
ディスカッションオントロジー:実世界の会議における人間行動から取得したメタデータ解析による知識発見
概要
本研究では、ディスカッションオントロジーの構築を目指し、メタデータを付与し構造化した会議情報の解析を行う。会議情報を構造化するために、Webブラウザベースのツールを用い実世界の会議に関する情報を獲得する。そして構造化された会議情報から、議論の中核となる発言がどのような意図で発されたか、機械学習を用いた判別ルールから推定し、議論構造の抽出を行う。抽出した議論構造から効率的に知識共有が可能な議論を行うための方法論の確立を目指す。
1 はじめに
我々は日常の活動として会議に携わる機会が多い。形式としては企業の役員会議のように場所・時間が決められ行われるものもあれば、近所の井戸端会議のようにそこに居合わせた人間で行われるものもある。また、内容としても何らかの問題事項に関して意思決定を目的とするものもあれば、お互いのアイディアを出し合いブラッシュアップするブレインストーミングを目的としたものまで、我々は多種多様の会議に囲まれている。人間同士のコミュニケーションを中心とする社会の形成には、他者との意見交換の場となる「会議」は不可欠なものである。
特にブレインストーミングを中心とする会議では、意思決定を目的とする会議と違い、いかに効率よく知識を共有できるかが重要となる。他者から多くの知識を短時間で得られた会議は一般的に評価が高くなるが、長時間にも関わらず得ることができる知識が少ない会議は評価が低い。ここで評価が高い会議を行うために必要な要素について、議論を行う必要がある。
この「良い会議」というものを行うために、現在進行中の会議への情報支援、再利用性の高い議事録の記録、そして会議に参加する人間自身のスキルの向上が必要であると考えられる。これらの要素に共通として必要となるのが、会議の構成要素やその要素間の関係を明確にした、会議に関するオントロジーである。これをディスカッションオントロジーと呼び、効率よく知識を獲得できる会議を行うための方法論を確立することが本研究の目標となる。
本研究では、ディスカッションオントロジーの構築を目指し、メタデータを付与し構造化した会議情報の解析を行う。会議情報を構造化するために、Webブラウザベースのツールを用い実世界の会議に関する情報を獲得する。そして構造化された会議情報から、議論の中核となる発言がどのような意図で発されたか、機械学習を用いた判別ルールから推定し、議論構造の抽出を行う。抽出した議論構造から効率的に知識共有が可能な議論を行うための方法論の確立を目指す。
2 ディスカッションオントロジー
本研究では、会議の構成要素やその要素間の意味関係を記述したものをディスカッションオントロジーと呼ぶ。会議の構成要素としては、一つの会議は複数の議論から構成され、さらにそれぞれの議論は複数の発言という要素から構成される。また、会議参加者や会議に使用する資料も会議の構成要素となる。これらの構成要素には議論と発言間の依存関係や発言と発言間の類似関係、会議資料と議論の対応関係など様々な意味関係が存在する。
さらに構成要素間の意味関係には、制約条件も含まれる。例えば、「質問を意図する発言の後には、その質問に回答する意図を持つ発言がくる」というものは会議を円滑に進める上で重要な制約条件となる。この意味関係や制約条件によって議論の形式化が可能になり、現在の議論の状況を把握することで会議支援を行うことができる。本研究では、会議に関する情報を蓄積し、メタデータを解析することによって、会議の構成要素のセグメンテーションや、要素間の意味関係と制約条件を明確にすることを目指している
3 会議コンテンツ生成のためのメタデータ取得
