
映像と論文へのアノテーションに基づく論文読解支援システム
概要
仕事や研究をよりよいものにするためには,先行研究や新しい技術の調査を行って,できるだけ多くの論文を読解し,自らの活動に反映していくことが必要である.しかし,論文だけを読んでも研究内容を理解できない場合がある.このような場合,論文以外の他の情報を参照することが有効であると考えられる.特に映像は論文で表現が困難な情報を含む有益な資料である.しかし,映像を論文と一緒に閲覧する際,論文の部分に関連するシーンを選択的に視聴しないと理解が深められないと考えられる.そこで本研究では,映像に含まれるシーンと論文に含まれる部分の定義,そしてこれらの間の関係についての情報をアノテーションとして記録・蓄積した.さらに,得られた関係情報を利用することで複数の映像と論文の閲覧を支援する仕組みを実現し,実験により評価した.
まえがき
仕事や研究をよりよいものにしたり,新しいアイディアや企画を生み出すためには,新しい研究や技術はもとより,先行する研究や技術の調査が非常に重要である.このような調査は,しばしば対象としている分野の論文やマニュアル,書籍などの文書を読むところから始まる.
ある文書が理解しやすいかどうかを考える場合,文書全体の構成,文章の論理性,文体や図・表が充実しているかなどが問われる.なかでも,著者の想定した読者が,実際の読者と合致しているかが特に重要な要素であろう.例えば,学習を始めて間もない初学者が専門分野の論文を充分に理解するためには,その文書が書かれた背景を認識することや基礎知識の蓄積が不可欠になる.その論文の文章や,挙げられている参考文献だけを読んでも,その内容を充分に理解するのは困難であろう.そして,特に論文などでは初学者が内容を理解するために必要な基礎的な事柄が詳述されることは少ない.初学者でなくとも,システムの動作や実験風景などについて,文書に含まれるテキストや図だけでは状況を充分に理解することが困難な場合がある.
このような場合,参考文献に挙げられている文書だけでなく,元の文書の内容に関連する様々なコンテンツを参考にすることが理解の補助となる.例えば,システムのデモビデオや,文書に書かれている内容について会議や学会などで発表された時の記録映像,あるいはその発表資料や開発したシステムの詳細な設計図,関連分野の基礎的な内容に関する書籍など,元の文書そのものには含まれていないが,内容の理解の補助となるコンテンツである.
しかし,関連するコンテンツを寄せ集めただけでは,効果的な読解支援は期待できない.論文に対する理解を促進する目的で,1時間を超えるような映像が提示されたとしても,論文の一部を理解するためにそのような映像を閲覧するのは時間的な負荷が高い.そのため,ある文書の部分を理解するために必要な映像の部分を切り出して提示することが必要であると考えられる.
%映像や文書の部分を扱うためには,部分を表すメタ情報が必要となる.このようなメタ情報を付与するのは負荷が高く,特定のユーザが単独で,自身が閲覧しているすべての文書に対して,文書の理解を補助するような他のコンテンツの部分を切り出して,文書の特定の部分に関連付けていくことは困難であり,また,そのような労力をかけるだけの動機付けは困難である.そこで,本研究では,ある研究領域について複数人が共同で研究している環境(例えば,同一の同じテーマで研究を行っているプロジェクト)を対象とし,論文の読解を必要とするユーザ(学生,研究者)同士が協調して参考になる論文や映像に対してアノテーションを付与することを想定する.ただし,本研究では,アノテーションが付与されたコンテンツを利用した読解支援を中心に扱い,協調的にアノテーションを付与することによって,アノテーションの付与に必要な労力がどの程度下がるのかなどについての議論は今後の課題とする.
例えば,大学の研究室では,毎年,新たに学生が配属されてくる.一般に,このような学生に研究室の教授や先輩が執筆した論文を読ませて,理解させるのは困難である.その理由のひとつとして,研究室で行われてきた研究の背景知識が乏しく,その論文を読んだだけでは,その内容を充分に理解できないことが挙げられる.このような場合,論文の部分に対して,その部分の理解を補助するような映像が関連付いていれば読解の補助になるであろう.
説明のため,より具体的に,著者が所属する研究室に配属された学部4年生に本論文を読ませることを考える.本論文に,後述のSynvie(映像アノテーションシステム)やDocvie(論文読解支援システム)のインタフェースの動作を説明した映像の部分や,関連研究それぞれの論文の一部分が適切に関連付いていれば,内容の理解がより容易になると考えられる.学生が,Synvieを拡張して実現した映像シーンに対するアノテーション画面の映像を閲覧し,その映像シーンと関連付けられた,Synvieについて記述された論文の引用インタフェースに論文の部分や,Synvieの先行研究であるiVAS(本文の参考文献ではないので脚注に論文への参照を入れる.D Yamamoto and K Nagao. IVAS: Web-based Video Annotation System and its Applications. In 3rd International Semantic Web Conference(ISWC2004), pp. 7-11, 2004.)やCo-Annotea,Annotea(同上,J. Kahan, M.-R. Koivunen, E. Prud’Hommeaux,and R.R. Swick. Annotea: An Open RDF Infrastructure for Shared Web Annotations. Computer Networks, Vol. 39, No. 5, pp. 589 - 608, 2002.)のインタフェースについて説明した論文の部分や映像の部分を参考にして読み進めていけば,本論文への理解が深まるであろう.
