
Video Scene Annotation Based on Web Social Activities
Abstract
We describe a mechanism for acquiring the semantics of video contents from the activities of Web communities that use a bulletin-board system and Weblog tools to discuss video scenes. Since these community activities include information valuable for video applications, we extract it as annotations. We developed a Web-based video sharing and annotation system called Synvie. We also performed an open experiment to acquire annotation data such as user comments on video scenes and scene-quoted Weblog entries and to evaluate our system. We havealso developed a tag-based system for retrieving video scenes that is based on annotations accumulated in this open experiment.
1 Introduction
The amount of multimedia content on the Web has been increasing explosively in recent years as more and more video and music clips are being posted and shared by not only commercial interests but also ordinary users. At the same time, the influence of users and Web communities has been increasing as a result of the appearance of Web communication tools such as Weblogs, social networking services, Wikies. There are some already-existing video sharing systems capable of video editing functionality such as motionbox.com, jumpcut.com, and kaltura.com. Although these systems allow users to edit and share videos for communications, however, they lack of functionality for recognizing the content of videos. There is therefore a need for platforms and tools that help users post, manage, and search for video clips.
Applications summarizing videos or retrieving scenes from them must acquire meta-information about the contents of those videos. Here we call this information annotation , and it can be done by extracting keywords related to the contents. Previous studies either used an automatic method in which metadata was extracted by using image-recognition and voice-recognition technologies or they used a semiautomatic method in which expert annotators associated video contents with high-quality annotation data by using annotation tools for describing MPEG-7 . Accuracy of automatic recognition of the content of nonexpert-created videos is still not high because these contents may include noise, indistinct voices, and blurred or out-of-focus images . Automatic recognition technologies are therefore not necessarily effective with nonexpert-created videos. Another problem with audiovisual content created by nonexpert users is that it is not cost-effective to have experts using semiautomatic annotation tools associate all of it with detailed annotations.
We propose a new solution for these problems. It is based on social activities, especially user comments and Weblog authoring, about the content of video clips on the Web. We developed a mechanism that helps users of online bulletin-board-type communications associate video scenes with user comments, and we developed a mechanism that helps users of Weblog-type communications generate Weblog entries that quote video scenes. We have also developed a system that can automatically extract deep-content-related information about video contents as annotations. We will demonstrate that the cost of the proposed system is low and that the system is robust with respect to quality of the automatic pattern recognition used.
We developed a mechanism that helps users of online bulletin-board-type communications associate video scenes with user comments, and we developed a mechanism that helps users of Weblog-type communications generate Weblog entries that quote video scenes. We have also developed a system that can automatically extract deep-content-related information about video contents as annotations. We will demonstrate that the cost of the proposed system is low and that the system is robust with respect to quality of the automatic pattern recognition used.
This paper has eight sections. Section 2 describes related work. Section 3 describes the architecture of our system, and Section 4 describes the methods for commenting on and quoting video scenes. Section 5 describes the automatic extraction of tags from text messages included in annotations and describes the semiautomatic screening of those tags. Section 6 describes our public experiments and their results, and Section 7 shows how the information extracted as annotations can be used to retrieve video scenes. Section 8 concludes this paper and mentions future work.
2 Related Work
There exists a plethora of video sharing and video editing services on the Web.
Some video sharing services, such as YouTube ( http://www.youtube.com/ ), already offer functions for embedding video contents in Weblogs and commenting on them. Bulletin-board-type communications that comment on contents and embed them in Weblog entries are used every day. There exists also some Web services that allow users to edit and share videos easily, such as motionbox.com, jumpcut.com, and kaltura.com. Because the aim of these systems is to support communications by sharing videos, they does not have a mechanism for video annotation in order to recognize content of videos. We may regard the contents of these communications as annotations associated with the video contents, but because these annotations are for the whole video they cannot be used to retrieve only part of the contents. They therefore cannot be used to retrieve video scenes.
