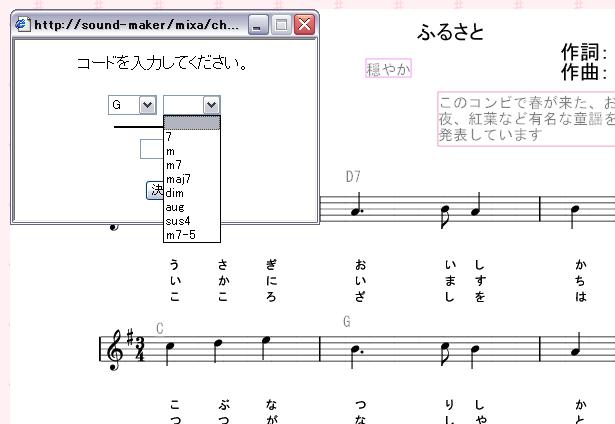
図2.9: コード型のアノテーション
次に、複数の要素間の関係を表すリレーションの場合のアノテーションについての手順を説明する。
リレーションタイプのアノテーションの説明の例として、二つの「解説」のアノテーションオブジェクトに対し、その二つのオブジェクト間の関係を記述する「解説の間の関係」というアノテーションを付与する場合を想定する。
「解説」と「解説の間の関係」のアノテーションは、具体的には次のようにアノテーション定義XMLにおいて定義されている。
<annotation id="description" type="reference">
<dataType>string</dataType>
<expression color="#88F00F">解説</expression>
<group>
<item>
<object minOccurs="0" maxOccurs="unbounded">note</object>
<object minOccurs="0" maxOccurs="unbounded">rest</object>
<object minOccurs="0" maxOccurs="unbounded">lyric</object>
</item>
<item>
<object>title</object>
</item>
<item>
<object minOccurs="0">composer</object>
<object minOccurs="0">poet</object>
</item>
</group>
</annotation>
<annotation id="relationOfDescription" type="relation">
<dataType>string</dataType>
<expression color="#272876">解説の関係</expression>
<group>
<item>
<object annotation="true">description</object>
</item>
</group>
<group>
<item>
<object annotation="true">description</object>
</item>
</group>
</annotation>
「解説」のアノテーションは、音符、休符、歌詞の集合やタイトル、作詞作曲者に対して関連付けることのできる、文字列型のアノテーションとして定義されている。また、「解説の間の関係」のアノテーションは、annotationタグの属性として、アノテーションタイプをrelationで宣言している。また、groupタグが二つあり、それぞれのgroupタグに記述されているdescriptionは、「解説」のアノテーションのIDを示している。そのため、「解説の間の関係」は、「解説」のアノテーションを二つ選択し、その間の関係を記述することのできるアノテーションとして定義される。
まず、図 のようにアノテーションを関連付ける「解説」のアノテーションオブジェクトを順に選択する。
選択された要素は、左側のフレームに表示されている。アノテーションは、楽譜に現れる音楽オブジェクト以外にも、このようにアノテーションオブジェクトに対しても関連付けることができる。アノテーションオブジェクトに対するアノテーションに関しては、アノテーションの階層化の節において詳細に述べる。
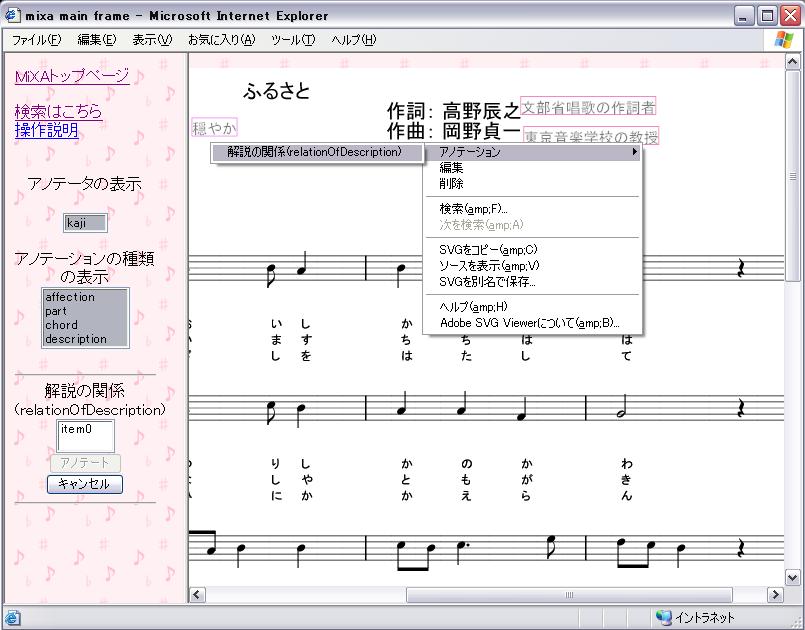
図2.10: リレーションタイプのアノテーション1
リレーションタイプののアノテーションを付与する要素を全て選択し終わったら、図のように左フレームの「アノテーション」ボタンより、アノテーションを付与することができる。アノテーションを記述する方式は、リファレンスタイプのアノテーションの場合と同じく、アノテーションのデータ型に依存する。「解説の間の関係」のアノテーションは、文字列型として定義しているため、図と同様に、アノテーションの内容をプロンプトから記述する。
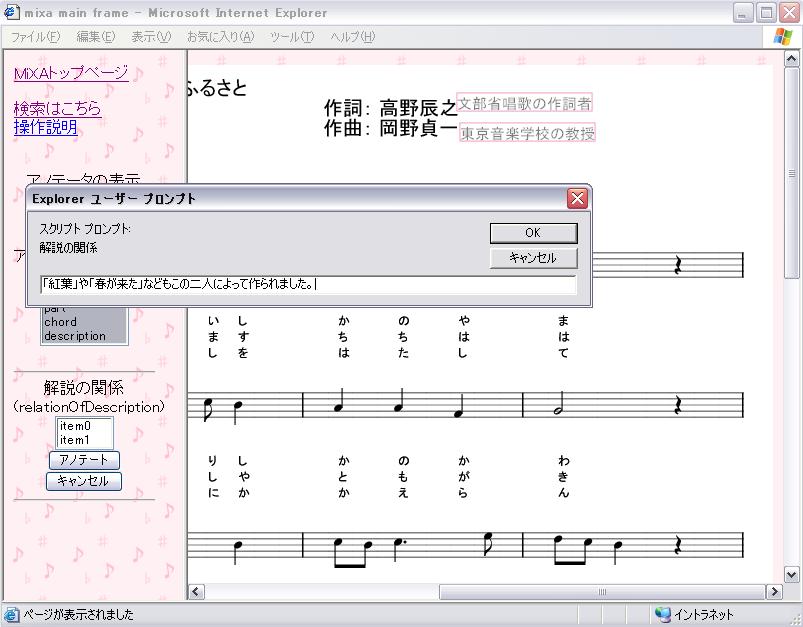
図2.11: リレーションタイプのアノテーション2
リレーションタイプのアノテーションオブジェクトにマウスカーソルを合わせると、図のように、どのオブジェクト間の関係を表しているかを強調表示する。
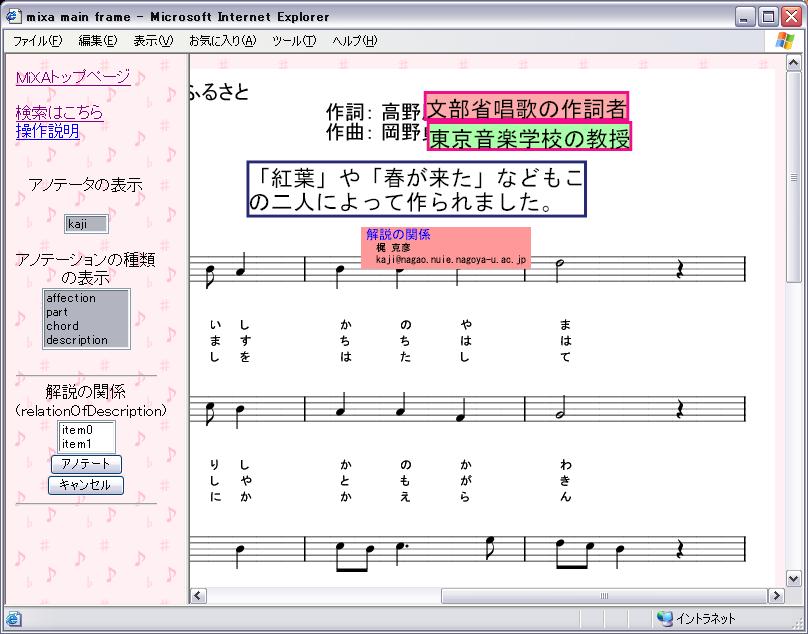
図2.12: リレーションタイプのアノテーションオブジェクトの強調
このように、作成されたアノテーションオブジェクトは楽譜上に表示される。ユーザはアノテーションオブジェクトを作成した後、そのオブジェクトをマウスでドラッグすることにより、楽譜上の見やすい位置へと移動させることができる。
作成したアノテーションを編集、削除したい場合は、該当するアノテーションオブジェクトにマウスカーソルを合わせ、右クリックメニューから実行することができる。編集、削除、移動といったオペレーションは、楽譜に現れる全てのアノテーションオブジェクトに対して行うことができる。
しかし、多くのユーザが同時にアノテーションを行う場合を考慮すると、アノテーションの保存を行う際に、削除、編集、移動といったオペレーションに関しては、自分が作成したアノテーションか、他者が作成したアノテーションかによって保存する内容を区別する必要がある。オペレーションの区別をしない場合、同じオブジェクトを同時に編集した時などに、アノテーションの情報に不整合がおきてしまうからである。そこで、アノテーションを保存する際のポリシーを以下のように決定した。
- 自分が作成したアノテーションオブジェクトは楽譜上の移動や編集、削除した結果をサーバに保存することができる。
- 他人のメタ情報は移動や削除はできるがその変更結果は保存できない。
作成したメタ情報をサーバに保存する場合には、マウスをどのオブジェクトにも合わない状態で、右クリックメニューからアノテーションの保存を選択する。
本システムでは一つの音楽コンテンツに対して複数の人がアノテーションを行い、ユーザが他人の作成したメタ情報を見られるようにするため、他のアノテータが作成したアノテーションオブジェクトも全て楽譜上に表示されている。しかし、楽譜上には様々な情報が混在する状態となり、アノテーションをスムーズに行えなくなってしまう場合がある。
そのような場合を考慮し、本システムはアノテーションのフィルタリングを行うことができるようにした。左側のフレームから、表示したいアノテータのID、アノテーションの種類を選択すると、該当するアノテーションオブジェクト以外のオブジェクトが画面上から無くなり、楽譜や注目すべきアノテーションオブジェクトを見やすくすることができる。
2.5 アノテーションの階層化
アノテーションの情報に拡張性を持たせるために、アノテーションオブジェクトに対してアノテーションを関連付けることができるようにした。このことで、コード進行のように、一つの単純なアノテーションでは記述しきれないような情報でも、階層化したアノテーションの集合により記述することが可能である。
アノテーションオブジェクトに対するアノテーションは、図のように、対象となるアノテーションオブジェクトにマウスカーソルを合わせ、右クリックメニューから、関連付けたいアノテーションを選択する。

図2.13: アノテーションオブジェクトに対するアノテーション
アノテーションオブジェクトに対するアノテーションにより、掲示板のようなユーザ同士によるインタラクションが可能になる。そのため、本システムによりユーザ同士が音楽コンテンツに対して意見を言い合う場としても利用することができる。
アノテーションが多いほど、検索などの応用システムの精度を高めることができるため、本システムは、多くのユーザからアノテーションを広く収集することを目的としている。このように本システムによりユーザ同士の意見交換を行うことができると、より多くのユーザが本システムを利用することになるため、多くのアノテーションを収集することができるようになる。
