
楽曲に対する多様な解釈を扱う音楽アノテーションシステム
概要
言語学の語用論の分野では、一文に複数の解釈が存在し、それらの中から適切な 解釈を選択するためには発話した人や受け取る人の文脈や背景を踏まえる必要 があると言われている。我々はビデオや音楽、画像などのコンテンツに関して も、そのコンテンツ内に複数の解釈が存在し、それらの解釈の中から適切なも のを選出する必要があると考えた。そのようなコンテンツの典型例として音楽 が挙げられる。音楽は芸術作品であるため、必ずしも解釈を一意に決定できず、 その楽曲を捉える人によって異なる解釈を見出すことがしばしばみられる。
そこで我々は音楽を対象とし、楽曲に対する多様な解釈をWeb上から収集する音楽アノテーションシステムを構築した。本システムは1.楽曲そのものに対するアノテーション、2.連続メディアに対するアノテーション、3.楽譜に対するアノテーションの3種類のエディタを備える。また実際に本システムによりアノテーションを収集し、楽曲に対する多様な解釈を扱う例として、楽曲検索システムとプレイリスト推薦システムを構築した。さらに実験を行い、同一の楽曲に対する複数ユーザからのアノテーションにより多様な解釈を取得することができることを確認し、本システムの必要性を実証した。
1 はじめに
言語学における語用論の分野では、ある文を意味的に捉えるためには、その文法や辞書的な意味に加えて、発話した人や背景を踏まえる必要があるといわれている。発話した人の背景によっては、一文に複数の解釈が存在し、一意に決定することが困難な場合が存在する。このような文を捉えるためには、考えうる解釈の中から、様々な文脈や知識の関連性を踏まえて適切なものを推論する処理が必要となる。
我々は、言語以外のコンテンツであるビデオや音楽、画像などのコンテンツにも複数の解釈が存在し、それらの中からそれぞれの人にとって適切な解釈を推論する必要があると考えた。例えばあるコンテンツの推薦度は、それぞれのユーザによって異なる。またコンテンツ推薦において有効であるとされる協調フィルタリングでは、多様な推薦度を実際に利用する際には、類似するユーザが付与した推薦度のみを利用する。
複数の解釈が存在するコンテンツの典型的な例として音楽が挙げられる。音楽は芸術作品であるため、意味を一意に決定することが困難であり、その楽曲を捉える人によって異なる意味を見出すことがしばしば見受けられる。このような場合、楽曲に関する複数の解釈の中から、その人にとって適切な解釈をの選別・抽出する手法が必要となるだろう。
例えば楽曲のグルーピング構造と拍節構造を分析する代表的な手法であるGTTM (Generative Theory of Tonal Music)は複数のルールにより構造化を行う手法であるが、ルール適用に関して厳密な定義がなされていないため,必ずしも一意の解を求めることができない。浜中らはこの問題に対処するために、GTTMの計算機モデルとしてルールの優先順位を決めるためのパラメータを導入したexGTTMを提案している。パラメータを操作するのは人であり、複数の解釈の中から人が一つの解釈を決定している例であると言える。
コンテンツに対して複数の解釈を扱うためには、複数の解釈をどのように取得し管理するかという問題がある。そこで我々はアノテーションの手法に着目した。セマンティックWeb の研究分野では、アノテーションは柔軟にコンテンツに対して個人的・公共的なコメントなどのメタデータを記述する手法として広く認知されている。そのためアノテーションは主観的・個人的な解釈を柔軟に収集するのにふさわしい技術であると言える。
del.icio.usやFlickrにおいて、Web上の多くのユーザがそれぞれのコンテンツにタグを付与することで、そのタグを基に分類やコンテンツへのアクセスを可能にするFolksonomyを構成している。音楽においても、Web上の多くのユーザにより少しずつ持ち寄られるアノテーションが音楽の解釈の多様性を浮き上がらせるのではないだろうか。そこで我々はWeb上のユーザを対象として、楽曲に対する様々なアノテーションを収集するシステムを構築する。またWeb上のユーザから収集する複数の解釈を用いたアプリケーションを実現する。