In order to recognize content of videos or images, there exists some Web annotation systems such as WebEVA and Google Image Labeler. IBM Efficient Video Annotation (WebEVA) System is a Web-based system that has a mechanism to annotate some concepts on large collections of image and video contents collaboratively in order to make a TRECVID ground truth. Many users evaluate the relation between a concept and a video by associating the following tags with each relation: positive, negative, ignore, and skip. When many users evaluate the same content at the same time, there may of course be contradictory evaluations.
The ESP Game and Google Image Labeler ( http://images.google.com/imagelabeler/ ) are a mechanism that enables users to add tags to an image in a manner that users consider to be a form of entertainment. It is an online contest that allows you to label random images and help improve the quality of image search results. It is a very clever mechanism that requires minimal efforts and provides entertainment. Tags acquired from this mechanism are used for technical improvement of content-based retrieval of images.
Because the aim of these annotation systems are to create annotations and applications, therefore, the aim of them are not to support communications. So we propose another level of content-annotations in video by combining the best from video editing systems and annotations systems on the Web.
On the other hand, there exists a lot of Weblog sites which have a mechanism to deliver Web articles and archive them efficiently. Because a Weblog supports many epoch-making standards such as permalink , trackback, and web feed, Weblog sites are easy to treat for not only humans but also machines. A permalink is a URL that points to a specific content and remains unchanged indefinitely. Web feed is a strcutured XML data format of Web entries and is readable for machines. By collecting Web feeds, they are useful for some applications such as RSS Reader and Weblog Search. Moreover, trackback exists as a mechanism of the quotation with creating a reverse-link automatically. By combining these mechanisms, multiple Weblog sites and tools cooperate mutually.
3 Social Content Framework
No other video sharing services support social activities on the Web such as ordinary users' annotation and quotation on finier elements (i.e., scenes and frames). A new user-friendly video annotation system that enables any users to refer to any fragments of online videos is required. We therefore designed one in which video contents are handled by referring to a Weblog framework that produces positive results in the management, distribution, and machine-processing of HTML contents.
3.1 Learning from Weblogs
Weblogs have mechanisms, such as permalink and trackback, that tightly connect articles in different Web sites and enable users to discuss these articles by adding their own comments. Parker states that advanced applications such as video blog search and video blog feeding could be obtained by applying these mechanisms to video content. We suppose that a new Weblog mechanism with ptrermalink to video scenes and user comments on them contributes to advanced video applications such as video scene retrieval.
3.2 iVAS
We had developed an online video annotation system iVAS in our previous work as shown in Fig.. Although iVAS was originally a Web annotation tool that allows users to associate detailed content descriptions with scenes during wathing a video, it was mainly used as a communication tool that allows users to post and share users' comments and impressions. Although these comments were short and unclear, they had some valuable keywords correspond to scenes . We thought that we will be able to acquire better user comments by extending iVAS.
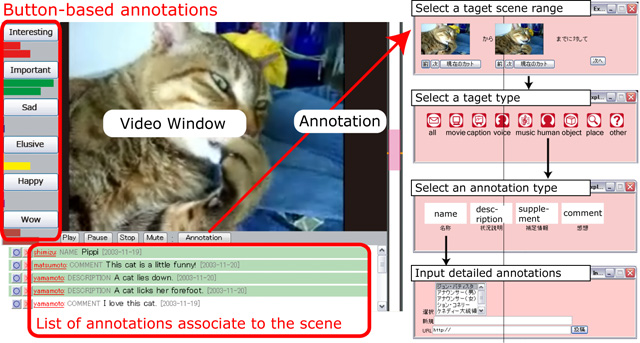
Fugure1: Interface of an online video annotation system iVAS
3.3 System Archtecture
We developed a novel video sharing system provided with scene comment and quotation interfaces called ``Synvie.'' Our objectives include acquisition of annotation data from Web users' social activities and development of annotation-based video applications. Its architecture is shown in Fig. . Annotation methods allow users to view any video, submit and view comments about any scene, and edit a Weblog entry quoting any scenes using an ordinary Web browser (described in detail in Section 4). These user comments and the linkage between comments and video scenes are stored into annotation databases. Annotation Analysis block produces tags from the accumulated annotations. (described in detail in Section 5). Application block has a tag-based video scene retrieval system (described in detail in section 7).
