
ディスカッションリマインダによる会議における議論の活性化に関する研究
はじめに
会社や研究室など様々な場所で、会社の経営方針や研究の進捗報告など議論するための会議が開かれている。これは会議で発表を行い議論を展開することで、自分一人では気付けなかった問題やアイディアを発見できる重要性に着目しているためである。
また、会議の様子をテキストや音声、映像などで記録することの重要性も高まっている。一般に、対面による会話を主体とした会議の内容は揮発性が高く再利用が困難であったが、それらをテキストや音声、映像等で記録し、検索できる状態で保存することにより再利用を可能にすることができる。会議の様子を振り返ることは、当時の議論中では気付けなかった事柄を再発見できたり、当時の発表内容を再利用して次の発表資料を作成するなど、個々人の研究活動に大きく貢献するものとなっている。
このような有用性に着目し、筆者の所属する研究室でも、ディスカッションマイニングと呼ばれる、人間同士の知識交換の場であるミーティング活動から実世界情報を獲得し、それらを半自動的に構造化することによって、再利用可能な知識を抽出する技術の研究・開発を行っている。ディスカッションマイニングでは、数台のカメラやマイクによってミーティングの様子を映像・音声情報として自動的に記録し、さらに発言を行うときには専用のデバイスを人間が操作して、発言時間などのインデックス情報や発言間の関連などの意味情報の付与を行うことによって再利用可能な議事録の作成を行っている。
ディスカッションマイニングがこのような環境で運用されている理由の一つは、議論を活性化するという目的が存在するためである。活発な議論を行うことは、より多くの有益な意見やアイディアを生み出し、結果として個々人の研究活動の生産性を高めると考えている。
では、そもそも議論を活性化するということはどういうことだろうか。本研究において議論の活性化とはさまざまな理由で停滞している議論を以下のように変えることであると考える。
-
参加者が建設的な意見を出す
-
全員が黙ってしまうような状態に陥らず、常に誰かが発言している
-
発言者が偏らず、全員が何らかの発言を行う
まず、1番目の項目については議論スキルという観点と知識量という観点からのアプローチによる議論の活性化が考えられる。このうち議論スキルは参加者自身の議論経験に依存するところが多いためシステムからの支援は比較的困難であると判断し、本研究では知識量という観点から議論の活性化を目指す。次に2番目、3番目の項目については単に参加者のモチベーションによるところもあるが、それ以外の要因も含まれているように考えられる。すなわちシステムから何らかのアプローチを行い会議の参加者全員が議論に参加し発言を行い易くすることで、結果として議論の活性化につながるのではないかと考えた。
ここで議論が停滞する原因の一つは、参加者全員が発表に関して同じレベルの知識を持ち合わせていないことに起因するのではないかと考える。発表に関する背景情報や過去の研究情報、あるいは過去に行われた議論内容といった知識を十分に持つ人(知識レベルが高い人)は発表内容を容易に理解できるため、議論参加へのモチベーションも高いと予測される。しかし一方で発表に関して十分な知識を持ち合わせていない人(知識レベルの低い人)は説明されない研究の背景やその他の知識に関して、知識レベルの高い人と差が生じてしまう。これにより発表内容を十分に理解できず、発言を行いにくい状況が発生すると予測される。そのため、発表に関する知識レベルが高くない人に対しシステムが発表内容を補足するような内容を提示することによって、知識レベルを底上げし、会議参加者全員の知識レベルを均一化する必要がある。
そこで本研究では参加者の知識レベルを高める手法として知識の共有化を提案する。本来は会議を開始する前に参加者全員が発表に関する知識をあらかじめ共有し、その上で議論に臨むことが望ましい。しかし、参加者全員が発表ごとに知識を共有していては非効率的である。多くの場合、発表者が発表中に必要な情報をその都度提示することで負担を軽減している。しかし、先にも述べたように発表内で説明されていない情報を獲得することは困難である。そこで発表に関し知識レベルの低い人が知識レベルの高い人と前提となる知識を共有することで、議論に参加するために必要十分な知識を獲得し、効率的に知識レベルを高めることが可能となる。
ここで、実際のディスカッションマイニングでの会議の様子に焦点を当てる。ディスカッションマイニングでは、現在進行中の議論を整理し視覚化することで議論が活性化できるという考えのもと、各発言間の構造情報を表示したり、現在行われている発言の内容を表示したりするインタフェースが提供されている。しかし、これらの支援はあくまで行われた議論の整理を促すものであり、議論を行ったり理解するために必要な知識そのものを補う支援ではない。そのため、ディスカッションマイニングにおいて知識の共有化を可能にし、議論に参加するために必要な知識を補うことのできるシステムが必要であると考えた。
ところで知識の共有化を実現する際には、二つの要件が存在すると考えている。一つは、共有される情報はより正確で詳細なものが望ましいということである。あいまいで不十分な情報を共有した場合、知識レベルの差は改善されず、結果として議論に参加できないどころか、誤解が生じてかえって議論を混乱させる要因になりかねない。そのため、システムには参加者が議論の内容を詳細に覚えていなくても知識の共有が可能となる情報提示機能が必要となる。
もう一つは本来の議論を妨げないということである。知識の共有化は会議中に行う場合、肝心の議論が中断してしまう。議論に参加するための知識を補うために議論そのものを妨げては意味がない。そのため本来行うべき議論をできる限り妨げないよう効率的に知識を共有する必要がある。
本研究では以上の二つの要件を満たし、知識の共有化を可能にするシステムであるディスカッションリマインダシステムを、ディスカッションマイニングシステムを拡張することで実現した。本システムでは、上記の二つの要件に対しそれぞれ以下に示す手法を採用することで会議中に過去に行われた議論の詳細な内容を振り返ること(回顧すること)を可能にし、知識の共有化を実現する。
まず前者の要件である、より正確で詳細な情報を獲得する方法についてである。本システムでは、ディスカッションマイニングによって記録されている映像情報に着目した。ディスカッションマイニングによって記録されている発言や議論に関する情報は、書記によって入力されたテキスト情報とカメラで記録されたビデオ情報がある。書記テキストからの情報獲得は発言内容が要約されており、短時間で内容を知ることができる。さらに指示語等が書き起こされている場合、音声だけではわからない情報も獲得できる。しかし、書記テキストのみからの情報獲得だけでは、人手による入力のためあいまいさが含まれる点で不十分である。一方でビデオ映像からの情報獲得は実際に行われた発言そのものの記録のため正確な情報が獲得できる。しかし実際の会議の様子を閲覧するため時間がかかるといった問題がある。そこでテキスト情報、音声・映像情報を複合的に取り扱うことで正確で詳細な議論内容把握を支援する。特に再生するビデオとしてスクリーンの映像を使用することで、音声だけでは解決困難な指示語の問題や、さらにはスライド上のアニメーションやポインタの軌跡も同時に閲覧することが可能となる。そして映像と同時に書記テキストも表示することで、音声のみでは聞き取り難い発言内容を視覚的に補う。このようにスクリーンビデオとテキスト情報を提示することで、過去の議論内容を正確かつ詳細に理解することを支援する。
次に後者の要件である、本来の議論を妨げないように回顧を行う方法についてである。本システムでは、ディスカッションマイニングによって記録されている様々なメタデータを効果的に提示することで、効率的に回顧を行う方法を確立する。大量の議事録から目的の議事録のみを参照するには、はじめに検索を行い関連性の高い議事録に候補を絞り込む必要がある。議事録には発表の日時や発表者情報をはじめ、当時行われた発言の内容やその発言者名といった詳細なデータが記録されている。そこでこれらの情報を検索のクエリとして用いて、条件に一致する議事録のみを抽出し、参加者に提示する。
次に一つの議事録を選択したとき、その中から目的となる情報を高速に見つけ出す必要がある。なお、議事録内から必要な情報だけを短時間で閲覧していく行為を本研究ではザッピングと呼ぶ。一つの議事録に含まれる発言の数は平均24発言程度あり、最大では94発言含まれる議事録も存在する。そのため段階的に発言をザッピングする必要がある。そこでまず議論に関係するスライドを見つけることにより絞り込みを行う。会議中に行われる議論は、スライドとそれに対する発表者の説明をもとに行われるため、各発言や議論はその時表示されていたスライドと関連性が強いと考えられる。次にスライドの選択によって絞られた発言から必要な部分だけを高速に見つけ出すことを支援する。発言のザッピングに利用する情報として以下の二つを用意した。一つは各発言における構造的関係を表す議論構造情報である。議論構造は各発言間の関係を木構造としてとらえることで、議論内容の理解を促す。この情報を視覚的に提示することで各発言間の関係を直感的に把握できる。もう一つは各発言に付与されているメタデータである。議事録において各発言には発言者名や書記の入力したテキストといった情報が記録されている。これらの情報を上記の議論構造とともに表示することで高速なザッピングを支援する。
また、選択した議事録がそもそも間違っていた場合を考える必要がある。本システムでは議事録情報とともに議事録の検索結果の一覧も同時に表示することで議事録のザッピングを効率的に行う。従来の検索エンジンでは、選択したコンテンツが目的のコンテンツでなかった場合、ほとんどが検索結果一覧へと画面を遷移させる。しかし最近ではAjaxの発展によりGoogle AJAX Search APIといった、専用のAPIをブログ等に埋め込むことで、画面遷移を行わない効率的な情報検索が可能となってきている。そこで本システムでは、議事録情報と同時に検索結果一覧の情報も表示することで、画面遷移を無くし、探索の高速化を図る。
以上のような手法を採用したシステムを作成し、知識の共有化を可能にすることで議論の活性化を図る。
以下に本論文の構成を示す。第2章では議論の活性化について詳細に述べる。第3章では本研究が提供するシステムであるディスカッションリマインダの有用性やその特徴について詳細に述べる。第4章ではディスカッションリマインダによる議論の活性化について詳細に述べる。第5章では関連研究について紹介し、最後の第6章ではまとめと今後の課題について述べる。