本稿では、2章でアノテーション管理のために採用したプラットフォームAnnphony について、3章でWeb上から楽曲への様々な解釈を収集する音楽アノテーションシステムについて述べる。4章ではこのシステムにより収集されたアノテーションを利用したアプリケーションである楽曲検索システムとプレイリスト推薦システムについて述べる。また5章ではWeb上のユーザからのアノテーションにより楽曲に対する多様の解釈を取得することができることを確認する実験を行い、本システムの必要性を実証する。
2 楽曲への多様な解釈の管理手法
本研究では、楽曲に対する複数の解釈を管理するために、任意のデジタルコンテンツに対するアノテーションを扱うプラットフォームであるAnnphony を採用した。本プラットフォームはRDFの形式を一部拡張することで、同一リソースに対する複数のアノテータによるアノテーション付与を実現している。
楽曲そのものを最小単位としない、より粒度の細かい処理を実現するためは、楽曲そのものへの解釈のほかに、楽曲の内部構造への解釈を扱う必要がある。楽曲のメディア形式はMP3、MIDI、MusicXML、WEDELMUSICXML など様々な形式が存在する。MusicXMLでは楽譜を形成するための情報が保持されており、楽曲の構造化が行われていると言える。またMusicXML はXML形式でありXPointerにより楽曲の任意の要素を指し示すことができるため、楽曲の内部構造に対するアノテーション記述が可能である。
一方でMP3のような音響信号で構成される形式には、楽曲としての構造化がなされていないため、楽曲の内部構造を指し示すことができない。現在流通しているほとんどの楽曲はMP3のような音響信号メディアであり、これらのメディアに対する楽曲の内部へのアノテーションを実現するためには、一度楽曲の構造化を行う必要がある。AnnphonyではElementPointerという形式を提案しており、本形式によりMP3などのバイナリに対しても、時間区分や楽器パートによる区分など、任意のセグメンテーションを定義することができる。そのため楽曲の構造化に関するアノテーションを収集し、バイナリのコンテンツに対応するMusicXMLのような構造化されたコンテンツの生成にも役立つプラットフォームであると言える。
AnnphonyはWeb上の多くのユーザから様々なコンテンツのアノテーションを取得し、管理することを目的としている。多くのユーザから幅広く収集されるいわゆるライトウェイト・アノテーションには一般的に信頼性の問題が存在し、多様なアノテーションの選別を行う際の障害となっている。そのため多数のユーザからのアノテーションを扱う際には、各アノテーションの信頼度を考慮しなければならない。Annphonyでは全てのアノテーションにアノテータに関する情報と、そのアノテーションの信頼度に関する情報が自動的に付与される。アノテーション・アノテータの信頼度は文献 の手法が採用されている。そのためアノテーションの選出の際の一つの指標としてアノテーションの信頼性を利用することができる。
楽曲へ付与するべきアノテーションは、そのアノテーションを利用するアプリケーションの種類によって異なるだろう。例えば楽曲推薦を行うためには楽曲の推薦度に関する情報が、楽曲の印象による検索を行うためには印象情報が必要となる。このようなアノテーションの種類を全て網羅することは困難であるため、アプリケーションの種類によって柔軟に収集するべきアノテーションの定義を行うことができる必要がある。AnnphonyではRDFSによるアノテーション定義を記述することで、定義に沿ったアノテーションを管理するため、アプリケーションによってアノテーション定義を変更することで様々な種類のアノテーション収集が可能である。
以上のことから、Annphonyは楽曲の内部構造に対する複数の解釈を管理するために有効なプラットフォームであると言えるだろう。次章ではAnnphonyをベースとした、Web上の多くのユーザからアノテーションを収集するシステムについて述べる。
3 音楽アノテーションシステム