2.6 システム構成
図は、本システムのシステム構成の概要を示している。この図のように、ユーザはWebブラウザを通して、複数のデータベースを管理するWebサーバとやり取りを行うことによってアノテーションを作成し、共有することができる。詳細は以下の通りである。
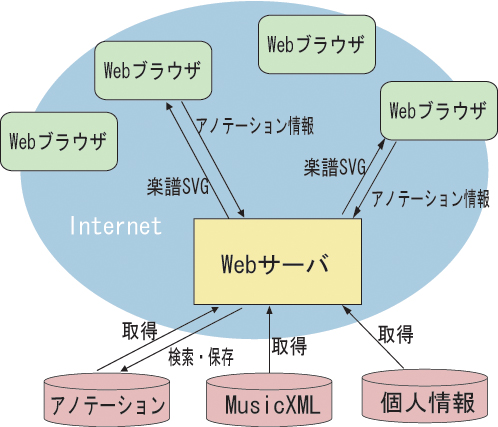
図2.14: MiXAのシステム構成
あらかじめWebサーバ側にXMLデータベース(Xindice)を用意し、そのXMLデータベースに音楽コンテンツであるMusicXMLを保存しておく。また、本システムを利用するユーザのプロファイルを記述した個人プロファイルXMLを、同じくXML データベースに保存しておく。音楽コンテンツに対するアノテーションのXMLドキュメントも音楽コンテンツや個人プロファイルと同様にXMLデータベースに保存されることになる。Webサーバには、Java Servletを使用した。
ユーザはInternet Explorerからユーザ名とパスワードを求めるベーシック認証を通して図の本システムのトップページにアクセスする。登録されている曲の一覧から、または後述する検索システムの検索結果一覧から、アノテーションを作成したい曲を選択すると、Webサーバは要求された曲のMusicXMLをXMLデータベースから取り出す。さらにそのMusicXMLをブラウザで表示することのできるSVG形式の楽譜に変換する。作成された楽譜の各音楽オブジェクトには、元のMusicXML のどの部分を指すオブジェクトであるのかを指し示すXPathが内部的に記述されている。
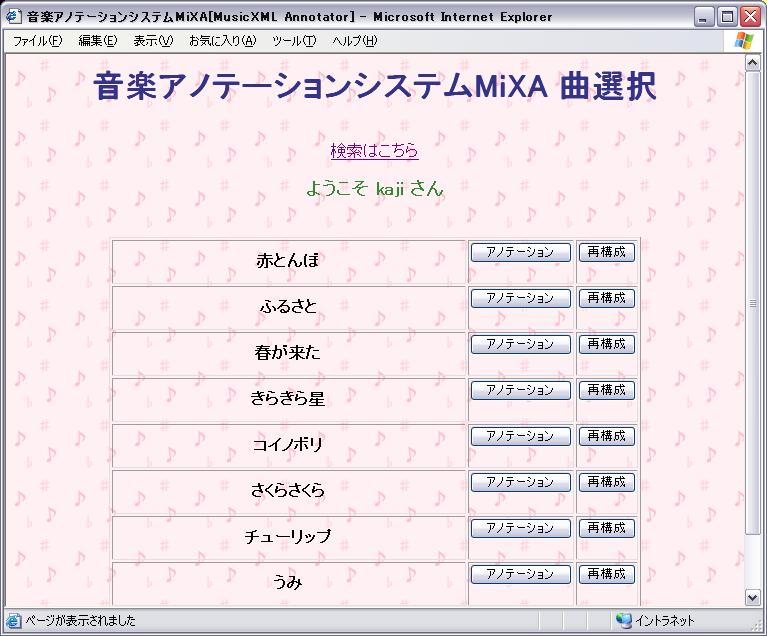
図2.15: MiXA曲選択画面
MusicXMLから楽譜を作成する際、該当する曲に関するアノテーションをXMLデータベースから検索し、アノテーションが検索された場合はそれらの情報をアノテーションオブジェクトとして楽譜に視覚的に重ね合わせてブラウザに表示する。また、それぞれのアノテーションオブジェクトを作成したアノテータの個人情報をXMLデータベースから取得しておく。
ユーザはブラウザに表示されている楽譜上でマウスとキーボードの操作によりアノテーションを行う。
ユーザがアノテーションの保存を選択すると、そのユーザが作成したアノテーションの内容や、楽譜上の座標などをサーバに送信する。サーバは、1ユーザ、1コンテンツにつき一つのXMLドキュメントを作成し、ユーザがその曲に対して作成したすべてのアノテーション情報を記述し、XMLデータベースに保存する。
3 アノテーションの応用システム
MiXAによるアノテーションは、一般には実現が困難と思われる様々な情報サービスの実現を容易にすることができる。各音楽コンテンツに対する多くの詳細なメタ情報を集めることができるので、検索に関しては特に大きく精度の改善を期待することができるだろう。また曲を再構成したり、曲のある部分を別の曲の途中に付け加えたりといった、コンピュータの自動解析だけでは実現が難しい、曲の構造を利用した高度なアプリケーションに関しても、コンテンツに詳細なメタ情報が関連付けられていれば、精度の高い解析結果を利用することができる。
本研究では、アノテーションを用いた応用システムの例として、音楽検索、音楽再構成のシステムを実装した。以下に詳細を述べる。
3.1 音楽検索システム
3.1.1 音楽検索のためのアノテーションの収集
高度な検索システムを実現するための前準備として、MiXAにより意見・感想、解説、印象、コード、曲の構成という四種類のアノテーションを収集することにした。アノテーションXMLには、表のようにそれぞれのアノテーションを定義した。
「意見・感想」は、多くのユーザから、音楽コンテンツの各部分に対して自由に文字列型のコメントを書き込んでもらうためのアノテーションである。ある人の意見に対して、別の人が意見を述べる場合を考慮して、「意見・感想」のアノテーションオブジェクトに対しても「意見・感想」のアノテーションを関連付けることができるようにした。
「解説」は、音楽コンテンツのタイトル、作詞作曲者に対してその曲の説明をしたり、音符や歌詞などに対して、その部分にはどのような意味あるかなどを文字列型として記述することができる。
「印象」は、曲の各部分に対し、ユーザがどのような印象を受けたかを文字列型として記述することができる。印象のアノテーションは、陽気、刺激的、厳格、元気、悲しい、夢想的、穏やか、上品の8種類から選択することができる。印象のアノテーションの選択候補とした8種類の印象語は、Hevnerの印象語群の定義によった。Hevenerは、これら八つの印象語によって、音楽の印象を分類することができると定義した。
「曲の構成」は、ポップスなどに見られるイントロやサビといった、その曲が大まかに見てどのように構成されているかを記述するためのアノテーションである。アノテーションとして付与することのできる情報は文字列型で、イントロ、間奏、エンディング、サビ、Aメロ、Bメロ、Cメロから選択する。
「コード」は、曲の各部分が、どのような和音構成であるかを記述する。コードのデータ型は、あらかじめ本システムで実装したコード型を使用する。コード型には、root、suffix、baseという情報が含まれており、例えばAm/Eというコードの場合、rootがA、suffixがm(マイナー)、baseがEとなる。コードのアノテーションは、音符、休符、歌詞の集合に対して関連付けることができる。
上記の定義でアノテーション定義XMLを記述した。付録A-2は、実際に検索システム実現のためにMiXAに適用したアノテーション定義XMLである。
以上の五つのアノテーションを、MiXAにより音楽コンテンツの各要素に付与する。本研究では、これらのアノテーションを長尾研究室の学生が作成した。ただし、コードなどの専門知識が必要となるアノテーションについては、信頼できる情報を作成するために、知識のあるユーザが作成した。今回はアノテーションの正確さについては厳密に考慮せず、アノテーションの内容はすべて正しい情報であるとみなすことにする。
こうしてMiXAを利用して音楽コンテンツに対するアノテーションを収集することができた。以下に、これらの情報を用いて音楽検索を行うシステムの詳細を述べる。
本検索システムでは、音楽コンテンツであるMusicXMLに記述されている、タイトルや作詞・作曲者の情報に加えて、アノテーションとして音楽コンテンツに関連付けられているメタ情報を用いて、キーワード検索を行うことができる。また、コード進行による検索や、曲の構成による絞り込み検索をすることができる。本検索システムはWebブラウザベースで実装されているため、ユーザはWebブラウザを通して検索を行うことができる。
3.1.2 キーワード検索
キーワード検索の流れを説明する。
まずユーザがタイトル、作詞者、作曲者、意見・感想、解説の情報を図のWebブラウザのフォームから検索の要求を行う。Webサーバはその検索要求を受け取り、以下のようにして該当する音楽コンテンツを検索する。Webサーバには、MiXAと同様Java Servletを利用した。
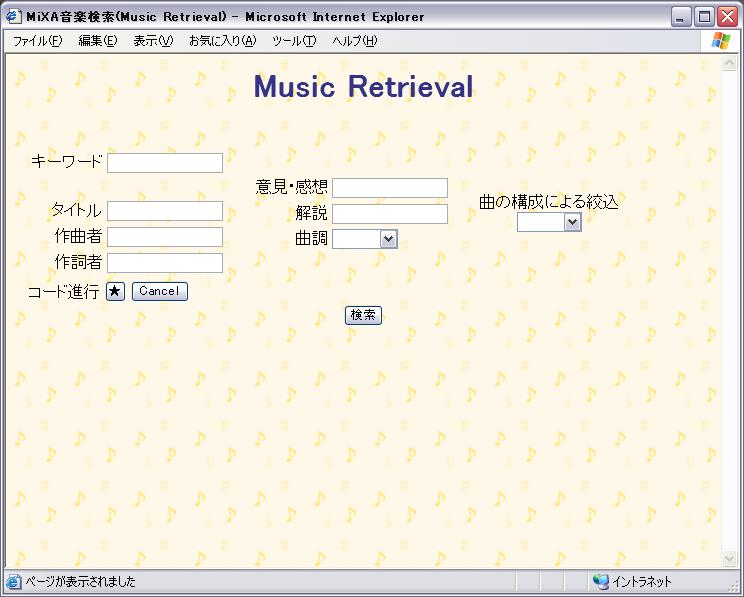
図3.1: 検索フォーム
タイトル、作詞者、作曲者の情報に関しては、MusicXMLに記述されているため、MusicXMLが格納されているXMLデータベースのコレクションである"/db/musicxml"に対して、XPathにより検索を行う。
作曲者が「岡野貞一」である曲を検索する場合は、XPathは以下のようになる。
/score-partwise[identification/creator/@type='岡野貞一']
このようなXPathにより検索すると、XPathに該当する複数のMusicXMLがまとめられたドキュメントを取得することができる。このドキュメントを解析することで、それぞれのMusicXMLのキーを得ることができる。