このような状況は,大学の研究室だけでなく一般的に起こりうる.本研究では,文書の読解,中でも論文の効率的な読解を支援するために,論文と映像の部分要素の定義とその関係に基づいて関連コンテンツを閲覧できるシステムについて提案する.
本研究では,まず,論文の部分(例えば,段落,文,図,表など)に対するアノテーションを獲得する仕組み,映像の部分(例えば,シーン,ショットなど)に対するアノテーションを獲得する仕組み,そして,それぞれのシステムによって蓄積された部分要素間の関係情報を獲得する仕組みについて,順に述べる.次に,それらのメタ情報に基づいて関連コンテンツを閲覧できるシステムについて説明する.そして,本システムを用いて被験者実験を行った結果,論文を効率的に読解できることを確認したので詳しく考察する.
1 関連研究
論文を充分に理解するためには,その背景になる知識がなければならない.論文を効率的に読解するためには参考文献だけでなく,関連する様々な種類のコンテンツを閲覧することが有効であると考えられる.文書に関連するコンテンツの効率的な閲覧を支援するためには,論文や映像などのコンテンツの部分要素を獲得すること,部分要素間の関係情報を獲得すること,そして,部分要素とその関係情報に基づいて文書と文書に関連するコンテンツの効率的な閲覧を支援するインタフェースを構築する必要がある.以下に,それぞれの課題についての関連研究を示す.
文書に対するアノテーションを行う研究は数多く行われている.中でもXLibrisでは,電子文書の部分要素に対してペンタブレットを用いて注釈を付与することができ,注釈を含む文書の部分要素をユーザ間で共有する仕組みを実現している.
映像の部分要素を獲得する手法に関係して,Sawhneyらの映像の内部構造を表現するための仕組みであるHypervideoを挙げる.Hypervideoでは,映像を複数の映像シーンに分割するメタ情報を付与し,テキストなどの他のコンテンツと関連付けて扱えるようにすることで,映像を取り扱いやすくするための仕組みである.また,長尾らは,映像シーンに対するメタ情報をWeb上のコミュニティ活動から獲得する,オンラインアノテーションを提案している.オンラインアノテーションの実装である山本らのSynvieでは,映像シーンを引用したブログ記事を書けるようにすることで,映像シーンの定義とそれに対するテキストアノテーションを獲得し,映像シーンの検索に応用している.
また,本研究では取り扱わなかったが,映像だけでなく学会発表や講義で利用するスライドやミーティングの音声など,様々なマルチメディアコンテンツの部分要素に対するアノテーションを利用することで,論文読解を支援できると考えられる.例えば,KamらのLivenotesやDavisらのNotepalsでは,講義中のスライドの一部分に対して講義の受講者がアノテーションを付与できる.
これらのマルチメディアコンテンツ間の関係を獲得する手法に関して,HunterらのCo-Annoteaがある.Co-Annoteaはマルチメディアコンテンツの部分要素に対するアノテーションと,部分要素間の関係を付与できるシステムである.付与したアノテーションに基づいて,複数のマルチメディアコンテンツを読み込んでアノテーションを確認しながら閲覧することができる.
コンテンツの部分要素を組合せて新たなコンテンツを作成することに注目した研究について,ChambelらのHTIMELをあげる.HTIMELでは,映像シーンとテキストの部分要素,画像を組合せたハイパーメディアコンテンツをユーザが自由に作成できる環境を実現している.HTIMELは,コンテンツを組合せてハイパーメディアを作成することができるが,そのコンテンツの閲覧者はハイパーメディアの作成者が意図した範囲のコンテンツしか閲覧することができない.
本研究では,コンテンツの部分要素とその関係を利用して,論文の読解を支援するためのインタフェースを実現する.論文読解を支援するためには,他のユーザが付与したアノテーションを手がかりに読解できるようにすることが有効であろう.テキストによるアノテーションだけでなく,映像や他のマルチメディアコンテンツの部分要素が互いに関連付けていれば,閲覧している部分要素と関連付いているコンテンツを辿って閲覧することができる.先述したCo-Annoteaにおいても,部分要素に関連付けられた他のコンテンツの部分要素を,単一のインタフェース上で閲覧できる仕組みを提供している.Co-Annoteaのユーザはコンテンツの部分要素間が関連付いている限り,アノテーションを辿って行くことで,多種多様なコンテンツを閲覧することができるが,論文読解などの特定の用途に特化してはおらず,またインタフェースに対しての定量的な検証も行われていない.