3.1 会議の構造化
実世界における会議(ここでは対面・同期式の会議)では、時系列に沿って会議が進行する。しかし、議論中の発言に着目すると、すべての発言が直前の発言を受けているわけではないように、会議を構成する発言・議論といった要素は必ずしも時系列で表現できるわけではない。そこで、会議内容を意味理解するためには、会議を構造化する必要がある。
本研究では会議の構造化とは会議を構成する要素、そしてその要素間の意味関係を明確にすることであると考える。つまり、会議のセグメンテーションを行い、各セグメントごとにリンクを付与することである。会議要素の切り分けや要素間の意味関係は、対象となる会議形態によって異なる。本研究で対象とする会議は、発表を中心とした会議とした。発表を中心とした会議、特にモデレータが発表資料としてスライドをプロジェクタに投影するような会議では、現在何を対象として議論がなされているかが明確にすることが容易なためである。
このような会議要素の抽出や意味関係の付与を自動的に行うのは困難である。そこでディスカッションマイニングという仕組みによって議論の構造化を半自動的に行う。
3.2 ディスカッションマイニング
会議支援や議事録作成の研究ではミーティングブラウザのように映像や音声の自動認識技術を用いることが多い。本研究で用いるディスカッションマイニングシステムでは、複数のカメラとマイクロフォンで議論の詳細な様子を記録するとともに会議参加者がブラウザベースのツールや、議論の構造化に必要なメタデータを入力するデバイスを用いて会議コンテンツを生成していく。ディスカッションマイニングシステムのイメージを図に示す。
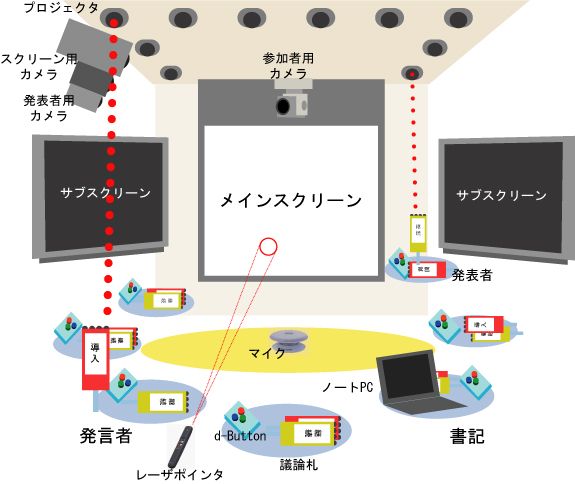
図1: ディスカッションマイニングシステム
また本研究では発表者がMicrosoft PowerPointのスライドを用いて発表を行い、その内容に対して参加者が議論を行う会議を対象とする。スライドに含まれるテキスト内容やスライドを切り替えるタイミングなどは発表者が専用ツールを用いることによって自動的に記録される。また、会議中の発言は議論札と呼ばれる札型のデバイスを用いることで、発言者のIDと「導入(Start-up)」「継続(Follow-up)」という発言の種類、発言の開始時間、終了時間が入力される。具体的な発言内容は、書記が専用ツールを用いて記録を行う。また会議参加者はボタンデバイスによって、現在行われている議論に対する自身のスタンスを表明することができる。議論の記録はXMLとMPEG-4によるマルチメディア議事録としてデータベースに記録される。記録された内容は、Webブラウザを用いて検索・閲覧が可能となっている。
ディスカッションマイニングでは発言者の発言のタイプを議事録構造化の視点から、「導入」と「継続」の2つに大きく分類する。発言の持つ意味については多くの議論があるが、議論の構造化とは議論のセグメンテーションであると考えている。つまり、現在行っている発言が直前の発言(あるいはいくつか前の発言)を受けてなされるものなのか(継続)、それとも新しい話題の起点なのか(導入)が議事録理解に大きな影響を与えていると考える。
3.3 会議記録の利用
議論を構造的に閲覧するためには、発言と発言間の関係を明確にする必要がある。グラフビューでは構造化議事録の閲覧とともに、アノテーションによる発言間の関係付けを行うことができる。グラフビューを図に示す。
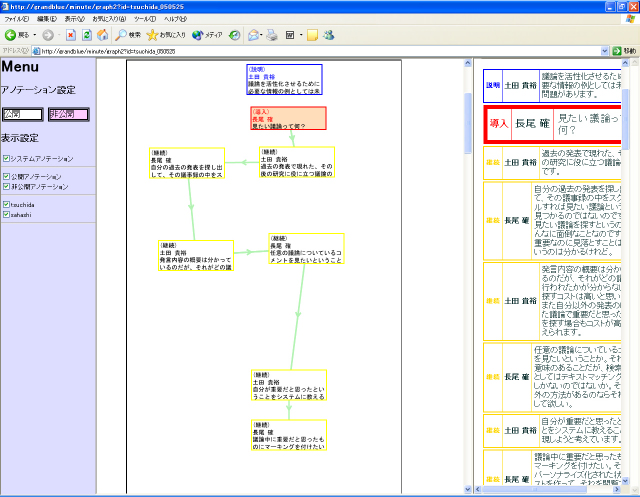
図2: 議事録グラフビュー
