
A Music Recommendation System Based on Annotations about Listeners' Preferences and Situations
Abstract
In this paper, we present a playlist generation scheme that uses lyricsand annotations to discover similarity between kinds of music and usertastes. It generates a playlist according to user preferences andsituations. Additionally, users can provide some feedback to the systemsuch as whether each song is suitable for preferences and situation.The system transforms the feature values concerning preferences andsituations and adapts them to each user.
The playlists are generated through three phases. First, an initialplaylist is found from databases by collaborative filtering. Second,transcoding improves the playlist according to the user's preference andsituation. Finally, by interaction between the system and the user, theplaylist becomes more suitable for the user.
1 Introduction
Recently, many people can easily listen to music anywhere/anytime byportable digital music players that have large memory capacity, andthere are many music files in the Internet. At present, Pod Castingthat enables iPod users to import many contents such as music and radiofiles automatically is already available. Like this, it is desired thatusers can import suitable contents from vast amount of contents withouttheir intent to their portable players .
Many researches on music recommendation and automatic playlistgeneration are actively in progress. Several music distributionservices such as iTunes Music Store are already available on the Web.In the near future, fixed charge services will be applied to musicdistribution. Many Web users will be able to share and recommendplaylists without music data itself so that a playlist consists of anumber of music IDs only.
Several researches on music recommendation have concluded thatcollaborative filtering or the method to use musical metadata (genre,artist, etc.) efficiently recommends music. Though, there are severalkinds of information that are difficult to collect for eachsong.Thus, it is necessary that the method to collect suchinformation immediately.
It can be said that interpersonal communication using text, drawing, andpicture through Blog and SNS (Social Networking Service) becomes active.Though music is difficult for many people to compose and perform as theywant , it is easily able to create playlists that reflects creators'idea and affection. In case of a playlist, a listener of it also can bea creator at the same time. Therefore we think that playlist will beone of media for future communication as well as text, drawing, andpicture. We call it the playlist-mediated communication.
Based on the above considerations, we think that it becomes moreimportant for people to express an individual mental state and situationand the relationship between a listener and a song via a playlist.However, these are inherently subjective and personal. In a typicaltechnique for handling an individual mental state and situation, theyare represented as attribute-value pairs for the attributes that areselected beforehand. For the relationship between a listener and asong, a conventional technique have been developed for extactingfeatures common among people, rather than personalized features.Actually, it is difficult to determine whether a song is suitable for asituation of a listener in a mental state, for example, only with genre,artist, and acoustic information of sound. Then, we focus theannotation technology for treating such subjective and personalinformation.
In the Semantic Web technology, annotation is widely recognized as ameans for flexibly describing meat data of contents, such as genre,artist, personal and/or public comments .Annotation is appropriate for immediate collection and flexibledescription of such subjective and personal information.
As a starting point, we propose a playlist recommendation method thatencourages playlist generation and recommendation. We employed not onlyconventional musical metadata but also annotations to take accountuser's preference and situation into consideration. In the situationthat the playlists are shared with many users, narrowing down bycollaborative filtering is effective to consider each user's preference.In addition to collaborative filtering, it uses transcoding to convertan initial playlist into a more suitable one that reflects thepreferences. Additionally, interactions between the system and thelistener can polish his/her preferences.
The paper is organized as follows. Section 2 describes the detail ofour playlist recommendation system. In Section 3, we evaluate how well oursystem works. Finally, Section 4 concludes the paper with mentioningfuture work and perspectives.
2 Playlist Recommendation System
It is general said that several types of feature values are effectivefor music recommendation.On the other hand, we suppose that listner's situation is crucial for musicrecommendation, in accordance with our ordinary method of enjoyingmusic. Then we construct a playlist recommendation system usingannotations based on listeners' preferences and situations. In thisresearch, the following are adopted as musical feature values: lyrics,musical scene, and listening situation.