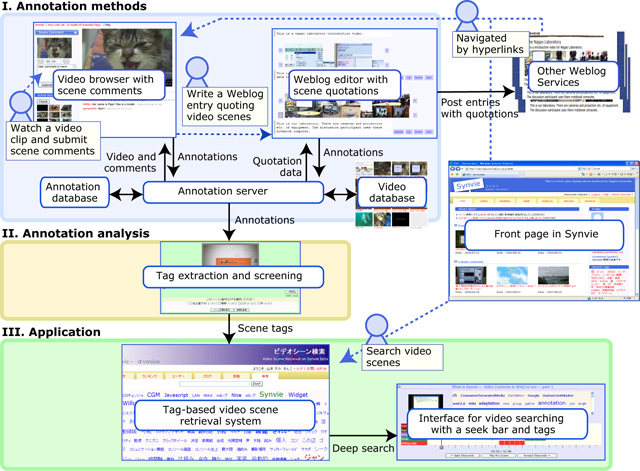
Fugure2: Architecture of the online video annotation and quotation system ``Synvie.''
3.4 Video Shots and Scenes
Video is represented by a set of shots. Shot is defined as a sequence of frames captured by the camera that do not differ from each other drastically. An interruption between two shots is called a shot transition or a cut. Since some of the video shots in blogs (i.e. person talking) can be really long, our system divides a long shot into 2s interval sub-shots, in order to better capture and summarize its semantic. This, our system combines the temporal sampling of the video with the fixed sampling to select the most representative key-frames from the video.
4 Annotation Methods
Explicit annotations (e.g., such as MPEG-7 description) are users' descriptions of the semantics, attributes, and structures of video contents. Tags and content descriptions are also explicit annotations. Implicit annotations , on the other hand, are extracted from user activities in Web social communities, such as submitting comments and writing Weblog articles. Although implicit annotation involves some analysis errors, it spares users the trouble of making annotations. By offering tools for communications and authoring Weblog entries, Synvie supports the creation of implicit annotations.
Lets define a ``content comment'' as a user's comment on entire video i.e. YouTube comment space, and ``scene comment'' a user comment on the specific video scene. And also we define a ``scene quotation'' as a mechanism that allows users to quote any video scenes in a Weblog entry.
4.1 Scene Comment
Scene-comment-type annotation allows ordinary users to associates video scenes with text messages. Because we needed an interface that helps users submit comments on any video scene easily, we simplified an annotation interface of iVAS. This interface is optimized for users' communcation.
To comment on a scene while watching a video, the user presses the button labeled ``Scene Comment'' then the video pauses and inspects the thumbnail image corresponding to the scene, as shown in Fig. . If the image is not suitable, the user presses the ``<<'' or `>>>'' button to adjust the beginning time of the scene. The thumbnail image changes accordingly, and when the user is satisfied with the beginning time he or she writes a text messages in the text input area just below the adjustment buttons and presses the ``Submit'' button. If a user wants to retrieve a watching scene later but not to write a comment on it now, then the user should press ``Check'' button to bookmark the scene. A series of the thumbnails of the scenes that were commented or checked before is displayed at the lower left of the interface as shown in Fig. .
Each scene comment is displayed when the corresponding video scene is shown, so several messages associated with the same scene can be displayed simultaneously. This interface allows users to exchange messages about video scenes with each other asynchronously.
This communication style is similar to that in which the users of online bulletin-board systems share impressions and exchange information.