会議のより詳細な様子を把握するためには、実際の会議映像を効果的に提示するのが有効である。ディスカッションマイニングでは、詳細な議論閲覧のための視聴支援インタフェースが用意されている。視聴支援インタフェースを図に示す。

図3: 議事録視聴支援インタフェース
4 メタデータ解析による発言の分類と議論展開の抽出
会議の議論において要素となる発言には、何をテーマとして発されたかという情報と、どのような意図で発されたかという情報が含まれる。前者の内容情報は議論の具体的な情報を把握するために重要であるが、後者の意図に関する情報はどのような展開で議論が進められていったかを把握することに有効である。この議論における意図情報の展開を議論展開とし、抽出することを試みる。議論展開を抽出し、人手で付与した重要度などと照応させることで重要度の高い議論展開の持つ性質を発見することができる。これは会議構成要素の意味関係の一つである発言間や議論間の依存関係の明確化へ発展させることができる。
議論展開抽出の手順は以下の通りである。まず、発言にはどのような意図が含まれるかの検証を行う。発言に付与する意図に関する情報を意図タグとし、蓄積された会議に関する情報から妥当な意図タグセットを決定する。次に、会議要素に含まれる各発言が決定した意図タグセットのどの意図に該当するか、分類を行う。全ての発言に対し意図タグを人手で付与することは困難であるため、発言に含まれる情報(発言者や発言タイプなど)から付与すべき意図タグを推定する。そして一連の議論に対し、意図タグを付与した場合に、連続する意図タグの種類や共起する意図タグを調査することで、頻出する議論展開を抽出する。
4.1 発言意図タグの決定
会議の発言に対し意図タグを付与することで、様々な目的に利用することができる。前述したように議論展開の抽出に用いることもできるし、働き掛けや応答のような、局所的な議論構造を調べることで対面式のコミュニケーションの特徴を明らかにすることや、構造の変化に伴うコミュニケーション効率の変化を明確にすることもできる。
利用する意図タグセットは、信頼性を高めるために標準化されたタグに基づいて作成されるべきである。当然利用する目的により意図タグは変化するものであるが、抽象度の高いタグを安定して付与できることが求められる。そこで本研究では、発話単位タグ標準化案を基に意図タグセットを作成した。発話単位タグ標準化案では、働き掛けやその働き掛けに対する応答といったやりとりを大きな分類とし、その下位分類として発話内行為を位置付けた1次元タグセットから構成されている。また、発話単位タグの安定性を向上する目的で、タグ付け作業を行うための決定木が用意されている。
そこで、会議情報として蓄積している4議事録に対し複数人でタグ付け作業を行い、発話単位タグの頻度分布を基に、本研究で利用する意図タグセットは以下のものとした。
-
未知情報要求
話者が相手に何らかの値あるいは表現を応答として要求する発言
-
真偽情報要求
話者が相手にYesまたはNoを応答として要求する発言
-
未知情報応答
未知情報要求に対し、その値を返す発言
-
真偽情報応答
真偽情報要求に対し、肯定あるいは否定する発言
-
応答要求に対し直接的に応答を返していない発言
応答保留
-
話者が自分の持つ知識を述べる発言
情報提示
-
話者が相手に行為を要求する発言
示唆・提案
-
意見・希望
話者が自分の持つ意見や希望を述べる発言
4.2 発言意図の分類
ディスカッションマイニングで蓄積された議事録数は370を超え、含まれる発言数も約14500に上る。この発言を前述の意図タグセットに分類することは人手では困難であるため、各発言の持つメタデータを属性として、機械学習アルゴリズムC4.5を用いて意図タグの推定を行い、人手で修正する方法を取った。