2.1 Estimation of similarity between songs using lyrics and annotations
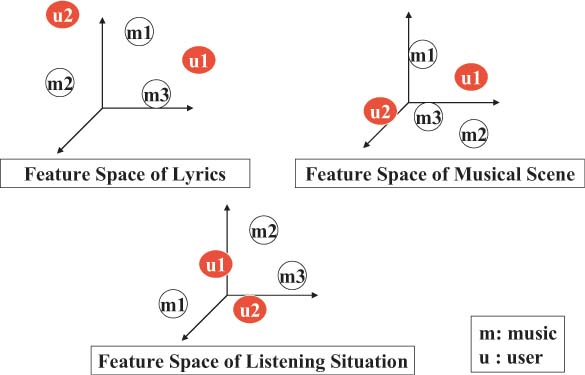
Fugure1: Feature spaces of lyrics, music scene and listening situation
Since information of musical scene and listening situation stronglydepends on listener aspects, it is hard for automatic analysis tocollect these information. Therefore several kinds of information oflistener aspect are collected for each song by musical annotationsystem, and we apply them to musical feature values. With the musicalannotation system, we can associate each song with musical scene andlistening situation. The information of musical scene and listeningsituation are gathered from a multi-item questionnaire.
Since annotations associated to each song do not contain equal amountsof information, annotation is made by users instead of by computer. Interms of musical scene and listening situation, the averages ofannotations are regarded as the feature values of each song.At the same time, keywords are extracted by TF*IDF(Term Frequency*InverseDocument Frequency is general method of keyword extraction.)from lyrics to map each song to the feature space of lyrics.
Feature values ,
, and
are the featurevalues of lyrics, musical scene and listening situation of music
.These values are all vector value and
is defined as followingformulas.
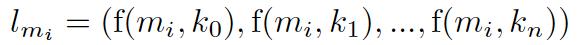
Fugure2: Vector value of lyrics
The number of keywords is and
means the No. i keyword. Thevalue of
come to 1 when the lyric of music
containskeyword
, and come to 0 when the lyric doesn't contain the keyword.
Figure \ref{fig2_2} shows feature spaces that feature values of lyrics,musical scene and listening situation is mapped. Each song shown as m1,m2 and m3 and each users shown as u1, u2 are mapped to the featurespaces. Cosine coefficient of any two songs was derived from featurespaces. Then musical similarity between music
and
can be calculated by each weighted cosine coefficient:
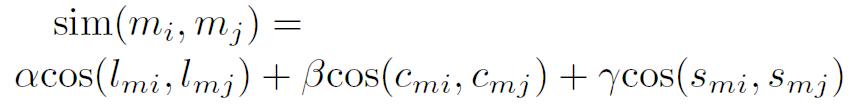
Fugure3: Similarity between two songs
Coefficients ,
, and
are the weights of the featurespaces of lyrics, the musical scene, and the listening situation,respectively. cos (a,b) denotes cosine coefficient. By using thisfunction, the similarity between two objects can be calculated. Sincethere are a number of feature spaces, the weight of each feature spacecan be adjusted by the feature value that is enhanced. The systemgenerates a particular playlist suitable for a user's situation. Then
as the weight of the listening situation is bigger than
and
.
Several studies on music recommendation methods have concluded that suchmusical metadata as genre or artist effectively recommend music. Oursystem can also import such effective metadata so that these featurevalues are mapped to multiple feature spaces.
2.2 Sequence of playlist generation
The system contains favorite songs from histories of playlistgeneration. Assuming that a listener's ideal song reflects his favoritesong, the user can be mapped to the above feature spaces of lyrics andmusical scene. A listener's situation can be mapped to the featurespace of listening situation when the system acquires it. Similaritybetween arbitrary songs and listeners can also be calculated.
Figure shows the playlist generation sequence. The systemgenerates a playlist through these three phases. First, an initialplaylist is found from playlist databases by collaborative filtering.To find similar listeners, listener similarity is calculated by cosinecoefficient from triple feature spaces. We regard listeners as similarover a certain threshold. Then, the similarity of listener's situationand the situation in which each playlist is created is derived. Fromplaylists over certain thresholds, one initial playlist is sought thatconsiders listener and situation similarities.

Fugure4: Sequence of playlist generation
Second is the transcoding phase where the suitability of the initial playlist is improved to match listener preference. In concrete terms, songs that listener give feedback as unsuitable are removed from the playlist. At the same time, the system introduces several songs that listener is not listened into the playlist at the rate of 30\%. By this process, the listener is able to listen new songs moderately.
Alternative songs are found by using similarity between the user and each song.In advance, the user is mapped to each feature space.From the user's preference and listening situation, similarity is calculatedby using cosine coefficient and the weight of each feature space.This process is equal to the calculation of musical similarity.