1 会議における知識の共有と議論の活性化
本章ではまず議論の活性化について述べる。その後、本研究室において先行的に研究されているディスカッションマイニングについて述べる。
1.1 議論の活性化とは
本節ではまず本研究における議論の活性化の定義について述べる。その後、議論の活性化を行うために本研究で取り上げる知識の共有について述べる。その後会議中での知識共有における要件について述べる。
1.1.1 議論の活性化の定義
本研究では、議論を活性化させるということは停滞している議論を以下のように変えることであると定義する。
-
参加者が建設的な意見を出す
-
全員が黙ってしまうような状態に陥らず、常に誰かが発言している
-
発言者が偏らず、全員が何らかの発言を行う
まず、1番目の課題は二つの観点からのアプローチが考えられる。一つは議論スキルに関するアプローチである。しかし議論スキルは参加者自身のこれまでの議論経験に依存する面が大きいと考えられる。そのためツールからのアプローチは困難と思われる。もう一つは知識に関するアプローチである。建設的な意見を出すためにはその土台となる十分な知識が必要となる。この知識に関しては何らかの情報提示を行う、というアプローチがあると考えた。次に2番目、3番目の課題については単に参加者のモチベーションによるところもあるが、それ以外の要因も含まれているように考えられる。すなわちシステムから何らかのアプローチを行い会議の参加者全員が議論に参加し発言を行い易くすることで、結果として議論の活性化につながるのではないかと考えた。
議論において参加者が増加することは多くの視点からの意見やアイディアが発生するだけでなく、特に異なるプロジェクトに属する人が議論に参加することで多角的視点からの新規性の高い意見やアイディアが期待できる。そこで本研究では議論への参加人数を増加させるための手段を考え、可能な限りで実現する。
1.1.2 議論の活性化における知識共有の必要性
議論が停滞する原因を考えたとき、そのひとつは参加者の持ち合わせている知識のレベルに差があることが原因ではないかと考える。発表者と同一のプロジェクトの参加者や発表者の研究に長く携わっている人は、発表内で説明されないような研究の背景や目的、あるいは過去に存在する類似した研究に関する情報といった多くの知識を持ち合わせ、知識レベルが高い状態で会議に参加している。そのため発表内容を容易に理解でき、結果として発表における発言数も多いと予測される。さらには十分な知識をもとに、建設的な発言を行えるのではないかと予測する。
しかし一方で発表者と異なるプロジェクトの参加者や、過去行われた発表を知らない参加者は発表内で説明される内容が知識の多くを占め、説明されない研究の背景やその他の知識において、知識レベルの高い人と差が生じてしまう。これにより発表内容を十分に理解できず発言がしにくくなり、結果として発言を敬遠すると予測される。
以下にこれらの考えを裏付けるために行った調査について述べる。
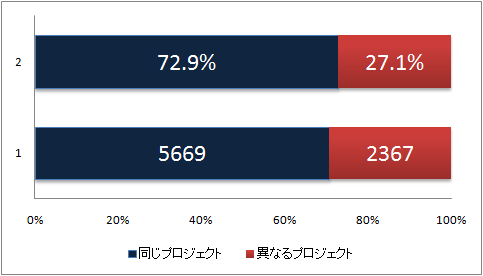
図1.1: プロジェクトと発言数の関係
まず、発表者が所属するプロジェクトとの差異が発言数に影響するかどうかを調査した。調査は過去2年間の発表を対象として行った。その結果を図に示す。調査結果は、発表者と同一のプロジェクトメンバーが行った発言と、異なるプロジェクトメンバーが行った発言の比率を表している。ここから一つの発表で行われる全発言の約7割が同一のプロジェクトメンバーが行っており、異なるプロジェクトメンバーの発言は3割程度であることがわかった。すなわち同一のプロジェクトに属することで発表に対し多くの知識を持つ人は、その分容易に発表を理解し発言を行えるが、異なるプロジェクトメンバーは発言を敬遠しているといえる。このことから、特に発表者と異なるプロジェクトメンバーに対する支援が必要であるといえる。
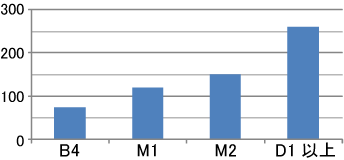
図1.2: 学年別の年間平均発言数
次に、研究に携わっている時間が発言数に影響を及ぼすか調査を行った。その結果を図に示す。調査結果は過去2年間の発表を対象として、学年別の平均年間発言数を表している。ここから学年が上がるにつれ、年間の発言数が増加する傾向にあることがわかった。またドクターの学生と学部4年生との発言数には約3倍もの差が生じていることがわかった。すなわち蓄積してきた知識の差が発言数に大きく影響していることがわかる。これらのことから、特に学部4年生のように十分に知識を蓄積していない参加者に対する支援が必要であるといえる。
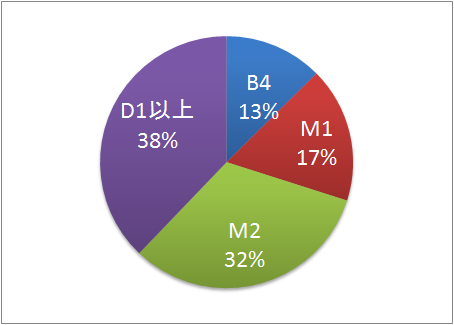
図1.3: 学年別の年間平均被マーキング発言数
最後に研究に携わっている時間と建設的な発言数の関係について調査した。調査には2.2.1節で述べるディスカッションマイニングによって記録されたマーキング情報(参加者が発言に対し検索時の目印として付ける情報)を用いた。マーキングがなされた発言は、マーキングされていない発言と比べ情報的価値が高いと考え、建設的な発言とした。マーキングされた発言の数と学年別の関係を図に記す。ここから上記の発言数と同様に学年が上がるにつれ、マーキング数が増加する傾向にあることがわかった。すなわち蓄積した知識の差は、発言数だけでなく建設的な発言の数にも影響してくるといえる。このことから知識レベルを高めることで、建設的な発言の増加が期待できる。
以上のような調査から、知識レベルが高くない人に対し何らかの支援を行い知識レベルを底上げし、会議参加者全員の知識レベルを均一化する必要があると考える。さらに知識レベルが高くなることで、建設的な発言の増加も期待できるであろう。そこで本研究では参加者の知識レベルを高める手法として知識の共有化を行う。
1.1.3 知識共有の要件
本節では実際に会議中に知識の共有化を行う際の要件について述べる。
会議中に知識の共有化を行う際に必要な要件は以下の二つあると考える。
-
より正確で詳細な情報を共有する
-
本来の議論をできるだけ妨げない
まず、前者の要件について述べる。知識の共有は議論参加の前提知識を共有する。一般にこのような知識共有は口頭で頻繁に行われている。しかし口頭での知識共有は多くが知識を与える側の記憶に頼り、その内容が不正確な可能性がある。また、説明される内容も人間の記憶を頼るため詳細な内容まで網羅することは困難である。このように不正確で不十分な知識を共有することはかえって議論を混乱させるおそれがある。それゆえに共有化される知識はより正確で、より詳細な情報が望ましい。
次に後者の要件について述べる。知識の共有は活発な議論を行う上で必要だが、同時に会議の時間を圧迫するものである。多くの会議は限られた時間の中で行わなければならない。そのため知識共有に多くの時間をかければその分議論を行える時間が減少する。それゆえに知識共有は、議論の妨げにならないようできるだけ短時間で効率的に行うことが望ましい。
1.2 会議における知識共有支援
筆者の所属する研究室ではディスカッションマイニングと呼ばれる、人間同士の知識交換の場であるミーティング活動から実世界情報を獲得し、それらを半自動的に構造化することによって、再利用可能な知識を抽出する技術の研究がなされている。ディスカッションマイニングでは何らかの意思決定を目的とした会議ではなく、発表を主体とし、議論を行う会議を対象としている。そして対象となる会議ではモデレータとなる発表者、その発表を聴き意見を述べる参加者、そして会議の記録を行う書記がいる。また、発表者は発表資料としてスライドをプロジェクタで投影し発表を行うことを前提としている。そして会議中の議論内容を半自動的に記録し、記録されたテキスト主体の議事録に、映像・音声情報やメタデータを組み合わせ、オンラインで閲覧可能にしたコンテンツを会議コンテンツと呼ぶ。
1.2.1 ディスカッションマイニング
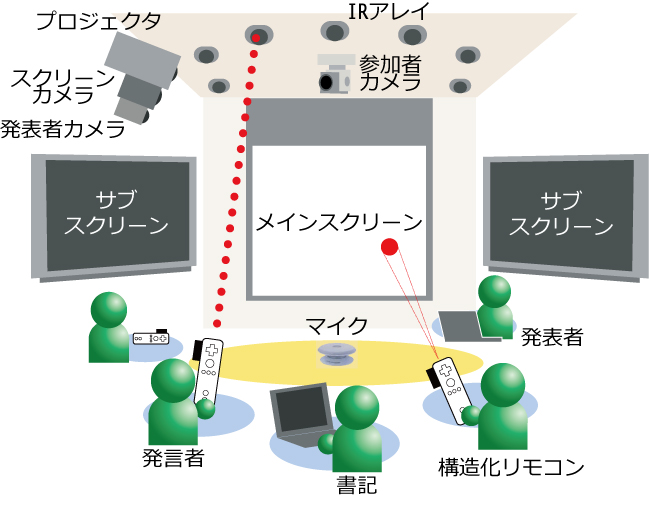
図1.4: ディスカッションルーム
会議を行うミーティングルームは図のような空間を想定している。ミーティングルームには音声を記録するためのマイクが設置されている。会議の詳細な文脈を記録するために1台のパンチルトカメラが設置され、またスライドを投影するスクリーンを記録するために固定カメラが1台、そして発表者の様子を記録するために固定カメラが1台設置されている。また、ディスカッションマイニングではミーティングルームの他に議事録の作成を行うためのサーバが用意されている。
発表者は発表に用いるスライドをブラウザベースの専用ツールを用いてサーバにアップロードする。アップロードする際には発表者の氏名やプロジェクト名、発表タイプ(その発表が個人研究の発表か、あるいはプロジェクト報告なのかといった発表の種類を指す)といった発表のカテゴリを選択する。アップロードが終了すると会議が開始され、開始時刻がサーバに送信される。発表者は専用ツール、あるいは構造化リモコンと呼ばれる専用のデバイス(図)を用いてスライド操作を行う。またスライド以外の資料(デモやWebの参照)を用いてプレゼンテーションを進める場合は、資料を追加することも可能である。

図1.5: 構造化リモコン

図1.6: 発言時の様子
また、発言者や発言時間、後述する発言タイプといった発言情報を記録するためにも構造化リモコンを用いる。構造化リモコンには赤外線を受信するためのデコーダが装着されている。受信する赤外線信号には発言者の位置情報が含まれており、構造化リモコンがどこに向けられているかを判別する。また、この構造化リモコンは常にBluetoothを通じてリモコンに記憶されている参加者のIDやボタン情報を送信している。そして参加者は発言を行うとき、図のように構造化リモコンを上げて発言を行う。このとき構造化リモコンは天井の位置情報を表す赤外線を発するLEDから信号を受信する。そして受信した赤外線信号に含まれる位置情報をもとにカメラの向きを決定し、Bluetoothを通じて情報が送信される。そしてリモコンをあげたときの角度(ひねり)により発言の種類(以降、発言タイプ)が決定する。議事録サーバには、これらの情報に加えて受信した時刻が送信・記録される。また、発言の終了時刻を記録する際にも構造化リモコンを用いる。