また、意見・感想、解説、印象の情報に関しては、MusicXMLに関連付けられたアノテーションの情報であるため、XMLデータベースのアノテーションが格納されているコレクションである"/db/musicxml/annotation"に対して検索を行う。
例えば、解説の中に「長野」という文字が含まれている曲を検索する場合、まずアノテーションのコレクションに対して以下のXPathで検索を行う。
/annotations/description[information/string[contains(text(),'長野')]]
この検索要求に対して、該当するいくつかのアノテーションがまとめられたドキュメントが結果として得られる。
次に、そのドキュメントから、一つ一つのアノテーションについて、どのMusicXMLに関連付けられているアノテーションであるかを解析し、関連先のMusicXMLのキーを取得する。
こうしてMusicXMLとアノテーションのコレクションより一つ一つのキーワードについて検索を行い、検索結果として得られたMusicXMLのキーを集める。
同一の音楽コンテンツに対して、同じキーワードが何度も出現する場合があるが、その場合は、MusicXMLのキーが重複されて検出されることになる。このように同じMusicXML のキーが検出された場合は、そのつど検索のランクを累積していく。同じMusicXMLのキーに対する検索対象であるキーワードの出現数を とすると、最終的な検索ランク
は以下のように計算される。
は、検索ランクのベースとなる数値である。
3.1.3 コード進行の検索
本検索システムでは、コード進行による検索を行うことができる。ユーザは検索フォームの「コード進行」のボタンを押して、図のように別ウィンドウから順にコードを入力していき、検索ボタンからWebサーバにコード進行を送信する。
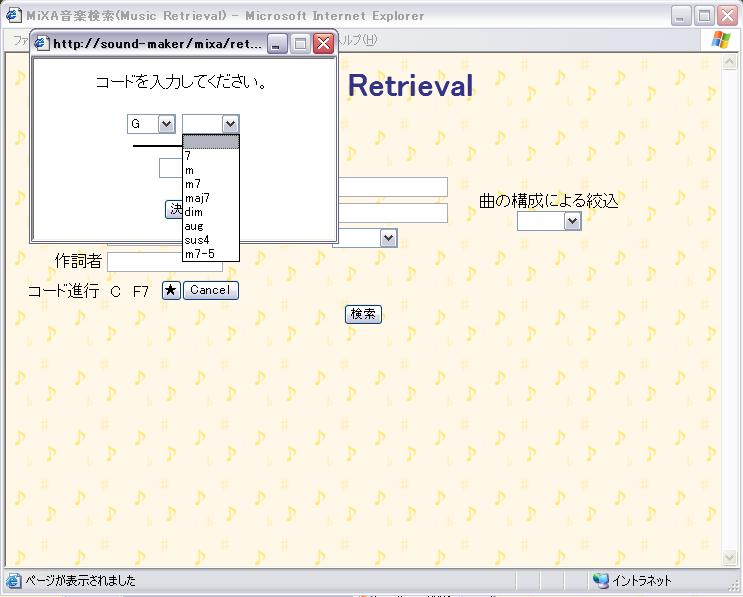
図3.2: 検索要求のコード進行の入力
Webサーバはまず、検索要求であるコード進行から、-6から6までの相対的な音の変化を計算する。例えば「C G/B Dm C」というコード進行の相対的な音の変化は、「0,-5/-1,2m,0」となる。m(マイナー)などのsuffixはそのまま残しておく。
次に、XMLデータベースに保存されている全てのMusicXMLのキーの配列を取得する。
それぞれのキーを用いて、一曲分のコードのアノテーションを取り出す。例えばキーが"kirakirabosi"である曲に関連付けられたコードを取得するためのXPathは次のようになる。
/annotations/chord[../@about='localhost//db/musicxml?key='kirakirabosi']
一曲分のコードアノテーションを取得したら、そのコードを実際に演奏される順にソートする。アノテーションには、MusicXMLのどの部分に関連しているかがわかるように、XPathが埋め込まれているため、その情報を用いてソートすることが可能である。
検索要求のコード進行が含むコードの数と同じ数のコードアノテーションを抜き出し、コードアノテーションを相対的な値に変換する。そして、互いにその値が、サフィックスを含めて全て一致した場合、どれだけ検索要求のコード進行とコードアノテーションとの間にキーのずれがあるのかを調べ、コード進行の類似度を計算する。キーのずれは、検索要求のコード進行の最初のコードと、抜き出したコードアノテーションのはじめのコードとのキーの相違を比べる。例えば
番目のアノテーションのコードがCであり、検索対象のコードがGだった場合、キーが5ずれているので、
は5となる。
の最小値は0で、最大値は6である。
番目のアノテーションのコードと、検索対象のコードとの類似度
は以下の式で表す。
ソート済みのコードアノテーションを一つずつ後ろにずらしながら、上記の検索要求のコード進行との比較をコードのアノテーションの数、回繰り返す。最終的な検索ランクは以下のようになる。
コード進行による検索は、キーワード検索と併用して行うことができる。この際の検索ランクは、キーワード検索で計算されたランクと、コード進行の検索により検索されたランクを足し合わせる。
3.1.4 曲の構成による絞り込み検索
音楽コンテンツに関連付けられている曲の構成に関するアノテーションを用いた絞り込み検索について説明する。
絞り込み検索を行う場合は、検索フォームにおいてサビやイントロなど、絞り込みたい曲の構成を選択し、他にキーワードやコード進行など検索情報を記入し、検索ボタンを押す。
Webサーバは、検索対象となるキーワードやコード進行と、絞り込みを行う曲の構成を受け取る。以下は「サビが悲しい曲」という検索要求を受け取ったとして説明する。この場合、「サビ」が絞り込みを行う曲の構成であり、検索対象は「悲しい」という印象のアノテーションである。
Webサーバはまず、曲の構成の情報を利用せず、上述のキーワード検索とコード進行の検索を行い、それぞれの音楽コンテンツに対して検索ランクを計算する。こうして計算された検索ランクをとする。この例では、「悲しい」という印象のアノテーションを用いてキーワード検索を行う。
同時に、「悲しい」というアノテーションが関連付けられている先の要素を表すXPathを、MusicXMLのキーごとに収集する。
さらに、通常のキーワード検索、コード進行の検索により取得された各MusicXML ごとに、曲の構成である「サビ」に関するアノテーションを収集し、同時に「サビ」のアノテーションが関連付けられている先の要素を示すXPathを収集する。
次に、こうして収集された検索対象が関連付けられている要素のXPathと、絞り込む曲の構成が関連付けられている要素のXPathにより、絞り込む曲の構成、「サビ」の部分に対して、どれだけ検索対象である「悲しい」というアノテーションが含まれているかという、含有率を計算する。
図に当てはめてみると、「サビ」のアノテーションが付与されている音楽オブジェクトは、から
までで、その要素数は
である。また、「悲しい」というアノテーションが付与されている音楽オブジェクトは、
から
までで、その要素数は
である。また、これら二つのアノテーションが共通して付与されているオブジェクトは、
から
までで、その要素数は
である。
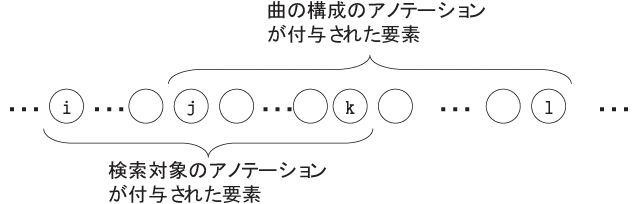
図3.3: 絞り込み検索の際の音楽オブジェクト
この場合、含有率は以下の式で求める。
こうして計算された含有率と、あらかじめ計算された音楽コンテンツの検索ランクと掛け合わせて、新しい検索ランクを算出する。最終的な絞り込み検索の検索ランクは以下の式となる。
3.1.5 検索結果一覧の表示
検索ランクの計算が終了したら、検索結果一覧をユーザに表示する。
検索結果一覧は、図のように検索ランクが高いものから順に表示される。
この検索結果一覧からも、MiXAのアノテーション画面や、後述する再構成システムへ移行することが可能である。
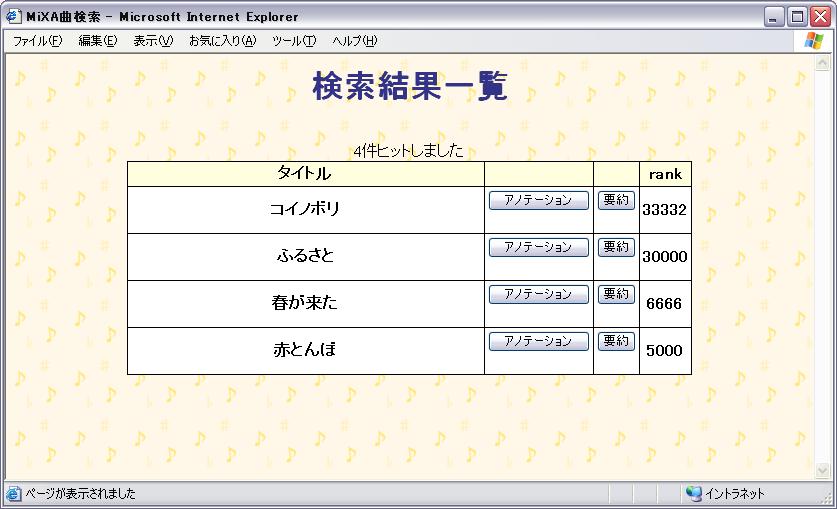
図3.4: 検索結果一覧
3.2 音楽再構成システム
本研究で実装する再構成システムは、MusicXMLが元から持っている情報(歌詞、楽器など)に加え、曲の構成を用いて、聴きたい、楽譜を表示したいという曲の部分を選択することにより、曲を再構成し、ユーザに提示するというシステムである。例えばサビだけ抜き出したい、といった要求や、イントロ-サビ-アウトロというように、曲を縮めてしまいたい、といった要求に応えることができる。
再構成システムを実現するために、曲の構成というのアノテーションが必要となるが、前述の音楽検索システムのため、既に曲の構成のアノテーションが作成されているので、簡単のため、再構成用に新しくアノテーション定義XMLを記述せず、検索用に生成されたアノテーションを利用する。
ユーザはまず、MiXAの楽曲一覧ページや、検索システムの検索結果一覧から、再構成を行いたい曲を選択することで再構成システムにログインする。図はログイン直後の再構成システムの画像である。