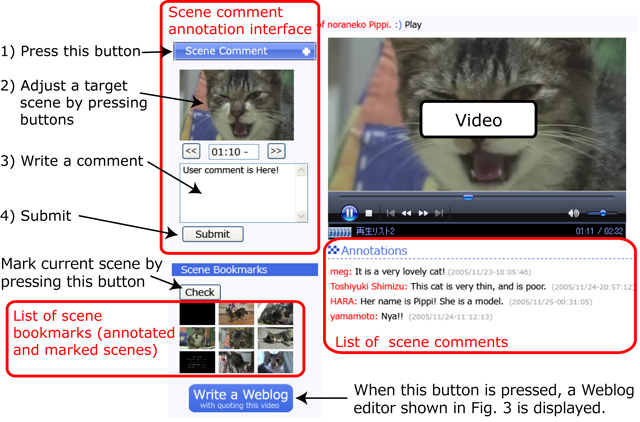
Fugure3: Interface for a scene-comment-type annotation.
4.2 Scene Quotation
Video scene quotation is a mechanism that allows users to quote any video scenes in a Weblog entry. By supporting user quotation of video scenes in a Weblog entry, we accumulate a detailed editing history of the user and acquire annotations that relate the sentence structure of the Weblog entry to the scene structure of the video content.
4.2.1 What is a Video Blog?
We call a Weblog entry that quotes video scenes a ``video blog entry.''
We expect there to be many of video blog entries discussing a video clip, and here we consider two kinds. One kind of entry the user who submits video content edits an entry that introduces that content. Users can easily indicate specific parts of the content by quoting them. This kind of entry is also useful for advertising the video clip. In the other kind of entry considered here a user who watched a video clip and liked it edits an entry introducing the clip to other users. We expect that the more popular a video clip is, the more entries there will be.
A video blog entry is composed of multiple paragraphs quoting video scenes, and each of those paragraphs contains thumbnail images of quoted video scenes, user comments, and links to scenes (Fig. ). We treat a comment as a annotation to the scenes and call this kind of annotation a ``scene quotation.''
4.2.2 Coordination with Scene Comments
A user must select scenes that he or she wants to quote, and for this selection we use the same mechanism used in making scene annotations. We assume that a user submits scene comments because those scenes are interesting to the user. They will therefore be candidate references for quotation in video blog entries, and a user can edit a video blog entry by quoting these nominated scenes.
4.2.3 Interface of Video Blog Tools
We think it is best if users can edit video blog entries by using a general Web browser, as they can when editing usual Weblog entries. Here we describe an interface for quoting video scenes that is suitable for editing a video blog entry that quotes continuous scenes as shown in Fig. . This interface enables users to select scenes, adjust their beginning and end times, and write messages longer than scene comments by going through the following steps:
-
STEP 1. Create comments about or just mark video scenes while watching video clips by using the user interface shown in Fig. .
-
STEP 2. Press ``Write a Weblog'' button shown in Fig. , then another interface for Weblog authoring shown in Fig. 4 appears. This interface shows a video blog template that is automatically generated by retrieving scene bookmarks shown in Fig. .
-
STEP 3. Browse thumbnail images of all scene paragraphs marked in Step 1 and delete unnecessary paragraphs by pressing ``Delete'' button as shown in Fig. 4.
-
STEP 4. Adjust time intervals of scenes by pressing buttons labeled ``+'' and ``-.'' as shown in Fig. 4.
-
STEP 5. Write messages in text areas just below thumbnail images of scenes, and then submit the automatically generated content in HTML format to an existing Weblog service.
Because this interface lets us modify the beginning and end time of a quoted continuous scene by expanding and contracting video shots on the media time axis, we can select video scenes more exactly than in scene comments. This interface is suitable for editing an entry that stresses the importance of the description of a video story.
Weblog entries are stored into annotation databases when they are being posted to a Weblog site.
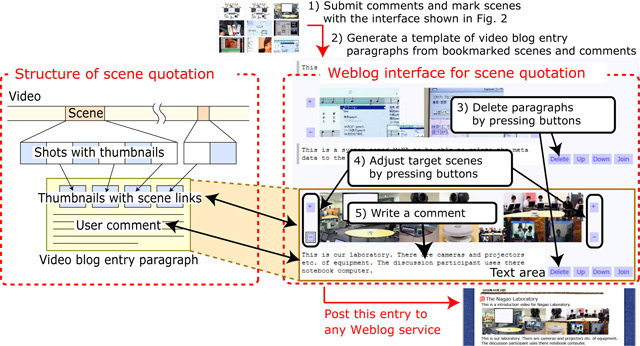
Fugure4: A strucutre and a weblog interface for scene quotation.