楽曲に対する複数の解釈を取得するためのシステムとして、音楽アノテーションシステムを構築した。本システムでは、その楽曲の推薦度など楽曲そのものに対するアノテーションを収集するエディタ(Tune Annotator)、MP3などの連続メディアに対する時間的なセグメンテーションと、セグメントに対するアノテーションを付与するエディタ(Timeline Annotator)、楽譜に出現する要素に対するアノテーションエディタ(Score Annotator)という3種類のエディタを備え、楽曲の形態や取得するアノテーションの種類に応じて様々な粒度のアノテーション取得を支援する。
これらのエディタは全てWebブラウザベースのシステムとして実装しており、Web 上の多くのユーザからのアノテーション収集を期待している。前章で述べたように、アノテータ情報はそれぞれのアノテーションの信頼度に関連する情報である。そのためアノテータとして本システムを利用するためにはあらかじめユーザ登録が必要であり、ログイン時にユーザ認証を行う。システムはどのアノテータがどのアノテーションを付与したかを認識し、各アノテーションにアノテータ情報を自動的に付与する。
表に各エディタを利用するための前提条件を示す。TuneAnnotatorの利用に関しては、その楽曲がURIを持つことが前提条件となり、コンテンツの種類はMP3、MIDI、MusicXMLなどどのような形式でもかまわない。Score Annotatorを利用する場合、楽曲がMusicXML で記述されていることが前提となる。MP3などの連続メディアの場合、Timeline Annotatorにより楽譜生成のためのアノテーションを付与しMusicXMLにコンバートすることで、ScoreAnnotator を利用した楽曲の内部構造へのアノテーションを付与することができる。
検索・推薦・要約など、楽曲に関するアプリケーションは多岐に渡り、アプリケーションの種類によって必要となるアノテーションは異なる。そのため全ての種類のアノテーションを網羅するアノテーションエディタを実現することは困難であり、柔軟なアノテーションの定義が必要となる。本システムは、前章で述べたAnnphonyにおけるアノテーション定義に基づくアノテーション収集を行う。アノテーション定義を変更した場合は、各エディタで取得できるアノテーションの種類も動的に変更される。
3.1 Tune Annotator
Tune Annotatorは楽曲そのものに対するアノテーションを収集するためのエディタである。図 は、4.2節のプレイリスト制作支援システムのために利用される、楽曲情景・鑑賞状況に関するアノテーションを付与する例である。あらかじめ楽曲の基本情報(タイトル、アーティスト、歌詞情報など) のアノテーションが同エディタにより取得されている場合はそれらの情報も表示される。
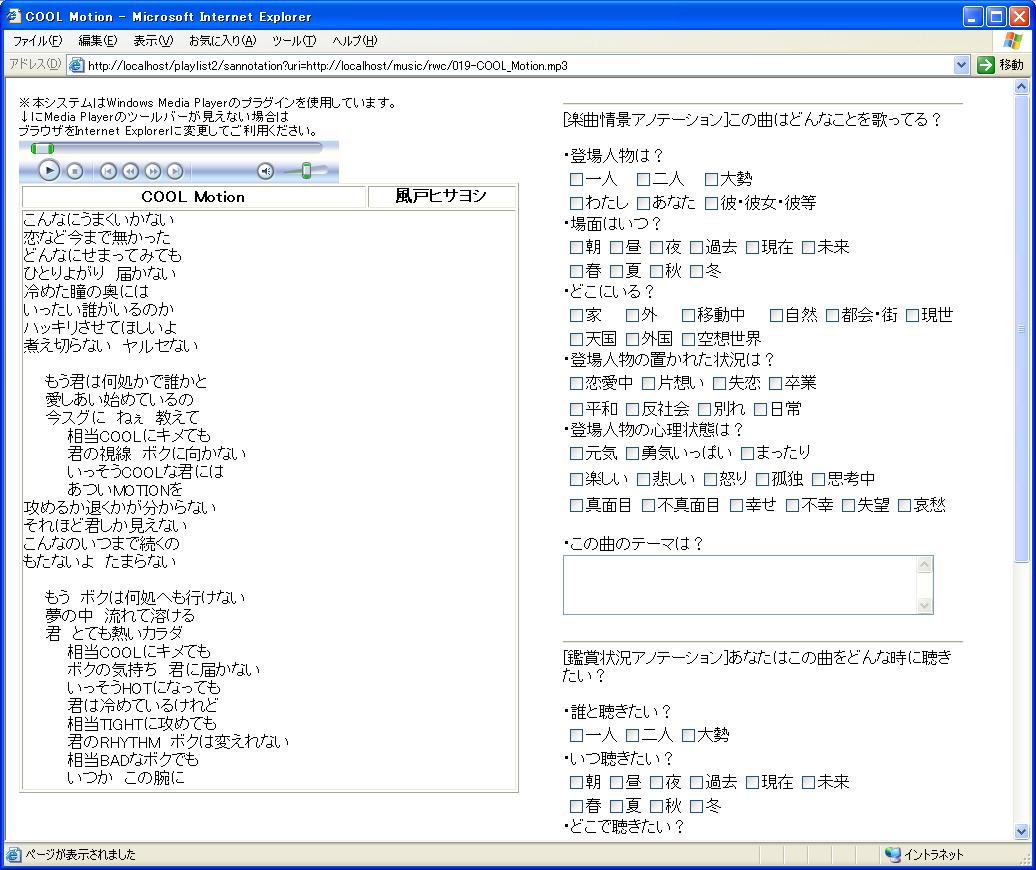
図1: Tune Annotatorの画面例
システムはAnnphonyのアノテーション定義を解析してWebブラウザ上に項目を生成し、ユーザに提示する。ユーザはそれらの項目に解答していくことでその楽曲へアノテーションを付与する。本エディタはタイトルやアーティストなどの基本情報や推薦度、アンケートなどの収集に適している。
3.2 Timeline Annotator
Timeline Annotatorは、MP3などの連続メディアに対して楽曲を時間的にセグメント化し、そのセグメントに対してアノテーションを付与するためのエディタである。音楽アノテーションシステムとしての本エディタの主な役割は、バイナリの連続メディアに対して楽譜形成に相当する情報の付与を行うことである。その楽曲をScore Annotatorで利用できるMusicXMLの形式にコンバートし、楽曲の内部構造に対するより詳細なアノテーションを収集することが可能になる。アノテーション定義のバリエーションにより取得できるアノテーションは変化するが、本節では連続メディアを構造化し、Score Annotatorに適用するまでの手順を述べる。
連続メディアを時間的にセグメント化するためのElementPointerの定義を図に示す。図では、楽曲の先頭からの経過時間の組(from,to)により楽曲のセグメントを表現するElementPointerを定義している。またMusicXMLを生成するために必要なアノテーション定義を用意する。図は音符情報に関するアノテーション定義の一部であり、楽器パート、発音列(音高・音長、音符タイプ)、歌詞などに関するプロパティを定義している。