本再構成システムは、曲の構成、楽器パート、歌詞による音楽コンテンツの再構成を行うことができる。
左のフレームが再構成システムのメニューとなっている。曲の構成による再構成を行いたい場合は、<パート>の部分にある曲の構成から、表示したい部分を選択する。歌詞の有無を変更したい場合は、<歌詞>の部分のセレクトボックスにチェックを行い、楽器パートを選びたい場合は、<楽器パート>の部分にあるチョイスボックスから、表示したい楽器パートを選択する。選択が終了したら「再構成」のボタンをクリックすると、曲の構成、歌詞の有無、楽器パートの選択を反映させた楽譜が表示される。
また、こうして再構成された音楽コンテンツのMusicXMLをダウンロードすることも可能である。
以下に実装の詳細を述べる。
3.2.1 再構成システムの実装
MusicXMLには歌詞や、何の楽器が使用されているかといった情報が含まれている。そのため、歌詞と楽器パートによる再構成は、元の音楽コンテンツであるMusicXMLのみを利用して実現することができる。
歌詞はMusicXMLでは図のように音符であるnoteタグの内部にlyricタグとして記述されている。
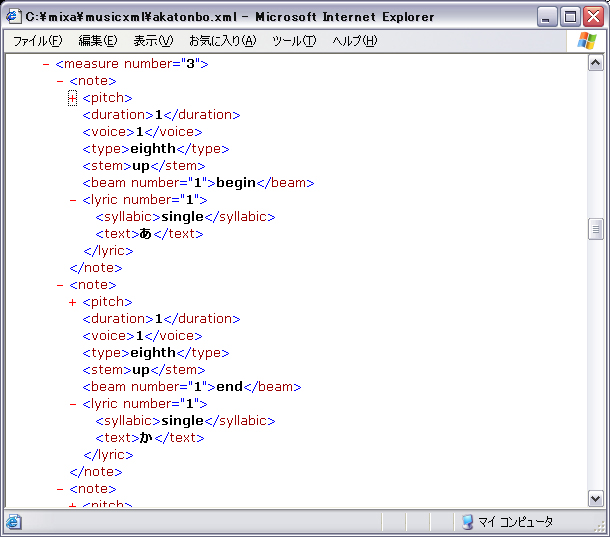
図3.5: MusicXMLにおける歌詞の記述
歌詞の表示をしない場合は、MusicXMLの各lyricタグを、親であるnoteタグ内から削除する。
また楽器パートは、MusicXMLでは図のように、part-listとして定義し、さらにそれぞれの楽器パートについて演奏情報が記述される。楽器パートによる再構成では、P1、P2といった残しておく楽器パートのIDを取得し、MusicXMLのpart-listタグから残しておくID以外のscore-partタグを削除し、さらにpart-list以降に記述されているpartタグも、残しておくIDのもの以外は削除する。
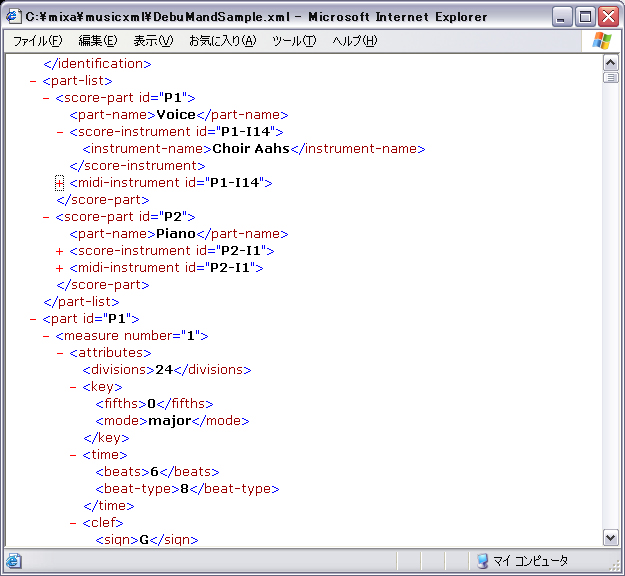
図3.6: MusicXMLにおける楽器パートの記述
曲の構成による再構成は、曲の構成という情報が音楽コンテンツに対するアノテーションを解析する。例えば音楽コンテンツのキーがkirakirabosiであり、「イントロ-サビ-アウトロ」という再構成要求の場合、まずデータベースのアノテーションコレクションから、該当する曲に対する曲の構成のアノテーションを検索する。XPathは以下のようになる。
/annotations[@about='localhost//db/musicxml?key=akatonbo']
/part[information/string='verse-a' or information/string='chorus'
or information/string='outro']
このようなXPathにより、該当する曲のイントロ、サビ、アウトロのアノテーションを取得することができる。それぞれ、MusicXMLのどのオブジェクトに対するアノテーションであるかは付録A-1のように、音楽オブジェクトのXPathが記述されているため、この検索結果を解析し、イントロ、サビ、アウトロのアノテーションが付与されている音楽オブジェクトのXPathをすべて収集する。
収集した音楽オブジェクトに対するXPathにより、MusicXMLの該当部分を抽出し、再構成したMusicXMLを生成する。
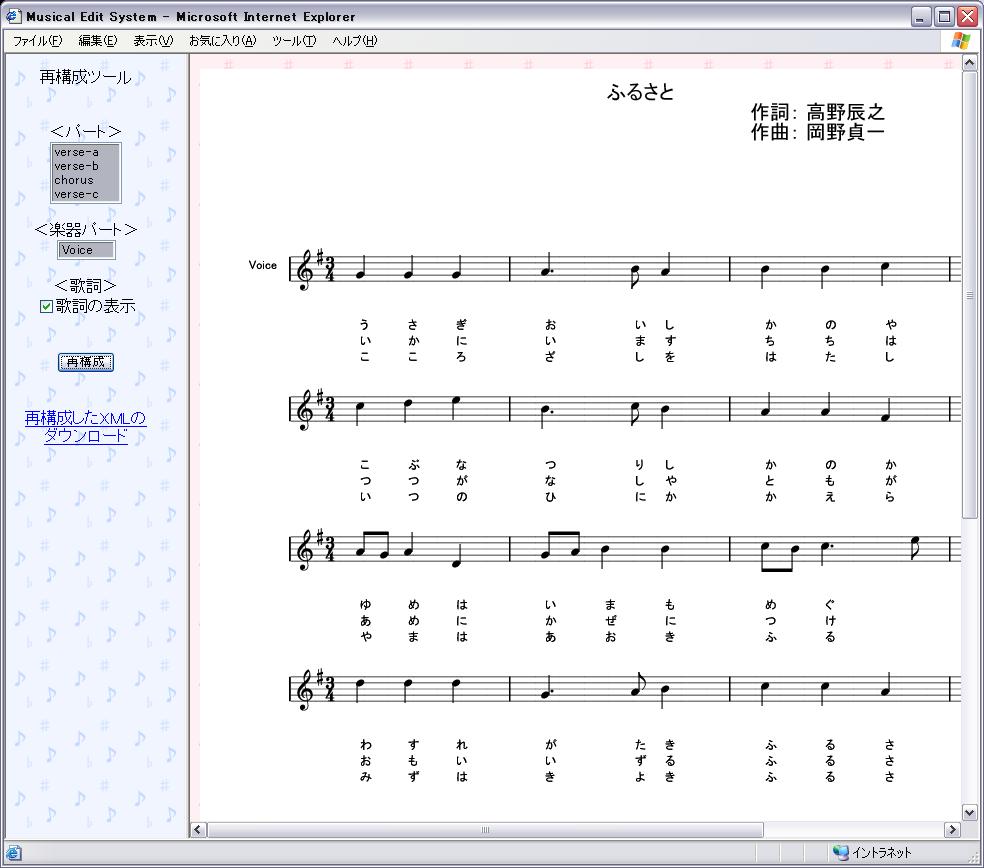
図3.7: 再構成前の画面
3.2.2 再構成したコンテンツの表示
上記のように、歌詞、楽器パート、曲の構成により再構成したMusicXMLが生成される。このMusicXMLからブラウザに表示できる楽譜のSVGを生成しブラウザに表示し、同時に、再構成済みのMusicXMLをファイルとして保存し、ユーザがダウンロードできるようにする。再構成後の画面は図のようになる。
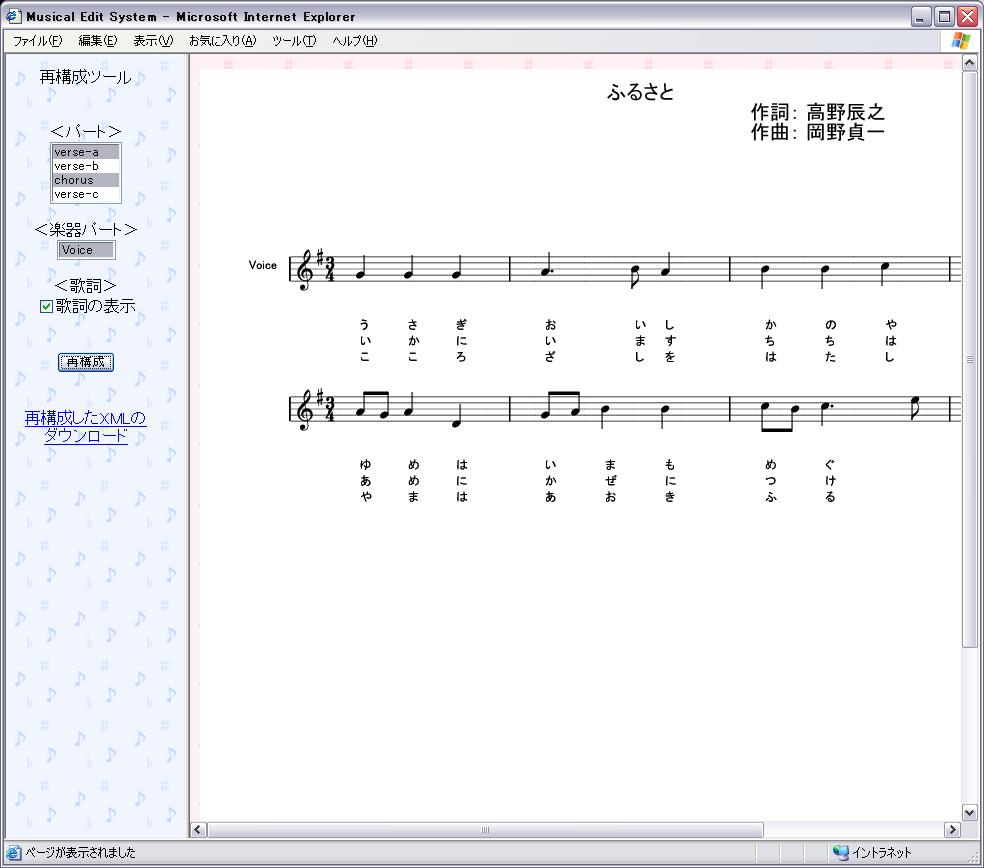
図3.8: 再構成後の画面
4 実験
本システムの評価を行うため、被験者実験を行った。
4.1 実験の目的
今回の評価実験では、本システムを用いてアノテーションを行う際のユーザビリティについて有効性を確認することが目的である。特に、ユーザインタフェースの分かりやすさと、積極的にアノテーションを行いたいかというモチベーションについての評価を行った。
4.2 実験方法
まず10人の被験者にMiXAのマニュアルページを読んでもらい基本的なアノテーションの手順を習得してもらった。その後実際にMiXAにログインして簡単な童謡9曲に対して,主に意見・感想と解説のアノテーションを行ってもらった。被験者が作成したアノテーションの画面例を図に示す。
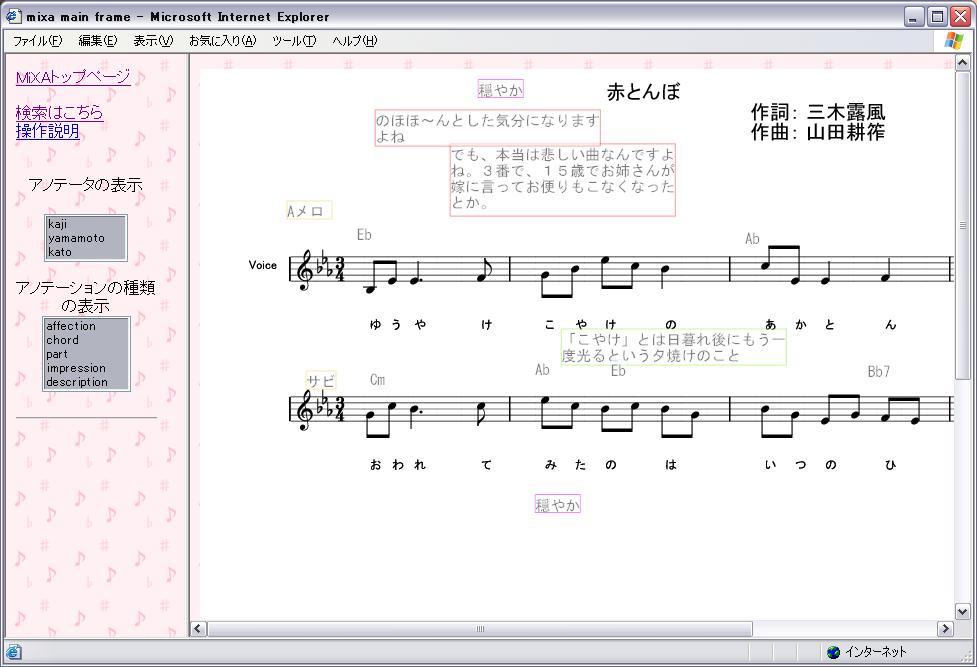
図4.1: 評価実験のアノテーション例
その後、以下の項目について5段階の評価と、各質問に対してコメントを書いてもらった。
- (質問1) アノテーションシステムとしての全体の使いやすさ
- (質問2) 楽譜、アノテーションオブジェクトの表示方法
- (質問3) 自分の思い通りにアノテーションできたか
- (質問4) MiXAを用いてアノテーションをしたいか
4.3 実験結果と考察
被験者実験のアンケート結果をに示す。
質問1に関しては,図のような結果となった。評価の平均が3.7であり、おおむね本システムがアノテーションシステムとして使いやすいものであると言える。しかし、改善するべき点もいくつか存在する。ブラウザベースのシステムのため、アノテーションを行った後、保存作業を行わずに別ページへ移動したり、ブラウザを終了させてしまったりした場合には、サーバ側にアノテーションの内容が送信されない。せっかく作成したアノテーションが消えてしまうという状況になってしまうため、そのような事態にならないように、アノテーションの保存を促す手段を講じる必要がある。
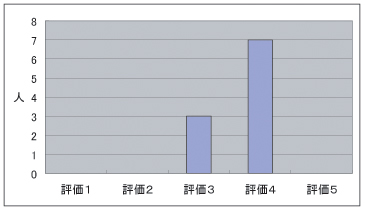
図4.2: アンケート結果(質問1)
質問2は,図のような結果であった。評価の平均は3.6であった。現在の楽譜とアノテーションオブジェクトの表示方法が、十分に適切であるとはいえない結果である。改善するべき点として、まずアノテーションオブジェクトが重複して表示されている状態を回避する必要がある。図のように、アノテーションが多く作成された場合、アノテーションのオブジェクト同士が重なり合ってしまい、非常に表示が見にくくなってしまう。オブジェクト同士が重なり合った場合、お互いのオブジェクトの位置を自動的に移動するなどして、重なりを解消する必要がある。もしくは、楽譜の上に全てのアノテーションオブジェクトを表示するのではなく、アノテーションは楽譜とは別ウィンドウで表示するなどの工夫が必要である。
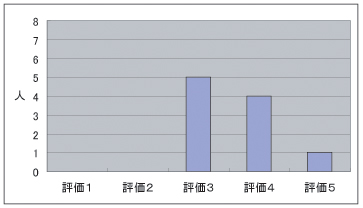
図4.3: アンケート結果(質問2)
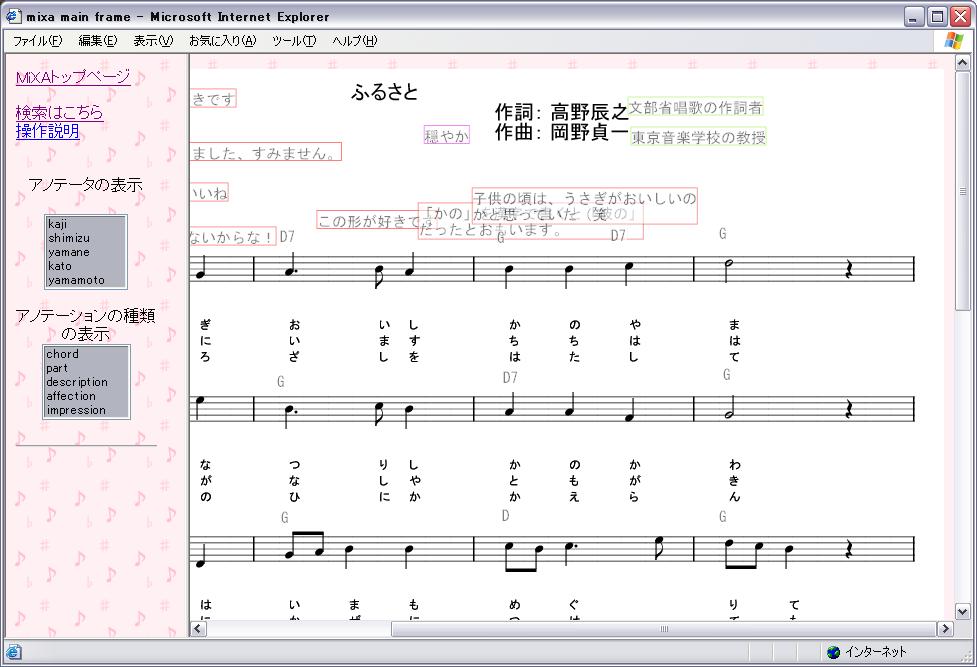
図4.4: 評価実験のアノテーション例
また、アノテーションオブジェクトにマウスカーソルを合わせたときに、関連付けられているオブジェクトを強調表示するが、その上その部分が音符などの音楽要素だった場合、実際に部分的に演奏をすると、よりどの部分に対するアノテーションであるのかが直感的に分かるであろう。
質問3は,図のような結果であった。評価の平均が3.2であった。低い評価になった理由としては、ユーザが付与したいと考えるアノテーションが含まれていなかったことが挙げられる。ユーザ同士で感想を述べ合う他に、質問、回答というアノテーションによりその曲に対する理解を深めていきたいという要求があった。今後、アノテーションを用いたユーザ同士のインタラクションをスムーズに行っていくためにも、質問、回答のようにユーザの要求の高いアノテーションを定義していく必要がある。