ディスカッションマイニングでは、発言者の発言タイプを議事録構造化の視点から「導入」、および「継続」の二つに大きく分類する。議論において、現在の発言が新しい話題の起点となると判断した発言を導入発言、直前の発言(あるいはいくつか前の発言)を受けてなされる発言を継続発言とする。そして一つの導入発言を起点として、それに対する継続発言の連続で構成される一連の議論を議論セグメントと呼んでいる。
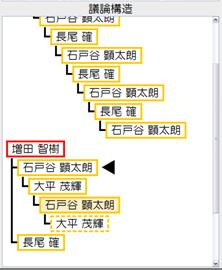
図1.7: 議論構造
そして参加者の発言で随時作成される議論構造は図のような木構造でサブスクリーン上に可視化される。この議論構造は終了した発言の構造だけでなく、現在進行中の発言や予約されている発言の一時的な構造も表示される。また、リモコンを上げるタイミングを誤ったり、他の人の発言を聞く前に発言を予約したが、発言を聞いた後に言うべき内容が変わった場合 、構造化リモコンを用いて、議論構造における自身の発言位置(どの発言に対する継続かを表す木構造上の位置)を、より適切な位置に変更できる。また、自身の発言を保留することによって、次の発言者に発言権を譲ることも可能である。これらの変更は随時議論構造に反映され、より発言者の意図に沿った議論構造が記録される。
また、構造化リモコンにはポインタ機能、アンダーライン機能、そして画面内オブジェクトの選択機能と呼ばれる機能がある。ポインタ機能は、リモコンをメインスクリーンに向けることでレーザーポインタのようにポインタをスクリーン上に表示する機能である。従来のレーザーポインタとは異なり、スライド上に線や図形を描くことができる。アンダーライン機能は、スライド中のテキストに対し、下線を描画する機能である。さらに下線部のテキストの取得が可能である。これは各スライドでOCR(Optical Character Recognition)されたテキストに対し、取得された文字や位置情報をもとに下線を引いた文字列や下線部の位置を判別、決定している。これらの操作ログは逐次操作者情報、および時間情報と共に記録される。画面内オブジェクトの選択機能は、サブスクリーンに表示されている発表スライドのサムネイルを選択し、メインスクリーンのスライドを切り替えることができる機能である。これにより発言権を持つ参加者が任意に表示スライドを切り替えることができる。
加えて、会議中の発表者の発言や参加者の発言に対して、随時自分のスタンスを入力できるボタン機能がある。スタンスに応じたボタンを押下することでサーバに自分のスタンスの情報を送信する。本システムでは参加者のスタンスを「同意(Agree)」、「非同意(Disagree)」としている。加えて会議終了後、議事録を閲覧する際、検索しやすくするための目印として発言に対しマーキングを行う機能もある。
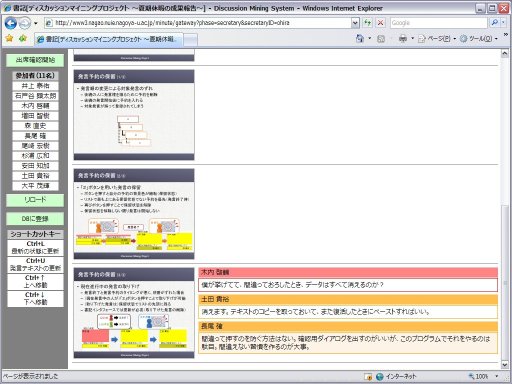
図1.8: 書記用インタフェース
書記は図に示されるWebブラウザベースの専用ツールを用いて議論の構造化と発言内容の記録を行う。書記ツールは前述の構造化リモコンと連動しており、参加者によって入力された情報が随時追加されていく。参加者がリモコンを上げることで情報を発信すると、書記ツールに発言者と発言タイプが付与されたノードが生成される。書記はこのノードを選択し、テキストを入力することで発言の内容を記録することができる。
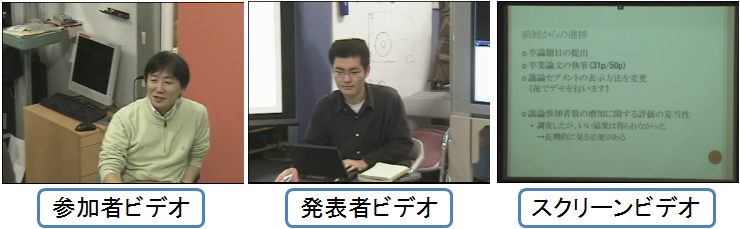
図1.9: 記録されているビデオ映像
またカメラやマイクで会議の詳細な文脈を記録した音声・映像はMPEG-4形式で映像・音声データベースに保存される。特にカメラで記録している映像は閲覧する環境や閲覧者の要求へ柔軟に対応するため、参加者ビデオ、発表者ビデオ、スクリーンビデオの3種類がある(図)。そして発表者が作成したスライド情報、書記が入力したテキスト、参加者のデバイスを使って獲得したメタデータは議事録XMLとしてXMLデータベースに記録される。
1.2.2 ディスカッションマイニングによる知識共有化支援
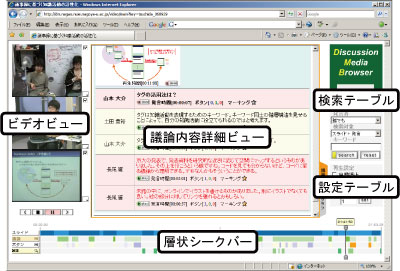
図1.10: ディスカッションメディアブラウザ
ディスカッションマイニングでは知識共有の観点から見てどこまで支援できているのであろうか。ここでの知識は議論そのものを行うために必要な前提となる知識を対象としている。
ディスカッションマイニングによって生成された会議コンテンツは図に示すようなディスカッションメディアブラウザと呼ばれる、Webブラウザベースのインタフェースによって閲覧することができる。会議参加者は各々が会議に臨む際、事前に過去の発表を閲覧し知識を獲得することで間接的な知識共有が行える。また、ディスカッションマイニングでは会議参加者全員に会議コンテンツの閲覧を促すため、新規に会議コンテンツが追加された場合、メールによるアナウンスが行われている。会議参加者は普段からディスカッションメディアブラウザによって過去の発表を閲覧し、知識を蓄積していく。
しかしこのような工夫を行っても参加者個人の行動に依存する面は大きく、全員が同じ知識レベルで会議に臨むことは困難である。例えば人によって同じ会議コンテンツを閲覧しても重要だと考える議論は異なり、結果として閲覧する議論も異なってくるであろう。そのため会議前に全員の知識レベルを同じ状態にすることは困難であると思われる。
そこで本研究では会議中における臨機応変な知識の共有化を目指す。会議中に知識共有を行うことには二つのメリットが考えられる。一つ目は会議以前に行う間接的な知識共有とは異なり、全員で同じ情報を同時に共有する直接的な知識共有が可能な点である。こうすることで事前に議論を閲覧し、必要な知識を獲得しているかどうかに関係なく、現在の議論に必要な知識を獲得できる。二つ目は獲得すべき情報の指示が直接行える点である。事前の会議コンテンツ閲覧では個人の判断で議論を閲覧するため、現在の議論に必要な知識をあらかじめ獲得することは難しい。しかし会議中に知識共有を行うことは、共有化すべき情報を的確に指示することができるため、ピンポイントな知識の獲得を期待できる。
2 ディスカッションリマインダ
ディスカッションリマインダとは、会議中に参加者全員で過去の発言や議論を振り返る(回顧する)ことである。本章では過去の議論を回顧することの有用性について述べたのち、ディスカッションリマインダシステムについて詳細に述べる。
2.1 会議中に議論内容を回顧することの有用性
本節ではディスカッションマイニングシステムを用いて会議参加者全員で過去の議論を回顧する有用性について触れる。
2.1.1 同じ議論を繰り返すことの回避
会議に参加する際、全員が同じ知識レベルで議論を行うことにより活発な議論展開が期待できる。。しかし現状として自分自身が所属していないプロジェクトに対してはその背景や目的といった情報が十分に与えられない傾向がある。そのため、会議の場において発表者と同一のプロジェクトに所属していない参加者たちが、意図せずして過去と類似した議論を行ってしまうケースが存在する。このとき過去に類似した議論が存在するにも関わらず、それを回顧せず議論を続けることで、本来行うべき本質的な議論から遠ざかってしまう可能性がある。
そこで、発表者あるいは同一のプロジェクトの人が、過去に類似した議論が存在していると気づいた時点で回顧を行うよう促す。そうすることで、会議中でも過去の議論の経緯や結果を参照することができる。それによって回顧した議論を今行うべきかどうかを判断でき、本来行うべき議論から遠ざかってしまうことを未然に防ぐ。もし本来行うべき議論と関連性が深く、過去の議論を踏まえて現在の議論を行うべきと判断した場合、次節で述べるように過去の議論をもとに、現在の議論を展開できる。
2.1.2 過去の議論に基づく現在の議論の展開
我々の会議は、発表者がスライドを用いて発表し、参加者はいつでも気になった点があればそれに対して質問やコメントを行い、発表者はそれに答え、再びそれに対し参加者がコメントや質問を行う、といった一連の行動の連続で構成されている。そのため、導入発言は発表のスライドや発表に関連したものがなされる。
しかし、それに続く継続発言のすべてが必ずしも現在のスライドや発表に関連したものとは限らない。それは現在の発表が、前回、あるいはそれ以前の発表や議論などを受けて行われていることが多いためである。そのため、たとえ導入発言が現在のスライドや発表に関連したものであったとしても、行われる議論の中の継続発言すべてが、現在の発表にかかわるとは限らない。
このとき、過去の発表や議論を単に触れるだけでとどめず、そのときの議論はどのようなものであったか、あるいはどのような結論に至ったかを回顧することは、その過去の発表や議論を知らない人に、さらには議論そのものに影響を与える。それは、現在の発表が過去の発表や議論をもとに成り立っているため、回顧することによって現在の発表の背景となった考えや目的など、暗黙的に説明されなかった情報が顕在化し、発表内容の理解が深まるためである。そのため、参加者全員がそれらの情報を理解した上で議論が行えるため、より活発な議論展開が期待できる。
2.1.3 議論回顧による知識の共有化
会議の参加者において全員が同じだけの議論を経験していることはまれである。多くの会議に出席している人はその分多くの議論に加わり知識を獲得しているが、逆に少ない人はその分参加した議論が少ないため、獲得している知識も少ない。その上で会議を開いたとき、参加者の議論の経験数に応じて発言の質や回数などに差が生じると予測される。多くの議論に参加した人はその分、多くの知識をもとに深い議論が展開できるが、少ない人は自分が知らない議論や発言などを持ち出され、議論が展開されてもその議論に参加することは困難である。しかし、活発な議論を行う上では多くの人が、十分な知識を持って議論に参加することが望ましい。
そこで本研究では知識の共有化にあたって現在の発表に関する前提や元となった議論、あるいは過去の類似する発表内容を記録した議事録から情報を獲得し、それらの知識を会議参加者全員で共有することにより知識レベルの向上を図る。