そこで本研究では,まず我々の研究室で研究開発が行われてきた,コンテンツにアノテーションを行うためのシステムを適宜拡張することで,ユーザが日常的な研究活動で閲覧する論文や映像の部分要素に対するアノテーションと,部分要素間の関係を記録する.そして,獲得したアノテーションに基づいて,ユーザが注目しているコンテンツの種類(論文または映像)に応じた,関連するコンテンツの部分要素を効率的に閲覧できるインタフェースを実現する.さらに,実現したインタフェースの論文読解に対する有効性を検証した.
なお,ユーザのアノテーション行為そのものが学習や読解の支援につながるとするActive Readingという手法があるが,本研究では,次章で説明するアノテーションの仕組みをコンテンツの部分要素に対するアノテーションを獲得するためにのみ用い,アノテーションを付与する過程における学習・読解支援については別の機会に扱うことにする.
2 論文と映像のアノテーションの獲得
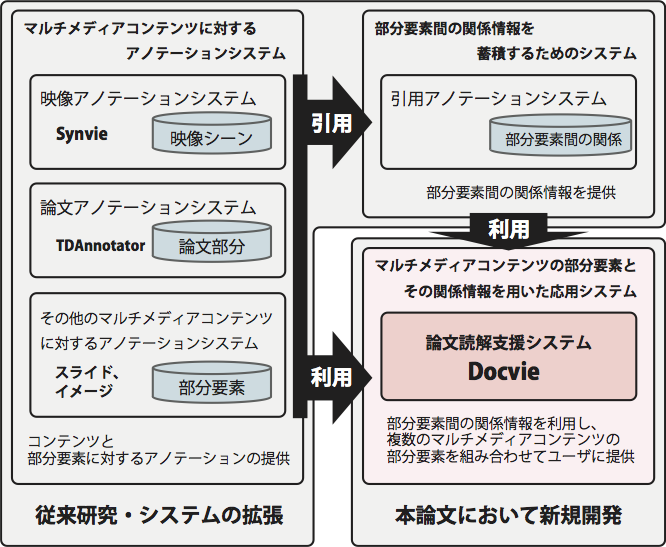
図1: コンテンツの部分要素間の関係を利用した論文読解支援の仕組み
図に示すように,論文に関連するコンテンツの効率的な閲覧を実現するためには,論文と映像の部分要素,および部分要素間の関係情報を獲得する必要がある.本研究では,論文の部分要素を取得するためのシステムとして,文書に対するアノテーションを行うことのできる様々な先行研究を参考にして,TDAnnotatorと呼ばれる新たなシステムを構築した.また,映像の部分要素を取得するための仕組みとして,我々がこれまでに研究・開発を行ってきた映像アノテーションシステムSynvieの映像シーン引用ブログを記述するためのインタフェースを利用して,映像シーンを定義して保存するためのインタフェースを開発した.さらに,部分要素間の関係情報を獲得・蓄積するために,引用アノテーションシステムを構築し,論文と映像の部分要素を引用できるようにした.なお,いずれの仕組みも,コンテンツの部分要素とその関係を獲得するために,先行研究を参考にして開発したり利用したりすることで実現しており,特に新規性はない.また,将来的には,関連付けるコンテンツの部分要素は映像に限らずスライドやイメージなども利用できるようにする.
先述したように,ユーザはこれらのアノテーションの仕組みを用いて,同じプロジェクトで研究している他のユーザと協調して,部分要素に対するアノテーションを行う.そして,日常的な研究活動の中で,矩形アノテーションを行える仕組みによって映像や論文へのアノテーションを蓄積していく.それぞれのアノテーションシステムは,別々のサーバで稼働しているが,ユーザ情報の管理を集中的に行うユーザ管理サーバを用いて,シングルサインオンを実現している.これによって,ユーザは認証を一度行うだけで全システムを利用することができ,それぞれのシステムが記録するアノテーションと関連付けされるユーザ情報は全システム共通である.また,それぞれのシステムは,他のシステムと連携するために,自身が管理しているコンテンツの情報を提供するAPIを実装している.
次に,映像と論文のそれぞれについて部分要素に対するアノテーションを作成する仕組み,両者の関係を獲得する仕組みについて詳述する.
2.1 論文へのアノテーション
論文に対するアノテーションを作成・閲覧するために,TDAnnotatorを開発した.TDAnnotatorの論文読解インタフェースを図に示す.この画面では論文の各ページが画像に変換され,アノテーションが付与された論文の部分が,状態ごとに色分けされた矩形で表示される.この矩形は,ユーザが論文の一部分に対してアノテーションを付与するために定義・作成する論文の部分要素である.以後この矩形領域を論文部分と呼ぶ.赤い矩形で表される論文部分は(図中の論文中段右側の細線の矩形)は,アノテーションが付与されていることを示す.また,青い矩形で表される論文部分(同,左上の太線の矩形)は,節で述べる関連付けの仕組みを用いて,映像シーンが論分部分に関連付けられていることを示しており,これは章で述べる実験で利用する.