図2: 時間的セグメンテーションのためのElementPointer定義
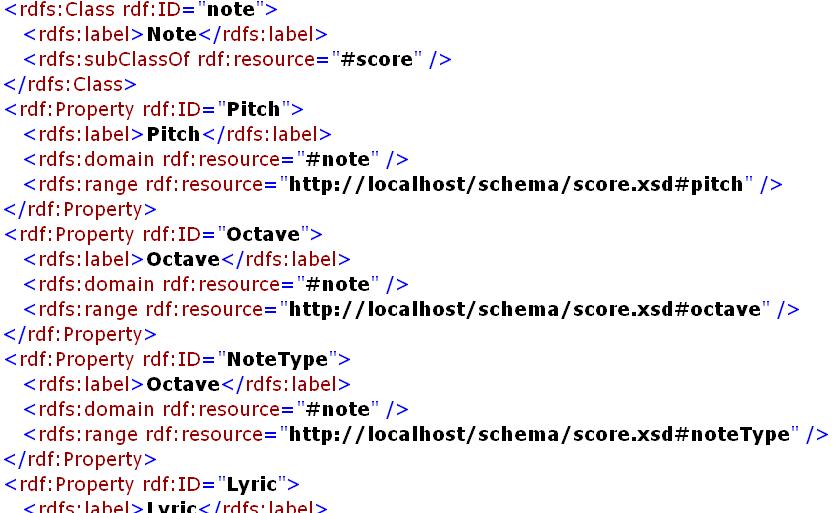
図3: 音符情報に関するアノテーション定義の一部
楽譜生成のためのアノテーション定義を適用したTimeline Annotatorを図に示す。ユーザは提示されたインタフェースから楽曲の時間区分に対するアノテーションを付与する。まず[From][To]ボタンによりセグメントを切り出し、[Annotation]ボタンを押してそのセグメントに対して、楽器パートや音符情報など、定義されたMusicXMLの生成に必要な情報を付与する。図 は切り出されたセグメントに対して音符情報を付与している例である。Annotation Typeを変更することで、以下に現れるフォームは自動的に変更される。また図は実際のアノテーション例である。音高やオクターブなどの音符情報に加え、Annphonyにおけるアノテーションの基本情報であるアノテータや作成日時、信頼度情報がRDF形式で記述されている。これらのアノテーションをAnnphonyに順次登録していく。
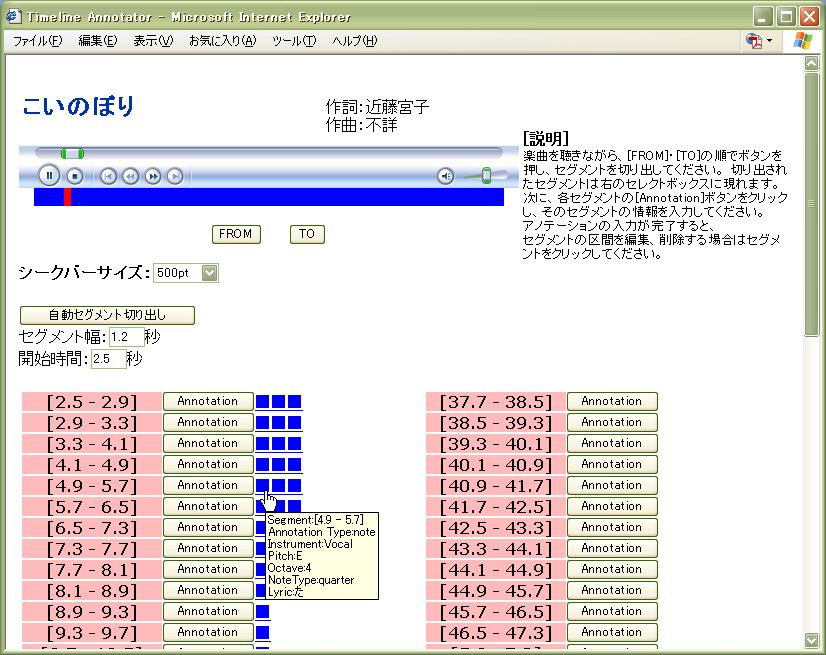
図4: Timeline Annotatorの画面例
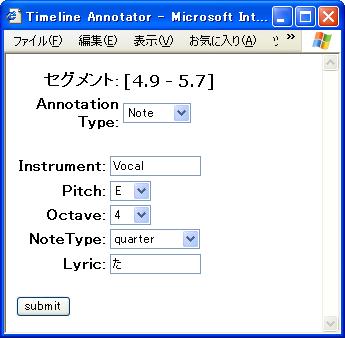
図5: セグメントへのアノテーション例
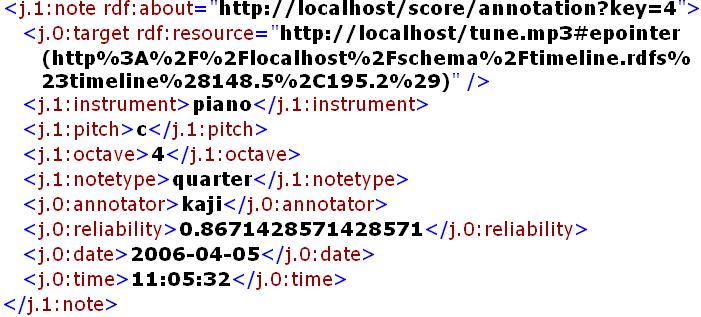
図6: 楽譜生成のためのアノテーションの一部
同一楽曲に対する上記のアノテーション群が収集されると、別途用意したコンバータによりアノテーション群からMusicXMLが生成される。図は実際に変換されたMusicXMLの一部である。図の部分に相当する情報が記述されているのが分かる。

図7: コンバートされたMusicXMLの一部
MusicXMLにおける音符や休符のノード中には、notationタグによりそのノードへの付加情報を記述することができる。連続メディアと、アノテーション群から生成されるMusicXML間の対応付けのために、コンバートする際にnotationタグ中に対応する連続メディアの開始・終了時間情報が埋め込まれる。MusicXML が生成された楽曲に関しては、次節のScore Annotator によるアノテーションが可能になる。
楽曲の楽譜形成のための情報付与は非常に人的コストがかかる処理である。ビートトラッキングなどの採譜に関する自動処理の結果を随時取り込み、人手によりその結果を修正することでコストを抑えることが可能であると考えられる。
3.3 Score Annotator
Score Annotatorは、楽譜に現れる要素の集合に対するアノテーションを付与するためのエディタであり、楽曲の内部構造に対するアノテーションを実現する。各楽曲についてMusicXMLを用意することで、本エディタにより楽曲の更なる構造化や詳細部分に対する様々なユーザの解釈を収集することができる。
アノテーションの付与が可能な楽譜の要素は、各楽器パートの音符、歌詞、タイトル、作詞者、作曲者、発想記号である。本システムでは楽曲に対する人間の解釈を扱うため、解釈が不完全であったり誤っている場合があるだろう。そのような場合にはそのアノテーションを補足するアノテーションが必要になる。そこでScore Annotator では、アノテーションに対してもアノテーションの付与を可能にした。
ユーザには図 のように楽譜とアノテーションを可視化したオブジェクトが重ねて表示される。アノテーション作成の際、ユーザはブラウザに表示された楽譜から関連付けたい要素または要素集合をマウスの操作により選択する。選択した部分が音符、休符を含んでいる場合は実際にその部分を視聴して確認できる。次に図 のように右クリックメニューからどの種類のアノテーションを関連付けるかを決定し、その後具体的な情報を記述する。
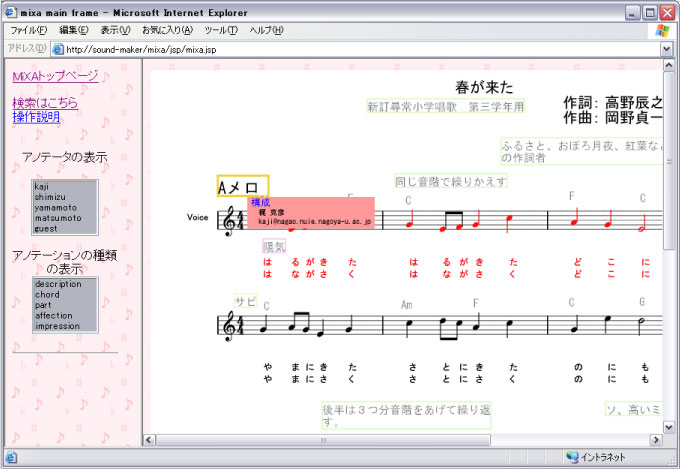
図8: Score Annotatorの画面例

図9: 選択したオブジェクトへのアノテーション付与
