
映像と論文へのアノテーションに基づく論文読解支援に関する研究
概要
特に映像は,システムや人間の動作など,論文では表現できない様々な情報を含んでおり,論文と併せて視聴することで理解を深めることができる.しかし,一般に論文と映像は共に様々な意味情報を含んでおり,映像を論文と一緒に閲覧する際,論文の部分に関連する映像シーンを選択的に視聴しないと理解が深められないと考えられる.そこで本研究では,映像と論文の部分要素の定義,そして要素間の関連性についての情報をアノテーションとして記録・蓄積する.そして,それらの関連性を利用した,複数の映像と論文の閲覧を効率的に行う仕組みを提案する.
まず,映像と論文の部分要素についてのアノテーションを付与するための仕組みを実現した.映像に対しては,映像シーンの開始・終了点とシーンタイトル,そしてコメントをアノテーションとして付与する.論文に対しては,論文部分の領域についての情報と,部分に対する翻訳やコメントなどのテキストをアノテーションとして付与する.次に,得られた部分要素間の関連付けを行うための仕組みを実現した.
そして,得られた関連性を利用して,複数の映像と論文を閲覧するシステムDocvie (Document with Movie)を実現した.Docvieでは,映像と論文を,関連情報を参照しながら閲覧する論文中心モードと映像中心モードの2種類の閲覧方法を利用できる.これらのモードを切り替えながら関連情報を辿ることで,複数の映像と論文を効率的に閲覧できる.
最後に,Docvieの有用性を確認するために被験者実験を行った.被験者に映像シーンを視聴してもらい,シーン中で説明されている研究についての設問の回答を,Docvieを利用した場合と,関連情報を参照しながら論文を閲覧する別のシステムを利用した場合の計2回行ってもらった.その結果,いずれの被験者についても,Docvieを利用した方が,問題に回答する時間は短く,かつ多くの問題に回答することができた.また,Docvieの使いやすさや,映像と論文を一緒に閲覧することの有効性についてのアンケートに答えてもらったところ,提案手法に対する高い評価が得られた.
1 はじめに
研究者にとって,先行研究の調査は非常に重要である.Takeshimaらによると,先行研究の調査は,研究活動の初期段階においては,自らの研究分野についての知識を深め,研究の方向性を決定するために行われる.次の段階では,自分の研究と関連する研究について,自分の研究の視点から理解し,考察するために行われる.そして最終段階では,研究論文を執筆する時に,関連する論文を分類するために行われると述べている.
研究者が先行研究の調査を行う場合,発表や講演会などへの参加,論文や映像の閲覧など,様々な方法がある.その中でも論文には,研究についての背景,目的,アプローチ,実験,考察,今後の課題,参考文献などについての情報が体系的にまとめられており,研究内容の理解に役立つ.
しかし,論文を読んでも内容を十分に理解できない場合がある.例えば,システムの動作や実験風景などについて,文章や図では状況を十分に想像しづらい場合,また,論文で述べられている内容が難解である場合などである.このような場合,参考文献に挙げられている論文や関連する映像など,論文に関連するコンテンツを参照することで,理解が深まると考えられる.その中でも特に映像は,文章では表現が難しい様々な情報を視覚的に表現することが可能であり,論文の理解に役立つと考えられる.
実際に,研究内容を発信するために,Web上に研究に関連する映像を公開しようという動きが高まっている.大学などの研究機関では,ホームページやYouTubeなどの動画共有サイトで,システムの動作映像や研究発表の映像などの研究内容に関する映像を公開している.ACM(Association for Computing Machinery)やIEEE(The Institute of Electrical and Electronics Engineers, Inc.)などをはじめとする学会でも,ビデオプロシーディングスや講演などの映像をホームページ上で公開している場合がある.このような動きは,今後もより活発になると考えられる.そのため,論文と映像を一緒に閲覧する機会は今後増えていくと考えられる.
しかし,読み手が論文を理解するために,関連するコンテンツを参照する際に,論文の文章から意識が離れてしまう.そして,コンテンツを参照した後に論文に戻る際に,読んでいた内容を思い出す必要がある.島崎らは,このときの思い出すという過程が読み手にとって負担であり,これを解決するために情報の閲覧・活用がシームレスに行わなければならないと述べている.
論文と関連するコンテンツをシームレスに閲覧するためには,論文のどの部分に対して,コンテンツのどの部分が関連しているかを明示することで支援できると考えられる.これによって,論文に関連している情報を読み手が探す時間を短縮できると考えられる.例えば,論文の部分に関連する映像の部分(以下,映像シーンと記述)が明示されていれば,映像が長時間にわたる場合でも,短時間で論文に対する理解を深めることができると考えられる.
また,論文と,論文に関連するコンテンツを統合し,一つのコンテンツ上で表示させることができれば,情報を参照するためにコンテンツ間を移動する必要が無くなり,情報の参照をよりシームレスに行うことができると考えられる.複数のコンテンツの情報を統合し,新たなコンテンツを生成する手法として,マッシュアップコンテンツの研究が注目されている.マッシュアップコンテンツとは,複数の異なるコンテンツを複合させることで生成される,新たなコンテンツのことである.マッシュアップコンテンツの例として,Google Mapsが挙げられる.Google Mapsでは,地図情報をベースに,お店などの場所に関連する情報を動的に統合して表示している.
本研究では,Web上に存在する研究活動を目的としたユーザの活動から得られた情報を利用することで,映像と論文のマッシュアップコンテンツを生成し,論文読解支援を行う手法を提案する.
本研究では,以下の手順でマッシュアップコンテンツの生成を行う.
-
映像・論文を構造化し,部分要素を決定する
-
映像の部分要素とシーン間の関連情報を取得する
-
取得した関連情報を基に,コンテンツのマッシュアップを行う
映像や論文などを構造化する手段として,アノテーションについての研究を利用することができる.アノテーションとは,アノテータがコンテンツに対して付与したメタ情報のことである.アノテーションは,コンテンツから知識を抽出し,共有・活用するために利用することができる.
アノテーションは,映像コンテンツや文書コンテンツなどに限らず,画像,音声,音楽などのコンテンツ一般に対して適用可能な技術であり,これまでにも多様なコンテンツに対するアノテーションの研究が行われている.また,複数の異なる種類のコンテンツに対するアノテーションを統合的に記録・蓄積することで,複数のコンテンツを同時に利用したアプリケーションが容易に作成可能となる.
アノテーション手法には,映像に対しては画像認識や音声認識,論文のような文書に対しては形態素・構文解析のような技術を利用することでアノテーションを抽出する自動アノテーション手法や,これらに加えて専任の人間が専用のツールを利用して高品質なアノテーションを付与する半自動アノテーション手法,また,Web上の不特定多数のユーザの活動から得られる情報からアノテーションを抽出するオンラインアノテーション手法などが提案されている.本研究では,オンラインアノテーション手法を利用することで映像,論文の構造化を行う.研究活動を目的としたユーザの活動からアノテーションを取得する.
例えば,我々が論文を読む際,英語などで書かれていた場合は日本語に翻訳する.また,重要だと考える部分に対しては注釈を加えながら読む.このような論文の部分要素に対する情報をアノテーションとして記録・蓄積する.
本研究では,論文に対するアノテーションを記録・蓄積するために,TDAnnotatorを開発した.TDAnnotatorでは,PDF形式の論文の各ページを画像として抽出して表示する.ユーザは論文の一部分を矩形として選択する.そして,矩形内に含まれる情報が図・表・文章・タイトルなど,どのような種類に分類されるか,また,矩形内に含まれる文章に対して翻訳・書き起こし・コメントといった情報をアノテーションとして記録・蓄積する.このシステムを用いることで,ユーザ間で論文に対する情報を共有することが可能となり,既に情報が付与された論文に関しては,後から読むユーザは自分が一度も読んだことが無い論文を,情報があらかじめ付与された状態で読むことが可能となり,ユーザの負担が軽減されると考えられる.
また,映像に対するアノテーションを記録・蓄積するために,我々の研究室で開発・運営されている映像アノテーションシステムSharvieを利用した.Sharvieでは,ユーザは映像の再生に対応して上下左右にサムネイル画像が流れていくサムネイル画像シークバーを利用して,シーンの開始・終了点を決定する.開始・終了点を決定したシーンに対して,シーンタイトルやコメントなどを付与することで,シーンの作成を行う.このときに得られたシーンに対する情報を,映像に対してのアノテーションとして記録する.
以上のようにして,映像・論文の各コンテンツにアノテーションを付与し,構造化を行う.
論文読解時に関連するシーンを視聴するためには,論文の部分要素とシーンの関連情報を記録・共有する必要がある.このために,我々の研究室で開発・運用されているDRIPシステムを利用した.DRIPシステムでは,議論時に得られた発言や,自分が考えたことをまとめたノートなどの情報を記録する.そして,記録した情報を引用してノートや発表資料などを作成することで,過去の研究活動を踏まえながら研究活動を行うことを支援するシステムである.このシステム上に,シーンと論文の部分要素の情報を記録した.これによって,ユーザはシーンと論文部分の情報を踏まえた研究活動を行うことが可能となる.DRIPシステム上で,シーンと論文の部分要素が同時に引用されたという情報をアノテーションとして記録する.このようにして得られたアノテーションから,論文の部分要素とシーン間の関連情報を取得する.
アノテーションから得られたシーンと論文の部分要素間の関連情報を利用することで,映像と論文を組み合わせたマッシュアップコンテンツの自動生成が可能となる.
本研究では,論文読解を支援するためのマッシュアップコンテンツとして,第一にTDAnnotator上での論文閲覧中に,関連する映像シーンと論文部分の提示を行った.これによって,論文の部分に関連付けられた映像シーンと論文部分を閲覧できる.このように,論文を,関連情報を参照しながら詳しく閲覧することが可能となり,論文を理解するのに役立つと考えられる. %このように,論文の部分要素・アノテーション・シーンをシームレスに閲覧することが可能となり,論文を理解するために役立つと考えられる.
第二に,論文と映像をシームレスに閲覧可能な論文読解支援システムDocvieの開発を行った.Docvieは,論文の部分要素に関連する映像シーンを提示し,ユーザは論文と映像を一緒に視聴することで,論文に対する理解を深めることができる.また,映像シーンを視聴するだけでなく,映像全体を視聴することで,映像に対する理解を深め,関連する論文の理解に役立てることもできる.加えて,TDAnnotatorで得られたアノテーションを表示することで,論文の理解を深めることができる.Docvieでは,論文に関連する複数の映像や論文を閲覧可能である.その際に,コンテンツの移動によって生じる,元のコンテンツについて思い出すときの負担を軽減するために,論文に関連するコンテンツとの移動を迅速に行うことで,論文読解を支援する.
Docvieを利用することで,論文に対する理解を迅速に行い,論文読解が支援されたことを検証するために,被験者実験を行った.被験者に,映像シーンを視聴してもらい,映像シーンで説明されている研究についての設問に対して制限時間内に回答を行ってもらった.実験は,設問回答時にDocvieを用いた場合とTDAnnotatorを用いた場合の2回行った.設問回答に利用したシステムの違いによって,設問の回答数,正解率,各設問の回答に要した時間についての比較を行った.その後,DocvieとTDAnnotatorの使いやすさについてアンケート調査を行った.
以下に本論文の構成を示す.本論文は本章を含めて7章から構成される.第2章では,研究活動における論文読解について詳しく述べる.第3章では,映像と論文の部分要素を作成するために作成したSharvieとTDAnnotatorについて,またそれぞれで作成された要素を関連付けるための仕組みであるDRIPシステムについて述べる.第4章では,収集される関連情報を利用したマッシュアップコンテンツである論文読解支援システムDocvieについて述べ,次の第5章でDocvieの有効性を検証した実験について述べる.第6章では,関連研究について述べる.そして,最後の第7章で,本論文のまとめと今後の課題について述べる.
2 映像を利用した論文読解支援
本研究では,映像と論文を効率的に閲覧可能にすることで論文読解支援を行うことを目的としている.そのため,まずは研究活動における論文読解の重要性と,どのような状況および手順で論文読解が行われるかについて明確にする必要がある.次に,映像が持つ特徴について述べ,映像を利用する利点と問題点,必要な支援について述べる.
本章では,まず第2.1節において論文読解の目的について述べる.次に第2.2節において,論文読解がどのように行われるかについてと,読解中に情報を参照することの重要性について述べる.さらに第2.3節で論文読解時に映像を参照することについて述べ,第2.4節で本研究の目的である論文読解支援について述べる.最後に第2.5節において,本章のまとめを行う.
2.1 論文読解の目的
論文読解の目的は,研究活動の初期段階においては,自らの研究分野についての知識を深め,研究の方向性を決定するために行われる.次の段階では,自分の研究と関連する研究について,自分の研究の視点から理解し,考察するために行われる.そして最終段階では,研究論文を執筆する時に,関連する論文を分類するために行われる.
2.1.1 先行研究を踏まえることによるより良い研究活動
先行研究を理解することで,研究分野についての以下のような知識を深めることができる.
-
現在どのような研究が注目され,活発に行われているか
-
過去にどのような研究が行われてきたか
-
どこの研究機関が先進的な研究を行っているか
現在どのような研究が注目されているかを知ることは,自分がどのような研究を行っていくかを決める上で参考になる.多くの研究者が扱っている問題を解決することは,その研究分野にとって大きな意味があるためである.
過去の研究を理解することで,自身の研究に役立てることができる.例えば,自分の研究を進める上で,先行研究で提案されている手法や実験方法を参考にできる.また,過去の研究で提案されている手法や実験方法などを踏まえることで,自らの提案する手法に説得力を持たせることができる.
自身がテーマにしている研究が,他の研究機関でどこまで進んでいるかを知るために,最新の研究の動向には常に注目している必要がある.そのため,自身の研究分野において,どこの研究機関が先進的な研究を行っているかを知ることは重要である.
2.1.2 参考文献による自身の論文の信頼性の向上
多くの論文を読解し,先行研究を踏まえた研究を行うことは,自らの執筆した論文の信頼性を向上させることにつながる.井上らは,Wikipediaを対象に,参考文献の引用数を利用した記事の信頼性評価を行い,多くの参考文献が引用されている記事は,引用文献の少ない記事に比べて信頼性が高いと述べている.このことは,論文についても同じことが言えると考えられる.参考文献が無い論文は,そこで述べられている手法や実験方法だけでなく,研究テーマ自体の正当性が疑われる可能性がある.また,複数の論文を引用する場合,特定の手法に偏ることなく,関連する複数の手法を参照するべきである. 一つの問題を解決するために,複数の手法が提案されている場合がある.そのような場合,一つの手法しか参考にせずに研究を行うと,自身の提案する手法が他の研究者によって既に提案されていたり,妥当な手法ではないと結論付けられていたりしている恐れがあるためである.
引用されている論文が,どこで発表されたものかということも重要である.論文には,大学や大学院の卒業時などに執筆される学位論文や,研究会などの国内会議や国際会議などで発表を行う時に論文集に掲載される論文,学術雑誌に掲載される論文など,様々な種類が存在する.この中でも,学術雑誌に掲載される論文などは,査読によって同じ研究分野の研究者によって評価を受けており,信頼性が高いとされる.
2.2 論文読解について
前節では,論文読解を行うことの目的と重要性について述べた.本節では,論文読解がどのように行われるかについて述べる.
2.2.1 注釈を付与しながら行う論文読解
論文読解は,論文を読むだけで行われるものではない.論文に対してコメントやアンダーラインなどを付与して,内容について考えながら読む必要がある.このように,論文に対して注釈を付与しながら読み,内容を理解していくことはActive Readingと呼ばれ,盛んに研究が行われている.
Active Readingについての研究は昔から行われており,SchilitらのXLibrisなどが挙げられる.XLibrisは,ペンタブレットを用いて電子文書に手書きペン入力によって書き込みをしながら文書を読むことができるシステムであり,紙の文書に対して行うような自由な書き込みを可能にしている.近年では,浜口らがWeb上へのメモ書きが可能なブラウザPerowserExを開発している.PerowserExでは,Webページに対してメモ書きを保存することができ,Web文書に対するActive Readingを容易に行うことができる.
また,PDF形式の文書に対してマーキングやコメントなどの注釈を付与することができるNitro PDF Readerや,同じくPDF形式の文書をiPad上で閲覧し,注釈を付与することを支援するiAnnotateというアプリケーションなど,Active Readingに適したアプリケーションが普及している.
2.2.2 他の情報を参照しながら行う論文読解
論文だけを参照しても,研究内容を十分に理解できない場合がある.論文は,学会や大学などの指定によってページ数が大きく異なる.例えば情報処理学会の場合,学術雑誌論文や国際会議論文の場合は8ページ前後,全国大会などで発表する論文は2ページ程度である.それに比べて,大学の卒業時に執筆する博士論文や修士論文などの学位論文は数十ページにわたる.ページ数の少ない論文を執筆する際は,自分の研究内容を可能な限り短くまとめる必要がある.そのため,自らの研究背景や提案手法,実験方法などで参考にした研究について詳しく述べることができないことがある.このような場合,論文だけを読んでも研究内容を十分に理解できず,関連する資料を参照する必要がある.