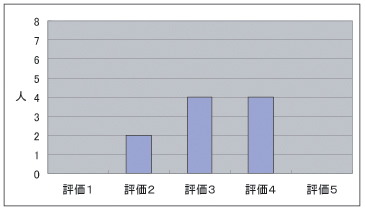
図4.5: アンケート結果(質問3)
質問4については図のような結果であった。評価の平均が3.9であり、高い評価結果となった。アノテーションを行いたいと思う理由については、主に本システムを通じてのユーザ同士がインタラクションを行うことができるため、様々な情報を収集する場となりうる、というものが多くあった。このように、アノテーションを階層化させることにより、アノテーションシステムに掲示板のような機能を持たせることができると分かった。
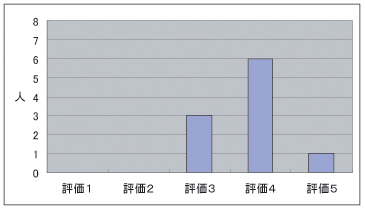
図4.6: アンケート結果(質問4)
掲示板のように、多くのユーザが集まるシステムであれば、アノテーションの情報も多く作成されることになり、アノテーションの収集効率も高まるであろう。アノテーションシステムの性質として、多くのアノテーションが集まればより応用サービスを高度なものにすることができる。そのため多くのアノテーションを容易に収集することができる可能性を持つ本システムは有用であると言える。
また、音楽についてあまり知識の無い人にとっても、感想などを言い合う場が提供されれば、音楽と身近に接する機会が増えるため、音楽そのものの価値も高まるのではないだろうか。
アノテーションによるインタラクションが可能であるため、将来音楽の教育システムとして利用することも可能であろう。先生と生徒が、質問、回答を楽譜上で行うことができれば、より効率的な教育手段となる。
他に考慮しなければならない問題として、アノテーションのコストの削減が挙げられるが、コストを軽減する手法はいくつか存在する。本システムを、アノテーションが楽しいと感じるシステムに改善すれば、ユーザの心理的負担を軽減することができる。また、他のコンテンツに対するアノテーションを別のコンテンツで再利用することや、機械による自動解析の結果をアノテーションに利用するといった手段でアノテーションのコストを削減することができる。さらに、楽譜に対するアノテーション以外にも、手軽に行うことのできる別のアノテーションの手法を実現する必要があると思われる。
評価実験の結果、複数の問題点も挙がったが、本システムはアノテーションの作成支援システムとして有用性が高いと考えられる。また、本システムは、今回の評価実験によって明らかになった諸問題の多くについても今後対応できる拡張性を備えている。今後も研究を進め、これらの問題を解決していく予定である。
5 関連研究
5.1 MPEG-7
MPEG-7はマルチメディア・コンテンツに対するメタデータの表記方法に関する国際標準規格である。正式名称をMultimedia Content Description Interface という。マルチメディア・コンテンツの検索の際に直接の検索対象となる特徴データを表現することができる。これら特徴抽出や利用法は今後も更なる発展の余地があると考え、MPEG-7は特徴データの抽出方法やその利用法については規定していない。また、アプリケーションの形態に対しても独立して定められた規格である。
マルチメディア・コンテンツに対するメタデータの表記方法としては、このMEPG-7が広く知られているが、本研究ではMPEG-7を採用しなかった。MPEG-7では、もともと決められたインタフェースに従ったメタデータしか記述することができない。またその形式は必ずしも二次利用に有効なデータ形式とは言えない。本研究では、アノテーションとして関連付けることのできる情報はすべてアノテーション定義XMLにおいて記述することができる。これによって二次利用に適した形式のアノテーションを柔軟に定義することができるため、MPEG-7を採用するよりも有効であると考える。
5.2 標準データ記述言語を用いた伝統音楽のデータ形式
XMLにより、長唄譜のためのデータ形式を定義した研究である。小十郎譜と三味線文化譜の持つ楽譜情報を忠実に記述するためのXMLによるデータ形式GIDA_U(Generally Integrated DAta format for nagaUta notation)を定義している。
GIDA_Uにより、長唄譜のようにパート間の同期をとりにくい楽譜をうまく記述することができる。また、旋律のヴァリアンテをうまく記述できる。口頭伝承によるところが大きい民族音楽には、多くのヴァリアンテが存在するので、これらの工夫は有効であるといえる。
しかし、このように音楽の種類に応じて書式を定義することは非常にコストの高いものとなってしまう。MiXAのように、ベースとなる形式の音楽コンテンツに対して、アノテーションとして情報を付与していく形態のほうが柔軟に、音楽の種類に応じた情報を記述することができる。
5.3 CDDB
CDDBは音楽CDに収録された楽曲情報を検索・認識するデータベースである。現在は約85万曲の音楽情報を収録し、音楽CD再生ソフトや機器への搭載がメインとなっている。これは音楽CDをPCや情報機器にセットすると、自動的にCDDBにアクセスして該当CD情報を検索、曲名やアーティスト名を付加してCDを再生できる。CDDBとの連携機能を持つソフトは数多いが、代表的なものとしてはRealJukeBoxやWindowsMediaPlayer、WinAmpなどがある。
CDDBは音楽コンテンツそのものに対して、タイトルなどメタデータを付与することができる仕組みである。多くの音楽プレイヤーに採用されているため、非常に有用なアノテーションデータを保持していると言える。しかし、音楽コンテンツの各要素に対してのアノテーションはこの仕組みでは実現することができない。より音楽コンテンツの詳細部分に対してアノテーションを行うためには、本研究で実装したような楽譜に現れるオブジェクトに対するアノテーションを付与する仕組みが必要である。
5.4 パピプーーン・SoundComplete
パピプーーンは、GTTMのタイムスパン簡約と演繹オブジェクト指向データベースを利用し、音楽を要約するシステムである。ここで、GTTM (GenerativeTheory of Tonal Music) とは、音楽理論のグルーピング構造と拍節構造を分析する代表的な手法であり、タイムスパン簡約とは、これらの構造を用いて解析されるもっとも安定なまとまりを形成する階層構造である。パピプーーンによりユーザとのインタラクションを通じて、課題曲全体の雰囲気を反映した質の高い要約を生成することができる。
音楽の高度な要約を実現するために、前処理としてユーザは専用ツールTS-Editorを用いてGTTMのタイムスパン簡約に基づく課題曲分析を行う。TS-Editorは、音楽コンテンツに対してアノテーションを付与するシステムといえる。MiXAと大きく異なる点は、音楽コンテンツの表示形態である。MiXAが楽譜を表示してそのオブジェクトに対してアノテーションを行うシステムであるのに対し、TS-Editorは音符を一切使用せず、ツリー形式で音楽を表現している。このように、同一の音楽コンテンツのアノテーションであっても、様々な手法が存在する。
SoundComplete は、パピプーーンの要約機能などをいくつかモジュール群として持つ、音楽の専門的な知識がないユーザでも簡便に楽曲を創作し交換して楽しむことができる音楽エンタテインメントソフトウェアである。ユーザに楽曲(断片) を加工・編集するどのモジュール群を提供し、ユーザはそれらをパッチエディタ上で自由に組み合わせ、Web上からインポートした楽曲(断片)を出発点として、新しい楽曲の創作を行う。作業の任意時点での楽曲をエクスポートする。主な特徴としては、既存の楽曲(断片)に少し手を加えて新しい楽曲を制作するという手法、他ユーザの楽曲を容易に入手できる環境、旋律や拍節といった高次レベルの音楽構造を対象とした操作とそれらのパッチエディタ上での柔軟な組合せ機能、などが挙げられる。
パピプーーン、SoundCompleteはアノテーションの応用例であるといえる。アノテーションとして付与される情報を用いて、高度な要約や編集を可能にしている。
6 まとめ