楽曲の内部構造に対するアノテーションは、楽曲そのものや時間区分といった大まかな対象ではなく、楽譜という音楽の論理構造に基づいた詳細な対象への言及を実現する。Score Annotatorによって付与されるアノテーションを利用することで、音楽的に意味のある部分へのアノテーションを利用することができるため、より高度なアプリケーションの実現を期待できる。
4 楽曲への多様の解釈を用いたアプリケーション
音楽アノテーションシステムによって、様々なアプリケーションに適用可能なアノテーションをWeb上から収集することが容易になった。本章では実際のアプリケーション例として、詳細な楽曲の内部に関する検索システムとプレイリスト制作支援システムを構築した。以下にそれぞれのアノテーション定義と、アプリケーションの詳細を述べる。
4.1 楽曲検索システム
楽曲の内部構造に対するアノテーションを利用した楽曲検索システムを構築した。本システムでは、タイトルや作詞・作曲者などの楽曲の基本情報からの検索に加えて、アノテーションを用いたキーワード検索、コード進行による検索、曲の構成による絞り込み検索を実現する。以下に収集するアノテーションと、それぞれの検索機能について述べる。
4.1.1 アノテーションの定義と収集
楽曲の詳細部分に対する検索のために、楽譜に出現する音符・休符・歌詞の集合に対するアノテーションとして、印象、解説、意見・感想、楽曲の構成、コードの4種類を設定した。それぞれのアノテーションの定義を表 に示す。
印象は曲の各部分に対し、ユーザが楽曲を鑑賞して受けた印象をHevnerが提唱した8 種類の印象語から選択する。解説に関しては自然言語による記述を許可する。楽曲の構成は、ポップスなどに見られるイントロやサビといった、その曲の大まかな構成を記述するためのアノテーションであり、8種類の中から選択する。コードは楽曲の各セグメントがどのような和音構成であるかを、基音・サフィックス・ベース音の組で表現する。また印象、意見・感想、解説のアノテーションは楽譜中の任意の要素に対して付与することができるが、楽曲の構成とコードに関するアノテーションは音符・休符・歌詞の集合への付与のみを許すように定義している。
これらのアノテーション定義をScore Annotatorに適用し、複数のユーザによってアノテーション収集を行った。以下に収集されたアノテーションに基づく検索機能の詳細を述べる。
4.1.2 キーワード検索
タイトル、作詞者、作曲者、意見・感想、解説、印象の情報に関して図のフォームからキーワード検索を行うことができる。楽曲の基本情報であるタイトルや作詞・作曲者情報からの検索以外に、Web上のユーザが付与したアノテーションに基づく検索が実現されている。
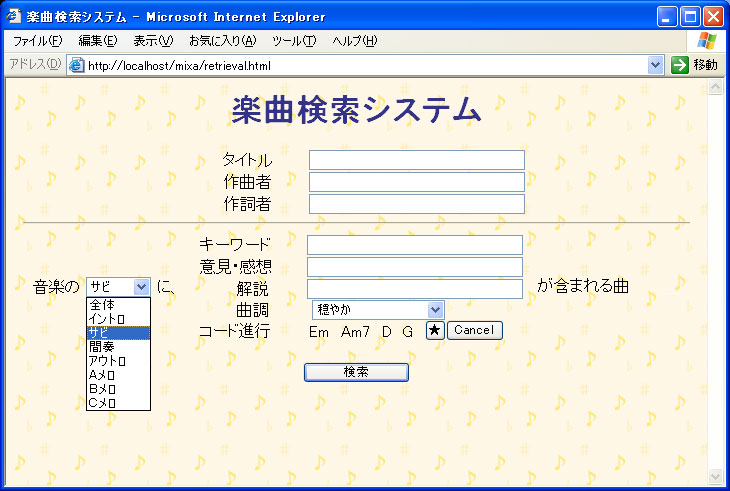
図10: 楽曲検索フォーム
検索結果のランクは同一の楽曲に出現するキーワードの出現数に依存する。印象情報は、ユーザの解釈の多様性から同一のセグメントに対して複数の競合するアノテーションが多く見られると予想される。そこで、検索するユーザとある閾値以上嗜好の類似するユーザが付与したアノテーション用い、それらのアノテーションを採用した。例えばある二つの楽曲に、等しい数の「悲しい」という印象アノテーションが付与されていた場合、嗜好の類似したユーザによるアノテーションが多い楽曲が上位にランクされる。ユーザの嗜好は後述するプレイリスト推薦システムのものを利用している。
4.1.3 コード進行による検索
コードに関して競合するアノテーションが複数付与されている場合には、それらの中で最も信頼度の高いアノテーションを採用する。キーワード検索のようにユーザの類似度によりアノテーションを選別する手法も考えられるが、正確性が求められる検索であるため信頼度による選別を優先した。
ユーザは検索フォームの「コード進行」のボタンを押し、別ウィンドウから順にコードを入力していくことで、コード進行による検索が可能である。サーバはまず、検索要求であるコード進行から相対的な音の変化を計算する。「C G/B Dm C」というコード進行の場合は「0,-5/-1,2m,0」となる。そして各音楽コンテンツに対して、コードのアノテーションを取得し、曲ごとにコード進行を作成する。次に検索要求のコード進行の相対変化を用い、アノテーションから作成されたコード進行に対してDPマッチングを行い、検索要求との距離を測る。距離の近い順に正答の候補とする。rankはDPマッチングの距離の逆数を正規化した値とした。コード進行での検索アルゴリズムは文献を参考にした。