また,研究成果を紙媒体の論文で伝えることが困難な研究分野がある.例えば,音声合成処理の分野の場合,提案された手法を適用することでどのような改善があったかを,数値を提示したり,過去の手法の結果と比較したりしても,実際に適用前後の音声データを聞いてみなければよくわからない可能性がある.また,ロボットなどの研究の場合,論文中の画像を閲覧するだけではどのように動作するのか分からないことがあると考えられる.このような場合,映像や音声などの論文以外の情報を参照することが必要となる.
以上のように,論文を読解する際は,論文だけを読むのではなく,先行研究や関連する他の多様な情報を参照することが有効であると考えられる.その中でも本研究では,映像を参照することに注目した.
2.3 論文読解時の映像参照
本節ではまず,論文読解時に映像を参照することで得られる利点について述べる.次に,映像が普及する可能性について述べる.そして最後に,映像を参照する際に考えられる問題点について述べる.
2.3.1 映像の利点
映像には,視覚的な情報,時間的な情報,音声情報が含まれている.視覚的な情報とは,画像などでも表現可能な物体の形状,明暗,色彩などの情報のことである.時間的な情報とは,物体の移動や,物体の形状が変化する様子など,時間が経つにつれて変化する情報のことである.音声情報は,人間が発する声や,機械や楽器が発する音などの情報のことである.
時間的な情報や音声情報は,一般にテキストや画像などで構成される論文では表現が困難なものである.第2.2.2項で述べたように,これらの情報を参照することで,理解が深まる場合があると考えられる.映像は,大学の授業内容や調理手順の理解など,様々な分野で利用され,有用性が確認されている.そのため,論文読解時に映像を参照することも,有効であると考えられる.
例えば,システムの動作や実験風景,提案手法を適用した結果などは文章や図では正確に理解できないことがあるため,これについての映像があれば,視聴することで論文の内容をより深く理解できると考えられる.他にも,学会や研究会での発表の映像があれば,論文の理解に役立つと考えられる.学会や研究会では,発表者は定められた時間内に,参加者に自分の研究を理解してもらうために発表を行う.そのため,発表内容は研究を短い時間で理解するために論文が要約されたものとなっていると考えられるためである.
システムの動作映像や発表時の映像などの他にも,研究の応用についての映像も役立つと考えられる.研究内容がどこで,どのように利用されているかを知ることは,研究についての興味を深め,論文を読むための動機づけになるだろう.
2.3.2 映像の普及の可能性
研究所や大学,学会などでは,研究内容を広く理解してもらうために,研究内容をWeb上に公開しようという動きが高まっている.その中でも特に,映像を公開するという動きが盛んである.
IEEEやACMなどを始めとする学会では,ビデオプロシーディングスや講演時の映像などをホームページ上で公開している場合がある.特に,ACMの中でもマルチメディアに関する分科会であるSIGMMでは,ACM Multimediaで発表された論文と,それに関する映像をホームページ上で公開するなど,映像の公開を積極的に行っている.
研究所や大学などの研究機関では,ホームページやYouTubeなどの動画共有サイトで,システムの動作映像や研究発表などの研究内容に関する映像を公開していることがある.例えば,NTTフォトニクス研究所などの研究所では,過去の研究についての映像を公開している.また,我々の研究室でも,オンラインビデオアノテーションシステムSynvie上で研究に関する映像を公開している.
このような研究に関する映像を公開する動きは今後も盛んになっていくと考えられる.それに伴い,論文読解時に映像を視聴することで理解を深める機会も今後増えていくと考えられる.
2.3.3 問題点
論文と映像は,共に様々な意味情報を含んでおり,複数の部分に分けることができる.そのため,映像を論文と一緒に視聴する際,論文の部分に関連するシーンを選択的に視聴しないと理解が深まるとは言いにくい.例えば,論文の背景にあたる部分を読んでいる時に,実験時のシーンを視聴しても,論文と映像がどう関連しているか理解できず,映像を視聴する意味はあまり無いと考えられる.
映像に対して詳しい情報が分からない場合,始めから終わりまで全て視聴しなければシーンを探し出すことはできない.しかしその場合,映像を視聴するために多くの時間を必要とするため,閲覧者にとって負担が多く,論文読解の効率が悪くなってしまう.
2.4 効率的な映像の閲覧による論文読解支援
本研究では,映像を用いた論文読解の効率を向上させることで,論文読解の支援を行うことを目的とする.第2.3.3項で述べた問題点をまとめると,以下の二つとなる.
-
現映像にどのようなシーンが含まれているか分からない
-
論文のどこにどのシーンが関連しているか調べる必要がある
これらの問題点から,閲覧者は映像の視聴に長時間を要するため,論文読解の効率を低下させていると考えられる.本研究では,これらの時間を短縮させることによって,映像を用いた論文読解の効率を向上させる.
1の問題点に関しては,どのようなシーンが含まれているかを把握することで映像を視聴する時間を短縮できると考えられる.そのため本研究では,映像に含まれるシーンを定義し,閲覧者に提示する.
2の問題点に関しては,論文の部分に関連しているシーンを提示することで,論文と関連している映像シーンを探す時間を短縮し,閲覧者の負担を軽減できると考えられる.本研究では,上記の映像シーンの定義に加え,論文の部分の定義を行う.そして,関連する論文部分と映像シーンの間にリンク情報の付与を行う.得られたリンク情報を利用することで,論文部分に関連するシーンの提示を行う.得られる論文と映像のネットワークの概略図を図に示す.
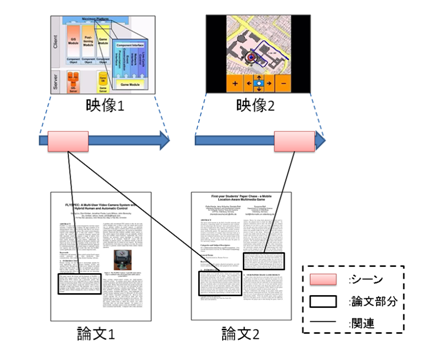
図2.1: 論文と映像のネットワーク
本研究では,論文と映像の部分の定義と,関連性の取得を行うためにアノテーションを収集し利用した.アノテーションに関する詳細,および本研究で実現した具体的な仕組みについては次章で述べる.
2.5 まとめ
本章では,論文読解を行うことの重要性と,論文読解がどのように行われるかについて述べた.また,論文読解時において関連する情報を参照することの有効性について述べ,本研究で着目した映像参照の利点とその問題点を述べた.そして,本研究の目的である論文読解支援と,それを実現する手法の概要について述べた.次章では,映像シーンと論文部分間の関連性を取得するためのアノテーション手法について詳述する.
3 映像と論文のアノテーションの取得
本研究では映像と論文の各部分要素間の関連性を取得することで論文読解を実現する.本章では,関連性を取得する具体的な手法について述べる.
本章では,まず第3.1節において,アノテーションについての説明と,我々の研究室で行われてきたアノテーションに関する研究について述べる.次に第3.2節において,映像と論文間の関連性を取得するために本研究で実現した仕組みについて述べる.そして第3.3節で,関連情報を利用することで実現可能な応用例の1つとして,論文へのアノテーションの作成・検索・閲覧のためのWebシステムTDAnnotator (Technical Document Annotator) 上での映像シーンと論文部分の提示について述べ,最後に第3.4節で本章のまとめを行う.
3.1 アノテーションとその応用
本研究では,映像シーンと論文部分間の関連性を取得するためにアノテーションを利用する.
アノテーションとは,アノテータが文書や映像などのコンテンツに対して付与するメタ情報のことである.アノテーションは,コンテンツから知識を抽出し,共有・活用するために利用することができる.我々の研究室では,アノテーションを利用することで様々なコンテンツを高度に利用する研究を行っている.以下で,我々の研究室で開発された,映像に対するアノテーションシステムSynvie,個人の知識活動を支援するDRIPシステム,そして異種コンテンツ間のアノテーションを生成・利用可能なアノテーションプラットフォームAnnphonyについて述べる.
3.1.1 Synvie
Synvieは,映像に対するアノテーションを作成するWebシステムである.Synvieでは,ユーザは映像全体だけではなく,映像内の任意のタイムコードに対してコメントを付与できる.また,Synvieに投稿された映像のシーンを引用したブログ作成や,映像シーンのプレイリスト作成を可能としている.
これらのユーザの活動から,映像に関するメタ情報を抽出し,映像の構造化を行う.任意のタイムコードに対するコメントによって,映像に対してテキスト情報を関連付けられる.また,映像シーンを引用したブログを解析することで,映像に含まれるシーンの定義,引用されたシーンに対する,ブログ内のテキスト情報の付与,そしてブログに引用された映像シーン間の関連性の取得が可能である.また,プレイリストを作成することで,プレイリスト内の映像シーン間の関連性を取得できる.
得られたアノテーションを利用したコンテンツの高度な応用として,Synvieでは映像シーン検索を実現している.YouTubeなどの動画共有サイトでの検索結果は,映像コンテンツ全体を検索結果として提示する.このような検索結果の提示方法では,映像にどのような情報が含まれているかを俯瞰することが困難である.
Synvieでは,映像シーン検索を行うことで,映像にどのような映像シーンが含まれているかを俯瞰することができる.映像シーンに関連付けられたテキストを形態素解析してタグを生成する.このタグを選択することで,映像シーンの検索を行う.検索結果は,映像のタイムライン上に,検索結果に該当する映像シーンを表示するという形で提示される.これによって,ユーザは映像にどのような映像シーンが含まれているかを俯瞰し,映像を視聴する手掛かりにできる.
3.1.2 DRIPシステム
DRIPシステムは,個人の研究活動の履歴を記録・蓄積し,蓄積された情報を引用しながら研究活動を行うことを支援するシステムである.研究活動において,議論の中で指摘されたことや,自分が考えたことを踏まえて研究を行うことは非常に重要である.しかし,指摘されたり,考えたりしたことは,保留してしまうと時間の経過とともにその存在自体を忘れてしまい,放置されてしまう可能性がある.
DRIPシステムでは,個人の研究活動で得られる情報をノード,ノード間のリンク情報をエッジとしたグラフ構造で図のように可視化される.扱うことができる情報として,ゼミで発表を行ったときに使用した資料の情報,ゼミの情報,自分が今後行う予定のTODOの情報,そしてそれらに対する自分の考えといった情報がある.
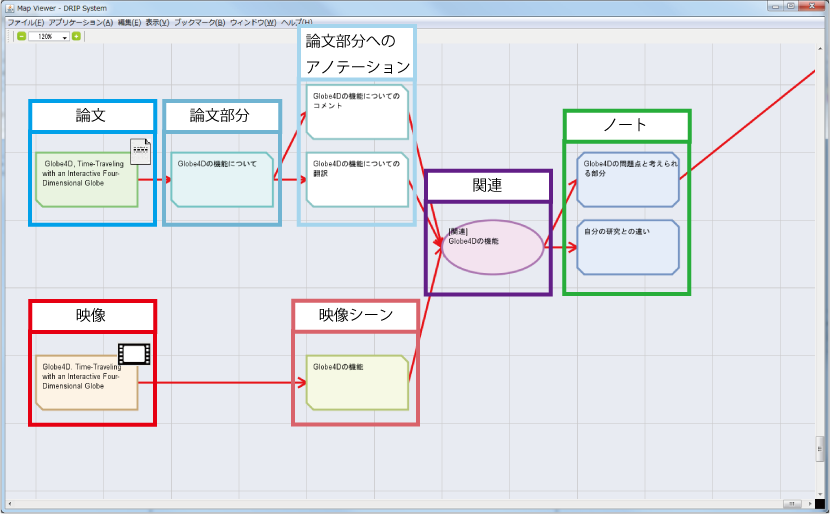
図3.1: DRIPシステム上での情報の可視化
DRIPシステムでは過去の研究活動履歴を記録し,それを引用する形でノートやスライドなどを作成できる.これによって,ユーザは過去に指摘された情報や考えたことを踏まえた研究活動を行うことができる.この時,引用元と引用先の情報間の関連性が自動的に記録される.
上記のように,DRIPシステムでは様々な情報を扱うことができる.これを実現するために,DRIPシステム上では,次項で述べるAnnphonyの仕組みを利用し,全ての情報はURIによって参照できるようになっている.
3.1.3 Annphony
コンテンツに対してアノテーションを行う研究は,映像やテキストなど,様々なコンテンツに対して行われている.しかし,付与されるメタ情報の表現形式は,コンテンツの種類に依存している場合が多く,互換性に乏しい.そのため異種コンテンツを同時に利用する研究を進めるにあたっての障害となっている.
Annphonyは,複数の異なるコンテンツに対するアノテーションを統合的に扱うアノテーションプラットフォームである.Annphonyでは任意のコンテンツの詳細な部分を表現するための形式として,コンテンツのURIと,RDFのスキーマ記述言語であるRDFS(RDF Schema)によって記述されるElement Pointerを提案している.これによって,任意のコンテンツの任意の部分に対して付与されたアノテーションを取り扱うことができる.
任意のコンテンツに対するアノテーションを統合的に管理することで,異なるコンテンツ同士を組み合わせたマッシュアップコンテンツの生成などを実現することができる.マッシュアップコンテンツについては,次章で述べる.
3.2 アノテーションを利用した関連性の取得
本節では,アノテーションを利用することで実現した,映像シーンと論文部分間の関連性を取得する具体的な手法について述べる.まず,映像シーンと論文部分の定義を行うために,それぞれSharvieとTDAnnotatorを開発し,アノテーションの記録を行った.次に,得られた映像シーンと論文部分の関連性を取得するために,第3.1.2項で説明したDRIPシステムを拡張し,映像と論文についての情報を扱えるようにした.図に映像シーンと論文部分間の関連性を取得する仕組みの概略図を示す.
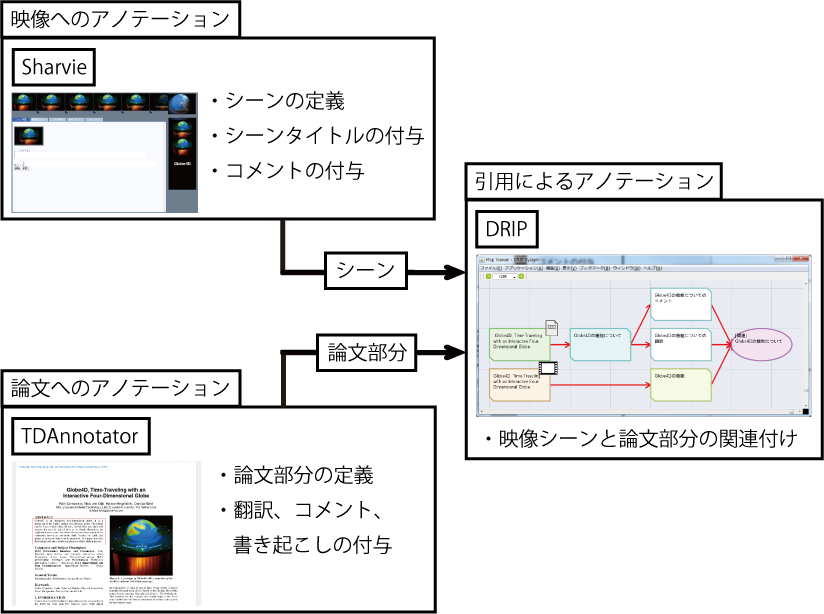
図3.2: 関連性を取得する仕組み
以下に,映像および論文のそれぞれに対してアノテーションを作成する仕組み,両者の関連性を取得する仕組みについて詳述する.
3.2.1 映像へのアノテーション
本研究では,第3.1.1項で述べたアノテーションシステムSynvieの機能を拡張した研究室内部向けの映像アノテーションシステムSharvieを利用した.本項では,本研究で実現した映像シーンに関するアノテーションの付与を行う仕組みについてと,その時に付与されるアノテーションについて述べる.