本論文では、音楽コンテンツの任意の要素集合に対してメタ情報を関連付けるシステムMiXAについて、新規性と意義、実装を述べた。MiXAの特徴を以下にまとめる。
MiXAは、ある実現したいサービスに応じて、そのサービスに必要なアノテーションの種類、名称などを柔軟に変更することができる。このため、効率よくアノテーションを収集することができ、容易にその情報をサービスに役立てることが可能である。
楽譜に対する操作により、楽譜中に表れる音符や休符、タイトル、作曲者などのオブジェクト、またはその集合に対して、アノテーションを関連付けることが可能である。
高度な検索システム、再構成システムを実現するために、MiXAでは、
- 意見・感想
- 解説
- 印象
- 曲の構成
- コード
以上の4つのアノテーションを付与できるようにアノテーション定義XMLを記述し、インターネット上でシステムを公開してユーザにアノテーションを付与してもらった。
アノテーションに対してさらにアノテーションを付与するといった拡張性も持っている。またアノテーションはXML形式で保存されているので、仕様の変更にも容易に対応することができる。
収集したいアノテーションが多人数に上る場合を考慮し、Webブラウザベースのシステムとした。ユーザはインターネットにつながっていればどこからでもアノテーションを行うことができる上に、ソフトウェアのインストールなどの複雑な手続きを踏む必要が無い。
また、MiXAの評価実験を行い、その有効性を確認した。
MiXAのアノテーションを応用したシステムとして、検索・再構成システムを実装した。それぞれの特徴を以下にまとめる。
元の曲と、MiXAによって曲に付与されたアノテーションを用いた、高度な検索システムを実装した。
元の曲に含まれる、タイトル、作詞作曲者といった情報に加え、意見・感想、印象、コード進行による検索が可能である。またコード進行の検索には、例えば「C G F C」というコード進行と、「A D C A」というコード進行のようにキーが違うだけで全く同じコード進行について、コード進行の類似度を計算し、検索時のランクを変化させている。
元の曲がMusicXMLであり、アノテーションの情報もXML形式で保存されているため、検索結果をXPathで容易に取得できる。
さらに、「イントロが悲しい感じの曲」や、「サビの部分が、C G F Cというコード進行の曲」といったような、曲の大まかな構成による絞り込み検索が可能である。絞り込み検索では、検索対象がどれだけ指定した曲の構成の中に含まれているかを計算し、ランクに反映させている。
この検索システムでヒットした曲の一覧から、MiXAのアノテーションシステムや、再構成システムに移動することができる。
また、「この曲の1番だけを聴きたい」「イントロ サビ エンディングの順で聴きたい」といった要求にこたえるために、再構成システムを実装した。元の曲に含まれている歌詞や楽器の情報に加え、MiXAによりアノテーションとして付与した曲の構成の情報を用いて、曲を切り出し再構成することが可能である。また、こうして再構成された新しい曲をダウンロードすることができる。その際の曲の形式はMusicXMLであるが、これは別アプリケーションによりMIDIなどに変換することができる。
7 今後の課題
評価実験の結果を踏まえて、今後、音楽コンテンツへのアノテーションに関する研究を続ける上での展望を述べる。
7.1 MiXAの改良
MiXAは、アノテーションシステムとしてまだいくつかの問題を持っている。今後改善していくべき課題を以下に述べる。
7.1.1 RWC音楽データベースの利用
Web上で音楽コンテンツを扱う際に、大きな問題となるのが著作権である。また、アノテーションを用いた応用システムの評価についても、比較対照となるシステムが存在しないため、評価を行うことが難しい。この問題を解決するために、RWC音楽データベースの利用を検討している。
RWC音楽データベースは、世界で最初の大規模な研究用音楽データベースである。他の研究分野では、以前から共通データベースの必要性・意義が認識されて、多様なデータベースを構築する努力がなされてきたが、音楽情報処理の分野では、従来、共通楽曲データベースは存在していなかった。
しかし、RWC音楽データベースを、ベンチマークとして共通に利用できれば、研究者は問題意識を共有しながら、様々なシステムを適切に比較・評価することが可能になる。それだけでなく、統計的手法や学習手法を活用した、 データベースに基づく多様な研究の進展も期待できる。また、学会等における研究成果の対外発表の際にも、著作権等による制約を受けずに自由な使用ができるという利点がある。
現在本システム、はSVG形式の楽譜を作成する時点のプログラムが未熟なため、童謡のように簡単な楽譜しか生成することができない。今後プログラムを改善し、本アノテーションシステムを用いてクラシックなどの複雑な曲に対してアノテーションを行いたいと考えている。
7.1.2 アノテータの嗜好に基づいた表示
楽譜にアノテーションのオブジェクトが分散しているため、ユーザは任意の場所にアノテーションオブジェクトを移動することができる。しかし、そのオブジェクトが自分で作成したアノテーションオブジェクトでない場合は、アノテーションの保存を行っても、移動させた情報を保存することはしない。また、アノテーションの削除を行った場合も同様に、削除の情報を保存しない。そのためユーザは再び同じ楽譜を見る際に、以前移動したり、消したはずのオブジェクトが、操作前と変わらない位置に存在してしまう。
このような状況は非常にわずらわしいものであるため、ユーザが自分自身で作成したアノテーションでなくても、オブジェクトの移動、削除といったオペレーションの情報を保存する必要がある。ただし、アノテータごとにアノテーションを分けて管理するため、アノテーションをしたユーザと別のユーザが、アノテーションオブジェクトを移動、削除したとしても、オリジナルのアノテーションの情報を変更するわけではない。このような方式をとれば、オブジェクトを移動、削除したユーザにはそのアノテーションオブジェクトをオペレーション後の状態にして表示し、その他のユーザには通常通りの表示をするといったことが可能になる。
このように、アノテータごとにカスタマイズされた情報を提示することができるようにしていく予定である。
7.1.3 アノテーションの排他処理
アノテーションが既に関連付けられているオブジェクトの部分集合に対して、別のアノテーションが付与されることを許したくない場合がある。コードや曲の構成などのアノテーションがそれにあたり、例えば、既にAというコードが付与されている要素の部分集合を含む要素に対して、Cというコードのアノテーションを付与してしまうと、意味的に矛盾が生じてしまう。逆に、意見・感想などのアノテーションの場合は、重複する要素へのアノテーションを行っても問題が生じない。そのため、アノテーションの種類によって、システム的に意味的に矛盾するアノテーションができないようにする必要がある。
7.1.4 分散データベース
本システムでは、現在アノテーションが一つのデータベースにすべて保存されている。
しかし、音楽コンテンツであるMusicXMLは、ネットワーク上に分散している。それと同様、音楽コンテンツに対するアノテーションの情報も、分散して存在する状況が考えられる。そこで、アノテーションのデータベースが複数存在している場合でも、本システムはどこにデータベースがあるのか、データベースの更新など変化があったかを常に認識しておく必要がある。
このような複数のデータベースを監視するために、データベースの更新状況をチェックするクローラーを実装し、データベースの状況を本システムに通知するように設計すべきだろう。
7.1.5 アノテーション定義XML作成支援システム
現在本システムではサービス提供者は、利用したいアノテーションを収集できるようにするため、アノテーション定義XMLをすべて手で書かなければならない。そのため、アノテーション定義XMLのスキーマを調べてどのような記述形式なのかを理解したうえで記述することになり、非常に困難な作業となる。