4.1.4 楽曲の構成に基づく絞込み検索
本システムは「サビが悲しい曲」といった曲の構成による絞り込み検索機能を持つ。Webサーバは、検索対象となるキーワードやコード進行と、絞り込みを行う曲の構成を受け取る。「サビが悲しい曲」という検索要求を受け取った場合、「サビ」が絞り込みを行う曲の構成であり、検索対象は「悲しい」という印象のアノテーションである。まず、曲の構成以外の検索要求である「悲しい」やコード進行について、前述の検索を行う。この時の検索結果のランクをpriorrankとする。次に、絞り込む曲の構成「サビ」の部分に対する「悲しい」アノテーションの含有率を計算し、含有率に基づきランクを決定する。絞込み検索に関しても、キーワード検索と同様に印象アノテーションを付与したユーザと検索を行うユーザの類似度を考慮し、ランクに反映させる。
このように、音楽アノテーションにより楽曲の内部構造に付与されたアノテーションを用いることで、従来の楽曲検索よりも高度な検索機能を実現することができた。本検索システムのために付与された楽曲の内部構造へのアノテーションは、検索のほかにも、楽曲要約や編曲に利用することも考えられる。
4.2 プレイリスト推薦システム
ジャンルやアーティスト、歌詞など、一般的に楽曲推薦に利用すると効果的であるとされている楽曲の特徴量がいくつか存在する。一方、日常生活における音楽との接し方から推測されるように、リスナの置かれている状況が、推薦するべき楽曲の選択に強く依存するのではないかと考えられる。そこで我々はリスナの嗜好と状況に合ったプレイリスト推薦システムを構築した。
4.2.1 アノテーション定義と収集
本システムは、楽曲の特徴量として歌詞・表現している情景(楽曲情景)・鑑賞したい状況(鑑賞状況)の3種類を採用した。楽曲情景、鑑賞状況に関する情報はリスナの解釈に強く関わる情報であるため、楽曲の音響情報を自動解析して得ることが困難である。そこで、音楽アノテーションシステムのTune Annotatorにより各楽曲に対して楽曲情景と鑑賞状況の情報を収集する。
楽曲情景・鑑賞状況アノテーションの定義にあたり、事前の予備実験において、どのような楽曲情景、鑑賞状況が存在するかを調査し、いつ・どこで・どのような心理状態であるかという項目を設定した。表は鑑賞状況に関する項目である。Tune Annotatorを用いてこれらのアノテーションを複数のユーザから収集した。
4.2.2 楽曲の特徴量
楽曲情景・鑑賞状況に歌詞のTF*IDFを加えた3種類のベクトルによりそれぞれの楽曲の特徴量とした。同一の楽曲に楽曲情景・鑑賞状況アノテーションが複数付与されている場合、対象ユーザと、ある閾値以上楽曲の嗜好が類似するユーザによって付与されたアノテーション群の平均ベクトルをその楽曲の特徴量に採用する。
楽曲間の類似度はこれらの特徴量の重み付き和により算出される。またユーザの嗜好に合った楽曲集合の平均をそのユーザの理想的な楽曲として楽曲情景・歌詞の特徴量空間にマッピングし、さらにユーザ自身が現在の状況を入力を鑑賞状況の特徴量空間にマッピングされる。プレイリストも同様に、プレイリスト要素である楽曲の鑑賞状況・歌詞ベクトルの平均値と、そのプレイリストが制作された状況をそれぞれの特徴量空間にマッピングする。以上の処理により、楽曲・ユーザ・プレイリスト間の類似を計算することが可能になる。
4.2.3 プレイリスト推薦
ユーザは、本システムに現在置かれている状況を入力する。システムはまず過去に制作されたプレイリストの中からユーザの嗜好と現在の状況を踏まえて、類似する嗜好・状況において制作された基プレイリストを選出する協調フィルタリングを行う。次に、選び出されたプレイリストに対し、嗜好に合わない楽曲を入れ替えるなど、よりリスナの嗜好に適合させるトランスコーディングを施し図のようにユーザにプレイリストを提示する。リスナは通常の音楽プレイヤと同様の操作によりプレイリストを鑑賞し、それぞれの楽曲に対して嗜好に合っているか、現在の状況に合っているかを申告する。システムはこのインタラクション情報を基に、さらにリスナの嗜好に適応したプレイリストに変換していく。