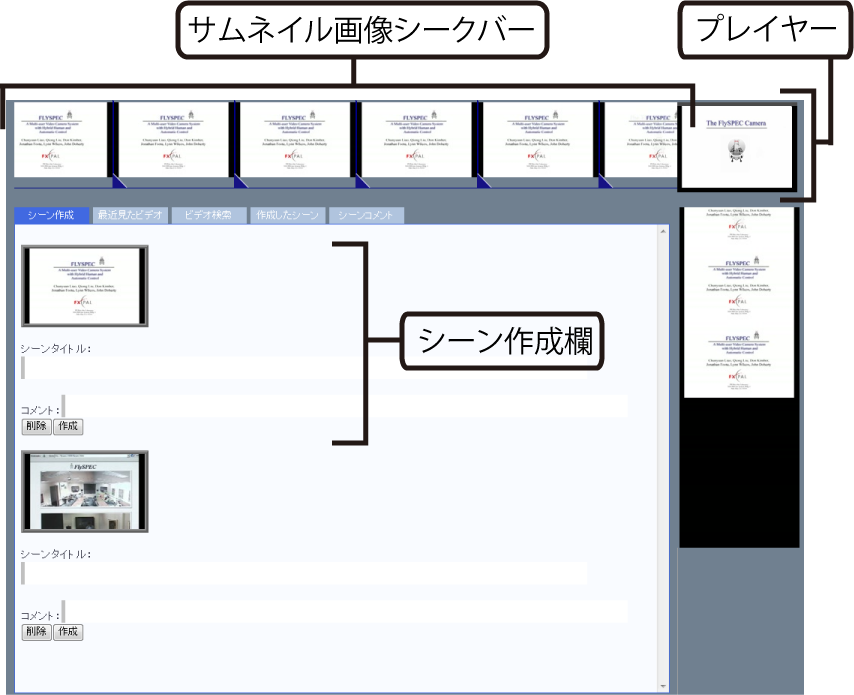
図3.3: シーンを引用するユーザインタフェース
図に映像シーン引用を行うためのユーザインタフェースを示す.本インタフェースは,Synvieにおいて山本らが映像シーン引用ブログを執筆するために作成したユーザインタフェースの仕組みを利用している.
まず,引用したいシーンを含む映像コンテンツを図のインタフェースに読み込む.コンテンツの読み込みには,ユーザが過去に視聴したコンテンツから選択する仕組みや,キーワードによってコンテンツを検索する仕組みを提供している.また,映像の視聴中に図のインタフェースを開くと自動的にそのコンテンツが読み込まれる.
コンテンツの読み込みが完了すると,画面の右上に映像を再生するためのストリーミングビデオのプレイヤーが設置される.映像を再生すると上下左右にサムネイル画像が流れていく.右から左へ水平に流れるサムネイル画像は2秒単位のサムネイル画像であり,上から下へ垂直に流れるものは10秒から60秒までの中でユーザが指定した単位のサムネイル画像であり,どちらもプレイヤーの再生時間に同期して画面上を移動し,マウスドラッグによるシーク操作が可能である.水平に流れるサムネイル画像は引用する映像シーンを決定する目的で利用され,垂直に流れるサムネイル画像は,ビデオ時間の長いコンテンツに含まれるシーンを引用したい場合に長い時間単位で映像シーンを飛ばしてシークする目的で利用されることを前提としている.
3.2.1.1 シーンの決定手順
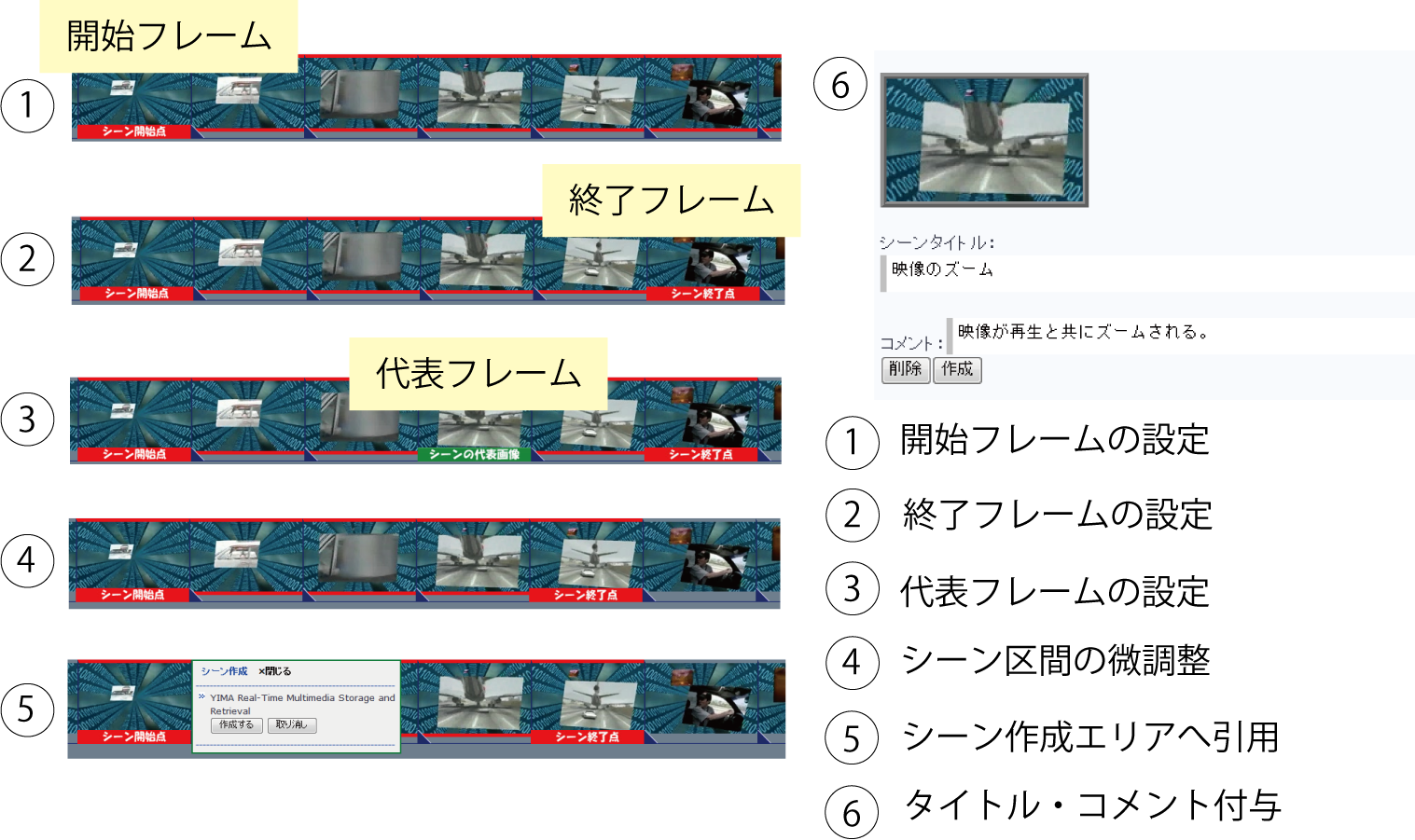
図3.4: シーンの決定手順
このインタフェースを利用してシーンの決定を行う手順を図に示す.サムネイル画像の上でマウスドラッグを行うことで,画像がシークされ,それに同期して早送りあるいは巻き戻しされる.シークによって引用したいシーンを発見したら,引用する区間を,サムネイル画像をマウスクリックすることで設定する.1回目のクリックでシーンの開始フレームを,2回目のクリックで終了フレームを,3回目以降のクリックで微調整を行う.シーンの選択を行ったら,Ctrlキーを押しながらマウスクリックを行うことで,シーンの代表フレームの設定を行う.デフォルトではシーンの開始フレームが代表フレームとなる.
引用するシーン区間と代表フレームを決定したら,右クリックによって表示されるポップアップウインドウ上のメニューから,映像シーンをシーンタイトル決定エリアに追加する.シーンタイトル決定エリアでは,ユーザが設定した代表フレームに対応するサムネイル画像によって映像シーンが表現される.ここで,シーンに対してタイトルとコメントを付与する.これによって,作成されたシーンがどのような意図で作成されたかを明確にすることができる.
シーンタイトル決定エリアで削除ボタンがクリックされると,作成中のシーンの情報がエリアから削除される.作成ボタンがクリックされると,シーンの作成が完了するとともに,後述の映像と論文の部分引用によるアノテーションを取得するシステムに対してシーンが引用される.
シーン引用インタフェースでシーンの作成を行うことにより,映像に対して以下の情報をアノテーションとして付与できる.
3.2.1.2 既存のシーンの再利用
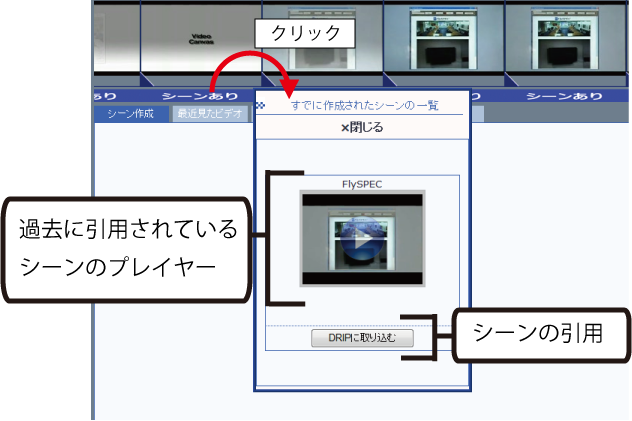
図3.5: 既存のシーンの再利用
ユーザは引用するシーン区間を自身で設定するだけでなく,既に他のユーザが引用した,あるいは自分が引用したシーンを再利用して引用することが可能である.再利用可能なシーンを含む区間は,図のように表示され,クリックすることでそのシーンをプレビュー再生することができる.また,「DRIPに取り込む」ボタンをクリックすることで,シーンを引用することができる.
既に定義されたシーンを再利用するために,Sharvieではシーン一覧ページからシーンを閲覧することが可能である(図).シーン一覧ページでは,シーンを「教育・研究」などのカテゴリに分類して閲覧することができる.この分類は,シーンを含む映像が投稿された時に,投稿者が付与する情報である.シーン一覧ページでは,シーン引用時に付与されたタイトルと,シーンの開始・終了時間,シーンの代表サムネイルが表示される.代表サムネイルをクリックすることで,シーンを再生することができる.代表サムネイル下の「DRIPに取り込む」ボタンをクリックすることで,シーンを引用することができる.
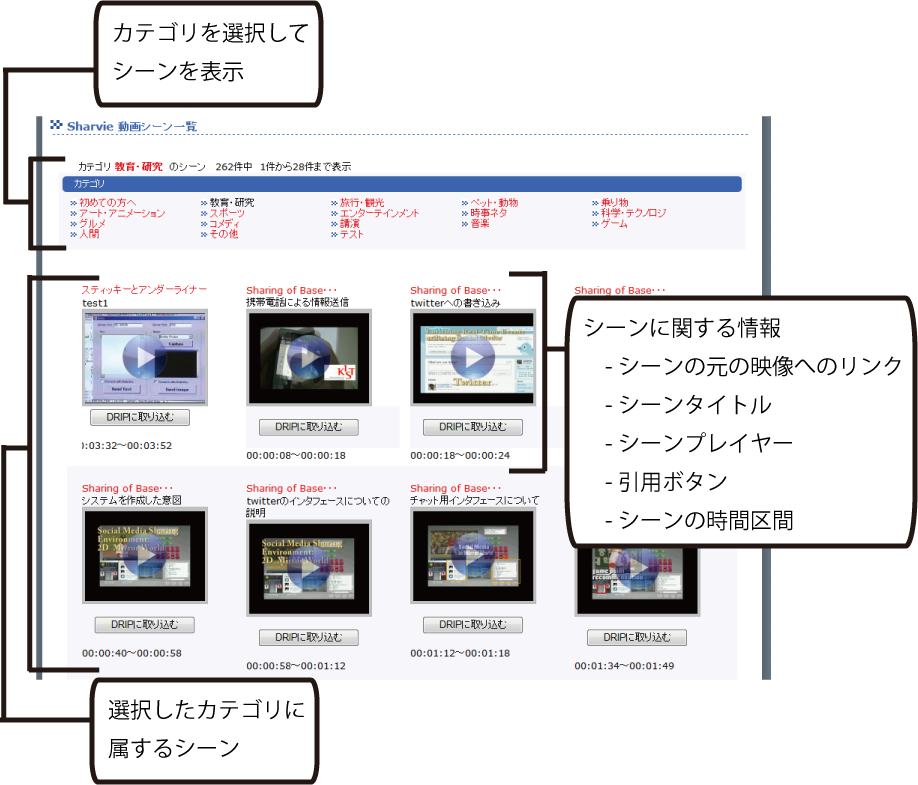
図3.6: シーン一覧ページ
その他に,映像に対する詳細な説明が閲覧できるコンテンツページ上で,映像に含まれるシーンを閲覧することができる(図).この画面からも,シーンを引用できる.
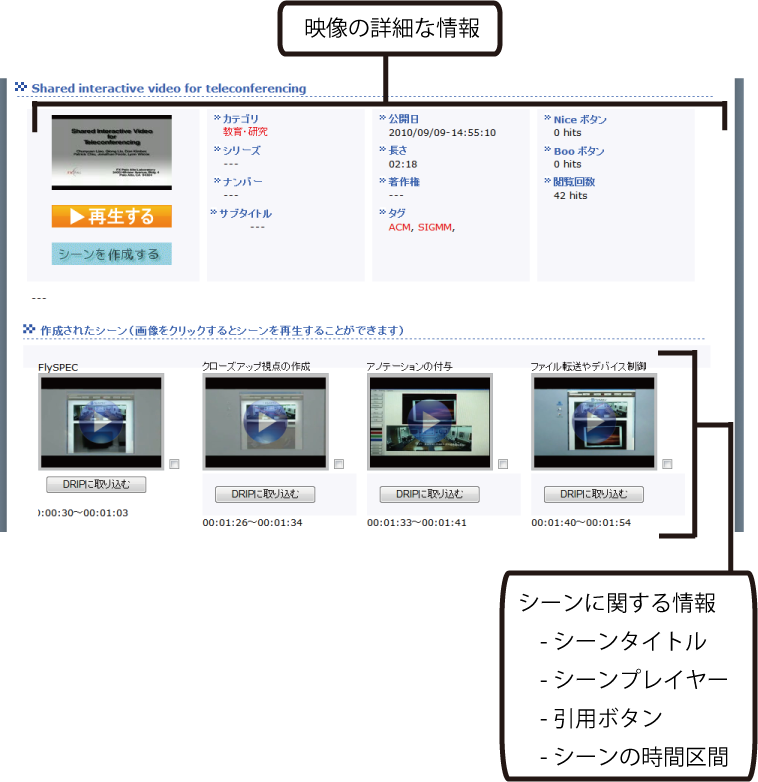
図3.7: 映像の詳細ページ
引用されたシーンを再利用することで,ユーザのシーン作成に対する負担を軽減することができる.さらに,アノテーションを蓄積するという観点から見ても利点がある.例えば,あるユーザはあるコンテンツの10秒から20秒のシーン,別のユーザは12秒から22秒のシーンを選択するというような微妙なずれが生じる可能性がある.この場合,それぞれの指し先が意味的に同一のシーンかどうかを判別することができないため,2つの異なるシーンとして扱うことしかできない.すると,それぞれのシーンに対する情報は,それぞれのシーンにしか関連付けることができず,同一の対象に関する情報を増やしていくことができなくなってしまう.本研究では,すでに引用されたシーンの再利用を許すことで,複数のユーザによって引用されたシーンの同一性を明確にすることができる.
3.2.2 論文へのアノテーション
本項では,本研究で開発した論文に対するアノテーションを作成・検索・閲覧するためのWebシステムであるTDAnnotatorについて述べる.Web上に存在している論文の多くは,PDF形式で公開されている.そのため,本システムで対象にする論文は,PDF形式の論文である.
3.2.2.3 TDAnnotatorのインタフェース
TDAnnotatorの論文閲覧インタフェースを図に示す.この画面では,論文の各ページは画像に変換されて表示される.変換前のPDF形式のファイルについては,インタフェース上にリンクが設置されており,ダウンロードが可能となっている.アノテーションが付与されている論文の部分は,赤い矩形で図のように表示される.

図3.8: TDAnnotatorの画面例
3.2.2.4 論文に対するアノテーション

図3.9: 論文に対してアノテーションを付与する手順
論文に対してアノテーションを付与する手順を図に示す.本システムでは,画面に表示される論文上でマウスドラッグ操作を行うと,論文のページ中のドラッグされている領域内以外の部分が暗い色に変化する.これによって,アノテーションを付与する領域を選択する.ドラッグ操作を終了すると,選択した領域の右下に「Annotate」ボタンが表示される.このボタンを押すことで,アノテーション入力のダイアログが表示される.
アノテーション入力のダイアログ上では,矩形内容,文章タイプ,文章言語,内容を入力する.矩形内容は,選択した矩形内にどのような情報が含まれているかという情報で,本文,数式,グラフ,表,図,タイトルなど,あらかじめ用意された項目の中から選択する.文章タイプは,アノテーションとして付与する文章がどのような内容かという情報で,翻訳,書き起こし,コメントといった項目から選択する.文章言語は,アノテーションとして付与する文章がどのような言語で入力されているかという情報で,言語リスト(現在のところ,英語と日本語のみ)から選択する.内容は,アノテーションの本文のことである.これらの情報を入力し,ダイアログ右下の「Apply」ボタンを押すことで,アノテーションの付与が完了する.アノテーションが付与された論文の部分は,論文上に赤い矩形として表示される.