図2: TDAnnotatorの画面
TDAnnotatorでアノテーションを行うためには,まず,画面に表示される論文上でマウスドラッグ操作を行って矩形範囲を選択(続けて複数の矩形範囲を選択することで複数の矩形範囲に対するアノテーションも可能)し,選択した矩形範囲をクリックすると,その矩形に対するアノテーションを入力するダイアログが表示される.このダイアログで矩形内容(本文,数式,グラフ,表,図,タイトル),文章タイプ(翻訳,書き起し,コメント),アノテーションの本文を入力する.
なお,すでに定義された論文部分の内側の部分に対してアノテーションを行う場合にも新たに,アノテーションを付与する場合と同様に,インタフェース上でドラッグ操作を行うことで新たな論文部分を定義できる.このような他の論文部分に包含された論文部分を選択する場合には,1回目のクリックが論文部分の選択となり,選択された論文部分がハイライトされ,2回目のクリックでダイアログが表示される.
アノテーションの登録を行うと,データベースには上述の矩形範囲(論文のページ番号,位置,サイズ)の集合,矩形内容,文章タイプ,アノテーションの本文,論分部分を含む論文のID,アノテーション作成者の全システム共通のIDが記録される.
また,他のユーザが定義した論文部分やユーザ自身が以前に定義した論文部分に対してアノテーションを付与することもできる.論文上に配置された論文部分をクリックするとアノテーション一覧が表示され,「Add Annotation」ボタンを押すことで既存の論文部分に対してアノテーションを付与することができる.この場合,データベースにはすでに定義された矩形範囲のIDとアノテーションが関連付けられて保存される.
付与されたアノテーションは付与したユーザのみが編集・削除を行える.ただし,矩形範囲に付いては,指し先のないアノテーションを防ぐために,他者がアノテーションが行っていたり,後述の仕組みで関連付けが行われている場合は,削除することができない.
論文上に表示される矩形を選択することで,付与されているアノテーションの内容を閲覧できる.また,論文に対するアノテーションはユーザ間で共有され,あるユーザが付与したアノテーションが後続のユーザの読解時の手がかりとなると考えられる.
2.2 映像へのアノテーション
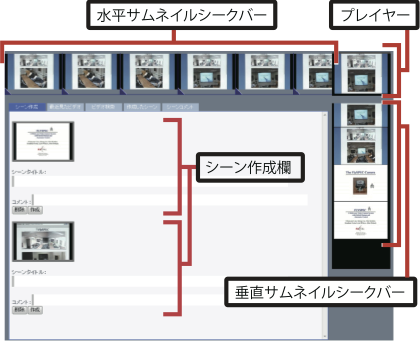
図3: 映像シーンを引用するインタフェース
図に映像シーン引用を行うためのユーザインタフェースを示す.引用を行うためには,まず引用したいシーンを含む映像コンテンツを,ユーザの閲覧履歴やキーワード検索を用いて読み込む.画面は,右上に配置された映像を再生するためのプレイヤー,そして,プレイヤーの水平方向・垂直方向に一定時間ごとのサムネイル画像を並べたシークバー(以下,サムネイルシークバーと呼ぶ)によって構成される.映像の再生を開始すると映像に同期して左右,上下にそれぞれサムネイル画像が移動する.また,サムネイル画像をドラッグすることで,プレイヤーをシークできる.水平サムネイルシークバーは,1秒間隔でサムネイル画像が表示され,引用する映像シーンを決定するために利用する.垂直サムネイルシークバーは映像を素早くシークするために利用する.
シークして引用したいシーンを発見したら,水平サムネイルシークバー上で開始フレームと終了フレームを選択することで引用するシーン区間を設定できる.引用するシーン区間を決定すると,映像シーンがシーン作成欄に追加されタイトル入力欄が表示され,タイトルを設定するとシーンの作成が完了する.これにより,映像シーンの開始・終了時間,タイトルを獲得できる.
すでに定義されたシーンはサムネイルシークバー下部に表示され,自分で定義したシーンと同じように,他のユーザが定義したシーンに対して新たなアノテーションを付与することができる.
定義したシーンは,TDAnnotatorと同様に指し先のないアノテーションを防ぐため,他人がアノテーションを付与していたり,後述の仕組みで関連付けされている場合には削除できない.
データベースには,シーンの開始時間,終了時間,タイトル,シーンを含む映像のID,全システム共通のアノテーション作成者のIDが映像シーンの情報として記録される.