まず、発表から情報を獲得するメリットについて述べる。一つ目は発表にはその時までの研究の進捗がまとめられている点である。発表ではこれまでの進捗をスライドの形でまとめ説明し議論を行う。つまり当時の研究内容が端的に表現されている可能性が高い。そのため短時間で密度の高い情報を取得できることが期待できる。二つ目は発表時に行われた議論がその後の研究や現在の発表に対し、影響を及ぼしている点である。現在の発表内容はどのような経緯を経て至ったのか、その起点となるものの多くは発表中に行われた議論である。そのため現在の発表に関連の深い議論内容を詳細に知ることで現在の発表に対する理解が深まることが予測される。次に発表を記録した議事録から情報を獲得するメリットについて述べる。本システムではディスカッションマイニングによって記録された議事録を利用する。その理由には、過去に行われた発表の情報が閲覧に適した状態で記録されていることが挙げられる。議事録には発表に関する情報が構造化され記録されている。特にディスカッションマイニングシステムによって記録された議事録は発言単位まで詳細に構造化され、かつ発言者名や発言時間といった属性情報も付与されている。そのため必要な情報をピンポイントに獲得することが可能となり、検索や情報取得までにかかるコストの削減が期待できる。
以上より、議事録から情報を手がかりにして効率的に議論を回顧することで会議参加者全員の知識共有を促すディスカッションリマインダシステムを構築した。
2.2 ディスカッションリマインダシステム
本節では実際に実現したディスカッションリマインダシステムについて述べる。
2.2.1 ディスカッションリマインダシステムの機能的特徴
本システムは会議中に過去の議論を回顧できるようにすることで、知識の共有化を行う。知識の共有化は2章で述べたように以下の二つの要件がある。
-
より正確で詳細な情報を共有する
-
本来の議論をできるだけ妨げない
これらの要件を満たすために必要なシステムの機能的特徴について具体的に述べる。
2.2.1.1 正確で詳細な情報の共有
本システムにおいて回顧の対象とする情報は過去の発表で行われた発言や議論であるが、それらの共有するためにディスカッションマイニングによって記録されたビデオ映像を利用する。
ディスカッションマイニングによって記録されている発言や議論に関する情報は、書記によって入力されたテキスト情報と会議の発話の様子を記録した3種類のビデオ情報がある。これらの情報のうち、最も効率的に閲覧が可能な情報はテキスト情報である。しかしこのテキスト情報は人手によって入力されているため、情報の欠落や表記のゆれを含むことが予測される。そのためあいまいな情報しか取得できない書記テキストだけでは不十分である。
次にビデオ情報による発言や議論内容を獲得する手法を考える。ビデオ情報の閲覧は発言内容をそのまま記録しているため正確な情報が獲得できる。加えてテキストだけでは表現不可能な発言時の口調や雰囲気といった副次的な情報も同時に獲得可能であるため、正確な情報を獲得するにはビデオによる閲覧方法で十分に思える。しかしこのような閲覧方法でも獲得困難な情報が存在する。それは指示語である。特に発表者の説明を対象とした指示語は発言だけでは獲得困難な情報である。そのためビデオ情報だけでは不十分である。。
そこでビデオ情報とテキスト情報を同時に視聴可能にすることで相互の欠点を補う。ディスカッションマイニングによって記録されているビデオは参加者ビデオ、発表者ビデオ、スクリーンビデオの3種類が存在する。このうち本研究ではスクリーンビデオを利用する。こうすることでスライドのアニメーションやポインタの動作も同時に閲覧可能となり、単なるスライドの画像だけでは取得困難な情報も獲得できる。さらにスクリーン上のものを対象とした指示語が容易に理解できるであろう。そしてそれ以外を対象とした指示語に関しては書記テキストによって補うことができる。また、書記テキストを表示することは、音声のため、ときには聞き取り難い発言内容を視覚的に補うこともできる。このためスクリーンビデオと書記テキストによる閲覧が最も妥当であると考える。
以上の観点を踏まえ、本システムではビデオ映像と書記テキスト情報の同時閲覧機能を実装することで正確で詳細な情報共有を実現する。
2.2.1.2 議論を妨げない回顧
本システムは全員で過去の議論を回顧するため、必ず議論が中断する。そのため高速に回顧の対象となる議論を見つける必要がある。ここで、各発表について様々なメタデータが記録されている議事録に着目した。議事録には発表の日付や発表者名をはじめ、各発言の書記テキストや議論構造など詳細なデータを記録している。そのためこれらの情報を適切に利用することで高速な議論回顧を実現する。
まずはじめに議事録の全体数が多いため議事録自体を絞り込む必要がある。そのため各発表を特徴づける日付や発表者などといった情報をクエリとして入力し議事録を絞り込むことで、見るべき議事録の候補を減らす。
次に絞り込まれた議事録から見るべき議事録の選択・決定を行う必要がある。より多くの情報を提示するため、表示する場所としてもっとも領域の広いメインスクリーンを利用する。そして検索結果を直感的に把握できるよう、発表に用いられたスライドの代表サムネイルを表示する。
次に議事録から目的の議論を高速に辿り着く必要がある。ここで、議事録内から必要な情報だけを短時間で閲覧していく行為をザッピングと呼ぶ。ただし、一つの議事録に含まれる発言数は決して少なくない。そのため、議論に関係するスライドをザッピングすることで候補となる発言を絞り込む。これは会議中に行われる議論は発表スライドとそれに対する発表者の説明をもとに行われるため、各発言や議論はその時表示されていたスライドと関連性が強いと考えたためである。
次にスライドのザッピングによって絞り込まれた発言から必要な部分だけを高速に探し出すための工夫について説明する。発言をザッピングするのに有効な情報として以下の二つを用意した。一つは各発言における議論構造情報である。議論構造を視覚的に提示することで、どの議論は発散し、どの議論は収束しているのかを直感的に把握できる。もう一つは各発言に付与されているメタデータである。議事録において各発言には発言者名や書記の入力したテキストといった情報が記録されている。これらの情報は各発言を特徴づける重要な手掛かりとなる。これらの情報を上記の議論構造とともに的確に表示し、効率的にザッピングできるようにした。
最後に、選択した議事録がそもそも間違っていた場合を考える必要がある。本システムでは一つの議事録情報とともに議事録の検索結果の一覧も表示することで議事録のザッピングを効率的に行う。従来のYahooやGoogleといった検索エンジンでは、選択したコンテンツが目的のコンテンツでなかった場合、ほとんどが検索結果一覧へと画面を遷移させる。しかしこのような手法では毎回画面が切り替わり、非効率的である。しかし最近ではAjaxの発展によりりGoogle AJAX Search APIといった、専用のAPIを使用することで、画面遷移を行わない効率的な情報提示が可能となってきている。そこで本システムでは議事録情報と同時に検索結果一覧の情報も表示することで、画面遷移を無くし、作業の高速化を図る。
以上の観点を踏まえ、本システムでは次のような機能を実装することで現在の議論をできるだけ妨げない回顧を実現する。
2.2.2 システムの構成
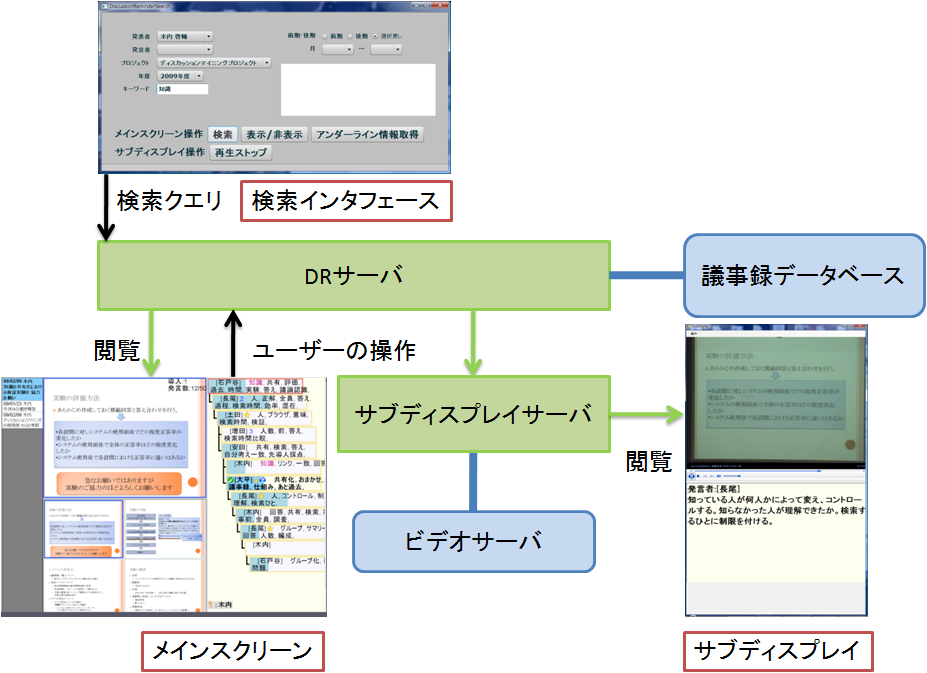
図2.1: システム構成図
ディスカッションリマインダシステム構成図を図に示す。ディスカッションリマインダシステムはサーバ・クライアント型のシステムとして実現されている。回顧する際の検索クエリが決定したとき、まず検索インタフェースに検索クエリが入力され、ディスカッションリマインダサーバ(以降、DRサーバと記す)へと送信される。DRサーバは受信したクエリをもとに議事録データベースにアクセスし、検索結果として議事録情報を取得する。そして取得した構造化議事録情報をもとにメインスクリーン上に情報を提示する。その後、ユーザーはリモコンを用いてインタフェースの操作を行う。ユーザーの操作はDRサーバへと送信され、それに応じてインタフェースが変化する。そしてインタフェースに対し発言再生の操作を行ったとき、DRサーバは再生するビデオのURIや再生開始・終了時間、ビデオ操作コマンドといった情報をサブディスプレイサーバへと送信する。サブディスプレイサーバは受信したビデオのURIをもとにビデオサーバにある目的のビデオへとアクセスする。そしてアクセスしたビデオ、およびDRサーバから受信するメタ情報をもとにサブディスプレイ上にビデオ情報を提示する。また、DRサーバからはビデオ操作の情報とともに発言者名や発言テキストも同時に受信し、これらの情報も合わせてインタフェースに表示している。
2.2.3 ディスカッションリマインダにおける各種機能
本節では実際に回顧を行う際の流れに則って、ディスカッションリマインダシステムの各種機能について詳細に述べる。
2.2.3.3 議事録の検索

図2.2: 検索インタフェース
検索クエリを決定し、入力する際に使用される検索インタフェースは図のような構成となっている。ここでは参加者によって決定された検索情報を入力し、後述するメインスクリーン上のインタフェースへその情報を送信する。また、メインスクリーンインタフェースの表示・非表示といった簡単な操作もここで行う。
検索インタフェースにおいて使用される検索クエリは以下のようになっている。
参加者はこれらのクエリを組み合わせることで全議事録から検索を行い、目的の議事録を絞り込む。
テキスト情報として存在するデータは書記の記録したテキスト、およびスライドに記述されているテキストである。今回の検索においてはいずれの情報も重要であるのでキーワードの検索対象としては両方を採用した。これによりキーワードを入力する際、何に含まれていたキーワードであるかを意識せず検索が可能となる。また、入力の手間を軽減するため現在の会議で引かれたアンダーライン情報も取得することが可能となっている。そして複数のキーワードを入力した際には先に入力したキーワードの重みが重くなる。これにより単純にキーワードが含まれているかどうかだけではない、より参加者の意思を反映した検索が可能となる。
以上のようなクエリを適切に組み合わせ検索クエリを決定し、その情報を表示用インタフェースへと送信する。
2.2.3.4 検索結果の選択・決定

図2.3: 検索結果一覧
検索インタフェースから受信した検索クエリをもとに表示用インタフェースは議事録データベースへアクセスを行い、検索結果を受信する。そしてその検索結果を図のように表示する。ここで提示される情報は検索クエリに該当した議事録の代表サムネイルと検索に用いたクエリの情報である。代表サムネイルは発表が行われた日付順、発表者の名前順にソートされ表示される。ただし、検索クエリとしてキーワードを入力した場合、スライド内、および書記テキストにおけるキーワードの包含数に応じてサムネイル一覧がソートされる。そしてキーワードを多く含むものはサムネイルの枠線を濃い色で表示する。さらに複数のキーワードを入力した場合、それらの重みを考慮しサムネイル一覧がソートされる。