Through the above process, an improved playlist is displayed, as shownin Figure . The generated playlist is displayed on the leftside, and the playlist displayed on the right side is initial playlistsought by collaborative filtering. A playlist player is embedded abovethe playlist. Listeners can operate the player as well as general musicplayers.
The user actually can enjoy the playlist and offer such feedback to thesystem as whether each song is suitable for preferences and situation.Then the system presents a fine-tuned playlist according to thesefeedback. Besides, the system updates the user's preferences by usingsuch feedback. In concrete terms, the base vectors of each featurespace are transformed. The following formula transforms the base vectorof the lyrical feature space:
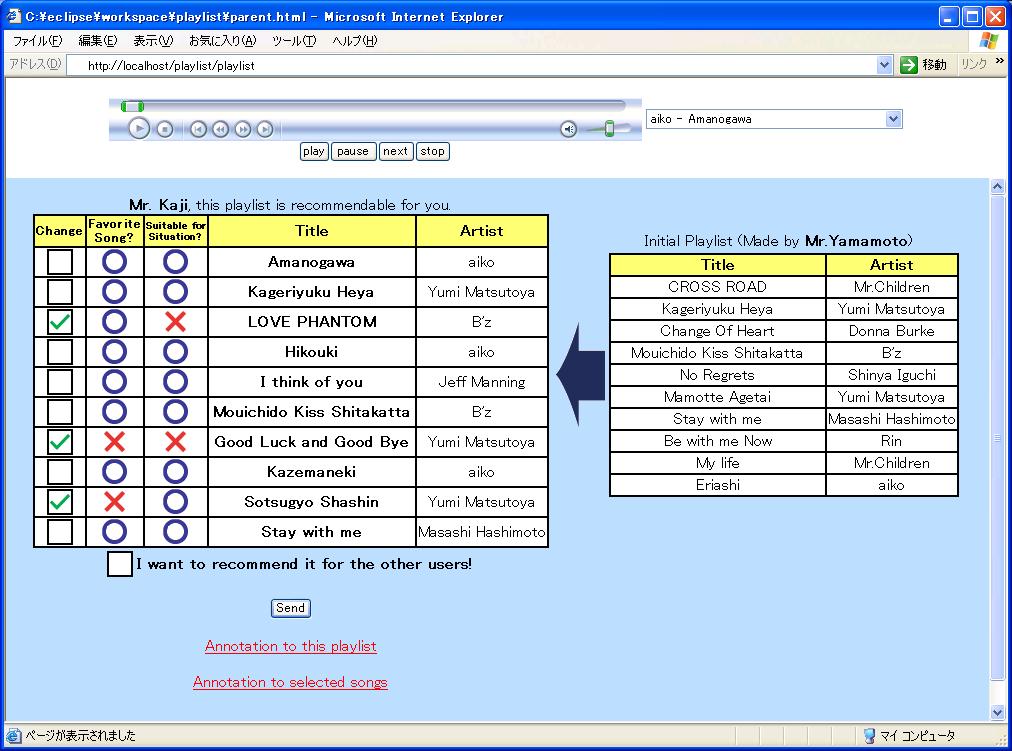
Fugure5: An example of generated playlist
Lyrical base vector of user is depicted as
.Feature value
means the average feature value of music fed backas favorites. Contrarily,
is the average feature value of musicfed back as disliked. The rate of transformation is depicted as
. Though the propriety the value of
is still underconsideration, we allocate 0.1 to it. In this transformation, basevectors are expanded in the direction of the dislike feature value andflexed in the direction of the favorite feature value. As concerns thebase vectors of the music scene and listening situation, they are alsotransformed by same method.
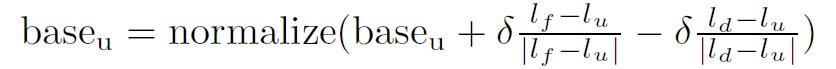
Fugure6: Transformation of lyrical base vector
The system preserves user's feedback such as favorite songs,songs suitable for each situation and generated playlists. These areapplied to collaborative filtering and transcoding.
2.3 Acquisition of listening history and its reflection to user profiles
Generally, as ideal information introduced into user profiles, the history of appreciated contents is given. To collect the information, the system embeds a playlist player into the web browser that users can operate as popular music players. The player feedbacks users' operation histories as frequency at which the music was listened to. Then, user profiles were updated with the information.