3.2.2.5 アノテーションの閲覧・引用

図3.10: アノテーションの閲覧
論文上に表示される矩形をマウスクリックすることで,付与されているアノテーションを閲覧できる.図のようにダイアログが表示され,付与されているアノテーションの文章タイプと文章の最初の十数文字が表示される.そして,「View」ボタンをクリックすることで,選択したアノテーションを詳細に閲覧できる.後述するが,本システムでは既に存在する矩形に対してアノテーションを追加することができる.そのため,複数のアノテーションが付与されているときに,どのアノテーションを閲覧するかを選択する手掛かりとするためにこのような表示を行っている.
ダイアログの表示中は,選択した矩形内の背景色を変えることで強調表示している.これにより,表示したアノテーションが論文のどの部分に付与されているかを明示している.
論文に対するアノテーションは,ユーザ間で共有される.これによって,既にアノテーションが付与された論文に関しては,後から読むユーザは自分が一度も読んだことが無い論文を,情報があらかじめ付与された状態で読むことが可能となり,ユーザの負担が軽減されると考えられる.
アノテーションの詳細な表示を行っているダイアログ上の「DRIPに取り込む」ボタンをクリックすることで,映像と論文の部分引用によるアノテーションを取得するシステムに対して,論文部分の情報とそこに付与されたアノテーションの情報を引用することができる.
3.2.2.6 論文部分に対するアノテーションの追加
ユーザはアノテーションを付与する論文部分を自身で作成するだけでなく,既に他のユーザが作成した論文部分に対してアノテーションを追加することが可能である.既存の論文部分に対してアノテーションを付与する手順を図に示す.
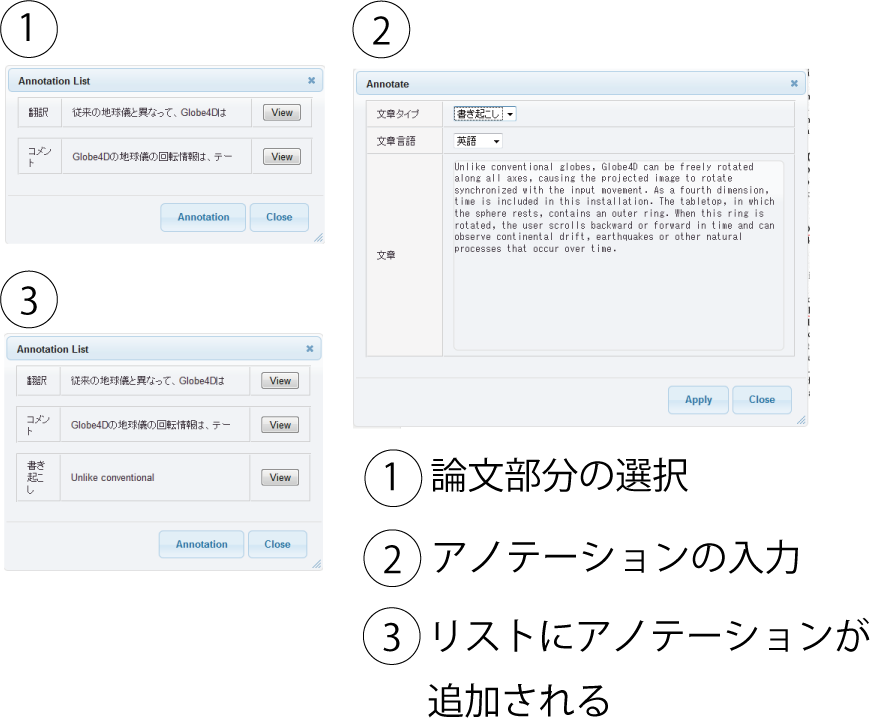
図3.11: 既存の論文部分にアノテーションを追加する手順
論文部分を選択することで表示されるアノテーション一覧のダイアログ上の「Add Annotation」ボタンを押すことで,アノテーションを追加するためのダイアログが表示される.このダイアログでは,文章タイプ,文章言語,内容を入力する.論文部分を新たに選択しながらアノテーションを付与する場合との相違点として,ここでは矩形内容を選択しない.これは,アノテーションの追加を行う場合は,既に矩形が定義されているためである.必要な情報を入力し,「Apply」ボタンを押すことで,矩形に新たにアノテーションが付与される.
既存の論文部分に対してアノテーションの追加を可能にすることで,ユーザの論文部分選択に対する負担を軽減することができる.さらに,アノテーションを蓄積するという観点から観ても利点がある.例えば,あるユーザが1章の第一パラグラフを選択してアノテーションを付与した論文に対して,別のユーザが同じ場所にアノテーションを付与したいという時に,既存の論文部分にアノテーションが付与できないと,同じ部分に対して再び論文部分の選択を行う必要がある.すると,2つのアノテーションは,2つの別の矩形に対してアノテーションが付与されることになり,同じ部分に対してのアノテーションとして扱うことができなくなってしまう.本研究では,既存の論文部分に対してアノテーションの追加を可能にすることで,複数のアノテーションが付与された部分の同一性を明確にすることができる.
3.2.3 映像と論文の部分共引用によるアノテーション
本項では,第3.2.1項,第3.2.2項によって取得した映像シーンと論文部分間の関連を取得する方法について述べる.本研究では,第3.1.2項で述べたDRIPシステム上で,映像シーンと論文部分の関連付けを行う仕組みを実現した.
3.2.3.7 DRIPシステムへの応用
DRIPシステム上に映像シーンと論文部分を引用したシステムの様子を図に示す.
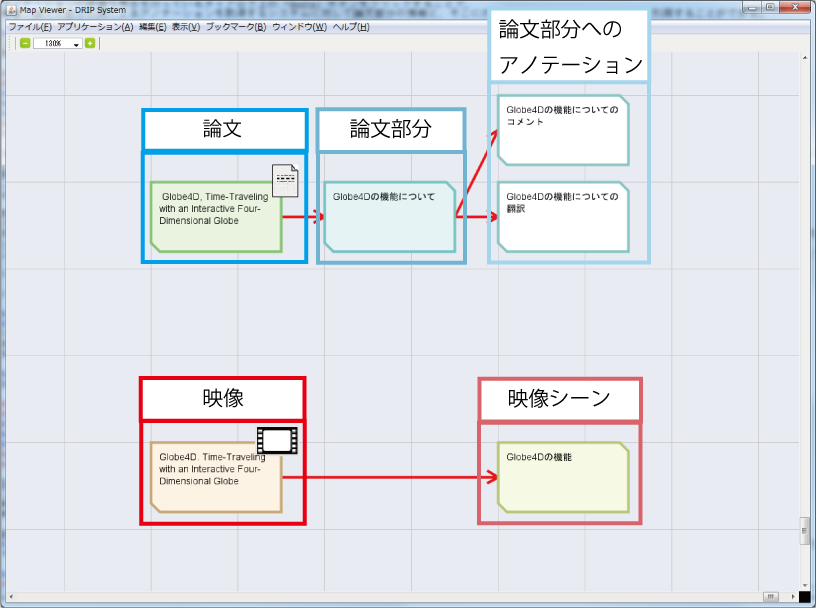
図3.12: DRIPシステム上での映像・論文についての情報の可視化
図のように,映像シーンは元となる映像のノードから派生するノードという形で表現される.これは,1つの映像から複数のシーンを引用した時に,それらが元は1つのコンテンツから引用されたことを明示するためである.映像シーンノードや映像ノードを,マウスのダブルクリックで選択することで,選択したコンテンツのSharvieの再生ページが表示され,映像の再生が行われる.映像シーンノードの場合,映像中の特定のシーンのみが再生される.
論文部分も映像シーンと同様に,論文のノードから派生する形で論文部分のノードが表現される.第3.2.2項で述べたが,TDAnnotatiorからDRIPシステムに情報を引用する時は,論文部分に付与されたアノテーションを引用する形で行う.そのため,論文部分のノードから派生する形で付与されたアノテーションのノードが表示される.
3.2.3.8 関連情報の入力
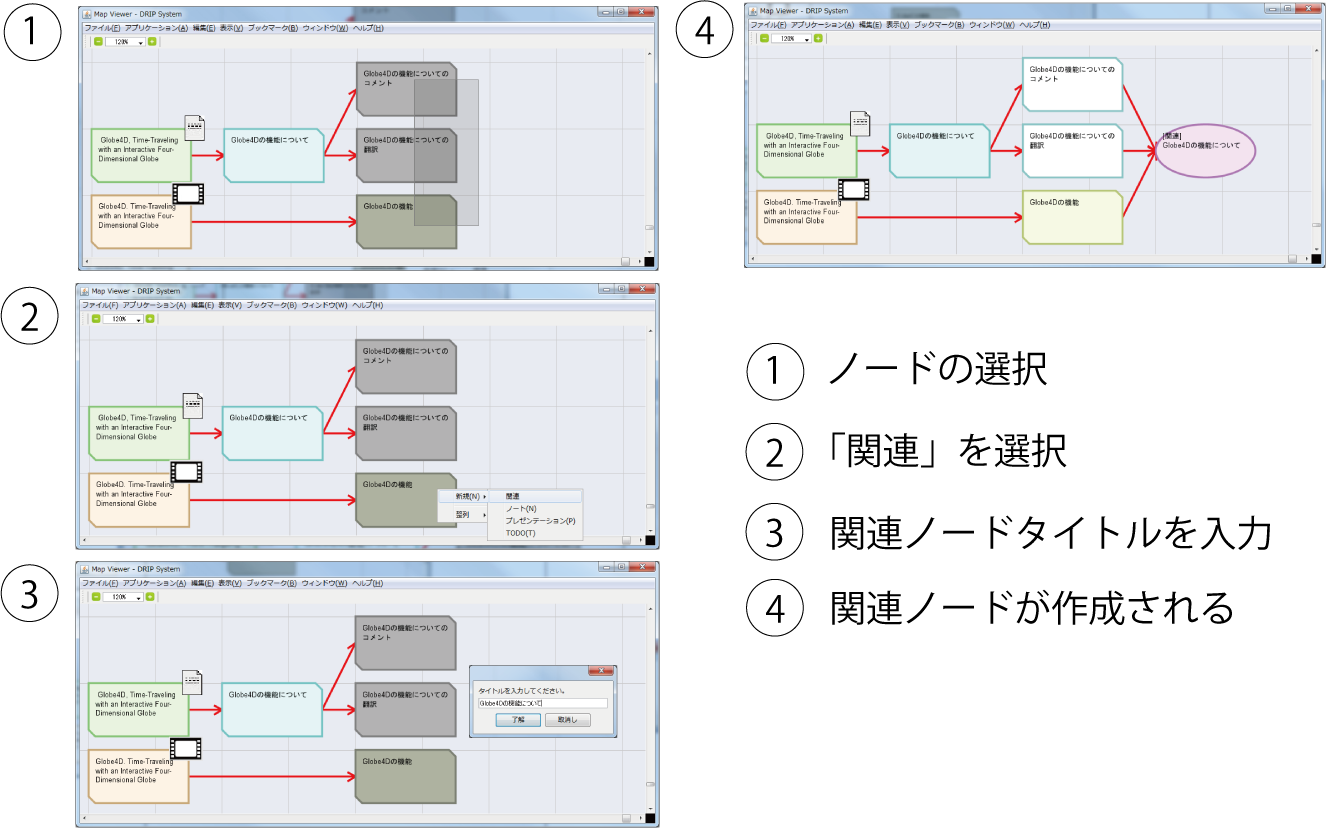
図3.13: 論文部分と映像シーンを引用した関連ノード
映像シーンと論文部分間の関連性を定義するために,DRIPシステム上で関連ノードの作成を行う.映像シーンのノードと論文部分のノードを引用する形で関連ノードの作成を行う.ユーザは,DRIPシステム上でドラッグ操作による範囲選択,もしくはCtrlボタンを押しながらノードをクリックすることでノードを選択する.そして,選択されたノードのいずれかの上で右クリックを押してメニューを表示させる.表示されたメニューの「新規(N)」ボタンを選択し,表示された項目の中から「関連」を選択する.このとき,ノードのタイトルを入力するフォームが表示され,ユーザがタイトルを入力し,決定することで関連ノードが作成される.図に,関連ノードが作成される手順を示す.
論文には,参考文献として様々な論文が引用されている.引用先の論文では,文中で引用元の論文を参照しながら手法の説明などを行っている.このような論文を読解する際に,引用元の論文を一緒に読むことは,論文で説明されている研究を理解する上で重要であると考えられる.そのため本研究では,DRIPシステム上で,映像シーンと論文部分の間の関連性に加え,論文部分と論文部分の間の関連性の定義も可能にしている.
関連ノードを作成することで,ユーザはDRIPシステム上でどの映像シーンとどの論文部分が関連しているかを可視化することができる.また,関連ノードを引用したノートを作成して研究活動を進めることで,先行研究を踏まえた研究活動を行うことができる.
3.3 関連情報を利用したTDAnnotator上での応用例
第3.2節の仕組みで得られた映像と論文の部分要素間の関連性の利用例を示す.本研究では,TDAnnotatorで論文部分の閲覧を行う際に,論文部分に関連する映像シーンや,他の論文の論文部分の提示を行った.これにより,TDAnnotator上で関連情報を参照しながら論文を読解することができる.
3.3.1 映像シーンの提示
図のように,シーンが関連付けられている論文部分に該当する矩形を青色の枠線で表示した.通常の論文部分と同様に,この部分をクリックしてアノテーションを表示させると,アノテーションに関連した映像シーンが表示される.これによって,ユーザは論文部分とそこに付与されているアノテーション,そしてアノテーションに関連付けられた映像シーンを同時に閲覧することができ,論文の理解に役立つと考えられる.

図3.14: TDAnnotator上での映像シーンの閲覧
3.3.2 論文部分の提示
図に,論文部分の閲覧時に,他の論文の論文部分を提示する仕組みを示す.前項で説明した映像シーンの提示方法と同様に,論文部分を選択し,そこに付与されているアノテーション閲覧する際に,論文部分を表示している.この時,表示されている論文部分を含む参照元の論文を詳しく閲覧したい場合は,論文部分の下部に表示されている「この論文を詳しく閲覧する」を選択することで,引用元の論文が表示される.引用元の論文は,選択した論文部分がピンク色にハイライトされ,その部分までスクロールした状態で表示される.

図3.15: TDAnnotator上での論文部分に関連した他の論文部分の閲覧
3.4 まとめ
本章では,まず論文と映像に対するアノテーションについての説明とアノテーションを利用した研究について述べた.次に,本研究で実際に実現した映像シーンと論文部分間の関連性を取得するための仕組みについて述べた.そして,得られた関連情報を利用することで可能な論文読解支援の一例として,論文アノテーションシステムTDAnnotator上での映像シーンと論文部分の提示について述べた.次章では,本研究で実現した論文読解支援システムDocvieについてと,Docvieを利用することで効率的な論文読解が行われることを確認するための評価実験について述べる.
4 映像を用いた論文読解支援システム:Docvie
本章では,前章で説明した仕組みを利用することで取得した関連情報を閲覧するシステムであるDocvieについて述べる.
まず第4.1節ではDocvieのコンセプトについて述べる.次に第4.2節でシステムの構成について述べ,第4.3節でDocvieの諸機能について詳述する.そして最後に第4.4節で本章のまとめを行う.
4.1 Docvieのコンセプト
第3.3節で述べたように,TDAnnotatorを論文読解に利用する場合,論文部分とそこに関連付けられた映像シーンと論文部分を一緒に閲覧することが可能であり,これによって論文に対する理解を深めることができると考えられる.しかし,TDAnnotator上での映像シーンの提示方法では,提示された映像シーンに他に論文が関連付いていたり,映像シーンの元となる映像の他の映像シーンに別の論文が関連付けられていたりしても,それを閲覧者が知ることはできない.図にTDAnnotatorで論文を閲覧した場合に参照可能なコンテンツの範囲について示す.