2.3 論文と映像の部分要素の関連付け
本研究では,論文・映像の部分要素間の関係情報を獲得するための仕組みとして,引用アノテーションシステムを利用した.このシステムは,ユーザがスライドや,そのスライドを利用して発表した会議において他者から得られた発言(映像とテキストによって表される)を引用しながらメモを書き,メモの内容を振り返ったり俯瞰したりしながら自身の活動をよりよくしていくためシステムである.ユーザは,クライアントアプリケーションを自身のPCにインストールして利用する.本研究では,引用アノテーションシステムで引用できるコンテンツとして新たに映像と論文を追加し,引用する映像と論文の部分要素に関するメタ情報を蓄積しているTDAnnotator(論文),Synvie(映像)などの各システムから,コンテンツの部分要素を読み込み,必要な部分を引用したメモを作成できる.ユーザが同じメモにコンテンツの部分要素を引用(これを共引用と呼ぶ)したという情報を用いることで,部分要素間の関係を獲得する.
部分要素を管理する各システムには,引用アノテーションシステムにコンテンツの部分要素を読み込むために,部分要素一覧画面が用意されている.引用アノテーションシステムから「映像シーンの検索」「論分部分の検索」メニューを選択すると,ブラウザが起動して各システムの一覧画面に遷移する.一覧は,コンテンツのタイトル,部分要素に付与されたアノテーション本文などのテキストを対象とした全文検索によって絞り込むことができる.そして,部分要素ごとに「引用」ボタンが設置されており,このボタンを押すと,クライアントアプリケーションが立ち上がって,部分要素が読み込まれノードとして表示される.
図に引用アノテーションシステムで表現されるノードの種類を示す.あるコンテンツの部分は,コンテンツを表すノードとそれに接続された部分要素を表すノードによって表現される.これは,一つのコンテンツから複数の部分を引用した場合に,それらが元は一つのコンテンツから引用されたことを明示するためである.映像シーンは,その映像シーンを含む映像ノードに接続された部分要素を表すノードとして表現される.映像ノードをダブルクリックするとSynvieで再生され,映像シーンノードの場合は,映像中の特定のシーンのみが再生される.論文部分も映像シーンと同様に,論文ノードに接続された部分要素を表すノードとして表現され,論文ノードをダブルクリックすると該当論文がTDAnnotatorで表示され,論文部分ノードの場合にはTDAnnotator上で論文部分がハイライトされる.
次に,図に,読み込んだコンテンツの部分要素を引用してメモを作成する手順を示す.ユーザは,引用アノテーションシステム上で引用したい映像シーンおよび論文部分ノードを選択して(図 (1)),コンテキストメニューを開き「メモ」を選択する(図 (2)).すると,メモのタイトルを入力するフォームが表示され(図 (3)),ユーザがタイトルを入力し,決定することでメモノードが作成される(図 (4)).作成されたメモノードをダブルクリックすると,内容を編集でき,必要に応じて映像シーンや論文部分ノードの追加・削除を行うことができる.
データベースには,メモのテキスト,関連付けられた部分要素のURIの集合,それぞれの部分要素を包含するコンテンツのURIが全システム共通のアノテーション作成者のIDと関連付けられて保存される.引用アノテーションシステムは個人の研究活動を支援するためのシステムであるため,作成されるメモは個人的な内容を含む可能性があり,メモのテキスト内容は共有するのに適さない.そのため,メモに引用されたノード間の関係情報のみを他のユーザと共有する.
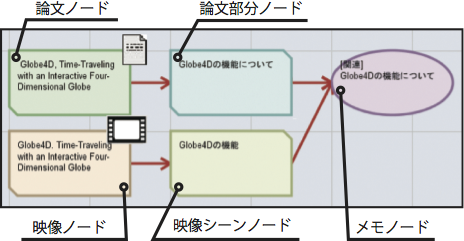
図4: 引用アノテーションシステムにおけるノードの種類
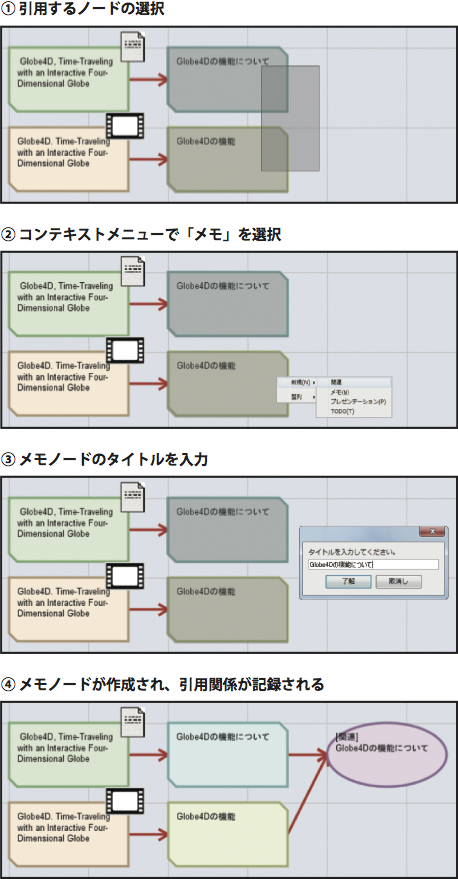
図5: 引用アノテーションシステムにおける関連付け手順
3 映像を用いた論文読解支援システム Docvie
これまでに説明した仕組みを利用して取得した,映像の部分要素,論文の部分要素,そして部分要素間の関係情報を利用して論文の効率的な読解を支援するシステム,Docvieについて述べる.