Such operation histories aren't useful for updating user preferences, but they are useful as musical annotations. Annotations, in the shape of listener aspects, are not equally collected by each song. So music that lacks annotation can compensate by using information of operation histories. For example, when music is often listened to in certain situations, the music is suitable for those situations.
3 Experimentation
We use 230 pieces (100 from the RWC music database and 130from Japanese pop songs). For preparation, annotations of musical sceneand listening situation is collected for each song.
We evaluate how well our system works with seven subjects by the followingprocess. Listening situations are assumed freely to each subject andare input to our system with a situations declaration formThen the system presentsplaylist suitable for subjects' preferences and situations. Next, thesystem let subjects express their preferences with buttons on a screen,and refined playlists are presented again.The process is repeated until the playlists become completelysatisfied.The playlist generation process is repeated three times.
Our system can consider user's preference, situation and the number ofinteraction when generating a playlist as described in Section 2.2, andwe evaluate our system under four conditions in terms of the parameterstaken into account: preferences, situations, preferences & situationsand the number of interaction.There are four groups in Figure, one of which are further made of three bars; a three-bargroup corresponds to each condition. The three bars depict first,second, and third generations of refining a playlist, respectively. Thearrowhead of each bar denotes standard deviation.
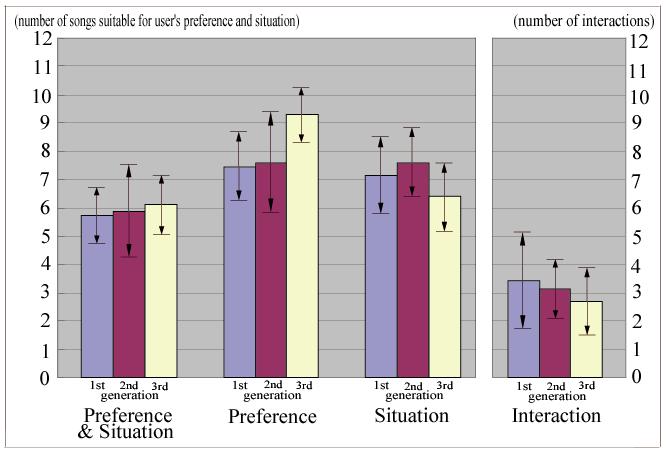
Fugure7: The result of experiments
For the condition of preference only shown in the second group in Figure, the amount of songs suitable user's preference increses;this means that the system can provide a better playlist by repeatedplaylist generation. Additionally, the number of interactions shown inthe right most group decreases. The number of songs suitable forpreferences and situations shown on the left group also increases.Thus, subjects get satisfactory playlists provides a betterplaylist as a generation proceeds
On the other hand, the number of songs suitable for situations,shown at the third group from the left, shows no tendencies afterrepeated playlist generation.
This is because when the system infers information of user's preference,we have faced two problems: (1) the number of situations is relativelylarger than that of songs (so called the sparseness problem), and (2)annoations are not added to all songs impartially. We call the latterbiased annotation problem. To solve the problems, it is necessary toguide a user to pay attention to songs that lack annoations. Moreover,it seems to be efficient to apply users' listening operation historiesto the annotations.If a song is listened to many people under certainsituations, it can be regarded that the song is suitable for the situation.Though, the information possess lower reliability than thesame type of annotations created by users.When the information is applied to the system,we have to take account of the weight of each synonymous kind of annotation.
4 Summary
For the realization of playlist-mediated communication, we aim toencourage of playlist activity like generation, recommendation andappreciation. As a starting point, we have develop a playlistrecommendation system. Using our system through the experiments, wehave found that annotation can describe more precisely and dynamicallyan individual user's mental state and situation and each relationship ofa user and a song. At the same time, we found that collaborativefiltering, transcoding and interaction are efficient to generateplaylist suitable for a user. Additionally, we have accomplished theencouragement of playlist generation and recommendation.
Finally, we briefly mention future work. The playlists generated by ourproposed system are supposed to be shared among many people. In thesituations, communication through playlists is necessary. Therefore, weare implementing a playlist annotation system that enables users to addremarks to the playlists. Furthermore, we think it is important todevelop a method to enhance the appreciation of the playlists.