そして参加者は各自の構造化リモコンを用いて議事録の選択・決定を行う。
これは会議参加時に全員が所持しているデバイスであるため、個々人が自分で任意に操作できるメリットがある。本システムでは操作のしやすさのため2種類の持ち方とそれぞれに対応する機能を割り当てている。
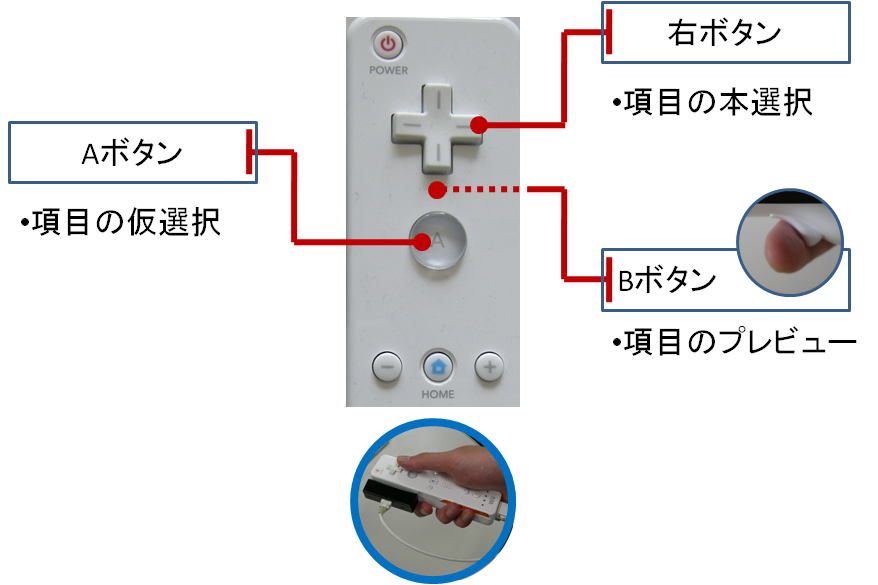
図2.4: スライド・議事録タイトルザッピング時の機能
図に示す機能は主にスライドや議事録タイトルのザッピングを行う際に用いる。
Bボタンは各項目に関するプレビュー機能となっている。参加者は項目をポイントしBボタンを押すことで項目の内容をプレビューすることができる。こうすることでその項目が自分にとって必要なものかどうかを瞬時に判断できるため、ザッピングの高速化が期待できる。また、このプレビューはBボタンを押し続けている間のみ行える。こうすることで必要な情報を必要な時だけ獲得できる。これは単に表示領域を確保するためだけでなく、不必要な情報を非表示にすることで情報の飽和を防ぐ目的もある。
Aボタンと十字キーの右はそれぞれ仮選択、本選択機能となっている。本システムにおける選択行為は他のザッピング画面を切り替えることである。議事録の選択はスライドと議論セグメントに、スライドの選択は議論セグメントに影響を与える。そのため不用意に選択行為を行うことはかえってザッピングの高速化に悪影響を及ぼすと考えられる。そこで本システムでは本選択の前に仮選択を設けることで操作ミスや安易な選択行為を防止している。また、仮選択には他の参加者に自分が見たい項目を表明する目的もある。
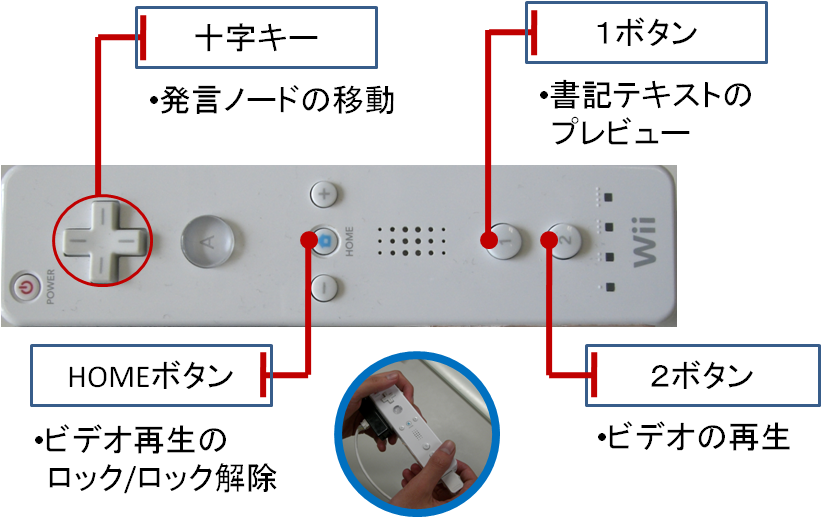
図2.5: 議論セグメントのザッピング時の機能
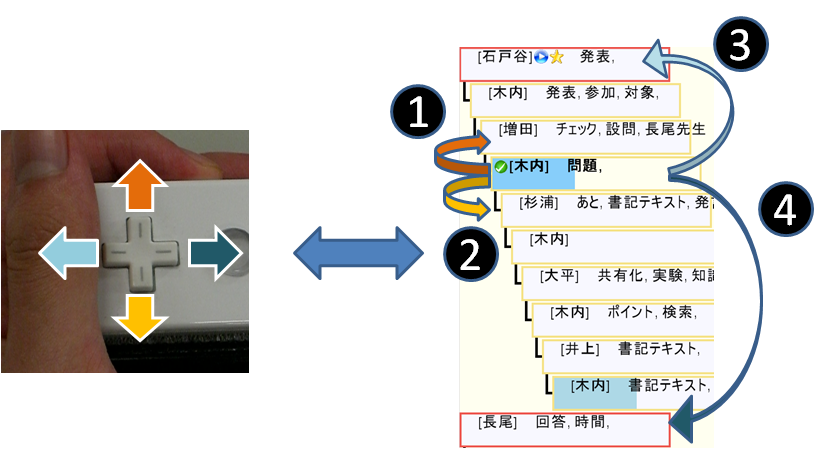
図2.6: 発言ノードの移動
十字キーの操作では各発言ノード間の移動を行う(図)。上下ボタンを押すことで各発言ノードを上下に一つずつ移動できる。上ボタンを押すことでひとつ前の発言ノードに移動し(1)、下ボタンを押すことでひとつ次の発言ノードに移動する(2)。左右ボタンで各導入発言ノード間の移動を行う。左ボタンを押すことでひとつ前の導入発言に移動し(3)、右ボタンを押すことで一つ次の導入発言に移動する(4)。
2ボタンはビデオ再生機能である。参加者は再生したい発言上で2ボタンを押すことでサブディスプレイ上で再生されている発言を切り替える。発言ノード上には現在再生中の発言ノードがどれかわかるようアイコンが表示される。
HOMEボタンはビデオ再生のロック機能である。ロック機能とはビデオ再生の操作権限を一時的にロックを行った人が獲得し、他の人がビデオ操作を行えないようにする機能である。これによって一時的にビデオ操作を排他的にでき、結果としてマルチユーザによる操作の混乱を防ぐことができる。
1ボタンは書記テキストのプレビュー機能である。参加者は書記テキストを閲覧したい発言ノード上で1ボタンを押すことで書記テキストをポップアップとして表示し、書記テキストの確認ができる。書記テキストのプレビュー機能は再生したい発言かどうかを確認する機能であり、ザッピングを行う上では副次的な行動である。そのため十字キーによる移動操作を優先し、移動操作を行うと同時にポップアップは閉じられる。
これらの機能は図のようなザッピング用インタフェース上で使用される。
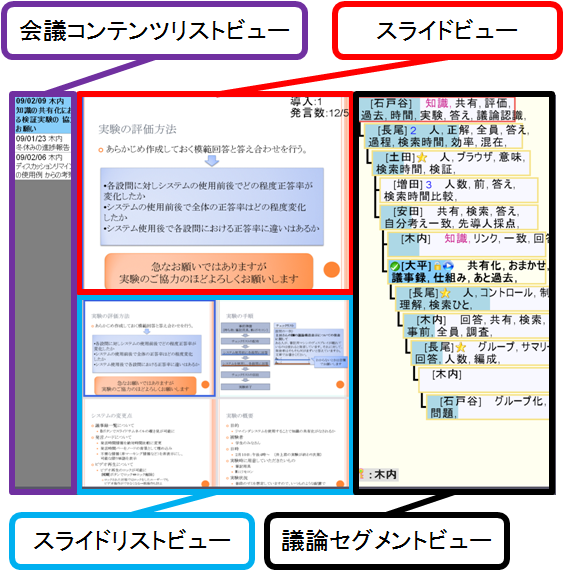
図2.7: ザッピン用グインタフェース
2.2.3.5 スライドのザッピング
議事録が選択されたのちに、スライドをザッピングする際には図に示すスライドリストビューとスライドビューを用いる。
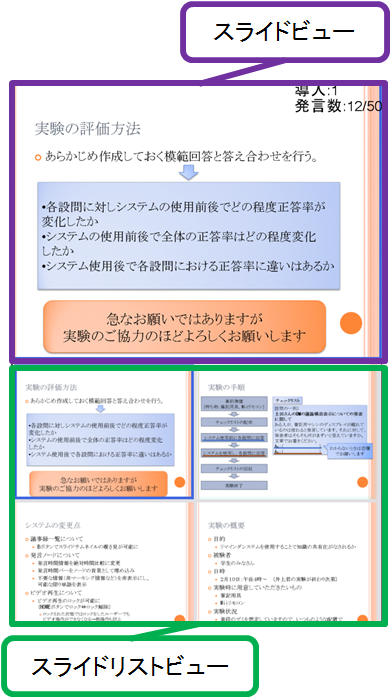
図2.8: スライドビュー・スライドリストビュー
スライドリストビューには現在選択されている発表でのスライドのサムネイルが表示されるが、より高速にザッピングを行うためいくつかの特徴がある。一つ目は議論が展開されていたスライドで、かつそのスライド上で議論が展開されたスライドの一覧のみが表示されている点である。これはあらかじめ議論が行われていないスライドを非表示にすることで、ザッピングを行う候補を減らし効率化を図るためである。二つ目は検索クエリを入力時、キーワードが入力されていた場合に限り、キーワードの包含数に基づいてサムネイルがソートされ、さらに枠の色が変化する点である。これは目的のスライドを探す手掛かりとなる。三つ目はスライド以外の資料を参照しているとき(たとえば、システムのデモやWebページの表示を行っているとき)に発生した議論に対して、スライドサムネイルの代わりにその時入力したテキスト情報を表示している点である。これによりスライドが表示されていないときの議論も網羅することができる。加えてどのような内容であったかも把握できる。
そして参加者はスライドリストビューから詳しく見たいスライドをリモコンでポイントしボタンを押すことで、スライドビューのスライドを一時的に切り替えることができる。これにより参加者個々人が任意にスライドの詳細情報を取得し、スライドをザッピングできる。
また、スライドリストビューには後述する議論セグメントビューを切り替える機能もある。参加者はサムネイルをポイント、選択することで議論セグメントビューを切り替える。
2.2.3.6 議論セグメントのザッピング
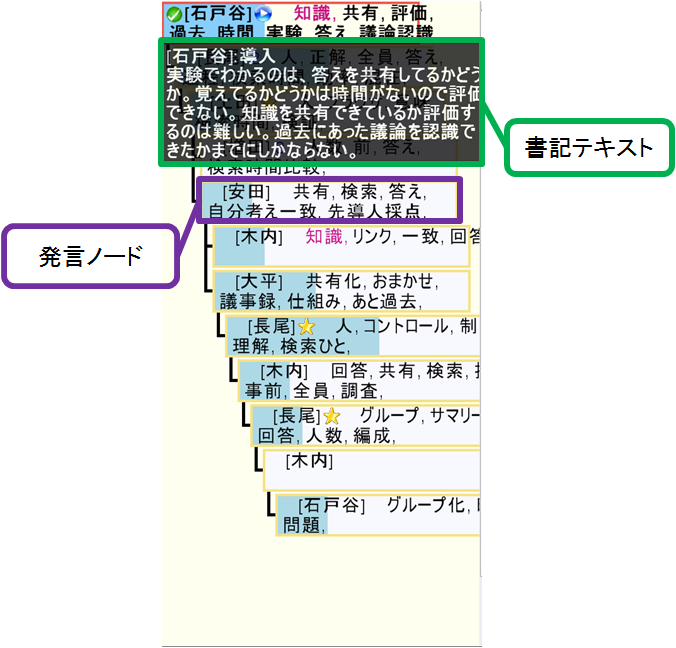
図2.9: 議論セグメントビュー
スライドをザッピングした後、閲覧したい議論や発言のザッピングを行うときは、図に示される議論セグメントビューを用いる。議論セグメントビューでは、議論構造と各発言を効果的に可視化することで効率的なザッピングを実現している。
まず、議論構造を可視化することで、ザッピングすべき発言箇所を絞り込むことが可能となる。議論セグメントの長さや、発言の分岐点といった情報が可視化されることで直感的に知ることができる。これらの情報は発散している議論や、逆に収束している議論を可視化する。参加者はこれらの情報をもとに議論セグメント単位の大まかなザッピングを行う。
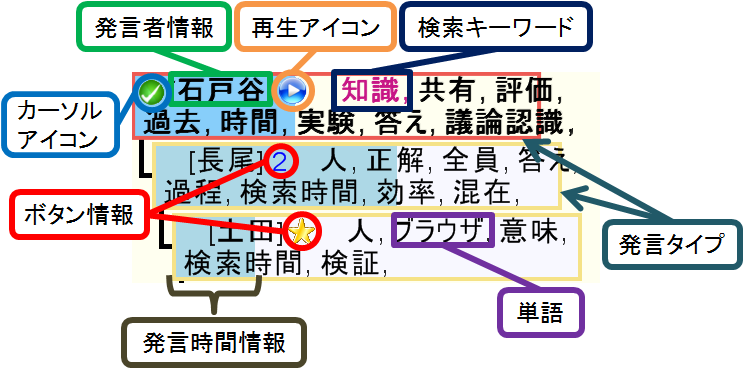
図2.10: 発言ノード
次に、発言ノードについてである。発言ノードとは図での議論構造における一つの発言を指す。発言ノードは以下に記す情報を適宜表示している。
そしてこれの情報を図のように提示している。次に各情報に対しての説明を行う。
発言タイプの情報は議論セグメントにおいてどの発言が導入で、どの発言が継続かを知る手掛かりとなる。そのため各タイプを発言ノードの枠線の色によって提示する。各枠線の色はディスカッションマイニングおける導入の色(赤色)と継続の色(黄色)を採用している。
発言者情報は誰が発言していたかという情報である。この情報は各発言ノードを特徴づける情報となる。
マーキング情報およびボタン情報は当時の参加者が入力したボタン情報である。マーキング情報はボタンを押した人がこの発言は重要だろうと判断して付与された情報のため、発言ノードを絞り込む上で大きな手掛かりとなる。また賛成・反対といったボタン情報は当時の参加者がその発言に対し自身のスタンスを表明する際に付与された情報である。このことからその発言には参加者が自身のスタンスを表明するだけの内容が含まれているだろうという予測が可能となる。また、これらのうち発言においては不要となる情報(例えば非マーキング情報など)が発生するが、これらの不要な情報は非表示になっている。これにより参加者は必要な情報だけを獲得することができる。
そして発言時間情報は各発言の内容を予測することに貢献すると判断した。例えば発言時間が短いノードが連続していれば単なる質疑応答の連続だろうという予測が、逆に発言時間の長いノードには多くの情報が含まれているという予測が可能であろう。この情報は各ノードの背景色を変化させることで表示している。時間情報を単純に数値として表示する手法では瞬時に発言の長さが把握できない。長さで表現する方法を取ることによって、表示領域が多くなり、発言ノード全体としての情報量が減少する。そこで他の情報の領域を圧迫せずかつ時間情報が視覚的に獲得できるよう背景として時間情報を表す。
最後は書記テキストを形態素解析することで獲得した単語に関してである。単純に書記テキストをすべて、あるいは一部を表示するのではなく単語に分割して表示することは次の観点から有利であると考える。それは単語の方が書記テキストと比べ発言の内容を把握するために有力な情報をより多く表示できる点である。書記テキストは文章が書かれるため必然的に助詞や句読点といった発言内容の把握には直接的に影響しない文字まで表示することになる。このような文字を除外し、内容把握に有力な情報のみに絞ることでより多くの情報が表示できる。結果として発言内容把握の効率化が期待できる。
ただし表示する単語は適切に選択する必要がある。ここでまず優先して表示すべき単語は検索時に入力されたキーワードである。この情報は検索時にクエリとして入力されたものである。そのためキーワードが発言内に含まれているかどうかは発言をザッピングする上で重要な手掛かりとなることが予測される。そして次に表示すべき情報が書記テキストを形態素解析することで獲得した単語である。本システムでは単語単体で発言内容の推測を可能にするため名詞に分類される単語を表示している。
単語を選別し表示しても発言の内容を把握することが困難なケースも存在する。このようなケースに対応するため議論セグメントビューでは参加者は任意に発言ノードの書記テキストを閲覧することが可能となっている。
また各議論セグメントにおける導入発言は議論を開始する起点となる発言のため、以下に続く継続発言に大きい影響を及ぼしていることが推測される。そのため議論セグメントビューでは現在フォーカスのある議論セグメントの導入発言ノードを常に表示している。こうすることで今見ている発言はその議論セグメントにおいてどのようなポジションにある発言かを知ることができる。
これらの情報をもとに参加者は閲覧したい発言を探し出し、次に述べるビデオビューとともに内容そのもののザッピングを行う。
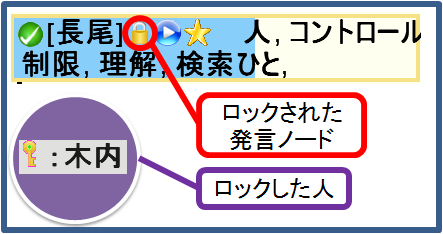
図2.11: ビデオ再生のロック