そこで、アノテーション定義XMLを作成するためのツールを実装する予定である。アノテーションの名前、型、どのオブジェクトに関連付けることができるかなどを容易に記述していき、容易にアノテーション定義XMLを作成できるようにしていきたい。
7.1.6 アノテーションの適用範囲
音楽の知識に関する情報などについては他の曲に対しても同様の情報を適用することができる。そこで、ある曲においてそのような情報が作成された場合、別の曲でも該当箇所を解析し、その部分にも同様の情報を付与するような仕組みが必要である。同じアノテーションをいくつも付与する必要がなくなるため、後述するアノテーションの自動生成と同様、アノテーションの際のコストを削減することができる。
7.1.7 データ型
現在本システムで付与できるアノテーションのデータ型は、文字列、数字、真偽、コードの4種類である。しかし、これらのデータ型だけでは、再利用に適したアノテーションを生成することができない場合がある。
例えば演奏時に注意する点をアノテーションとして付与しようとしても、文字列だけですべて表現することが困難である場合がある。楽譜に対してフリーハンドで画像が書き込めるようにできれば、より効率的なアノテーションとなるだろう。
さらに、通常の音楽に用いられる五線譜に加え、ギターのタブ譜のように、楽器による特有の構造を持った形式での奏法譜を作成することができるように、高度な構造を持つメタ情報を作成できるように改良していく必要がある。
また、現在本システムでは、コードというデータ型のアノテーションを付与することができるが、そのコードがどのようにグループ化されているか、また、一つ一つのコードは次のコードに対してどのような働きをしているかといった、コード進行の情報を付与することができない。そこで、以下のようにコード進行のアノテーションを実現する予定である。
まずコードに対して、Chord Functionの情報をアノテーションとして付与する。この情報は、4種類のプロパティ(Tonic、Dominant、Sub Dominant、SubDominant Minor)から選択する。Chord Functionは、一つ一つのコードが、そのコード進行においてどのような役割を担っているかを示す情報である。例えば、ハ長調の曲において「C G7 C」というコード進行の場合、それぞれのコードは「Tonic - Dominant - Tonic」というChord Functionを持つ。
さらに、コードに対する別のアノテーションとして、どこからどこまでがひとまとまりのコード進行であるか、という情報をChord Progression Groupという名前で付与する。
コードのアノテーションと、コードに付与されるChord FunctionとChordProgression Groupの二つのアノテーションを合わせて、コード進行のアノテーションととらえる。
現在コード進行をアノテーションとして付与できないのは、一つのアノテーションオブジェクトに対してアノテーションすることはできるが、複数のアノテーションオブジェクトを一度に選択し、それに対してアノテーションを付与することができないためである。Chord Progression Groupの情報は、複数のコードの集合に対して付与されるべきアノテーションであるので、現時点でこの情報を作成することができない。早急に、複数のアノテーションオブジェクトに対するアノテーションができるよう改良する必要がある。
また、アノテーション定義XMLにおいて、これらの基本となるデータ型を組み合わせた新しいデータ型を定義することができれば、より再利用に適したアノテーションを作成することが可能となる。
7.1.8 日本語歌詞の対応
MusicXMLでは、歌詞はnoteタグの一つ一つの内部にlyricタグとして記述される。そのため、歌詞が英語の場合、一つの単語が複数の音符にまたがる時には、その間をハイフンで結ぶ。例えば、"weather"という単語が二つの音符に対応する場合、はじめの音符には"wea-"、二つ目には"ther"というように記述される。そのため、検索などで歌詞を利用する場合、ハイフンの付いている文字を連結していくことで、一つの単語に復元することができる。
しかし、日本語の場合、複数の音符に一つの単語がまたがる場合には、もともと漢字で表記される歌詞であっても、ひらがなやカタカナに直された上で音符に対応して記述される。例えば、"桜"という歌詞が3つの音符にまたがっている場合、一つ一つの音符に"さ"、"く"、"ら"、というひらがなが割り当てられる。また、どこまでが一つの単語であるのかを記述する方法もない。仮に英語のように、ハイフンでつないだとして、"さくら"という単語を導き出せたとしても、漢字の変換候補が複数あるため、どれが正しいのか、また、ひらがなのままが正しいのか、判断することができない。そのため、歌詞の検索において"桜"という文字で検索したとしても、その曲が検索一覧に表示されることはない。
そこで、歌詞の情報もアノテーションとして付与することを検討している。まずMusicXMLで記述されている、一つ一つの音符に関連付けらる歌詞の情報に加え、歌詞の一つ一つの文字に対して音符を対応させるようにする。上記の"桜" という歌詞に対して3つの音符に分かれて対応している場合には、"桜"という文字には、その3つの音符が関連付けられることになる。こうして、音符に対応する歌詞と、歌詞に対応する音符を併用することにより、検索など、歌詞を用いるタスクを高精度に実現することが可能になる。
7.1.9 メタ情報の自動生成とその編集
曲調やコード進行のように、ある程度コンピュータが自動で解析できる情報については、曲の登録が行われた際に、コンピュータがあらかじめそれらの情報を自動生成することが可能である。しかしその情報は必ずしも全て正しいわけではない。ユーザがその情報を編集、訂正することにより、精度のよい解析結果にすることができ、さらに高度な応用につなげることができる。
このように、コンピュータが作成した粗い情報を、ユーザがアノテーションという形で編集、訂正していくという方式をとれば、ユーザがアノテーションの際に費やす労力をかなり削減することができる。GTTMのように、コンピュータが曲の構成を解析してもあいまいな部分が生じるような場合には、そのあいまいな部分をアノテーションとして編集、訂正することより、有効な構造解析結果を得ることができる。
7.2 別の視点での音楽アノテーション
楽譜に対してのアノテーション作業は、メタ情報を詳細に生成できるというメリットがある。しかしアノテーションを行うユーザの労力は比較的大きくなってしまう。楽譜上で行うアノテーションの他に、もっとユーザが気楽に行うことができるアノテーションの手法が必要である。
7.2.1 視聴時におけるアノテーション手法
楽譜に対するアノテーションとは違う形態としては、音楽コンテンツの視聴状態において、比較的少ない労力でアノテーションを作成できるようにすることが考えられる。視聴の際に簡単なボタン操作などにより、ほんの少し曲の印象などのアノテーションを行うシステムであれば、ユーザがアノテーションをする際に必要となる労力はかなり小さいもので済む。このようなシステムでは、一人一人のアノテーションにより得られる情報が少ないが、より多くの人が参加することで情報量を補うことができる。
今後、このような、より気楽に行うことのできるアノテーション手法についても実装し、検証していく予定である。
7.2.2 音楽コンテンツの製作時におけるアノテーション手法
また、音楽コンテンツを作成する段階で、コンテンツ製作者自身がそのコンテンツに対してアノテーションを作成することができるようになると思われる。音楽コンテンツを作成する作業には、メタ情報として使える履歴が多く存在すると考えられるので、このような履歴を元にメタ情報を生成する手法についても考察中である。この場合、アノテーションシステムは作曲システムの中に組み込まれている必要があるため、MiXAのようにWebベースシステムとしての実現は困難であるが、作曲システムのプラグインとしてアノテーションシステムを実現することは可能である。