3.1 Docvieのコンセプト
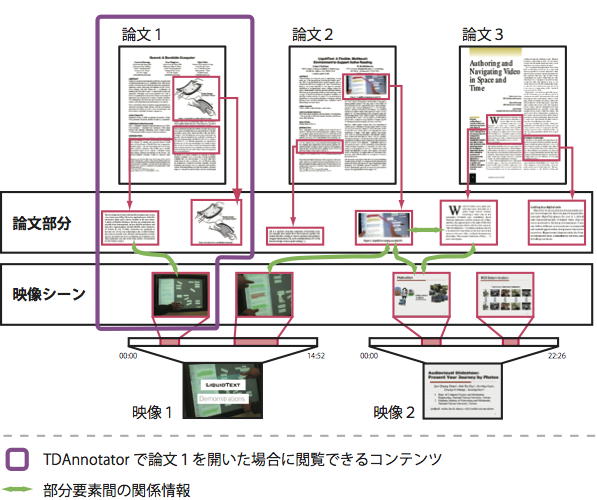
図6: 論文と映像の部分要素間の関係の模式図
論文の読解を支援するためには,その論文に関係するコンテンツを効率的に閲覧できるようにする必要がある.Docvieでは,図に示すどのコンテンツから閲覧を開始しても,部分要素間の関係を辿ることで,すべてのコンテンツを閲覧することができる仕組みを実現した.
Docvieでは論文だけでなく,論文・映像をユーザが注目しているコンテンツの種類に応じてインタフェースを切り替えて閲覧できる.論文に注目している場合には,論文の読解中に関係情報を利用して,論文部分に関連した映像シーンなどを視聴しながら閲覧できる.また,映像に注目している場合には,映像の視聴中にシーンに関連する論文部分などを参照しながら閲覧できる.それぞれのコンテンツの種類に応じたインタフェースを切り替えて閲覧することで,そのコンテンツに対する理解を深めることができると考えられる.
この2種類の閲覧インタフェースを,論文を主として閲覧する論文中心モード,映像を主として閲覧する映像中心モードと呼ぶ.
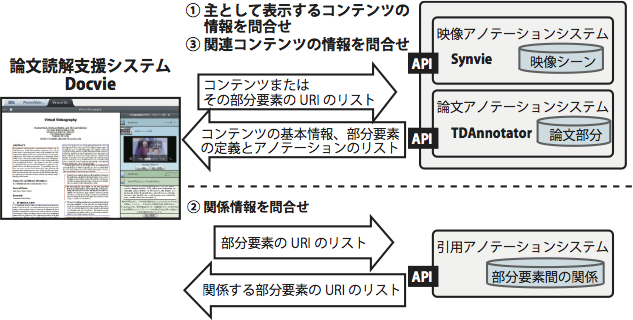
図7: Docvieにおけるデータ取得の流れ
Docvieにおけるデータ取得の流れを図に示す.まず,ユーザがコンテンツを読み込むと,Docvieはコンテンツの種類(論文,映像)に応じてTDAnnotator,Synvieが提供するAPIに,そのコンテンツのURIをキーにコンテンツの情報を問い合わせる(図 (1)).APIはそのコンテンツの基本的な情報(論文の場合は,画像の情報やタイトル,著者など.映像の場合は映像ストリームのURIやタイトル,作者など)とともに,コンテンツの部分要素の情報(論文の場合は,矩形範囲が定義された論文のページ番号と位置・サイズの集合,映像の場合はシーンの開始・終了時間)と,その部分要素に付与されたアノテーション(アノテーション本文,アノテーション作成者のIDなど)のリストを返す.次にDocvieは,取得した部分要素のURIのリストをキーに,引用アノテーションシステムに関係情報を問い合わせる(図 (2)).引用アノテーションシステムは,与えられた部分要素に関連付けされた部分要素のURIのリストを返す.Docvieは,受け取った部分要素のURIのリストをコンテンツの種類ごとに分けて,TDAnnotatorおよびSynvieにそれぞれ問い合わせる(図 (3)).それぞれのシステムは部分要素とそれを含むコンテンツの情報を返す.Docvieは,このようにして取得したデータを用いて,ユーザが閲覧しようとしているコンテンツに応じてユーザインタフェースを変更する.