最後にロック機能について述べる。参加者は構造化リモコンを用いてビデオビューでの再生操作を行うが、操作対象が一つのためその操作は排他的になる。そのため複数の参加者が同時に再生を行おうとすることで操作の競合が起こる。加えて再生中に議事録やスライドの変更が行われることでもビデオビューの再生が中断される。この問題を解消する手段として議論セグメントビューでは再生のロックが可能となっている。ロックを行うと図のように発言ノードにアイコンが追加される。これによりどの発言ノードがロックされているかがわかる。加えて誰がロックを行ったかがわかるようロックを行った人の名前が表示される。ロックを行うと他の人が再生操作を行うことができなくなり、さらに議事録やスライドの変更ができなくなる。このようにロックを行うことで最後まで視聴したい発言を他の参加者に邪魔されることなく視聴することができる。
2.2.3.7 ビデオ映像と書記テキスト情報の閲覧

図2.12: ビデオビュー
議論セグメントビューにおいて選択した発言をサブディスプレイに表示されているビデオビュー(図)にてその詳細な内容を閲覧することができる。ビデオビューでは会議中に記録されたスクリーンビデオを用いて発言の詳細な内容を視聴する。
ビデオ映像では発言そのものを映像で再生できるため、非常に正確な情報を視覚的・聴覚的に閲覧できる。特にスクリーンビデオを再生することで音声だけでは獲得が困難な、指示語の対象そのものの閲覧が可能になる。加えてスライドのアニメーションやポインタの動作も同時に閲覧可能となるため、単なるスライドの画像だけでは取得困難な情報も獲得できる。
さらに本システムではビデオ映像とともに書記テキスト情報も同時に提示している。書記テキストにはそれ単体では人手入力のため情報があいまいである。しかし書記テキストには発言中にでてくる指示語が網羅されている可能性が高い。特に映像だけでは獲得困難な発表者の説明に対する指示語が記述されている場合がある。このような情報とともにビデオを閲覧することで、詳細な内容を獲得できる。加えて書記テキストを表示することで音声のみでは聞き取り難い発言内容を視覚的に補うことも可能である。また、ザッピングの効率を上げるためビデオの再生は議論セグメントビューにおいて選択された発言の開始時間からピンポイントに開始される。
2.2.3.8 議事録のザッピング

図2.13: 議事録リストビュー
議事録のザッピングは、選択した議事録が間違っていた際に行う。図に示される議事録ビューは、検索結果の画面に遷移することなく議事録を切り替えられる機能を持つ。議事録ビューにおいて表示される一つの議事録の情報はれ発表者、発表日時、そして発表タイトル名がテキスト情報として提示されている。
さらに詳しく内容を見たい議事録が見つかった場合、参加者はスライドをプレビューすることで、議事録を切り替えることなくスライドの詳細を知ることができる。参加者はこれらの情報をもとに議事録のザッピングを行う。これらの情報をもとに閲覧する議事録を選択・決定する。こうすることで参加者は議事録サムネイル一覧画面に戻ることなく効率的に閲覧中の議事録を切り替えることができる。
3 知識の共有化と議論の活性化に関する実験と考察
前章ではディスカッションリマインダシステム(以降、本システム)について詳細に述べた。本章では、本システムを用いた議論の検索実験とその考察について述べる。
本システムは過去の議論を回顧することで知識の共有化を行い、議論の活性化を目指すシステムである。そこで本実験では予備実験として、会議中の回顧を想定した議論の検索実験を行った。
3.1 実験方法
本実験は、本研究室の在籍時間によって知識レベルに差が生じていると思われる被験者を対象に行った。被験者は8名の学生でそれぞれ知識レベルが高いと思われる順に、D2の学生1名、M2の学生3名、M1の学生2名(ただし、うち1名は2008年度に転属)、B4の学生2名である。
そして被験者らには過去に行われた発表に関する設問が用意された設問リストを配布した。設問リストの各設問は5つの発表を対象とした。これらはいずれも2007年度に行われた発表である。設問リストの各設問には、「この発表を覚えていますか?」というチェック項目、およびその発表で行われた発言や議論に関する問題が用意されている。被験者らには事前調査として本システムを使用する前にこの設問リストに回答してもらった。以下に設問の一例を示す。
[l]設問の一例 成田さんのペットロボットの実験について
-
発表者は作成時間に関してある仮説を立てていましたが、結果はそれと反するものでした、それに対して、
-
発表者は実験のやり方について(A)が一番まずかったと発言しています。Aに当てはまるものをお書きください。
A:( )
-
そしてどうすべきだったと発言してますか?文章でお書きください。
B:( )
その後、全員で本システムを使用し、話し合いを行いながら各設問に対し回顧を行ってもらった。その際、事前調査で発表を覚えていると答えた被験者1名に各問題のサマリーを行ってもらった。サマリーに関してはB4の被験者にも分かる程度に説明してもらうよう指示をした。その後各設問の問題に対する答えがわかったかどうかのチェックを行ってもらった。そしてシステムの使用前の設問の正答率とシステム使用後のチェック状況を比較することで被験者らがあいまいな情報だけでも十分に回顧できるかを見る。
3.2 実験結果
本節では事前調査と実験結果ついて述べる。
3.2.1 事前調査結果
本節では事前調査について述べる。なお、説明のため5件の発表をそれぞれ発表A?発表Eと表記する。
表に発表に対する事前調査の結果を記す。各項目は、発表を覚えていると回答した人の人数、覚えていないと回答した人の人数、その発表に参加していない人の人数、そして各設問に用意された問題の正答率である。なお正答率は発表を覚えていると答えた人の中で各問題に対し正答した人の割合である。また、全発表に対する問題の正答率は8.05%であった。この結果から、たとえ発表を覚えていたとしてもその発表で行われた詳細な内容まで記憶しておくことは困難であることがわかる。
3.2.2 システム使用後における調査結果
次にシステム使用後に行った、各問題に対する答えがわかったかどうかのチェックについて述べる。システム使用後の平均回答時間と正答率は表のようになった(※:ただし回答できなかった問題は除く)。この結果から、まず発言に対する詳細な記憶がなくともほぼ目的の発言を探し出せることがわかった。平均回答時間に関して、各発表において大きなばらつきが見られた。また、発表を覚えている人の数と平均回答時間の間に相関関係は見られなかった。
3.2.3 考察
3.2.3.1 平均回答時間に関する考察
回答時間が全体の平均回答時間を超えた発表(発表C,発表D,発表E)に関して述べる。これらの発表では被験者の一人が、発言者や発言内容に関して思い違いをしていたことが確認された。また、傾向としてはスライドの選択はあっているが、発言を探す際に時間がかかっていた。これはスライド情報は画像として記憶に残りやすいため比較的早く見つかるが、発言情報はもともとが音声情報のため記憶に残り難く、あいまいになっているからだと推測する。しかしすべてのケースにおいて他の被験者が思い違いを指摘し、目的の発言に辿りついていることがわかった。これらのことから、複数人でザッピングを行うことは、各々の人がスライドや発言を閲覧することで効率的になるだけでなく、一人だけでは気付けなかった思い違いを他の人が指摘し修正することで正確な情報の回顧ができるといえるであろう。
次に平均回答時間が特に短かった発表Bに関して述べる。発表Bにおける問題にはいずれもスライド中に含まれる特徴的な単語が含まれていた。加えて、そのスライドで行われた発言も5つ程度と少ないものであった。これらのことからまず発言箇所がスライドから特定し易い発言に関しては高速にザッピングが行えると考える。さらにスライドのザッピングによって絞り込まれた発言候補が少ないことで、発言のザッピングにかかる時間も短縮され、結果として短時間で目的の発言に辿りつけると考える。
3.2.3.2 発表Aに関する分析および考察
本節では正答率に関して唯一低かった発表Aに関して述べる。これは、下に記す問題Eに対する回答が見つからないとチェックした結果である。しかし事前調査での結果では問題Eに対し5名中4名が正答していた。
[l]問題Eおよび回答ペットロボットの質の変化に関して、質の変化と同時に複雑さについても言及されていますが、ここでの複雑さとは実データの(E)に表れています。Eに当てはまるものをお書きください。(回答:点の数)itembox
問題Eでの実験の様子を分析してみた結果、発言の内容をビデオで視聴していないことが、回答は「点の数」であると断言できなかった原因の一つではないかと考える。まず、すべての問題のうち問題Eのときのみ、問題の回答を含む発言のビデオが視聴されなかった。しかし被験者らは問題Eの答えを含む発言にはたどり着いていることがわかった。加えてその発言の書記テキストも十分に(38秒程度)閲覧していたことがわかった。書記テキストの詳細は下記に記す。
[l]書記テキストそういう例はない.点の数は同じなんだけれども,感覚が変わることで,複雑さは同じだけれども,質が変化する例.そのようなことを考察するのならば,そこで初めて複雑さとは違う指標を導入するべき.itembox
だが、この書記テキストだけでは内容が十分に理解されなかった。それは被験者の「意味がわからない」といった発言からも推測される。このとき被験者らはビデオを視聴せず、書記テキストのみで答えの判断を行っていた。そして最終的に被験者らは見つからなかった、という結論に至った。
正確で詳細な内容を獲得するためには書記テキストだけではなく、ビデオも視聴する方が望ましいと考えられる。
3.2.3.3 実験時に見られた被験者の行動に関する考察
最後に実験時に見られた被験者の行動に見られた傾向について述べる。実験全体を通して主にD2の被験者が話し合いを先導する傾向があった。これは被験者らの中で最も多く発表を経験し知識が豊富であったためと推測される。しかしザッピングの操作に関してはこの傾向とは異なるものであった。そこで図には平均回答時間と最も近かった発表Dの操作履歴を記す。
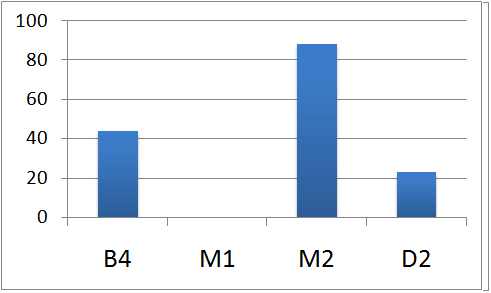
図3.1: 発表Dにおける操作回数の偏り
このようにD2の学生はあまり操作を行わず、M2の学生が操作を行う傾向は他の発表でも見られた。また、操作しているM2の学生も一人の学生に限られていた。そして話し合いの様子からはD2の学生と操作を行っているM2の学生との会話が多く見られた。