4.2.4 Scene Quotation as Implicit Annotation
We treat a scene quotation as an annotation. A scene quotation has two different type of annotations.
One is more correct and informative ``scene comment.'' Paragraphs in video blog entries can be considered to be annotations of quoted scenes, and their sentences will have better wording and fewer misspellings than scene comments created while watching videos because video blogs can be written more carefully.
The other type is semantic relationships between video scenes. Simultaneous quotation of continuous scenes of a video clip may specify that these video shot series has a semantic ``chunk.'' Simultaneous quotation of scenes of different video clips may clarify the semantic relationships between quoted scenes and videos. For example, if a user quoted scenes of different video clips in a video blog, the system may also find some semantic relationships between these scenes and clips. We will be able to calculate the semantic similarity of contents based on these relation in the future.
5 Annotation Analysis
Our system accumulates annotations such as scene comments and scene quotations without degrading any of the information in them. Because these annotations are only sets of user comments, it is not necessary for a machine to be able to understand them. We think that these annotations include some semantics corresponding to video scenes. To develop applications using these annotations, we must analyze annotations and convert them into machine-understandable data.
5.1 Tag Extraction
We extract from scene comments keywords that express the semantics of scenes, and we call a keyword associated with contents a ``tag.'' In particular, we call a keyword associated with scenes as a ``scene tag.'' They are extracted as follows (Fig. ). Each comment is first automatically analyzed and converted into morphemes, and then nouns other than dependent nouns, verbs other than dependent verbs, adjectives, and unknown words are extracted from these morphemes (unknown words are treated as proper nouns), by using Japanese morphological analysis system ChaSen . The basic form of each morpheme becomes a tag.
Because this method cannot generate tags that consist of compound words, we extended it to convert a series of nouns into a tag. Our system also supposes that comments are mainly written in Japanese, so if a series of alphanumeric characters like ``Web 2.0'' appears in Japanese text, the algorithm generates a tag corresponding to the series.

Fugure5: Tag extraction from comments.
5.2 Tag Screening
Automatically extracted scene tags include ineffective scene tags unrelated to scenes. Because it is hard to screen out these tags automatically, we decided to use manual screening in order to develop a practical application. So we developed a tag selection system that enables web users to select appropriate scene tags from automatically extracted tags.
Scene tags synchronzied with video scenes are displayed for users.This system shows automatically extracted scene tags to users who are watching the scenes corresponding to those tags. Each tag is shown accompanied with a check box, and the user can screen tags by selecting ones related to the present scene as shown in Fig. . The time taken to select tags is the cost of screening the tags. By getting many users to participate, we expect to make the per capita cost of screening the tags small. Because this is a routine work, we have to propose the mechanism that tags can be discriminated more efficiently.

Fugure6: Tag screening system.
6 Experimental Results
To evaluate our annotation system and accumulate a lot of annotation data about video contents, we ran a public experimental service based on our system (http://video.nagao.nuie.nagoya-u.ac.jp/, a service available only in Japanese). The service started on July 1, 2006 and we evaluated data accumulated from July 1 to October 22, 2006. We gathered 97 registered users, 94 submitted video clips, 4769 annotations, and 7318 accesses by users. Submitted video clips related to education, travel, entertainment, vehicles, animals, etc. were created by nonexpert users and their average length was 320 seconds.
We also compared the experimental service with existing video sharing services such as YouTube. YouTube-type comments correspond to our content comments. We additionally provided scene-comment-type and scene-quotation-type annotations. We confirmed the usefulness of these annotations by comparing their quantity and quality with those of the annotations generated using the other services.