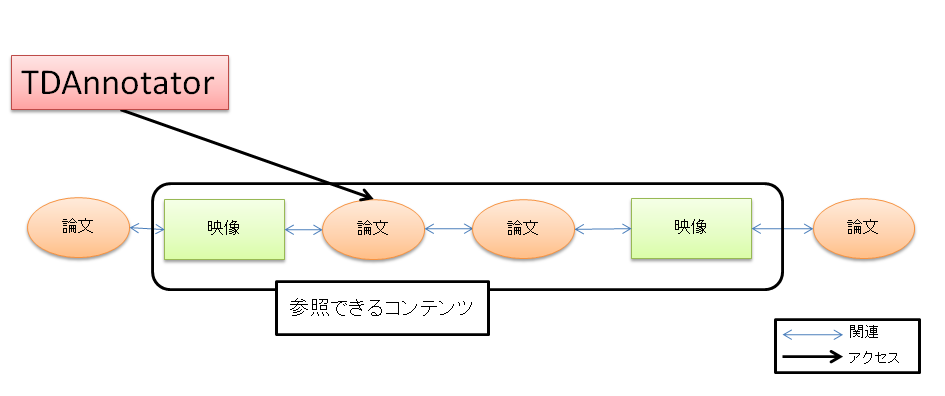
図4.1: TDAnnotatorで論文を閲覧する場合に参照可能なコンテンツ
図のように,映像に対して複数の論文が関連付けられていても,ユーザは最初に選択した一つの論文と,それに関連する映像シーンしか閲覧することができない.そのため,TDAnnotatorで論文を閲覧する際は,閲覧中の論文に関連付けられた映像に,別の論文が関連付けられていても,その情報を参照することができず,参考文献として挙げられているもの以外の論文間の関連を意識して論文を読解することはできない.
関連情報を利用して複数の論文と映像を閲覧することで,論文間のつながりを意識した論文読解を行うことができると考えられる.例えば,ある手法について詳細に説明している映像シーンに対して,その手法を提案している論文と応用している論文の二つが関連付いている場合,映像シーンを手掛かりに二つの論文を辿ることで,読んでいる論文に対して理解を深めることができる.他にも,複数の論文部分と映像シーンが同じ研究分野の研究として関連付けが行われている場合,それを辿ることで研究分野に対しての理解を深めることができる.
論文読解時に,論文について疑問や興味が生じた場合,閲覧者は参考文献などの論文に関連する情報を探し,閲覧することで理解を深めようとする.しかし,論文に関連する情報を探すためには,Web上での検索を行ったり,論文集などで関連する研究を調査したりする必要があり,その負担は大きいと考えられる.このような場合,関連情報を利用することで,読解中の論文に関連する論文部分や映像シーンなどの情報を提示することで,論文読解時の閲覧者の情報検索の負担を軽減できると考えられる.
このようなことを踏まえて,本研究では映像を用いた論文読解支援システムDocvieを実現した.Docvieでは,関連情報を利用することで複数の論文と映像の理解を深めることを目標としている.図にDocvieで論文を閲覧した場合に参照可能なコンテンツの範囲について示す.Docvieでは,最初に選択した論文の閲覧中に,関連情報を辿ることで複数の論文と映像を閲覧することができる.
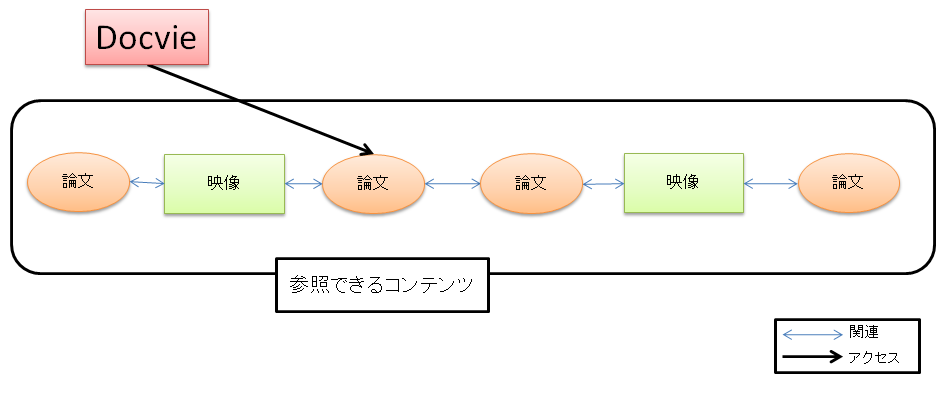
図4.2: Docvieで論文を閲覧する場合に参照可能なコンテンツ
Docvieでは,論文を主体とする閲覧と映像を主体とする閲覧を行うことができる.論文を主体とした閲覧では,論文の読解中に関連情報を利用して,論文部分に関連した映像シーンなどを視聴しながら閲覧する.映像を主体とした閲覧では,映像の視聴中にシーンに関連する論文部分などを参照しながら閲覧する.これによって,ユーザは論文だけでなく,映像も手掛かりにして,関連するコンテンツを探すことができる.
4.2 システムの構成
本システムはWebアプリケーションとして実装されており,専用のクライアントソフトを必要としない.ユーザはWebブラウザを利用してアクセスすることで,論文と映像の閲覧を行うことができる.また,本システムはiPadなどのパッド型デバイス上で動作可能である.これにより,ユーザは好きな場所で好きな時に手軽に本システムにアクセスできる.
前述の通り,Docvieでは論文を主体とする閲覧および映像を主体とする閲覧を行うことができる.それらに対応して,Docvieは前述のSharvieやTDAnnotatorと連携することができる.
本システムでは,第3章で述べた仕組みで取得した映像シーンと論文部分の関連情報を利用することで,映像と論文という2種類のコンテンツがマッシュアップされたコンテンツを閲覧する.コンテンツのマッシュアップとは,複数の関連するコンテンツを自動的に統合して新たにコンテンツを生成することである.Webコンテンツを用いて生成されたマッシュアップコンテンツの例として,Google Mapsが挙げられる.Google Mapsでは,地図情報をベースに,店舗などの場所に関連する情報を動的に統合して表示している.これによって,どのような種類の店舗がどのような地域に分布しているかなどを詳細に理解することができる.
我々の研究室でも,過去の研究で,アノテーションを利用してマッシュアップコンテンツの生成を行った.ブログ上にオンライン辞書システムの辞典の部分と映像シーンが共引用されたという情報から,辞典の部分と映像シーン間の関連性を抽出した.この関連情報を利用することで,辞典の項目中の同時引用された文以降に,ビデオへのリンクを埋め込んだビデオ用例付き辞典システムを実現した.
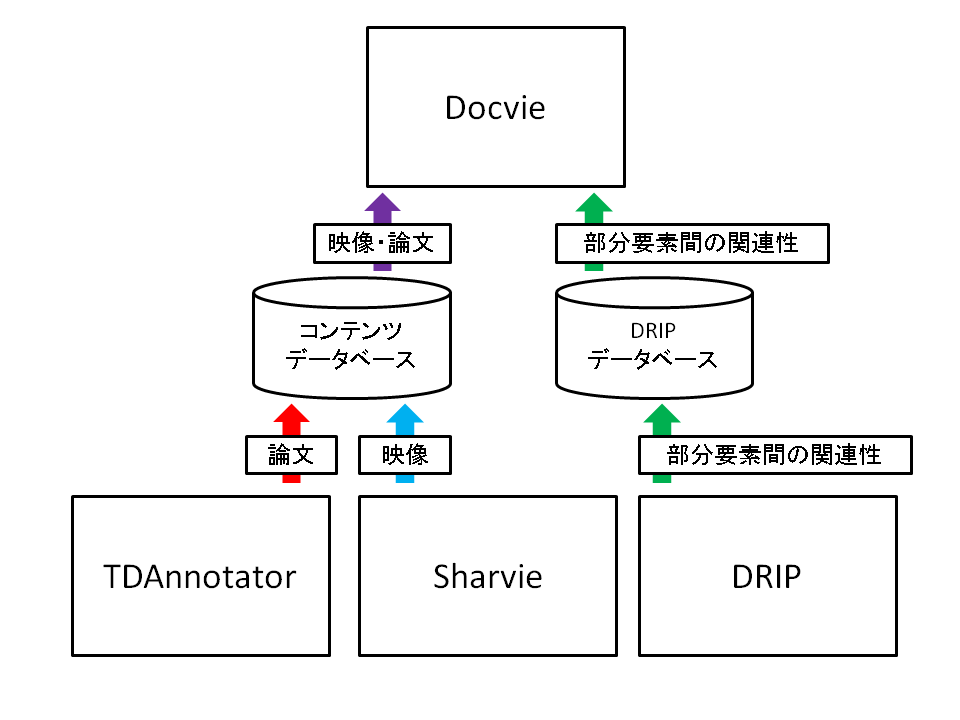
図4.3: システムの全体構成
本システムの全体構成を図に示す.論文と映像についての情報と,それぞれTDAnnotatorとSharvieで付与されたアノテーションの情報はコンテンツデータベースに保存されている.そして,DRIPで得られた論文部分と映像シーン間の関連性についてのアノテーションの情報はDRIPデータベースに保存されている.Docvieで閲覧を行う場合,主体として閲覧するコンテンツに関連付けられた情報をDRIPデータベースから取得する.そして,DRIPデータベースから取得された情報を元に,必要なコンテンツのデータをコンテンツデータベースから取得する.得られたコンテンツの情報から,Docvieの閲覧画面の表示を行う.
4.3 Docvieの諸機能
本節では,Docvieの持つ機能について詳しく述べる.Docvieでは,論文を主体として閲覧する論文中心モード,映像を主体として閲覧する映像中心モードの2種類の閲覧モードを切り替えながら閲覧を行う. 以下に,それぞれのモードについて詳述する.
4.3.1 論文中心モード
論文中心モードの画面を図に示す.画面の上部には,現在開いている他のコンテンツを表示するためのタブが配置されている.そのすぐ下のタイトルバーには,現在開いている閲覧画面を閉じるためのボタン,閲覧モードを表わすアイコン,そしてコンテンツのタイトルが表示されている.画面の左側に主として閲覧している論文,右側に論文に関連付けられた情報を表示する.この画面では,主として閲覧する論文を,関連情報を参照しながら読解することで理解を深めることを支援している.以下に,このモードでの機能について述べる.
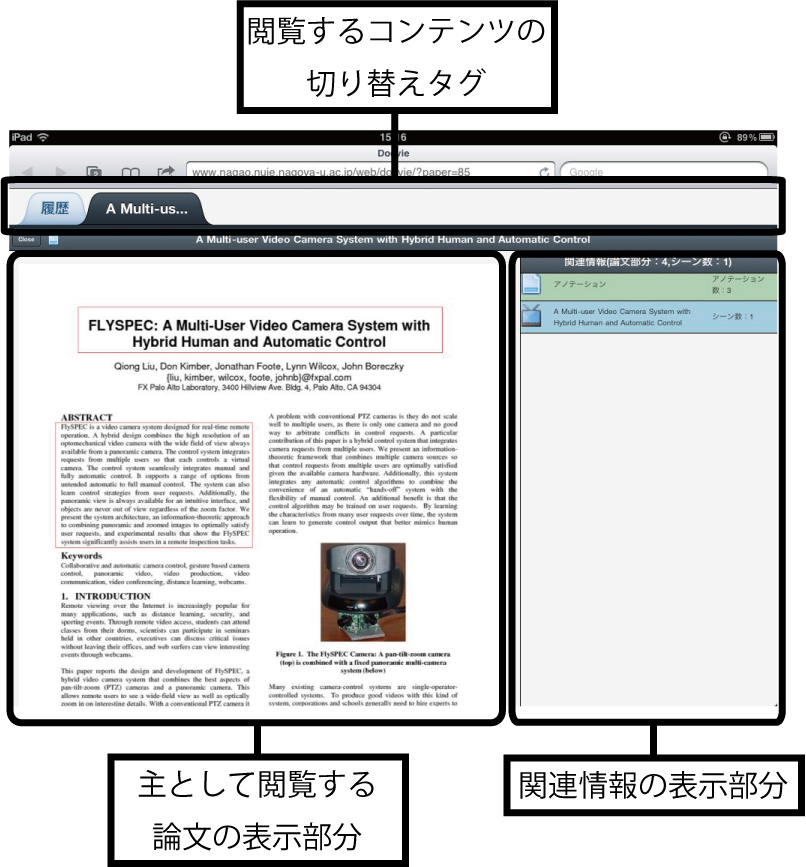
図4.4: 論文中心モードの画面
4.3.1.1 論文の閲覧部分
論文中心モードの画面の左側の部分には,主として閲覧する論文が表示される(図).この部分には論文の各ページが左から右に配置されており,ユーザは論文をスクロールしながら閲覧を行う.また,ここに表示される論文は拡大・縮小が可能であり,論文のある部分を詳細に閲覧したい場合は拡大して閲覧することが可能である.

図4.5: 論文の表示部分
論文上には,TDAnnotatorでアノテーションが付与された部分を矩形で表現している(図).TDAnnotator上での表示と同じく,TDAnnotatorで付与されたアノテーションのみが関連付けられている論文部分は赤い枠線の矩形で,映像シーンが関連付けられている論文部分は青い枠線の矩形で表示される.これらの部分は,ユーザによって情報が付与されている部分であり,付与されている情報を参照しながら論文を読解することで,論文についての理解を深めることができると考えられる.表示されている論文部分を選択することで右側の関連情報の表示部分の表示が変化し,選択した論文部分に関連付けられた情報が表示される.関連情報の表示の変化については,次項で述べる.

図4.6: アノテーションが付与されている論文部分の表示
4.3.1.2 関連情報の表示部分
関連情報の表示部分について図に示す.上部に論文に関連付けられている論文部分と映像シーンの数が表示される.リストの項目を選択することで,TDAnnotator上で論文部分に付与されたアノテーションと,論文部分に関連付けられた部分要素についての情報が展開される.図に,リストの項目を展開した様子を示す.

図4.7: 関連情報の表示部分の説明
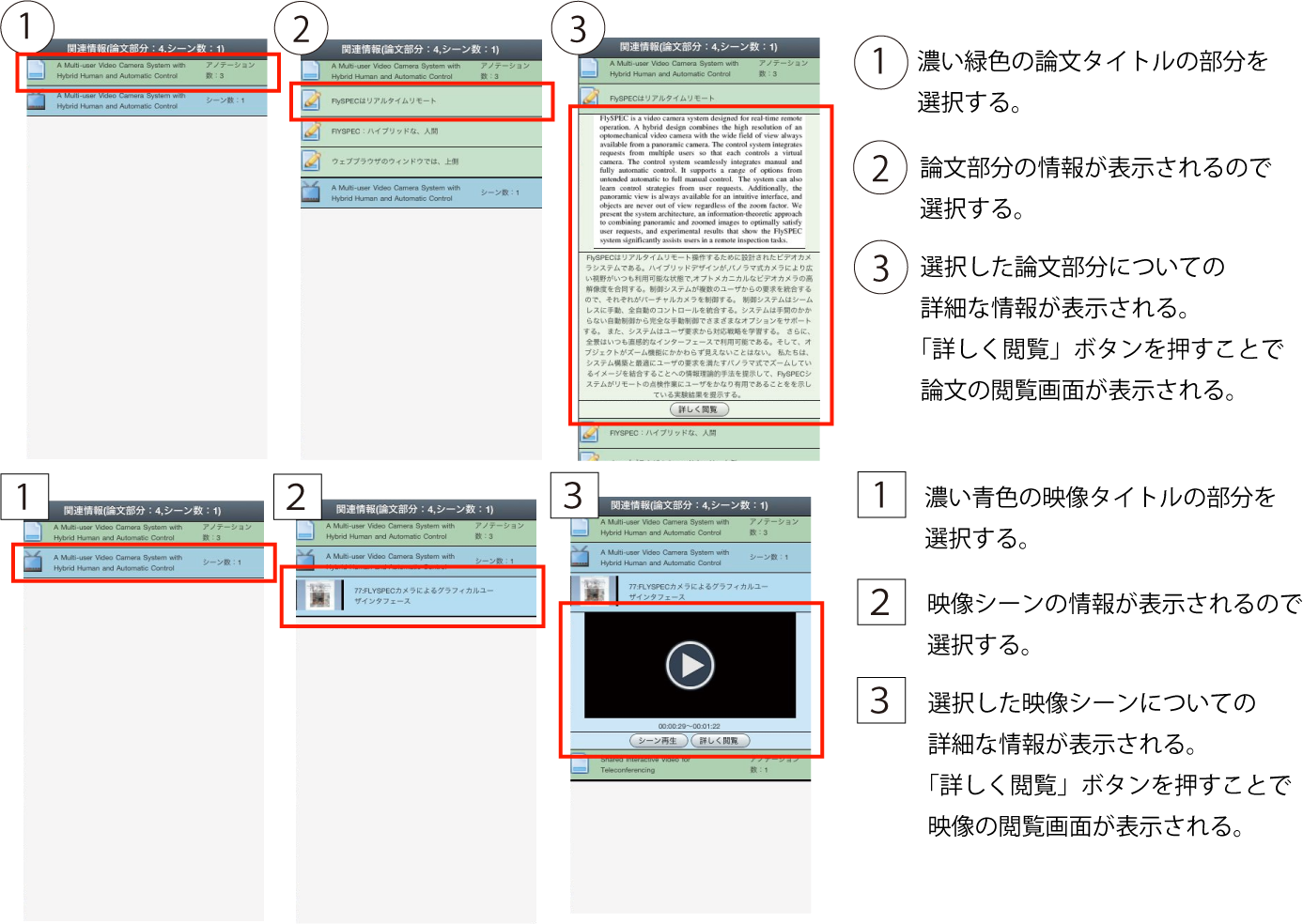
図4.8: 関連情報の展開図
リストの緑色の項目は,主として閲覧している論文,もしくはそれに関連付けられた論文部分についての情報である.図のように,リストの項目を選択することで詳細な情報が表示される.論文のタイトルの項目を選択することで,その論文に付与されているアノテーションの最初の数文字が記述された項目が表示される.そして,その項目を選択することで,論文部分と付与されているアノテーションが詳細に表示される.主として閲覧している論文に関連付けられた論文部分の情報の場合,「詳細に閲覧」ボタンが表示されるので,そのボタンを押すことで,その論文部分の引用元の論文を閲覧する画面が表示される.