これらのことから、話し合いを先導する人がザッピング操作の多くを占めるとは言い切れないことがわかった。むしろ一人が話し合いを先導し、一人が操作を行うといった分担が自然になされていたと言えるであろうこのように一人の人がすべての作業を行わず分担することで、効率的にザッピングが行えていると考えられる。これは本システムの複数人によるザッピングを可能にしたことが有用に働いたといえるであろう。
3.2.4 課題
3.2.4.4 議論の活性化に関する課題
本実験では疑似的な環境のもとに実験を行ったため、実際の会議において議論が活性化できるかどうかは評価できていない。しかし第2章の2.1.2節で挙げたように学年が上がるにつれ発言数およびマーキング発言数は増加している。また実験の様子からも話し合いをD2の学生が先導していることから、知識レベルが高まることは議論の活性化につながることは予測できる。
本研究では今後も引き続き知識の共有化による議論の活性化を目指す。本研究で今回対象にしたことは議論中における知識の共有化である。しかしもっとも望ましい状態は会議に参加する前に全員の知識が共有されていることである。そのため会議中に行った知識の共有化によって生成された情報を次の会議に利用するような仕組みを考える必要があるであろう。
具体的には、会議中に行った回顧の議論内容などをディスカッションマイニングへフィードバックすることで、個々人が会議後にディスカッションメディアブラウザを用いて簡単に閲覧可能になる。このように会議中では十分に理解できなかった内容も会議後に回顧することで、着実に知識レベルが高まることが期待できる。
3.2.4.5 知識共有化に関する課題
今回の実験では問題の答えがわかったかどうかのチェックしか行っておらず、対象とした議論の内容までわかったかどうかの評価は行えていない。すなわち発言に対する情報を獲得できることは分かったが、その発言の内容を理解できたかどうかは分からない。
そこで設問として挙げた発表に不参加だった3名の被験者に「サマリーをきいて問題の内容が理解できたか」というアンケートを行った。その結果、各被験者における、すべての設問に対しての理解度はそれぞれ63%,57%,47%であった。このアンケートの結果から、たとえ発言に対する情報を獲得し、その内容を説明されても全員が内容を理解できるとは限らないことがわかる。また、同じ説明を聞いても人によってその内容が理解できるかどうかが異なっていた。
これらのことから本システムは知識の共有化に必要な情報を提供することはできているが、そこから各参加者の理解を促すまでには至っていないことがわかる。加えてこの理解度は問題ごとにサマリーを行った上での理解度のため、現在のシステムでは参加者に内容を理解させるには不十分であることも分かった。そのため本システムはまず、できるだけ発言内容の説明を行い易くするような改良が必要であると考える。
具体的には、議論だけでなく発表者の説明やデモの様子なども回顧の対象とする方法が考えられる。今回の実験でも、発言には「例を見せます」とだけしか記録されておらず、肝心のその内容は閲覧できないケースが存在した。そして具体的な内容はD2の学生が説明していた。このような問題は議論以外の情報も閲覧可能にすることで解決できると考える。すなわち、説明に必要な前提知識はシステムが補うことで、発言内容の説明を行い易くできるであろう。
3.2.4.6 システムの操作性に関する課題
本システムの議論セグメントビューでの操作は複数人の操作を受け付けるようになっている。これはだれでも操作が行えるようにすることでザッピングの効率化を期待したためである。しかし実験では、同時に操作を受け付けるため、逆に複数人の操作が競合してしまうことが多かった。図には発表Dにおける、議論セグメントビューでの各被験者の操作記録と時間の関係をプロットしたものを示す。なお、縦軸は各被験者を表す。
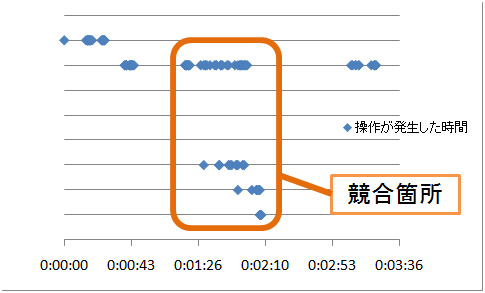
図3.2: 発表Dにおける議論セグメントビューの操作記録
この図から議論セグメントビューでの操作が一部、集中していることがわかる。また、実際の会議の様子からも一部で操作の競合が見られた。このことから排他的になる操作に関しては、全員が平等に操作でき、かつ操作の混乱が起きないようシステムを改良する必要があると考える。具体的には、誰かが操作を行った場合は、一定時間他のユーザの操作を受け付けなくする、といった方法が考えられる。
4 関連研究
4.1 議事録の検索・閲覧に関する研究
4.1.1 ReSPoM
会議の様子を記録し、さらに検索を可能にする研究は多く行われている。倉本らはReSPoMと呼ばれる、会合中に書かれるメモから、会合の様子を記録した一次記録の検索を行うシステムの研究を行っている。ReSPoMではマイクと液晶タブレットを用いて会合を行うことで、音声情報とメモ情報を自動的に記録する。その際リアルタイムに行われている発話情報とメモ情報間に記録用インタフェースを用いてリンク情報を付与する。そしてこのリンク情報をもとに検索用インタフェースを用いて会合中に使用した資料やメモ、発話の再生を行う。
メモ情報のように会議中に付与される情報から一時記録を再生するといった点では本システムと類似している。しかしメモ情報では個人の筆跡や重要だと思う観点が異なり、複数人が閲覧する環境での利用には向かないといった問題がある。ReSPoMでは発話内容からの検索は行えないが、本システムでは発言内容や発言者といった情報をもとにした検索も可能となっている。また、対象としている一次記録は発言単位でセグメントされた情報であり、発言間の意味的関係からの構造化はなされていない。そのため議論の構造を可視化し検索を行うといったことができない点も問題である。
4.2 議論の構造化に関する研究
4.2.1 MAST
議論の構造化に関して、森らはMASTと呼ばれる、会議の様子を記録した逐語録から自動的に議論の流れを抽出し、発言の対応関係に基づく議論の構造化および可視化を行うシステムの研究を行っている。MASTでは会議の発話を記録した逐次録から、会議後に各コメントにおける単語の共起関係をもとにコメント間の連結強度を割り出し、それをもとに議論の構造化を行っている。インタフェースとしては議論構造の可視化、発言内容の可視化、検索機能、そしてノード間のリファレンスを示すリンクの閾値変更機能がある。ユーザは閾値を任意に変更することで、リフレクションを行う。
構造化という観点から、議論構造を目的に応じて変更できる点は、本研究で利用している議論構造とは異なる点である。任意に議論構造を変化できることは個々人の目的に沿った議論構造を表示し、リフレクションを容易にする。しかし本研究のように複数人で高速に議論を見つけ出すという目的には不適切である。複数人が操作することで議論構造が頻繁に変化することが予測される。そのため、議論構造からの発言の推測が困難となる。また、MASTは会議後に構造化を行っているが、これは会議参加者全員の議論構造に関する共通見解が持てないため、複数人が同時に議論構造を閲覧する本研究の環境では問題となる。
4.2.2 構造化フレームワーク
議論の構造化に関して、谷村らは構造化フレームワークと呼ばれる、一定のプロセスを経ることで柔軟な議論構造を獲得できるフレームワークを提案している。構造化フレームワークではまず、逐語録を発言の最小単位として1文章に分割する。その後、複数の発言をそれらを構成する意見や質問ごとにまとめ、これをArgumentと定義している。そしてArgumentどうしの対応関係を調べ、発言の対象が存在するものにはこれを参照関係で結合する。このときの参照関係は時系列順に基づき生成されている。
このような発言の構造化は発言間の時系列に基づくため応答関係を明示することには優れているであろう。しかし本研究においては発言の検索に主眼が置かれているため、発言の内容を重視した発言の構造化が求められる。また、構造化フレームワークによる構造化では発言の最小単位を1文章と定め、その上で機械的にArgumentを生成しているためArgumentには発言者意図が反映されにくい。これらのことは会議参加者全員が発言を閲覧する本研究のような環境では、議論構造に対する考え方の相違からかえって検索に時間がかかるといった可能性も考えられる。
5 まとめと今後の課題
5.1 まとめ
筆者の所属する研究室では、ディスカッションマイニングと呼ばれる、人間同士の知識交換の場である会議から実世界情報を獲得し、それらを半自動的に構造化することによって、再利用可能な知識を抽出し、会議コンテンツとして蓄積・共有する技術の研究・開発を行っている。ディスカッションマイニングシステムはスライドを投影するためのスクリーンや、記録用のマイクやカメラ、補助用のサブディスプレイなどを設置した環境で運用されている。
ディスカッションマイニングの目標の一つに議論の活性化がある。本研究ではディスカッションマイニングシステムを拡張し、会議中に過去の議事録を回顧できるようにすることで、知識の共有化を行い、議論の活性化を目指すディスカッションリマインダシステムの開発、研究を行った。
会議参加者全員の知識レベルが同じ状態で議論に臨むことは難しい。それは他の参加者と比べ自分にとって参加したことのない会議が存在するなど理由は様々である。そのため会議において臨機応変に知識の共有を行い、知識レベルを均一にすることが求められる。本研究では特に過去に行われた議論に着目し、会議中にそれらの様子を回顧可能にすることで、たとえ自分が参加していない議論であっても、詳細にその内容を知ることができる。
会議中においての知識共有は、正確で詳細な知識を、本来の議論を妨げないようできるだけ早く共有することが求められる。そのため本システムを用いて過去の議論を回顧し知識を共有する際にもそれらの要件を満たす必要があった。そこで本研究ではまず前者の要件を満たすためにディスカッションマイニングによって記録されているビデオ映像に着目した。会議中に過去の議論の様子をビデオでピンポイントに視聴可能にすることで、正確で詳細な情報の獲得を可能にした。次に後者の要件を満たすために本研究ではディスカッションマイニングによって生成される議事録に着目した。議事録には会議に使用されたスライド情報や、会議中に行われた発言の詳細な情報が構造化され記録されている。そのため必要な情報をピンポイントに獲得でき、効率的な情報を探索が可能となる。