以降,それぞれのインタフェースについて詳述する.
3.2 論文中心モード
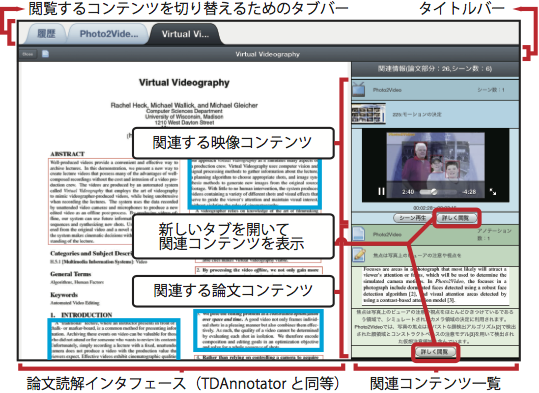
図8: Docvieの論文中心モードの画面例
論文中心モードの画面を図に示す.画面の上部には,現在開いている論文を含むコンテンツがタブとして配置されている.論文中心モードで表示しているコンテンツだけでなく,後述する映像中心モードで開かれているコンテンツもタブとして表示され,タブを切り替えながら閲覧できる.タブバー直下のタイトルバーには,現在開いている閲覧画面を閉じるためのボタン,閲覧モードを表わすアイコン,コンテンツのタイトルが表示される.そして,画面の左側にTDAnnotatorと同等の論文閲覧インタフェースが,右側に論文に関連するコンテンツの一覧が表示される.この画面では,主として閲覧する論文を,関連コンテンツを参照しながら読解することで理解を深めることを支援する.
論文上には,TDAnnotatorでアノテーションが付与された論文の部分要素を矩形で表現している.TDAnnotator上での表示と同じく,アノテーションが付与された論文部分は赤い枠線の矩形(論文読解インタフェース上の細線の矩形)で,映像シーンが関連付けられている論文部分は青い枠線の矩形(同,太線の矩形)で表示される.これらの部分は,ユーザによって情報が付与されている部分であり,付与されている情報を読解の手がかりとして参照することで,論文に対する理解を深めることができると考えられる.論文上の矩形を選択すると,関連コンテンツ一覧の中にある,選択した論文部分に関連するコンテンツにフォーカスし展開表示される.
関連コンテンツ一覧には,閲覧している論文に関連するコンテンツが,コンテンツの種類を把握しやすいように種類ごとに色分けされて表示される.映像が青色(関連コンテンツ一覧の上側)で,論文は緑色(同,下側)である.
関連コンテンツ一覧に表示される関連する論文の情報は,初期状態では,それぞれの論文のタイトルが表示される.タイトルを選択すると,その論文の部分要素に付与されたアノテーションの書き出しが一覧表示される.さらに部分要素を選択すると,その部分要素の内容とそこに付与されたアノテーションが表示される.またそれぞれに「詳しく閲覧」ボタンが設置されており,このボタンを押すと部分要素を含む論文が新たなタブとして追加される.
また,関連する映像の情報は,初期状態では,それぞれの映像のタイトルが表示される.タイトルを選択すると,その映像に含まれるシーンのタイトルとサムネイルが一覧表示される.一覧の中から映像シーンを選択すると,その映像シーンのタイトルとシーンを再生するためのプレイヤーが表示される.プレイヤー下部の「シーン再生」ボタンを押すことで映像をシーンから再生することができる.論文の部分要素と同じく「詳しく閲覧」ボタンが設置されており,このボタンを押すことで,そのシーンを含む映像全体を閲覧する画面が新たなタブとして追加される.
このように,関連コンテンツ一覧を段階的に展開できるようにすることで,論文に多くの情報が関連付けられた時に,関連コンテンツを俯瞰し,どの情報を閲覧するかが選択しやすくなると考えられる.論文閲覧時に論文に関連付けられた情報を効率よく閲覧できるようにすることで,関連する情報を探す負担を軽減し,論文読解の効率を向上させることができる.
3.3 映像中心モード
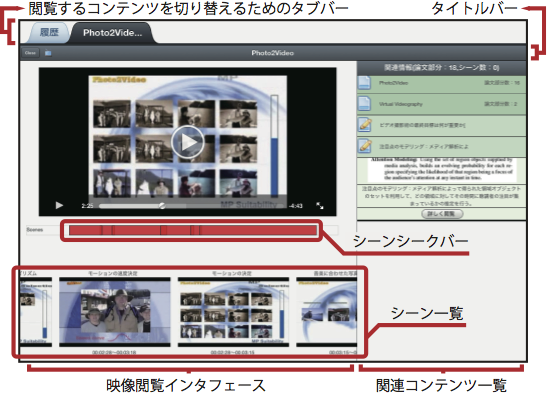
図9: Docvieの映像中心モードの画面例
映像中心モードの画面を図に示す.画面左側に映像閲覧インタフェースが表示されるほかは,論文中心モードと同様である.画面右側の関連コンテンツ一覧には,映像に関連した情報が一覧表示される.この画面では,主として閲覧する映像を,関連コンテンツを参照しながら視聴することで理解を深めることを支援している.