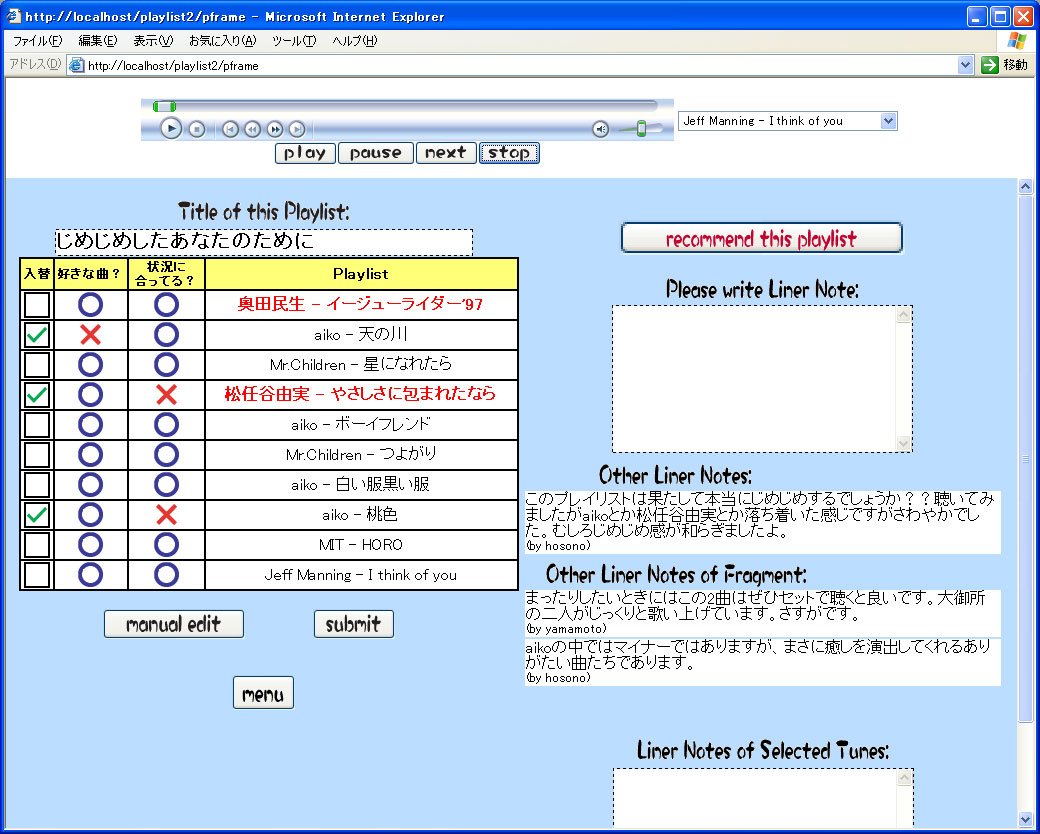
図11: ユーザに提示されるプレイリスト
またリスナはプレイリストに対して、ライナーノーツ(解説文)や推薦度のアノテーションを付与することができる。また、楽曲を鑑賞することで随時どの楽曲を鑑賞したかという情報を通知する。これらの情報からユーザ・プレイリストのモデリングを行い、協調フィルタリングや競合するアノテーションの選別に利用している。
また評価実験では本システムがユーザの嗜好や状況に適合したプレイリストの推薦に有効であることが確認されている。音楽アノテーションシステムを用いたアノテーションの収集により、高度なアプリケーションを実現することができた例と言えるだろう。
5 実験
ユーザや楽曲の特性によって解釈に多様性が存在し、音楽アノテーションシステムを用いることでその多様性を取得すること、またそのような多様性を扱う必要があること実証するための実験を行った。楽曲に対する解釈の例として、楽曲の最も印象的な部分であるハイライトを採用した。ハイライトは楽曲要約や試聴支援など様々な応用に利用することができる情報であるが、一般に楽曲のハイライトはサビの部分であるとされている。ユーザによってハイライトと認識する理由や区間に多様性が存在するのではないだろうか。以下に実験の詳細を述べる。
過去5年におけるオリコン年間売り上げの上位10曲ずつ、計50曲の楽曲を対象とし、被験者は20代の男女10名である。それぞれの被験者は、Timeline Annotator を用いて各楽曲のハイライトのセグメント切り出し、各ハイライトについて、なぜその部分をハイライトであると認識したかという理由を記述する。また別途その楽曲の嗜好に関する5段階項目、認知度に関する3段階項目に回答する。一方で、一人のユーザによりTimeline Annotatorを用いて人手により各楽曲のサビの部分を切り出しを行い、その部分をサビ区間の正解データとして利用した。
本システムにより収集されたアノテーションを、ハイライトと認識した理由により人手で以下に示す11種類に分類した。
-
サビである
-
歌詞が特徴的
-
聴いたことがある
-
歌い方が特徴的
-
盛り上がるから
-
メロディーが良い
-
個人的な思い入れ
-
演奏が特徴的
-
リズム・テンポが良い
-
イントロだから
-
その他
本システムはWeb上での任意のユーザによるアノテーションを収集するシステムである。実際にはユーザは好みの楽曲に対するアノテーションを多く付与すると考えられる。またサビであるという理由で切り出されたハイライト区間が、正解データであるサビ区間にどれだけの割合で含まれるかを計算したところ89.0%の重複がみられた。一方で楽曲の認知度が3であるもののみを用いたところ、正解データとの重複率は93.2%に上昇した。この結果から、楽曲の認知度の高さがアノテーションの信頼性と関連することが分かる。これらのことから、以降のデータは楽曲の嗜好が4以上、認知度が3である楽曲へのアノテーションのみを利用した。
図はハイライトと認識した理由が全体の区分数に占める割合を表している。一つの区間に対し重複する理由の記述を認めているため、割合の合計は100\% を超える。従来からハイライトであることが多いとされる「サビである」や「盛り上がるから」という理由に対して歌詞に基づく認識が多いことが分かる。また理由別のハイライトがサビにどれだけ含まれるかを表 に示す。この図から、サビである、盛り上がりに基づく認識のハイライトはサビ区間との重複率が高いが、歌詞や歌唱・演奏方法に基づく場合は必ずしもサビ区間との関連があるとはいえないことが分かる。
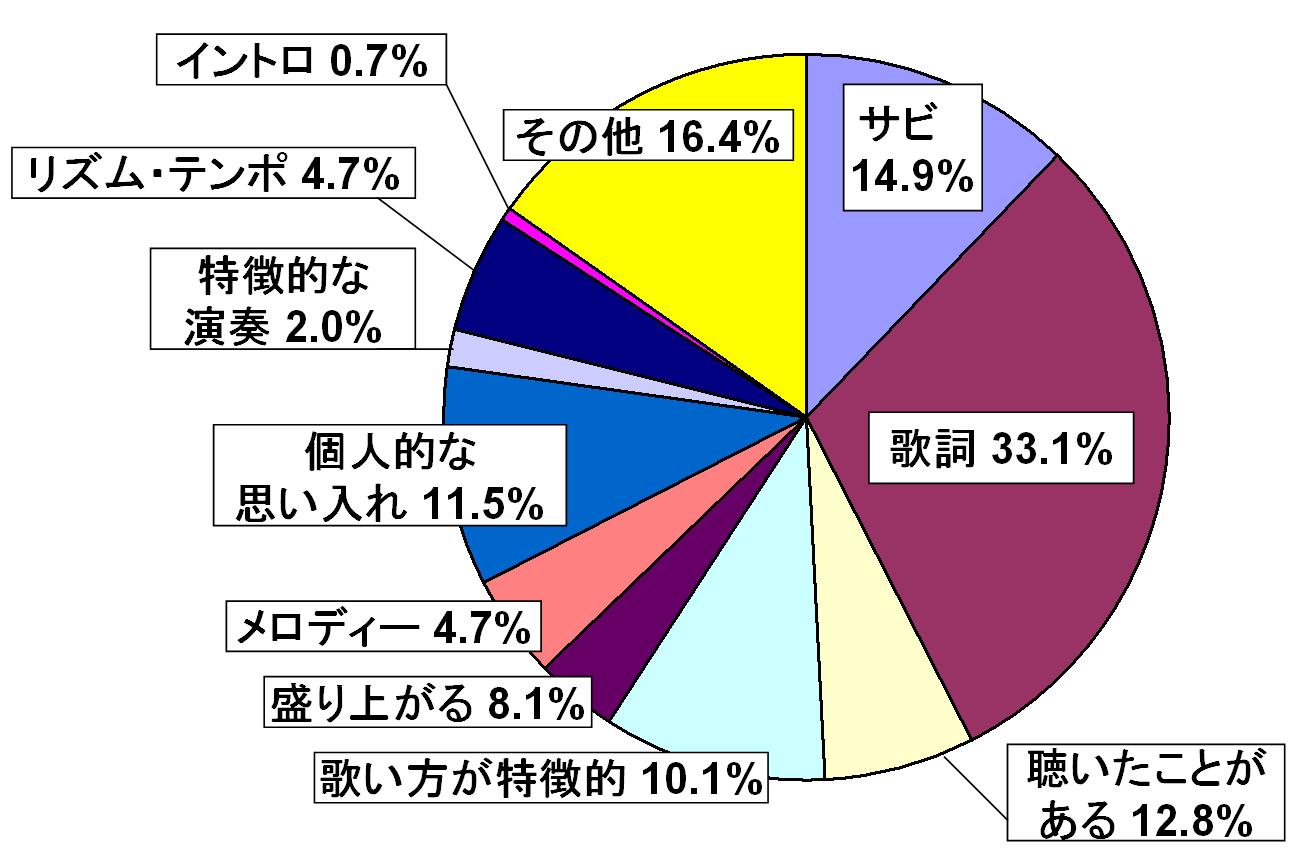
図12: ハイライトと認識した理由の割合
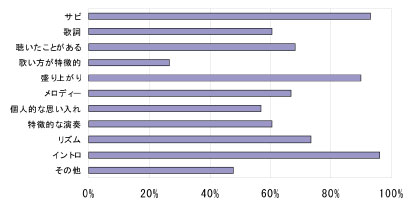
図13: 理由別ハイライトがサビ区間を占める割合
次にユーザごとの認識の多様性について考察する。図にユーザA、Bがハイライトであると認識した理由の割合を示す。ユーザAはサビであることでハイライトであると認識する可能性が高く、ユーザBは歌詞や歌唱方法に基づいてハイライトであると認識する可能性が高い。