本システムでは上記の二つの要件を満たすため、次のような手法で効率的に正確で詳細な議論の回顧を可能にした。まず会議中に議事録の検索を行うためのインタフェースを実装した。これにより参加者は数ある議事録の中から検索条件を入力することで閲覧候補を絞り込める。次に議事録の情報をメインスクリーン上に可視化するインタフェースを実装した。インタフェース上では議事録の情報をスライドサムネイル一覧と議論セグメント(一つの話題に関する発言の集合)一覧として表示している。議論セグメント一覧では発言間の関係が直感的にわかるよう、一つの発言をノードとした木構造で表現されている。発言のノードには発言者名をはじめ発言を特徴づける情報が提示されている。さらに議事録の情報と同時に検索結果の一覧も表示している。このような手法を用いることで効率的な発言の探索を実現している。そして参加者は専用デバイスを用いて各操作を行い、閲覧したい発言を選択する。そして選択された発言をビデオ映像として視聴できる映像視聴用インタフェースを実装した。映像視聴用インタフェースでは選択された発言のテキスト情報と発言時のスクリーン映像を同時に視聴可能となっている。スクリーンビデオの映像を用いることでスライド上のアニメーションや、発言に含まれる指示語など画像だけでは獲得できない情報を提示している。さらに選択された発言の開始時間からピンポイントに再生を開始することで、効率化を図っている。
以上のような手法を取り入れたシステムを実装することで会議中において効率的に、かつ正確で詳細な議論内容の回顧を可能にした。
そして本システムを用いた実験では会議中の回顧を想定した議論の検索実験を行った。実験では知識レベルに偏りがある8名の被験者を対象とし、過去に行われた発表を検索し、それらに関する設問に回答してもらうことで、知識の共有が行えるかどうかを検証した。その結果、全体の設問の正答率は96%となり、本システムを使用することで知識の共有が行えることを確認した。しかし実験を通して、一部の被験者は内容を十分に理解できていないなどの課題も残されている。
5.2 今後の課題
5.2.1 長期的な運用に基づく評価
本実験では本システムを用いて回顧が行えるかどうかの評価までしか十分に行えていない。本システムを用いて十分に知識の共有化が行えるか、さらには議論が活性化しているかどうかの評価は十分ではない。そのため今後は本システムを長期的に運用し、実際の会議の場において知識が共有されているか、そして議論が活性化しているかどうかの評価を行う必要がある。
評価方法の一つとしては議論への参加人数の変化を調査する手法が考えられる。本システムは過去の議論情報を提示することで、会議参加者に議論参加に必要な情報を提供する。そのため情報が不足し、議論に参加できなかった参加者がその情報を獲得し、理解することで議論に参加すると推測される。しかしこの評価は短期的な調査では行えない。それは議論に参加できない理由が本当に情報の不足によるものか短期的に見るだけではわからないからである。議論に参加できない理由には個人のスキルに依存する面も大きく、情報の不足が原因かどうかは長期的に傾向を見る必要がある。そのため本システムを長期的に運用し、その傾向を見ることで正当な評価を行う。
5.2.2 ディスカッションマイニングとの連携
本システムはディスカッションマイニングを拡張することによって実装され、ディスカッションマイニングによって生成された議事録を利用する形となっている。しかし現段階では本システムからディスカッションマイニングへのフィードバックは十分に行えていない。そのため今後はディスカッションマイニングへのフィードバックを考えたシステムの拡張が必要となる。
具体的な拡張としては各議事録間のリンク生成が考えられる。現在ディスカッションマイニングによって生成されている議事録にはコンテンツ間のリンクが存在しない。しかし本システムを用いて回顧を行うことで現在の議論と回顧対象の議論間に関連性が生まれる。この関連性を議事録間における議論間のリンクとして作成し、記録することで再利用性が高まるのではないかと期待する。例えばディスカッションマイニングメディアブラウザによって発表を閲覧するとき、現在のままでは閲覧した発表での議論情報しか獲得できない。しかし議論間にリンクが作成されていれば閲覧者は、リンクをたどることで、過去に行われた議論情報も同時に獲得できるようになるであろう。
5.3 今後の展望
5.3.1 DRIPシステムとの連携
本節ではディスカッションリマインダシステムの応用として本研究室で先行的に研究されているDRIPシステムとの連携について述べる。DRIPシステムでは個人の研究活動といった知識活動を以下の4つのフェーズから構成されるDRIPサイクルと定義し、各フェーズにおいて個人の研究活動を支援するシステムである。
-
議論(Discussion)フェーズ
アイディアや知識を他者に発表し、議論を通じて多角的な視点によるコメントやアドバイスを獲得する
-
再認(Reflection)フェーズ
議論フェーズで行われた議論の内容を整理し、その後の活動方針を見定める
-
探究(Investigation)フェーズ
過去の議論内容を踏まえつつ、調査や実験、検証といった様々な作業を行い、新たなアイディアや知識を創出する
-
集約(Preparation)フェーズ
創出したアイディアや知識を公表し、他者から新たなコメントやアドバイスを獲得したい事柄を明確にし、次の議論フェーズにつなげる
議論フェーズではこれまでの研究活動から生まれた知識やアイディアを発表する。そして自分だけでは解決できなかった、もしくは他者の意見を参考にしたい点などについて、議論を通じ参加者からの多角的な意見やアイディアを獲得する。その際、ディスカッションマイニングによって議論の内容が詳細に記録されるが、そこには「自分にとって有益な議論かどうか、そしてその議論はなぜ有益なのか」といった人間の解釈が含まれていない。そのため目的の議論を探し当てることが困難になる。そこで次の再認フェーズでは議事録の中から重要な議論を取り出し、再利用をしやすくするために人間の解釈を加える作業を行う。議論フェーズにおいて記録された議論の中で、自分自身にとって有益な議論はどれか、どのような観点からその議論が有益なのか、といった解釈の付与を行う。続く探究フェーズでは、解釈の付与が行われた議論をもとに情報不足を補うために調査を行ったり、重要なアドバイスに基づいて、実験を行ったりするなど、適切なプロセスを行う。そしてそのプロセスを通じて新たなアイディアや知識を生み出す。最後の集約フェーズでは研究活動を行っている人間が自身の活動内容を把握し、発表資料として探究フェーズの結果をまとめることが求められる。そして作成された発表資料を用いて議論フェーズにて発表を行うことで新たな議論が生まれ、さらなるフィードバックを獲得することができる。以上の4つのフェーズは図のように繰り返し行われることで、個人の研究活動における生産性を向上させる。
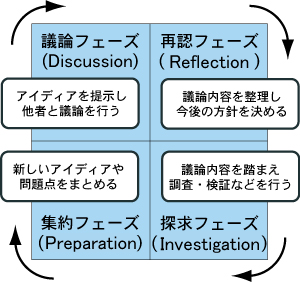
図5.1: DRIPサイクルの図
DRIPサイクルにおいて議論を行う議論フェーズに大きく影響を及ぼすと考えられるフェーズは、議論フェーズにて用いる発表資料を作成する集約フェーズである。そのため活発な議論を行うためには集約フェーズにおいて十分な準備が求められる。加えて活発な議論を行うには第2章で述べたように議論を行うために必要な知識を共有する必要がある。
そこで本システムではこのDRIPシステムと連携し柔軟な知識の共有化を目指す。本システムは過去の議事録を回顧することによって自分自身が参加していないような発表の知識も会議中に共有できるシステムである。しかし共有することのできる知識はこれだけではない。例えば探究フェーズにおける、調査によって獲得した情報や、実験の詳細な経緯や結果、あるいは作成したインタフェースのソースコードなどさまざまである。これらのような探究フェーズの結果としての知識は集約フェーズによってまとめられ発表資料として集約されるが、その過程で発表資料に組み込まれない知識もやはり存在する。そのような知識を臨機応変に参加者へ提示し、共有することで活発な議論展開が期待できる。
具体的な手法としてはサブディスプレイを用いての臨機応変な情報提示が考えられる。上述したとおり本来発表資料としては取り入れにくい探究フェーズの成果物が存在する。そのような成果物は本来は発表資料としては冗長な情報である。しかし実際の議論では臨機応変な対応が求められる。ときとしてそのような情報(例えば参考にした論文内容など)を提示することで議論参加者の理解を促すこともある。あるいは単に提示するだけでなく、本来のスライドと並行し、補足として情報を提示することで議論参加者の理解を促すこともある。
このような情報はDRIPシステムによって半自動的に関連付けがなされる。発表者はDRIPシステムを使用し、発表のパワーポイントを作成するだけで、探究フェーズでの成果物とパワーポイント間にリンク情報が付与される。そして本システムにおいては副次的な資料としてそれらを準備することなく利用可能にする。発表者はサブディスプレイ上に議論の状況に応じて任意に関連付けされた情報を提示することで、臨機応変な知識共有を行い、結果として活発な議論を展開できるだろう。
謝辞
本研究を進めるにあたり、指導教員である長尾確教授には、研究に対する姿勢や心構えといった基礎的な考え方から、研究に対する貴重なご意見、論文執筆に関するご指導など大変お世話になりました。心よりお礼申し上げます。
大平茂輝助教授にはプロジェクトゼミや研究室全体のゼミにおいて貴重なご意見をはじめ、論文の添削など様々な場面でお世話になりました。深く感謝いたします。
そして自分が所属するプロジェクトのリーダーである土田貴裕さんには研究的な面からプライベートな面において様々なご指導していただきました。ここにお礼申し上げます。本当にありがとうございました。
石戸谷顕太朗さんには研究やプライベートに関するご指導、さらにはプログラムに関するアドバイスなど様々な場面でお世話になりました。深く感謝いたします。
増田智樹さんには研究室全体のゼミやプライベートでの貴重なご意見をはじめ様々な場面でお世話になりました。本当にありがとうございました。
尾崎宏樹さん、森直史さん、安田知加さんには研究に関するご意見や、研究室生活における様々な面でお世話になりました。ありがとうございました。
井上泰佑さん、杉浦広和さんには卒業論文執筆にあたって非常に良い刺激を与えてくれました。ありがとうございました。
長尾研究室秘書である鈴木美苗さんには、研究室生活や学生生活の様々な面でお世話になりました。 ありがとうございました。
最後に、影ながら見守っていただき、生活を支えていただいた両親にも最大限の感謝の気持ちを伝えたいと思います。本当にありがとうございました。