6.1 Quality Classification of Annotations
Annotation data acquired by our experimental system consisted mainly of text comments created by ordinary Web users. We used them in the video scene retrieval system described in the next section. For this purpose, each message should have clearly describes the content of its corresponding video scene and had a good wording. We therefore had to evaluate characteristics of the comments. We did this by manually classifying all of the accumulated annotations into the following classes A-D by considering relevance of the description of the message to the content of the corresponding video scene.
-
A. Comment that mainly explains video scene content.
-
B. Comment that consists mainly of opinions of video scenes and includes keywords related to the scene.
-
C. Comment that discusses topics derived from the scene content.
-
D. Incomprehensible comment: text that consists of only exclamations or adjectives or text that about topics irrelevant to content, such as the video streaming quality or video capturing method.
We also categorized the text of categories A, B, and C into subcategories based on the text quality.
-
X. Comment that expresses enough content, such as text that consists of subject, predicate, and objects.
-
Y. Comment that does not express enough content.
Two evaluators also simultaneously categorized all annotations. When they disagreed, they reached an agreement by discussion.
An example of category A-X is a scene quotation about a morning glory exhibition in a photographer's Weblog entry: ``It is a morning glory of the Yashina type cut in the Nagoya style called Bon. It enables bonsai tailoring without extending the vine, and it is unique. It has a history of 100 years.'' This adequately expresses the content of the scene, and we may extract more semantics by analyzing the language. An example of category A-Y is a scene comment about the scene that an image is uploaded in a web application: ``Upload image.'' It does not adequately express the content but does include some keywords related to the scene. An example of category B-X is the scene quotation ``I wonder how this cat stayed alive under the bench. It seems so cold ...'', which expresses an opinion about a video scene. From the example of category B-Y, the scene comment ``You eat too much junk food,'' we can extract some keywords. An example of category C-X is a scene comment about the URL of the caption of the scene: ``It is a recycling toner specialty store, and it produces free CG movies and music.'' An example of category C-Y is the scene comment: ``Prof. Nagao mainly researches annotation.'' Although these scene comments do not directly express the content of the corresponding video scene, we can use them as supplementary information about this scene. Examples of category D include scene comments that alone cannot express meaning, such as ``Great!,'' ``Beautiful!,'' or a scene comment about video image quality such as ``This image is unclear. Please use Window Media Encoder to make this image clearer.''
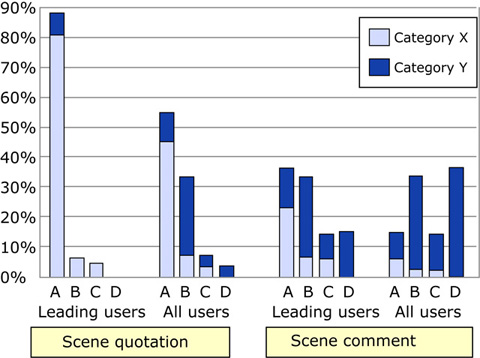
Fugure7: Annotation quality for each method.
6.2 Discussion of Quality
Most of the accumulated annotations (795) were scene comments, less than half as many (334) were scene quotations, and only 40 were content comments. We think that the amount of annotations accumulated is related to the ease of annotation. Because most of the annotations were for scene comments, we infer that scene comments are the easiest to use of these three communication tools. One might think that there would be more content comments than scene comments because scene comments are harder to make, but users who watch same scenes share context and can therefore easily submit brief comments.
Although a strict definition of annotation quality is application-dependent, here we consider a higher-quality annotation to be one that consists of grammatically correct sentences that describe the details of the semantics of the scene and includes keywords about it. We consider the quality of the four classes of annotations to be ranked in the order and the quality of subcategory X to be higher than that of subcategory Y. So we consider A-X, A-Y, and B-X annotations to be effective ones.
One can see in Fig. , that the scene quotations were better than the scene comments. 59% of the scene quotations posted by all users were effective, while only 11% of the scene comments posted by all users were effective. And only 4.8% of the scene quotations posted by all users were of the lowest quality (category D), while 36% of the scene comments posted by all users were category D annotations. This was largely because scene quotations contained fewer irrelevant and spam-like comments.