機械学習に用いる発言に関するメタデータとして、「発言者」「発言の種類(導入か継続か)」「直前の発言の種類」「発言時間」「キーワードの有無」などの情報が獲得できる。これらを属性とし、3議事録に対し人手で付与した意図タグを正解とした訓練例を作成し、意図タグの判別ルールを作成した。意図タグの判別ルールの例を以下に示す。
-
未知情報要求
発言の種類=導入、発言者=発表者以外の参加者、キーワード=有、発言時間=短(20秒以内)
-
意見・希望
発言の種類=導入、発言者=発表者以外の参加者、キーワード=無、発言時間=中程度(21秒-40秒)
判別ルールを適用した結果、複数の意図タグを含む発言の場合には該当する意図タグ全てを付与することにした。これは一つの発言であっても複数の意図が含まれる場合があるからである。例えば、未知情報要求の意図を持つ発言があった場合に、発言には呼応する未知情報応答とともに情報提示や意見・希望の意図を持つ場合もある。判別の精度は適合率が83%であった。判別した後、人手により意図タグの修正を行った。
4.3 発言意図に基づいた議論構造の抽出
ディスカッションマイニングでは、議論札によってそれぞれの発言に「導入」「継続」の情報が付与される。議論は導入発言から始まり、その発言に対して議論が継続されるなら継続発言が続いていく。この1つの導入発言とそれに付随する複数の継続発言をまとめて議論セグメントと呼び議論の単位とする。
次に、蓄積された20議事録対し議論展開の抽出を行い、頻出する議論展開や発言意図の共起頻度を調べた。頻度の高い10項目を表1に示す。
出現頻度の高い意図タグによる議論展開は、会議における議論の進め方の手本の一つになるだろう。つまり、頻出する議論展開は議論の文法であり、これに従った議論の進行はある一定の成果をもたらすと考えられる。逆にこの議論の文法から逸脱する展開の場合には、議論を発散させる恐れがあり、効果的な議論を阻害させる可能性がある。
議論展開の利用として、以下のようなことが考えられる。抽出された議論展開から、任意の議論間の類似性や差分を発見することができる。抽出した議論展開の比較(パターンマッチ)から類似する展開を持つ議論の発見を行ったり、同内容の議論の展開比較を行うことで議論差分を発見したりすることができる。
また、抽出された議論展開は、議論の特徴とすることができる。これによって議論の文法を定義することができると考えられ、また議論要約や一つの議事録の要約も行うことができる。例えば、質問とそれに対する回答が繰り返される、という議論パターンの場合は、質問→回答→質問→回答の繰り返し、という議論展開となる。ここに含まれる繰り返しパターンを省略することにより議論の要約が可能となる。
5 まとめと今後の課題
本研究では議論における発言形式の分類や、発言の形式を中心とした議論展開の抽出を行った。構造化された会議情報のメタデータ解析によって、会議の構成要素の重要性が明確になり、会議議事録の利用において必要な情報の取捨選択が可能になる。さらには会議コンテンツを構成する要素間の意味関係が明確になり、ディスカッションオントロジーを構築することが可能になるだろう。また、従来行われてきたテキスト処理によるキーワードを中心とした議論からの知識発見技術と併せることによって、内容・形式に基づいた効果的な会議議論からの知識発見支援が期待される。
今後の課題として以下のことがあげられる。
・ディスカッションオントロジーにおける会議音声・映像の意味付け
・類似するテーマや議論を持つディスカッション・グループの発見支援のための議事録公開環境の整備