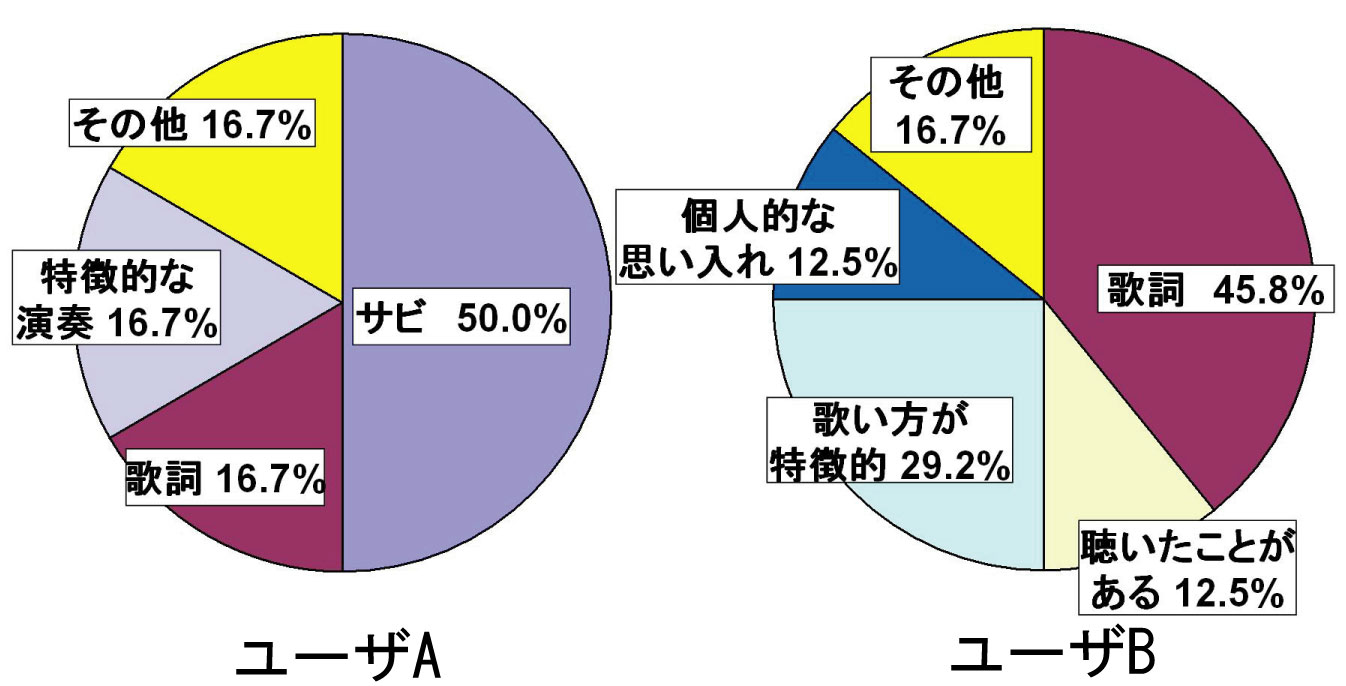
図14: ハイライトと認識する理由の偏り
ある楽曲のサビ区間と理由別のハイライトを図に示す。例えば楽曲のハイライトを試聴支援に用いる場合、サビを高い確率でハイライトと認識するユーザAにとっては、区間A、Bを中心に聴かせることが効果的であり、一方歌詞に基づきハイライトを認識するユーザBにとっては区間Cを中心に試聴を促すことが効果的であると考えられる。
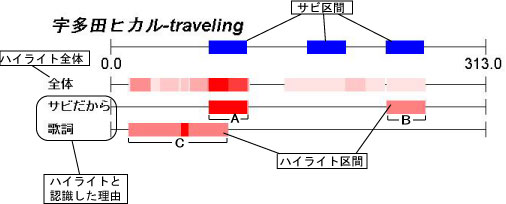
図15: サビ区間とハイライトの分布例
このように、個人に適応する応用を実現するためには楽曲の特性に加えて個人の特性を扱うことが重要であることが分かる。本実験により、音楽アノテーションシステムを用いて楽曲に対する解釈の多様性を取得することができ、また多様な解釈に基づく応用が必要であることを確認することができた。
6 関連研究
6.1 CDDB, MusicBrainz
CDDBは音楽CDに収録された楽曲情報を検索・認識するデータベースである。CDDB は音楽コンテンツそのものに対して、タイトルなどのアノテーションを付与することができる仕組みである。一方MusicBrainzはRDFを採用し、音楽・ビデオ全般のメタデータ作成を目標としている。CDDB はCDのIDを用いてCDの特定を行うのに対し、MusicBrainzでは楽曲ファイルから楽曲を特定する技術を備えている。Web上の任意のユーザによりメタデータを収集する例である。
これらの仕組みでは楽曲そのものに対するアノテーションを記述することはできるものの、楽曲の部分要素に対する詳細なアノテーションを記述することはできない。また、これらのシステムで扱うことができる情報は、楽曲に対する一意的な情報であり、人の解釈による多様性を扱うことができない。楽曲のセマンティクスを扱うためには、人の解釈による多様性を扱わなければならないため、音楽アノテーションシステムのような仕組みが必要となる。
6.2 TS-Editor
パピプーーンは、GTTMのタイムスパン簡約と演繹オブジェクト指向データベースを利用し、音楽を要約するシステムである。パピプーーンによりユーザとのインタラクションを通じて、課題曲全体の雰囲気を反映した質の高い要約を生成することができる。
音楽の高度な要約を実現するために、前処理としてユーザは専用ツールTS-Editorを用いてGTTMのタイムスパン簡約に関するアノテーションを作成する。TS-Editor はタイムスパン構造のみを記述することができるスタンドアロンのシステムであり、音楽アノテーションシステムはアノテーション定義を変更することにより様々な種類のアノテーションを取得するシステムであるため、タイムスパン簡約に関する情報を取得することも可能である。
7 おわりに
本稿では、コンテンツに対する多様な解釈を扱う必要性を指摘し、その典型例としての音楽を題材として、Web上のユーザから様々な解釈を獲得する音楽アノテーションシステムを構築した。本システムは任意のデジタルコンテンツに対するアノテーションを管理するプラットフォームであるAnnphonyをベースとして、楽曲のメディア形式と取得するアノテーションの種類により、1:楽曲そのものへのアノテーションエディタ、2:連続メディアに対するアノテーションエディタ、3:楽曲の内部構造に対するアノテーションエディタの3種類のエディタを備えている。本システムによりWeb上の多くのユーザから多様なアノテーションを取得することができる。また実際に収集された多様な解釈に関するアノテーションを利用したアプリケーションとしてプレイリスト推薦システム、楽曲検索システムを構築した。さらにWeb上のユーザからのアノテーションにより楽曲に対する多様の解釈を取得することができることを確認する実験を行い、本システムの必要性を実証した。
今後の課題としては、多様な解釈を選択する手法についての評価実験を行い、どのような指標により一つの解釈を選択することが望ましいかについて検討すること、また音楽以外のコンテンツに対しても、複数の解釈を収集し、アプリケーションに適用することなどが挙げられる。