This result shows that scene quotations, which are used for Weblog entries by users who do not necessarily share a context, tended to be written more politely than scene comments, which are used for ad hoc communication among users wating a video and sharing a context. This result reflects the fact that the quality of the text in a Weblog is generally higher than the quality of the text on a bulletin board. Annotation quality therefore depended on the type of annotation.
We define as leading users the 30 percent submitting most of the annotations categorized as A. Fig. shows that 95% of the scene quotations created by leading users were effective ones, only 62% of those posted by all users were categorized as effective, and that 43% of even the scene comments posted by leading users were effective ones. Annotation quality thus depends on the characteristics of the users creating the annotations.
We can conclude that our video-scene-oriented annotation methods will gather more and higher quality information than other methods do and that the quality and quantity of the annotations will depend on whether they are scene comments (bulletin-board type) or scene quotations (Weblog type). When there are a lot of annotations we should use only the scene quotations, and when there are few annotations we need to also use the scene comments.
6.3 Discussion of Scene Tags
To evaluate tags generated by using the technique described in the previous section, we manually classified them as either effective or ineffective according to whether they were or were not closely related to the content of the corresponding scenes.% More than half (59%) of all the tags were effective ones.
More than three times as many effective tags were extracted from scene quotations: the average number of effective tags extracted from a scene quotation was 5.96, and the average number of effective tags extracted from a scene comment was 1.51. Both kinds of annotations are comments discussing scenes, but scene quotations are written in more detail and tend to be better sources of effective tags.
Evaluating the effectiveness of the tags generated automatically by the tag screening technique described in Section 5.1, we found that 59% of the tags extracted from the scene comments submitted by all users were effective ones. This may not seem to be a high percentage, but all annotations are more or less related to scenes in that the users write them while watching the content. Even those tags classified as ineffective in this study might therefore be effective for some applications.
7 Annotation-Based Application
To confirm the usefulness of annotations acquired in Synvie, we developed a tag-based scene retrieval system as based on the mechanism of a tag-cloud .
When scene tags are generated automatically from annotations, appropriate tags are not necessarily given to all scenes. And when there are not enough annotations for each video, it is hard to use conventional search techniques like the exact-matching methods.
To solve these problems, we used the tag-cloud mechanism for our video scene retrieval system. A user selects some tags from a tag-cloud composed of all scene tags for all videos, and the system displays a list of videos that include these tags. Each video has a seek bar associated with scene tags and has thumbnail images arranged along the time axis (Fig. ). When the user drags the seek bar, the system displays thumbnail images and scene tags synchronized with the seek bar. By browsing these tags and thumbnail images, the user can understand the content of the video without actually watching it. Moreover, when the user clicks an interesting-looking tag, the temporal location of the tag is displayed on the seek bar. Because users can search for target scenes by using scene tags and the temporal distribution of tags and thumbnail images, they can browse and search for scenes interactively.
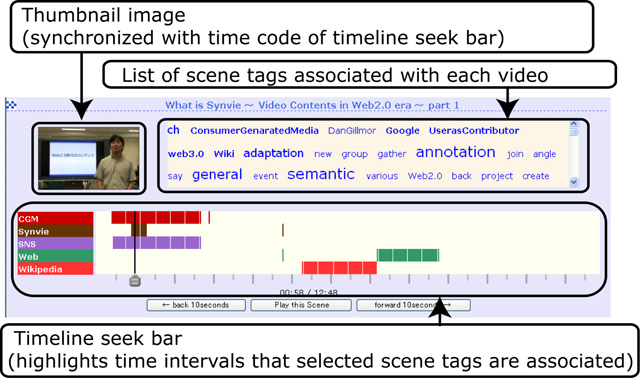
Fugure8: Interface for video searching with a seek bar and tags.