リストの青色の項目は,主として閲覧している論文の部分に関連付いた映像についての情報である.論文についての情報と同じく,リストの項目を選択することで詳細な情報が表示される.映像のタイトルの項目を選択することで,映像シーンのタイトルとサムネイルが配置された項目が表示される.そして,その項目を選択することで,選択したシーンを再生するためのプレイヤーが表示される.プレイヤーの下部に配置された「シーン再生」ボタンを押すことで,シーンの再生が行われる.そして,「詳しく閲覧」ボタンを押すことで,そのシーンの作成元の映像を閲覧する画面が表示される.
映像シーンの項目を展開した時に,緑色の項目が出現する場合がある.これは,展開した映像シーンに関連付けられた他の論文の部分についての情報である.この項目も,展開することで,論文部分についての詳細な情報を閲覧することができる.
このように,関連情報のリストを段階的に展開して表示できるようにすることで,論文に多くの情報が関連付けられた時に,関連情報を俯瞰し,どの情報を閲覧するかを選択しやすくすることができると考えられる.
第4.3.1項の論文の閲覧部分についての説明で述べたが,論文の閲覧部分に表示される論文部分を表わす矩形を選択することで,選択した論文部分に関連付けられた情報が自動的に表示される.論文部分選択時の関連情報リストの変化を図に示す.このように,論文読解時に論文に関連付けられた情報をシームレスに閲覧することで,論文に関連する情報を探す負担を軽減し,論文読解の効率を向上させる.
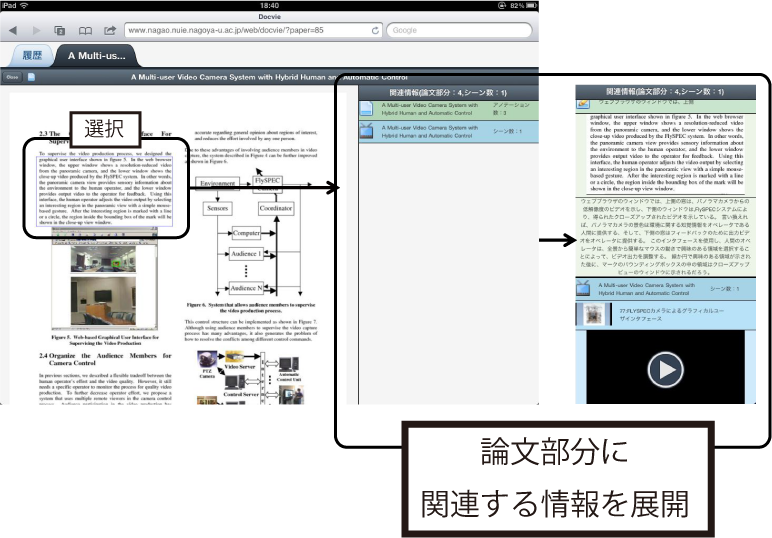
図4.9: 論文部分の選択に応じた関連情報の表示の変化
4.3.2 映像中心モード
映像中心モードの画面を図に示す.論文中心モードと同様に,画面の上部には現在開いている他のコンテンツを表示するためのタブが配置されている.そのすぐ下のタイトルバーには,現在開いている閲覧画面を閉じるためのボタン,閲覧モードを表わすアイコン,そしてコンテンツのタイトルが表示されている.画面の左側に主体として閲覧する映像,右側に映像に関連付けられた情報を表示する.この画面では,主体として閲覧する映像を,関連情報を参照しながら視聴することで理解を深めることを支援している.以下に,このモードでの機能について述べる.
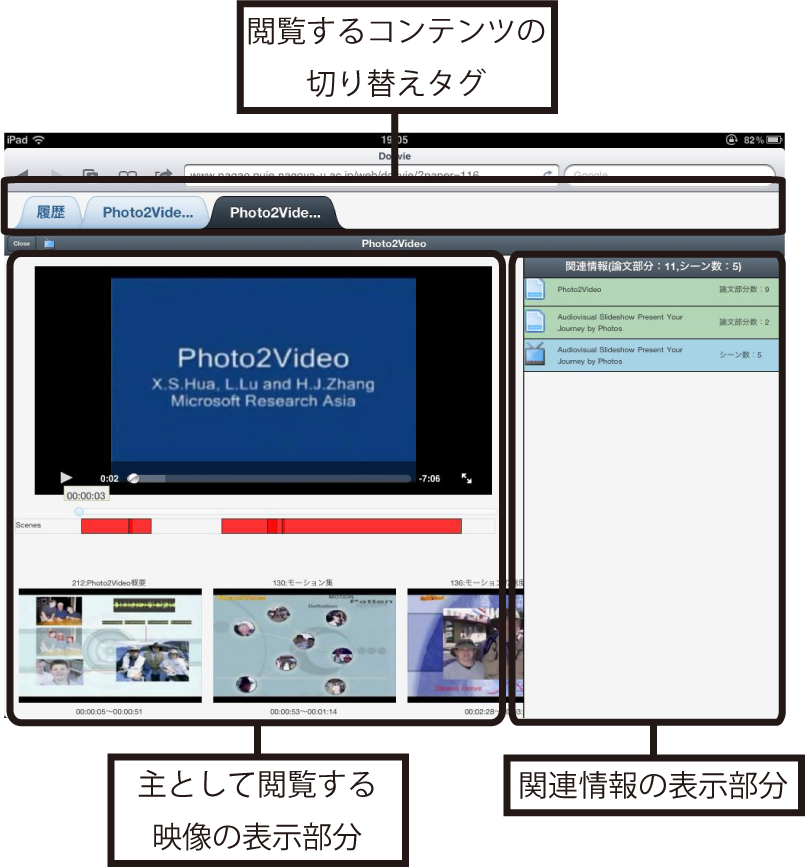
図4.10: 映像中心モードの画面
4.3.2.3 主として閲覧する映像の視聴部分
映像中心モード画面の映像の表示部分を図に示す.この部分には,映像のプレイヤーと映像のタイムライン,そして映像に含まれるシーンの情報が表示される.
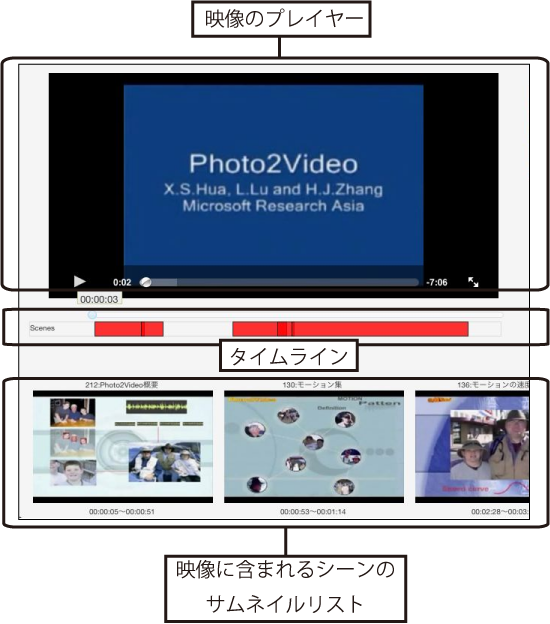
図4.11: 主として閲覧する映像の再生部分
プレイヤーの下部に設置されたタイムライン上には映像の再生時間が表示される.また,映像のどの部分がシーンとして定義されているかをタイムライン内に赤い矩形の形で表示する.これによって,ユーザは映像のどの部分からシーンの定義が行われているかを俯瞰することができるため,映像シーンへのアクセスの手掛かりになると考えられる.
タイムラインの下部には,映像に含まれているシーンのリストが表示される.リストには第3.2.1項で説明したSharvieでのシーン作成時に付与したシーンタイトルとシーンの代表サムネイル,シーンの開始・終了時間が表示される.サムネイルを選択することで,対応するシーンが上部のプレイヤーで再生される.サムネイル画像を表示することで,ユーザは映像を実際に再生せずにシーンの情報を閲覧することができるため,映像へのアクセスを効率的に行うことができると考えられる.これによって,ユーザは映像にどのようなシーンが含まれているかを俯瞰することができる.
映像中心モードの画面では,プレイヤーでの映像再生に対応して右側に関連情報の提示が行われる.関連情報の表示部分については次で述べる.
4.3.2.4 関連情報の表示部分
映像中心モードの関連情報の表示部分は,論文中心モードの関連情報の表示部分と同様の構成となっている.DRIPシステム上で閲覧中の映像のシーンと関連付けられた論文部分についての情報と,他の映像シーンについての情報が表示される.リストの項目の配色や展開方法については,論文中心モードの関連情報の表示部分と同様である.
論文中心モードでは,論文上に表示された矩形を選択することで関連する情報を自動的に展開していた.映像中心モードでは,映像の再生時間に応じて関連情報が展開される(図).映像の再生に同期して関連情報を自動的に提示することで,ユーザは視聴中のシーンについての理解を深めることができると考えられる.
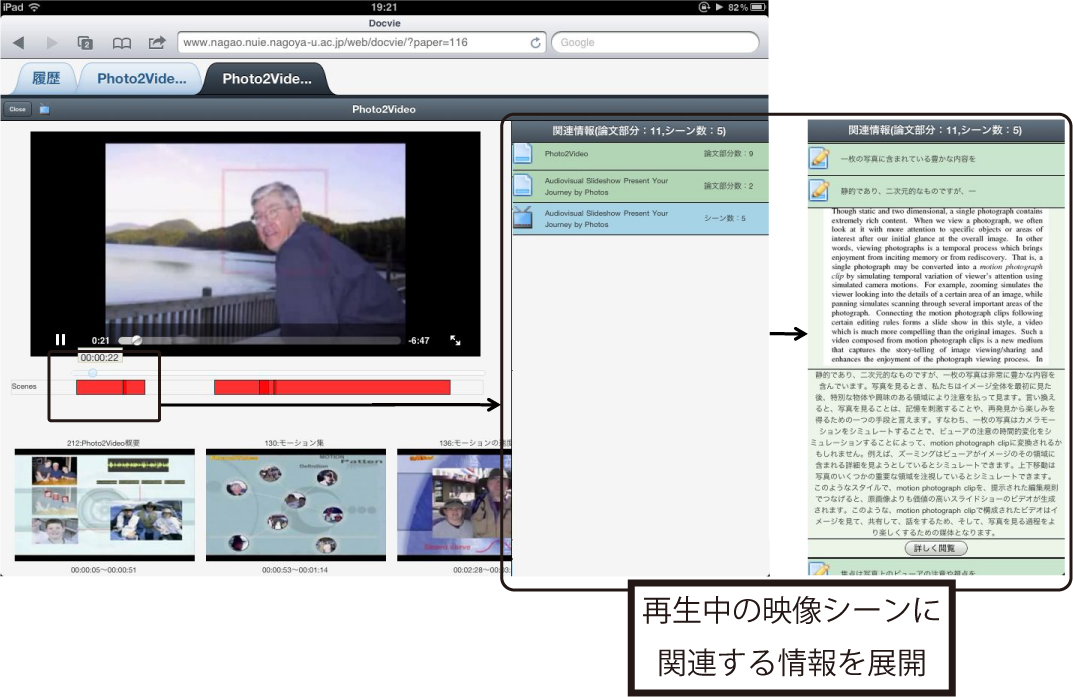
図4.12: 関連情報の展開
4.3.3 閲覧履歴の表示
Docvieでは,ユーザが閲覧したコンテンツの履歴を表示し,履歴から閲覧するコンテンツを選択することができる.これによって,以前に閲覧したコンテンツを再び閲覧したい時に関連情報を辿って目的のコンテンツを探す必要が無いため,ユーザの閲覧時の負担を軽減できると考えられる.
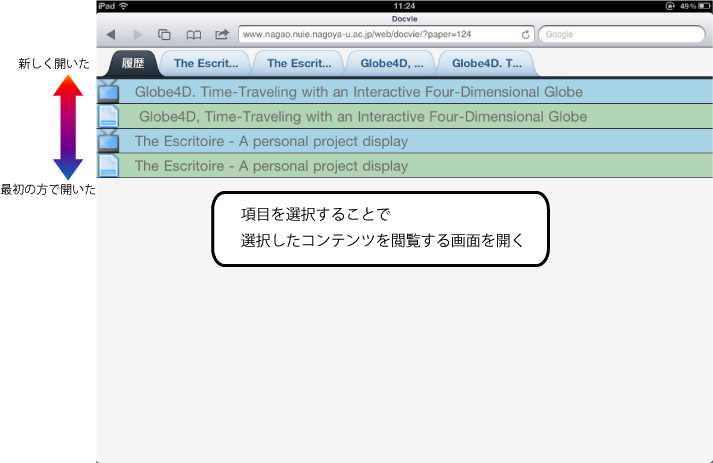
図4.13: 閲覧履歴の表示
図に閲覧履歴の表示画面を示す.閲覧履歴はコンテンツのタイトルと,そのコンテンツが映像か論文かを表わすアイコンのリストで表現される.再び閲覧したいコンテンツの項目を選択することで,そのコンテンツを主体とした閲覧画面がタブに追加される.新たにコンテンツの閲覧画面を開くと,それに対応して閲覧履歴にそのコンテンツの情報が追加して表示される.リストは,上部に最近閲覧したコンテンツが表示され,下にスクロールするほど過去に閲覧したコンテンツの情報が表示される.
4.4 まとめ
本章では,前章で説明したTDAnnotatorを論文読解システムとしてとらえた場合に不十分な点を挙げ,それを改善した論文読解支援システムDocvieのコンセプトとシステムの構成,そしてDocvieが持つ諸機能について詳しく述べた.次章では,DocvieとTDAnnotatorを用いた評価実験と,その考察について述べる.
5 実験と考察
本章では,前章で説明したDocvieの評価実験とその結果と考察について詳しく述べる.
まず第5.1節において実験目的について述べる.次に第5.2節で実験内容について述べる.第5.3節で実験結果について述べ,考察を行う.そして,最後に第5.4節で本章のまとめを行う.
5.1 実験目的
本研究で実現したDocvieの持つ最も特徴的な機能は,映像中心モードでの,映像を主体とした閲覧を行う機能である.映像中心モードでは,再生中の映像シーンに関連付けられた論文部分を閲覧することができる.これによって,映像を手掛かりにして関連する論文を探すことができる.
本実験は,映像を手掛かりにして論文を探す手法が論文読解を行う上で有効であるかどうかを検証することが目的である.本実験ではこれを評価するために,被験者による評価実験を行った.次節で実験の詳しい内容について述べる.
5.2 実験内容
本実験では,Docvieとの比較対象として第3章で説明したTDAnnotatorを利用した.第4章で述べたように,本研究ではTDAnnotatorでの,関連情報を辿って複数の論文と映像を閲覧することができないという問題点を,映像を中心に閲覧する機能を加えたDocvieを実現することで解決した.そのため,TDAnnotatorとの比較を行うことで,映像を手掛かりにして論文を探すという機能の有用性を検証することができると考えられる.