7.3 アノテーションを用いた応用システム
7.3.1 音楽検索システム
現在のコード進行検索は、曲の構成とコードの情報のみを使用しているため、コードの始まりがどこからであるか、一つ一つのコードの意味はどのようなものであるか、といった詳しい検索を行うことができない。「C、G、F、C」というコード進行を検索する場合、コード進行のまとまりのはじめからこのようなコードが表れる場合と、途中から表れる場合では意味が異なってくる。前述したコード進行のアノテーションを利用することができれば、コードのまとまりがどこからどこまでなのかがわかるため、正確なコード進行の検索を実現することができる。
コード進行には類似性が存在するが、現在コードの類似度計算に使用しているのは相対的にキーがどれだけずれているか、という情報だけである。「C G7 C」と「B F\#7 B」の二つのコード進行は、キーが一つずれているが、「C G7 C」と「D A7 D」の二つのコード進行は、キーが二つずれている。そのため、前者の組の方がより類似度が高い、と計算される。
しかし、キーのほかにも、類似性を示す情報が存在する。前述したコード進行のアノテーションに含まれるChord Functionがそれにあたる。
例えば、ハ長調の曲において「C F C」というコード進行を考える場合、それぞれのコードのChord Functionは、「Tonic - Sub Dominant - Tonic」となる。さらに、Sub Dominantのカテゴリには、F6、FM7、Dm7が存在するので、「C F C」のFのコードを、「C Dm7 C」と置き換えることが可能である。つまり、「C F C」と「C Dm7 C」という二つのコード進行には類似性が存在する。
このように、コード進行のアノテーションに含まれるChord Functionの情報を用いることで、より精度の高いコード進行による検索を行うことができる。
また、ある曲のコード進行と似た曲を探したい、といった曲の間の類似関係を要求する検索にも対応することが可能であろう。さらに、より直感的な検索を行えるように、自然言語による検索を実現していきたい。
7.3.2 音楽再構成システム
現在、再構成システムは、曲の構成のみを用いて、曲の各部分つなぎ合わせたり、削除したりしている。しかし、このようにぶつ切りにされたパートをつなぎ合わせただけでは、そのつなぎ目において違和感のある曲の流れになってしまうことが多い。
そこで、前述したコード進行のアノテーションを本再構成システムに利用することを検討している。曲を再構成する際、ぶつ切りにされたパートのつなぎ目の部分の前後のコード進行を解析し、曲の流れを滑らかにするコードを自動生成する。コードを自動生成する際には、Cadenceの原理を利用する。Chord Functionの4つの要素である、Tonic(T)、Dominant(D)、Sub Dominant(S)、Sub Dominant Minor(SM)の間には、以下の4つの法則が存在する。
- TはD、S、SMに進む
- Dは必ずTに解決し、S、SMへは進まない。
- SはT、D、SMに進む
- SMはT、Dに進むが、Sへは進まない。
この法則と、コード進行のアノテーションとして付与されるChord Functionの情報を用いて、再構成の際のつなぎ目のコード進行を自動生成することが可能である。
さらに、そうして自動生成されたコード進行による伴奏をつなぎ目に挿入することにより、つなぎ目の不自然さを改善する、といったものである。
7.3.3 プレイリスト作成システム
本研究で実装した検索・再構成のシステムを組み合わせて、プレイリスト作成システムを実装する予定である。例えば「サビの明るい曲」という検索要求の場合、ユーザはサビの部分をまず聴きたいと考えるだろう。そこで、検索に使用された曲の構成のアノテーション、この場合は「サビ」という情報を用いて、検索された曲を自動的に再構成する。さらに、検索結果一覧から、再構成済みの曲のMusicXMLを一括でダウンロードでき、プレイリストを容易に作成することができるシステムである。
このように検索要求に応じたプレイリストが容易に作成できれば、ユーザはそのプレイリストを再生して楽しむことができ、また検索した曲が自分の意図している曲であるのかを短時間で調べることが可能となり、非常に有用なものとなるだろう。
7.3.4 遠隔音楽教育システム
現在、MiXAによるアノテーションの応用として、高度な遠隔音楽教育の実現について考察中である。
近年、習い事をしたくても教室に通う時間の無い人のための通信教育が盛んになっている。また、PCの普及により、インターネットを通じての通信教育サービスも数多く見られるようになった。音楽に関しても、電子ピアノでの演奏をMIDIにしてメールでやりとりをする通信教育サービスが存在する。しかし、講師と生徒のやり取りはせいぜい週に1回程度であり、音楽の上達にとって一番重要な日々の練習に対しては講師側が十分にケアすることができない状態である。また、遠隔地の複数の生徒に対してMIDI をリアルタイムに送信し、同期的に遠隔教育を行うサービスが存在する。同期した教育は理想的であるが、音楽の特性上合奏などの場合を除いて、講師一人が複数の生徒を同時に教えることはなかなか難しい。しかし講師一人が生徒一人を教えるという方法ではコストが高くなりすぎてしまう。こういった理由から、多くのユーザが望む遠隔音楽教室の形は非同期であり、かつ毎日の練習を効率よく充実したものにできるようなサービスである。そこで、生徒が行う毎日の練習の際にアノテーションを利用して演奏時の注意を促すことができれば、一回一回の練習を非常に充実したものにすることができる。以下にアノテーションによって可能になる遠隔音楽教室について述べる。
まず音楽教室、たとえばピアノ教室を主催する側は、生徒が練習する音楽コンテンツの注意して演奏するべき部分に対して、どのような弾き方が望ましいかや、注意点などのメタ情報を関連付ける。また模範演奏のMIDIも用意しておく。
生徒は音楽教室の指示に従い用意されている練習用の音楽コンテンツとそのアノテーションをダウンロードし、電子ピアノのディスプレイにその楽譜を表示させる。
生徒が演奏の練習を始めると、演奏のスピードに合わせてどの部分をどのように弾けばいいかといった情報がディスプレイ上に効果的に現れ注意を促す。また演奏が終了すると、画面に模範演奏と生徒の演奏の差分やその曲に関連付けられているメタ情報から、どの部分がどのように間違っているか、どの部分が特によかったかなどが表示される。この際、前回の演奏でうまくいかなかった部分に対して、新しくどのように注意して弾くべきかといった情報を自動的に生成する。これにより次回の演奏練習では、前回うまくいかなかった部分に対して、画像や動画などを用いて注意を促すことができる。
生徒は週一回程度の間隔で、その一週間の間に練習したMIDIの履歴と、その際に自動生成されたメタ情報を音楽教室に送信する。
ある生徒から音楽教室に送られてきた、練習中に作成されたメタ情報の中には、別の人に対しても利用可能なものがあるかもしれない。このように教室側と生徒が行うやり取りの過程でアノテーションが蓄積されていく仕組みにすることで、情報が増えれば増えるほど音楽教室側がアノテーションの作業に大きなコストを割く必要がなくなってくる。
このように、アノテーションを有効に利用した遠隔音楽教室は既存のサービスを大きく上回る質のサービスになると思われる。このような遠隔音楽教室のシステムは、MiXAを拡張することにより実現可能である。
謝辞
本研究を行うにあたり日頃御指導を賜わった、 長尾確 教授、大平茂輝 助手には研究の基礎的な考え方から論文指導など様々な面でお世話になりました。御礼申し上げます。
長尾研究室秘書の兼松英代さんには学生生活ならびに研究活動のための様々なサポートをいただきました。また、長尾研究室の皆様には本研究を進めるにあたり有益な議論と様々な励ましを頂きました。この場を借りて御礼申し上げます。