7.1 Evaluation of Scene Retrieval
We prepared α, β, and γ as data sets for a retrieval experiment. α was a data set of scene tags extracted by the automatic tag extraction method described in Section 5.1. β was a data set of scene tags screened from α by using the manual tag screening method described in Section 5.2. γ was a data set of scene tags generated by using a manual annotation tool we made for scene tagging for comparative experiments. The creation cost (total creation time per content) of α was 0 sec, that of β was 314 sec, and that of γ was 1480 sec, as shown in TABLE . The average number of scene tags was 153 in α, 55 in β, and 53 in γ. These values would of course depend on the interface used for creating or screening tags, but we used the same type of interface for each of them.
The targets were 27 videos contributed to Synvie. The average length of these videos was 349 seconds. The retrieval question consisted of a blurred thumbnail image and sentences describing the content of the answer scene. Because there was a possibility that the answer could be found easily when the retrieval question included feature keywords in the answer scene, we tried to prevent the inclusion of these keywords. We assumed the situation in which the user was searching for a target scene had an uncertain memory.
Examples of the question sentences are ``A scene in which a parent-child pair of certain animal is stopping in the middle of the road'' and ``A scene in which a certain person is snowsurfing before he slides off the track.'' The subjects (nine university students) retrieved the scene corresponding to each question by using our system, and we measured these retrieval times. They retrieved nine scenes for each of the data sets α, β, and γ.

Fugure9: Experimental results of video scene retrieval.
7.2 Discussion
In this experiment, all users were able to find the correct target scenes. The average retrieval time was 169 seconds when set α was used, 145 seconds when set β was used, and 119 seconds when set γ was used, as shown in TABLE . The difference between the retrieval times for sets α and β show that using the tag screening technique reduces retrieval time significantly.
To evaluate the cost effectiveness of automatic tag extraction, we took the tag creation time into account when comparing the retrieval times for the β and γ data sets. The average creation time was 314 seconds for the β set and 1480 seconds for the γ set. Defining cost effectiveness as how much the retrieval time was reduced per 100 seconds of creation time, we find the cost effectiveness of set γ to be 3.48 and that of set β to be 7.18. Thus, we can say a tag screening mechanism is significant that from the viewpoint of cost effectiveness.
Through these experiments, we showed that tags extracted from annotations acquired in Synvie are useful for video scene retrieval. Since experimental results depend greatly on the amount of annotation, however, detailed evaluation is a future task. We showed that the tag screening technique is useful for improving retrieval efficiency, so we must use tags appropriately considering factors such as the target video contents and retrieval frequency.
8 Conclusion
The main purpose of Synvie is to propose a novel approach to integrating video sharing, user communication, and content annotation. By associating user communications about videos with deep content of the videos, we can discover knowledge on video scenes and use it for their applications. Since their communication space should not be restricted within a single video sharing site, our scene quotation can extend them to the entire Web. Also users usually struggle with creation and selection of tags. We therefore believe that communications are nice motivation of collaborative tagging of the video scenes. To achieve our purpose, we developed mechanisms for annotating video scenes and extracting annotations from Weblog entries containing video scene quotations, and we evaluated them in public experiments. From an analysis of annotation for each annotation method, we discovered characteristic tendencies for each annotation method. These tendencies indicated that scene quotations are better qualtity than scene comments. We also developed a tag-based video scene retrieval system based on these annotation data. We thus showed that the annotation acquired from these Web communities was useful for applications such as a video scene retrieval.
There are, however, some problems that were not resolved in this paper. Currently, we extract only tags. We intend to extract more semantic information by applying the concept of ontology to scene tags or using more advanced language analysis. Using these mechanisms, we can also construct semantic hypermedia networks based on quotations of video scenes. In these networks comprising Weblog entries and video contents, the granularity of hyperlinks can be refined from units of videos and Weblog entries to units of scenes and paragraphs, the scale of network links can be extended from communities within a single site to communities on the whole Web, and also links between contents can be expanded from hyperlinks for navigation to semantic links based on the meanings of quotations. We therefore think that this general method for extracting knowledge about multimedia contents from the activities of communities can provide data for various applications.