5.2.1 実験手順
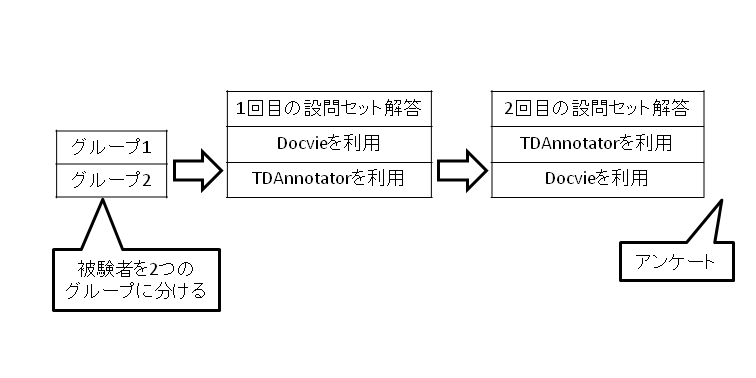
図5.1: 被験者実験の流れ
本実験では,DocvieとTDAnnotatorのどちらか一方を利用して被験者に設問を提示し,設問の回答数や回答速度,アンケートなどによって評価を行った.実験の流れを図に示す.被験者は6名で,1回目の設問への回答時にDocvieを利用する「グループ1」と,TDAnnotatorを利用する「グループ2」に分けた.まず,それぞれの被験者グループに設問セット1への回答を行ってもらった.設問セットとは,次項で述べる設問5問から構成されるセットである.これによって,DocvieとTDAnnotatorの2つのシステムの違いによって,どのような差が現れるかを調べることができる.2回目の設問への回答時は,「グループ1」と「グループ2」で回答に用いるシステムを入れ替える.すなわち,「グループ1」の被験者はTDAnnotator,「グループ2」の被験者はDocvieを利用して,それぞれ設問への回答を行う.これによって,1回目の設問への回答の結果が被験者グループの違いによって引き起こされたものかどうかを評価する.2回目の設問への回答時には,設問セット2の回答を行った.
設問セットの回答には,10分間の制限時間を設けて行った.これによって,被験者は可能な限り迅速に設問に回答しようとすると考えられるためである.
実験の最後に,DocvieとTDAnnotatorの使いやすさなどを被験者6名に対するアンケートで調査した.その結果を次節の後半で示す.また,次項で実験に利用した設問について述べる.
5.2.2 実験に用いた設問について

図5.2: 実験で出題した設問の例
本実験で利用した設問の例を図に示す.設問は,映像シーンと,映像シーンで説明されている研究に対する小問から構成される.小問は,記述されている文章が研究内容を正しく記述しているかどうかを判定するという形式である.1つの設問中に3つの小問が含まれている.
設問に回答する際に,被験者に対して,提示される映像シーンを視聴完了してから小問を読み,回答するという制約を設けた.これによって,被験者は映像シーンの視聴に集中することが可能になると考えられるためである.また,映像シーンの視聴中に回答を開始したかどうかの違いによって回答時間や回答数に影響が出ないようにするということも理由の一つである.
設問に回答する際にTDAnnotatorを利用する場合は,回答の手掛かりとなる論文のリストを提示する.リスト中の論文は,第3章で説明した仕組みを利用してアノテーションが付与されており,設問の最初に提示する映像シーンをはじめとする複数のシーンとの関連付けが行われている.これらの論文をTDAnnotatorで閲覧し,設問の回答を行う.TDAnnotatorで実験を行う場合,最初に提示される映像シーンの視聴は,第3.2節で述べたSharvieで視聴を行った.
Docvieを利用して設問に回答する際,映像シーンの再生を第4.3.2項で述べた映像中心モードで行う.そのため,映像シーンに関連付けられた論文部分の情報が自動的に提示される.また,論文部分から論文中心モードの表示画面を開き,論文を閲覧することも可能である.これらの情報を参照することで,設問の回答を行う.本実験では,閲覧する映像シーンに対して,複数の論文から論文部分を抽出し,関連付けを行った.そのため,Docvieを利用して実験を行う被験者は,関連付けられているどの情報が設問の回答に役立つかを複数の論文部分から探す必要がある.
5.3 実験結果と考察
5.3.1 設問の回答による評価
各被験者の,各システムを利用して設問に回答した際の設問回答数についての表を表5.1,5.2に示す.
表5.1,5.2からわかるように,どちらのグループもほとんどの被験者がTDAnnotatorを利用した場合と比べてDocvieを利用した場合の方が多くの設問に対して回答を行うことができた.被験者1については,どちらのシステムを利用した場合も同じ数の設問を回答しているが,後述するように,各設問を回答する際に要した時間に違いがあった.
各設問を回答するために被験者が要した時間について,表5.3,5.4,5.5,5.6,5.7に示す.
これらの時間は,被験者が,最初に提示した映像シーンの閲覧を終了してから設問に対する回答を終了するまでの時間である.どちらのグループも,Docvieを利用して設問に回答した場合の方(表5.3と表5.6)が,TDAnnotatorを利用した場合(表5.4と表5.5)よりも一つの設問の回答に要する時間が短く,表5.7に示すように,どちらの設問セットに対して回答を行う場合も,それぞれ平均2倍近くの早さで設問に回答することができた.また,被験者1は設問の回答数はどちらのシステムを利用した場合も同じであったが,回答に要する時間は表5.3,5.4からわかるように,Docvieを利用した場合の方が短く,回答数が同じであった理由はどちらのシステムを利用した場合も設問4に回答できなかったためであると考えられる.
表5.8に,各被験者の設問セット毎の小問回答数と正解数,正解率を示す.
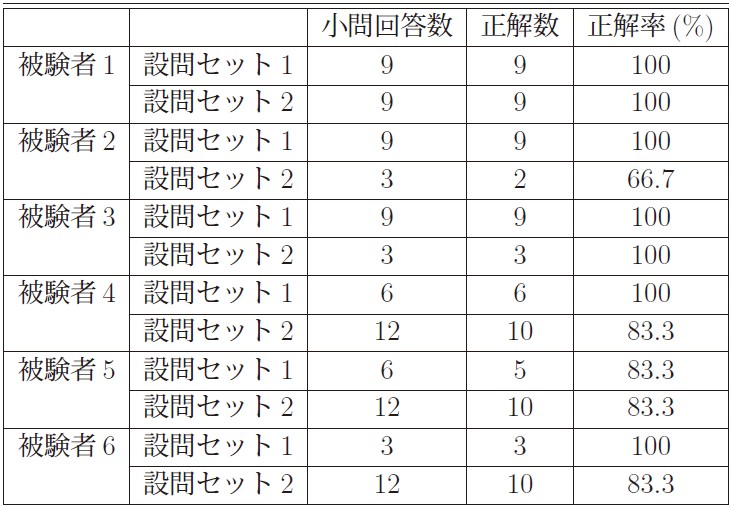
図5.3: 表5.8: 各被験者の小問回答数,正解数,正解率
被験者の中には,1問か2問の小問で不正解の回答を行っている者がいた.各被験者に対して,なぜ間違えたのかを尋ねたところ,主な不正解の理由は問題文の解釈の間違いによるものであるという回答を得た.そのため,正解数に関するこの結果から,両システムの問題点などに言及することはできないと考えられる.
設問への回答の際に,被験者に回答が不正解であることを知らせていれば,被験者は各システムを用いて論文と映像を閲覧し,回答を修正する必要がある.その結果,設問に回答する時間と設問の回答数に影響が現れる可能性がある.そのため,今後,設問への回答による実験を行う場合は,正解するまで次の設問に移行できないようにするなどして,被験者が研究内容を正しく理解するまでの時間を調査するべきであると考えられる.
以上の結果から,映像シーンを手掛かりに関連情報を探して理解を深める場合は,Docvieを利用した方がTDAnnotatorを利用して行う場合よりも効率的に理解を深めることができると考えられる.
5.3.2 アンケートによる評価
設問の回答後に,Docvieに関して,被験者に対して行ったアンケートの結果について示す.アンケートは,自由記述に加えて,以下の6つの項目で評価を行った.まず,以下の2つの項目について,「はい」,「いいえ」で評価を行った.
-
(質問1)論文の閲覧中に映像シーンを視聴することで,論文に対する理解を深めることができると思うか
結果:6人中6人が「はい」と回答
-
(質問2)映像の視聴中にシーンに関連する論文部分を参照することで,映像に対する理解を深めることができると思うか
結果:6人中6人が「はい」と回答
これらの結果から,Docvieの持つ映像中心モードと論文中心モードの2つの画面で閲覧を行うことで,関連情報を参照しながら映像と論文それぞれの理解を深めるという機能は有用であると考えられる.
次に,実験に用いた2つのシステムに関して,以下の4つの項目について,5段階の評価を行った.
-
(質問3) 映像の閲覧のしやすさについて,それぞれ5段階で評価してください
(3-1)Docvie
(3-2)TDAnnotator
-
(質問4) 映像の閲覧のしやすさについて,それぞれ5段階で評価してください
(4-1)Docvie
(4-2)TDAnnotator
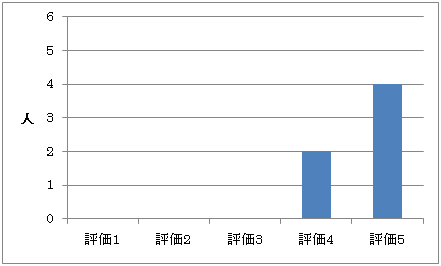
図5.4: アンケート結果(質問3-1)
質問3-1に関しては,図5.3のような結果となった.評価の平均が4.6であり,Docvieが映像を閲覧する際に使いやすいものであると言える.
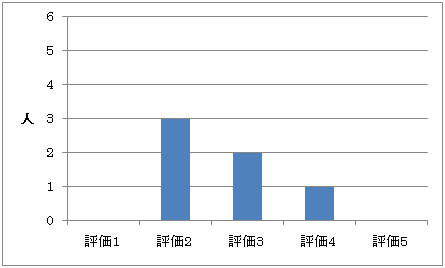
図5.5: アンケート結果(質問3-2)
質問3-2は,図5.4のような結果となった.評価の平均は2.4であり,TDAnnotator上では映像を視聴するには不十分であると言える結果である.
このような結果となった要因として,被験者からの意見に,TDAnnotatorで映像シーンを閲覧する際に必要な操作が多いというものがあった.第3.4節で述べたように,TDAnnotatorでは論文上に表示された矩形をクリックで選択しない限り,関連付けられた映像シーンを視聴することはできない.そのため,映像シーンを再生する際にユーザにとって負担が大きいと考えられる.そのため,矩形上にマウスオーバーした時点でポップアップで関連付けられた映像シーンを表示するなどして,ユーザの負担を軽減する必要があると考えられる.
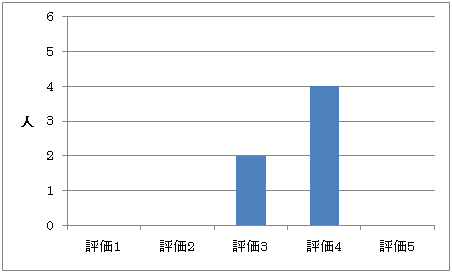
図5.6: アンケート結果(質問4-1)
質問4-1は,図5.5のような結果となった.評価の平均は3.6であった.現在のDocvieでの論文の閲覧方法が,十分に適切であるとは言えない結果である.
このような結果となった要因として,自由記述による被験者からの意見として,「映像中心モードで再生中の映像シーンに関連付けられた論文部分が自動的に提示されるが,どのような理由で論文部分が関連付けられているかわからない」という意見があった.また,他の意見として,「(映像中心モードでは)論文部分しか表示されないため,表示されている部分が元の論文のどのような章,節で述べられているか分からない」,というものがあった.これらの意見から,映像中心モードで映像に関連付けられている論文の情報を提示する際に,その部分が論文内のどのような位置付けか,またその部分がなぜ関連付けられているか,といった情報を提示することで評価を改善することができると考えられる.
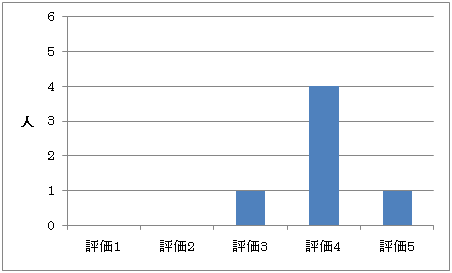
図5.7: アンケート結果(質問4-2)
質問4-2は,図5.6のような結果となった.評価の平均は4.0であり,TDAnnotatorが論文を閲覧するシステムとして有用であると言える.しかし,被験者からの意見として,「質問(3-2)と同じく,アノテーションを閲覧する際に必要な操作が多い」というものがあった.また,「アノテーションが付与されている部分を矩形で強調するだけでは,論文部分が多い場合はどの論文部分から閲覧を行うべきか判断しづらい」という意見があった.これを解決するためには,ユーザのアノテーションの閲覧回数やユーザによるアノテーションの有用性の評価などを行うことで,TDAnnotator上での論文部分の表示を変化させ,どの部分から閲覧するべきかの手掛かりをユーザに提示することが必要であると考えられる.
第5.3.1項での実験結果と,本項での結果から,Docvieを利用することで,映像シーンを関連情報を参照しながら閲覧し,理解を深めることができると考えられる.これによって,ユーザが映像の閲覧中に再生中の映像シーンについて疑問が生じた場合,関連情報を閲覧することで解消できると考えられる.
5.4 まとめ
本章では,第4章で提案した論文読解支援システムDocvieの,映像を手掛かりに論文を探しながら閲覧を行うという機能の有用性を評価するための実験について述べた.被験者に対して映像シーンを提示し,映像シーン中で説明されている研究内容についての設問を出題し,その設問をDocvieを利用して回答した場合とTDAnnotatorを利用した場合で回答数,回答に要する時間などを記録し,比較することで評価した.その結果,Docvieを利用した場合の方が効率的に設問の回答が行われ,映像を手掛かりにした閲覧を行うことの有用性を示すことができた.また,アンケートによるシステムの使いやすさの評価を行ったところ,映像の閲覧のしやすさについては高い評価を得た反面,論文の閲覧方法には不十分な点が見られた.
6 関連研究
本章では,本研究に関連する研究をいくつか紹介する.関連する分野として,論文読解に関する研究,文書に対するアノテーションに関する研究,映像に対するアノテーションに関する研究,そして映像と文書以外のコンテンツに対するアノテーションに関する研究について述べる.
6.1 論文読解に関する研究
論文読解を支援する研究の例として,島崎らの,検索エンジンを用いた英語論文読解支援システムが挙げられる.これは,Web上に存在する各種APIとAjax技術を利用して,英語論文に含まれる英単語の意味の検索や専門用語の抽出・検索などを論文を表示する画面と同じ画面で行うことで,ユーザが論文読解時に可能な限り論文と論文に関連する情報に集中できるようにするシステムである.
Docvieでは,アノテーションが付与され,論文部分として定義されている部分に対しては,付与されているアノテーションや映像シーンなどを論文部分と一緒に閲覧することができるため,論文読解を支援することができる.しかし,アノテーションが付与されていない部分を読解する際の支援は行っていないため,島崎らのシステムのような支援が必要であると考えられる.
他の研究として,文書に対してコメントやアンダーラインなどの注釈を付与して,内容について考えながら行う読み方であるActive Readingを支援するXLibrisがある.XLibrisでは,電子文書に対してペンタブレットを利用した自由な書き込みが可能である.ユーザは,紙の文書に対して行うように電子文書に対する注釈の付与を行うことができる.
本研究では,論文に対するアノテーションの付与はTDAnnotatorで,詳しい閲覧はDocvieで行っているが,今後Docvieでもアノテーションを付与することを支援したり,DocvieからTDAnnotatorをシームレスに呼び出せるようにしたりすることで,論文読解中の注釈の付与をスムーズに行えるようにするべきである.
6.2 文書に対するアノテーションに関する研究
林らは, 文書の引用行為に着目し,引用・被引用文書の関係を内部要素レベル(セクションやパラグラフ)で扱う仕組みを提案している.このシステムは,オンライン文書の閲覧時に論文の部分に対するマーキングとコメントの付与を支援し,この時の情報を閲覧時アノテーションとして記録・蓄積する.そして,閲覧時アノテーションを付与した部分を引用して論文を作成することを支援し,この時の引用・被引用についての情報を引用時アノテーションとして記録・蓄積する.この時得られた引用時アノテーションを利用することで,文書間の類似度を計算し,類似文書検索を実現した.
林らのシステムでは,対象となる文書はXML(eXtensible Markup Language)に基づく文書フォーマットである文書XMLによって記述されている.これによって,閲覧時アノテーションを付与する対象を文や句などの小さい単位で付与可能にしている.一方,本研究で実現したTDAnnotatorで論文部分を指定する際は,矩形による範囲選択を行う.しかし,図6.1のように,矩形では選択したい論文部分を正確に選択できない場合がある.そのため,この点に関して改良する必要がある.

図6.1: TDAnnotatorで論文部分を選択した場合の問題
6.3 映像に対するアノテーションに関する研究
本研究で利用した映像シーンを引用する仕組みは,山本らのSynvieの映像シーン引用ブログの仕組みを利用したものである.映像シーンに対して,引用先のブログに記述されたテキストを関連付ける.Synvieでは,関連付けられたテキスト情報を,映像シーン検索に利用している.本研究では,映像シーンと論文部分間の関連性を取得することができる.そのため,映像シーン検索に,論文のテキスト情報を利用することができる.論文のテキストからは,ブログから獲得することが困難であると思われる,研究分野に関する専門用語が含まれている.そのため,論文から得られたテキストを利用することで,映像シーン検索を研究調査のために利用したいという要求に,より適切に応えることができると考えられる.
映像へのアノテーションを獲得するその他のシステムとして,映像シーン連動型掲示板コミュニケーションシステムSceneNAVIがある .SceneNAVIは,Web上に存在している映像を閲覧しているコミュニティの間でコミュニケーションを行うシステムである.映像を,カット,テロップ,カメラの動き,人の声などを手掛かりにあらかじめ映像シーンへ分割しておき,各映像シーンに対してのコミュニケーションを行うことができる.SceneNAVIでは,掲示板型のコミュニケーションを行うことができ,コミュニケーションの過程において,映像上の任意の時間にコメントが関連付けられる.本研究の,映像に対するアノテーション手法との違いは,映像シーンがあらかじめ定義されているという点である.映像シーンは自動解析によって定義されるため,意味的な内容が考慮されているかどうかが問題となるが,あらかじめ映像シーンをユーザに対して提示することで,映像シーンを引用する負担を軽減し,映像に対してより多くの情報を関連付けることができる可能性があるため,今後の研究を進める上で参考にするべきである.
また,スライドの切り替えタイミングを利用して映像シーンの定義を行うシステムとして,edubaseがある.edubaseでは,スライドを利用して行われた講義の映像を公開している.講義映像の視聴画面には,映像中で利用されているスライドのサムネイル一覧が表示されており,マウスクリックで選択することで,選択したスライドを表示して説明している映像シーンが再生される.スライドは,画面に一枚ずつしか表示できないため,スライドを利用して講演する際,講演者は可能な限り,説明する内容をスライド一枚で完結させようとする.そのため,スライド単位で映像シーンを定義することで,映像を意味のある単位で分割できると考えられる.学会などで研究発表を行う際,ほとんどの発表者はスライドを利用している.また,我々の研究室でも,ディスカッションマイニングと呼ばれる,スライドを用いた会議の様子を記録し,再利用を可能とする技術を実現しており,同様に,撮影された映像をセグメントする手段の一つとして,スライドの切り替えタイミングを利用している.このようなことから,この手法は,スライドを用いた講演風景を撮影した映像に対して,広く適用できると考えられる.
6.4 映像と文書以外のコンテンツに対するアノテーションに関する研究
本研究では,映像と論文の関連付けについての手法を提案したが,今後の展望として,画像や音楽をはじめとする映像以外の様々なメディアとの関連付けを行うことが考えられる.そのため本節では,映像と文書以外に対してアノテーションの付与を行っている研究などについて述べる.
6.4.1 Webコンテンツに対するアノテーションに関する研究
任意のWebコンテンツに対するアノテーションを記述し,そのアノテーションを共有する仕組みにAnnoteaが存在する.Annoteaでは,Webコンテンツの任意の箇所にコメントを付与することができる.付与されるアノテーションはRDF形式で記述される.また,アノテーション箇所のポインタ情報をXPointerによって管理している.この仕組みは,アノテーションそのものを情報共有に使用することが目的であるため,アノテーションを利用してコンテンツ間を関連付けたり,マッシュアップコンテンツを生成したりといったことは行われていない.
任意のWebコンテンツに対して手書き入力によるアノテーションを付与する仕組みにPerowserExが存在する.ユーザは,付与したアノテーションを他のユーザと共有するかしないかを選択することができる.またPerowserExは,タブレットPCで快適に操作できることを目指しているため,キーボード・ショートカットを利用する代わりに,ペンジェスチャによる操作が可能となっている.ユーザはペン入力を行うだけで,簡単にWebコンテンツに対してアノテーションを付与することができる.
しかし,PerowserExでは主に紙に対してペンでメモ書きするかのようにアノテーションを付与できることに焦点を当てているため,アノテーションの対象を正確に機械が理解することはできない.そのため,本研究に対してこの手法を適用するためには,範囲指定や属性の付与など,ユーザに対してある程度の負担をかけることが必要である.
6.4.2 画像に対するアノテーションに関する研究
画像に対するアノテーションを付与することができるWebサービスに画像共有サービスであるFlickrが存在する.Flickrは,個人が撮影した画像を共有するサービスであり,画像の部分に対するコメント記述,画像に対するタグの記述,画像のブログエントリへの引用などの仕組みを提供している.Flickrでは,画像の部分に対してコメントを付与することができる.これによって画像の部分を強調し,画像を閲覧したユーザの注目を集めることができる.
研究内容を伝えるために論文に画像を掲載するなど,画像は広く普及したメディアであると言える.そのため,本研究で提案した仕組みを,画像に対しても適用できるように拡張することは有効であると考えられる.またその時に,Flickrのように画像の部分に対してアノテーションを付与可能にすることで,Docvieで論文や映像の閲覧中に,画像の注目個所を強調して表示するなどの支援が可能であると考えられる.
6.4.3 音楽に対するアノテーションに関する研究
音楽に対するアノテーションの研究として,梶らの研究が挙げられる.楽曲全体だけでなく,楽曲の時間区分に対してアノテーションを付与することができる仕組みである.得られたアノテーションに基づいて,検索や推薦などを行う仕組みについても提案を行っている.音楽には,映像とは異なり視覚的情報は含まれていないが,音声処理などの分野で研究が行われており,論文読解時に役立つメディアの1つであると考えられる.
7 おわりに
本章では,本論文をまとめ,今後の課題について述べる.
7.1 まとめ
本研究では,映像と論文に対してアノテーションを付与することで,映像シーンと論文部分間の関連性を取得する仕組みを提案した.そして,蓄積された関連情報を利用して,複数の論文と映像を閲覧することで理解を深めるシステムを実現した.さらに,被験者実験によって,実現したシステムの有用性を確認した.
第2章においては,研究活動を行う上で論文読解を行うことの重要性と,論文読解時に論文以外の情報,とりわけ映像を視聴することの有効性と問題点について述べた.そして,本研究のアプローチである映像と論文に対してアノテーションを付与する仕組みの概要について述べた.
第3章においては,本研究で実現した映像と論文に対してアノテーションを付与する仕組み,さらに,得られたアノテーションを利用することで可能な論文読解支援の仕組みについて述べた.まず,映像に対するアノテーションを行うシステムに関して,映像シーンの開始点と終了点を効率的に選択し,映像シーンについての情報を映像に対するアノテーションとして記録するシステムを実現した.次に,論文に対するアノテーションを行うシステムに関して,論文に対して論文部分の定義とその部分に関する情報をアノテーションとして付与するシステムであるTDAnnotatorを実現した.そして,映像シーンと論文部分の情報を引用し,引用した部分要素間の関連付けを行う仕組みを実現し,部分要素間の関連情報を取得した.さらに,得られた関連情報を利用することで,TDAnnotator上での映像シーンと論文部分の提示を行った.具体的には,TDAnnotatorで閲覧している論文中に定義されている論文部分を選択した際に,関連情報を利用して関連する映像シーンと論文部分の提示を行った.
第4章においては,関連情報を利用することでTDAnnotator上で実現した論文読解支援システムの問題点と,それを解決したシステムであるDocvieについて述べた.本研究で実現したDocvieでは,論文を主体として閲覧を行う論文中心モードと,映像を主体として閲覧を行う映像中心モードの2種類の閲覧画面での閲覧が可能である.これらのモードでは,主体として閲覧しているコンテンツを,関連する他のコンテンツの情報を参照しながら閲覧することで理解を深める.また,関連するコンテンツを詳しく閲覧するために,画面を切り替えて閲覧を行うことができる.これによって,論文を手掛かりにして,関連するコンテンツを辿るだけでなく,映像を手掛かりにして辿ることも可能となる.
第5章においては,Docvieの有効性を検証するために行った,被験者実験について述べた.具体的には,映像シーンで説明されている研究内容についての設問を用意し,TDAnnotatorとDocvieのそれぞれを用いて制限時間内に被験者に回答してもらった.この時の,各設問に要した回答時間,回答設問数,正解率などを記録し,利用したシステムの違いでどのような差が出るかを評価した.その結果,いずれの被験者の場合もDocvieを利用した場合の方が,TDAnnotatorを利用した場合よりも回答時間,回答設問数に優位性が見られた.その後,映像と論文を一緒に閲覧することの有用性や,システムの使いやすさについて評価するアンケートを行った.その結果,映像と論文を一緒に閲覧することで理解が深まるという評価を被験者全員から得た.また,システムの使いやすさについては,Docvie,TDAnnotator共に改善すべき点を指摘された.
第6章においては,論文読解支援についての関連研究について,文書および映像に対するアノテーションに関する研究,そして,他のコンテンツに対するアノテーションに関する研究について述べた.
7.2 今後の課題
今後の課題としては,以下のことが挙げられる.
7.2.1 Docvieの課題
7.2.1.1 閲覧するべき情報の推薦
本研究で提案する仕組みを継続的に運用した場合,関連情報が大量に取得できると考えられる.そのため,Docvieで関連情報を参照する際に,どの情報を参照するべきかを推薦する仕組みが必要である.現在Docvieでは,論文中心モードでは選択した論文部分に関連する情報のみを表示したり,映像中心モードでは再生中の映像シーンに関連する情報のみを表示したりしている.しかし,表示すべき情報が大量に存在する場合,更なる絞り込みが必要である.
これを解決するために,関連付けられた回数などが利用できる可能性がある.同じ部分要素間の関連付けが,複数のユーザによって行われている場合,その部分要素間には強い関連性があると考えられる.そのため,ユーザに対して優先的に提示することには意味があると考えられる.しかし,同じ部分要素間の関連付けが複数回行われるという事態がどの程度の頻度で行われるかは不明である.そのため,今後も継続的に運用し,関連情報を記録・蓄積することで有用なデータであるかどうかを判断する必要がある.
他に利用できる情報として,ユーザの操作履歴が考えられる.複数のユーザが閲覧した関連情報,関連情報の元のコンテンツを主体とした閲覧画面を開いた回数などを利用して,関連情報の重要度を計算する方法が考えられる.また,関連情報が役に立ったかどうかを評価する機能をDocvieに追加することで,関連情報の評価を行うことなども,関連情報の重要度を計算する上で利用できると考えられる.
7.2.1.2 関連情報の提示方法の改善
Docvieでは,閲覧している映像コンテンツに関連付けられた論文部分を閲覧する際に,論文部分しか閲覧できないため,その部分が元の論文内でどのような位置付けにあるかを理解することが困難である.これを解決するために,関連情報の表示部分で論文部分を提示する際に,元の論文の何ページの何章から引用された部分かといった詳細な情報を提示することが必要であると考えられる.
また,Docvieでは,コンテンツに関連付けられた情報が,どのような理由で関連付けられたかを知ることができない.そのため,関連情報を一緒に閲覧しても,主体として閲覧しているコンテンツに対する理解が深まるとは限らない.これを解決するために,Docvie上で関連情報が関連付けられた理由を提示する必要がある.
以上を実現するためには,関連付けを行う段階での改善が必要である.次項で,関連付けについての課題について述べる.
7.2.2 取得する関連情報についての課題
現在,DRIPシステム上で部分要素間の関連付けを行う際に取得している情報は,「部分要素間に関連性がある」という情報のみである.しかし,第7.2.1項で述べたように,関連付けがどのような理由で行われたかという情報が無いと,閲覧しているコンテンツとの関連性が分からず,理解の支援につながらない恐れがある.そのため,関連付けを行う際に,部分要素間にどのような関連性があるかという情報を取得するべきであると考えられる.
また,本研究で関連付けに利用したDRIPシステムでは,システムに引用した情報に新たな情報を関連付けることができる.この機能を利用することで,複数の部分要素に対して関連付けを行った場合の,部分要素間の関連付けの重要度を計算できると考えられる.第3.2.3項で述べたように,映像シーンと論文部分に付与されたアノテーションを引用した新たなノードを作成する形で要素間の関連付けを行っている.この時,各部分要素を共引用(Co-quotation)したノートの作成を支援する.これによって,文章中に引用した部分要素の情報が埋め込まれたノートの情報を取得できる.江藤は,文書は体系化されて構成されるため意味的に近い内容のものはまとまって述べられるという仮説を立て,引用先文書の引用箇所間の距離が共引用における文書間の類似性に影響を与えると述べている.本研究では,引用される情報は映像シーンのような,文書以外の形式の情報であるが,同じことが言える可能性がある.そのため,今後このような情報を記録し,解析することで重要度を計算することができると思われる.
7.2.3 TDAnnotatorの課題
TDAnnotatorで論文部分を選択する場合,現在のところ矩形による範囲選択を行っているが,この選択方法では第6.2節で述べたように,選択したい論文部分を正確に選択できない場合がある.そのため,論文部分の選択を,矩形単位ではなく文章や図単位で行えるようにするべきである.
これを解決するために,PDF形式の論文を,XMLのような内部構造が詳細に定義された形式に変換する必要がある.これによって,論文部分を詳細に指定し,かつ選択された部分にどのような情報が含まれているかも取得できる.また,第7.2.1項で述べたDocvieで関連情報として論文部分を提示する際に,論文部分の位置付けや周辺の文脈を提示するためにも利用可能である.
また,TDAnnotatorは論文の各ページを画像に変換して表示しているため,選択した論文部分に含まれている情報を取得するために,ユーザに,論文部分の内容についての情報の入力を要求している.この操作はユーザにとって負担であり,また,入力ミスなどによって誤った情報が付与される可能性がある.これに関しては,OCR (Optical Character Recognition)などの文字認識を利用して,論文部分内に含まれるテキスト情報を自動的に抽出することで部分的に解決できると考えられる.
7.3 今後の展望
今後の展望としては,以下のことが挙げられる.
7.3.1 他の種類のコンテンツへの適用
本研究では,映像の持つ情報量の多さや,今後,映像が普及する可能性などに着目し,映像と論文の関連付けについての手法を提案した.しかし,現在,映像の他にも音楽や画像など,様々なメディアが普及しており,また論文と一緒に閲覧することで理解が深まる可能性がある.そのため,本研究で提案した仕組みを他のメディアに対して適用できるように拡張することが考えられる.
7.3.2 コンテンツの自動編纂
本研究で提案した仕組みを改善・運用し,大量のアノテーションを蓄積することで,映像と論文のより高度な応用が可能になると考えられる.例えば,コンテンツの自動編纂である.編纂とは,複数のコンテンツを編集・統合し,1つのコンテンツとしてまとめることである.例えば,「画像処理についての研究」について知りたいというユーザに対し,本研究で得られたアノテーションから関連情報を抽出し,画像処理に関する論文の重要な部分とそこについての説明を行っている映像シーンからなるコンテンツを自動的に生成し,提示することができれば,そのユーザにとって非常に役立つと考えられる.
このような仕組みを実現するためには,第7.2.2項で述べたような関連情報の取得の仕組みを改善する必要があるなど,様々な課題が残されている.しかし,これを実現することで,Web上に大量に存在するコンテンツを効率的に閲覧する有効な手段が得られると考えられる.
謝辞
本研究を遂行するにあたり,指導教員である長尾確教授をはじめ,数多くの方々に御支援,御協力を頂きました.ここに感謝の意を表します.
指導教員である長尾確教授には,研究に対する姿勢や心構えといった基礎的な考え方から,研究に関する貴重な御意見,論文執筆に関する御指導など,大変お世話になりました.心より御礼申し上げます.
松原茂樹准教授には,主にゼミで,研究に関する様々な御意見を数多く頂きました.心より御礼申し上げます.
大平茂輝助教には,昨年度には,ビデオプロジェクトリーダーとして御指導頂き,研究に関する様々な御意見を頂きました.また,本年度も,全体ゼミなどで,様々なご意見を頂きました.心より御礼申し上げます.
土田貴裕さんには,ゼミ等で研究に関する様々な御意見を数多く頂きました.また,研究室の雰囲気作りをしていただきました.ここに御礼申し上げます.
石戸谷顕太朗さんには,研究に対する姿勢や心構えについて何度も御指導頂きました.また,本年度はビデオプロジェクトリーダーとして御指導頂き,様々な御意見を頂きました.ここに御礼申し上げます.
棚瀬達央さんには,同じビデオプロジェクトの一員として,研究に関する様々な御意見を頂き,様々な面で大変お世話になりました.ありがとうございました.
森直史さん,木内啓輔さん,井上泰佑さん,高橋勲さん,渡邉賢さん,磯貝邦昭さんには,ゼミ等での貴重な御意見など,研究生活の様々な場面において大変お世話になりました.ありがとうございました.
長尾研究室秘書の鈴木美苗さん,土井ひとみさんには,学生生活ならびに研究活動のための様々なサポートを頂きました.ありがとうございました.
最後に,影ながら見守っていただき,日々の生活を支えてくださった,家族に最大限の感謝の気持ちをここに表します.ありがとうございました.