映像閲覧インタフェースは,映像のプレイヤー,その直下のシーンシークバー,最下部の映像に含まれるシーン一覧で構成される.シーンシークバー上には映像の再生時間が表示される.また,映像のどの部分がシーンとして定義されているかをシーンシークバー上に表現することで,映像のどの部分がシーンとして定義されているかを俯瞰することができ,ユーザが映像全体の中から映像シーンを選択する手掛かりとなる.
シーンシークバーの下部には,映像に含まれているシーンのリストが表示される.リストには,Synvieで映像シーンを作成する際に付与したシーンタイトルとシーンの代表サムネイル,シーンの開始・終了時間が表示される.サムネイルを選択することで,対応するシーンがプレイヤーで再生される.また,サムネイル画像を表示することで,ユーザは,映像を再生する前にシーンの情報を閲覧することができるため,映像へのアクセスを効率的に行うことができると考えられる.ユーザは,シーンシークバーとシーン一覧を用いることで,映像にどのようなシーンが含まれているかを俯瞰することができる.
論文中心モードでは,論文上に表示された矩形を選択することで関連する情報が自動的に展開されるが,映像中心モードでは,映像の再生時間に応じて,その時間を含むシーンに関連するコンテンツが展開される.映像の再生に同期して関連コンテンツを自動的に提示することで,ユーザは視聴中のシーンについての理解を深めることができると考えられる.
4 評価実験
Docvieが提供するインタフェースの有効性を確かめるために,比較対象としてTDAnnotatorで映像を閲覧できるようにした.図に示すように,節の方法で映像シーンが関連付けられた論文部分は青色の枠線(図中では,論文左上の太線の矩形)で表示される.通常の論文部分と同様に,この部分をクリックしてアノテーションを開くと,映像シーンと論文部分の情報が表示される.この提示方法は単純なもので,提示された映像シーンに対して別の論文の部分要素が関連付いていたり,その映像シーンを含む映像の他の映像シーンに,別の論文部分が関連づいていたりしても,それをユーザが知ることはできない.
例えば,図に示すように,ユーザが論文1を閲覧しているときに,論文1の部分要素に関連付けられた映像1の部分要素を閲覧することはできるが,同じく映像1に関連付けられている論文2を,映像1との関係を辿って閲覧することはできない.Docvieでは提示された関連コンテンツを辿って他の映像や論文を閲覧することができ,ユーザが注目するコンテンツの種類に応じた適切なインタフェースを提供している.
本実験では,TDAnnotatorとDocvie,動画と映像の閲覧に利用される一般的なツール(本実験では,GoodReader(http://www.goodiware.com/goodreader.html)と呼ばれるPDFとMPEG-4形式の動画を別々に閲覧できるソフトウェアを用いた)の三つのソフトウェアを被験者実験を通して比較することで,Docvieで実現した機能が有効に働いているかどうかを,読解効率(回答時間および正答率)の観点から検証した.
4.1 実験の内容
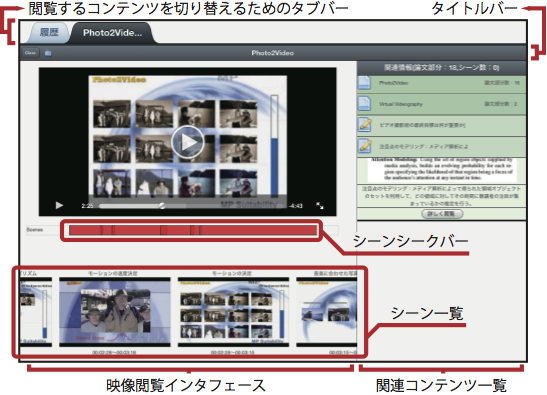
図10: 実験に用いた大問の例
本実験は,被験者に論文と映像を閲覧してもらい,その内容に関する問題を解いてもらう形式である.論文と映像の閲覧にはタブレット型デバイスを用い,GoodReader,TDAnnotator,Docvieのいずれかのソフトウェアを用いた.
図に被験者に提示した実際の問題を示す.小問3問を含む大問3問でひとつの問題セットとした.小問は回答に際して,被験者に提示される複数の論文と映像の内容に対して「正しい・間違い」で答えることができ,提示された論文の中に答えの根拠となるパラグラフが必ず含まれるように作成した.また,アノテーションが付与されている部分だけを読めば答えられる問題とならないように,根拠となるパラグラフがTDAnnotatorとDocvieで表示される,アノテーションが付与されていることを表す矩形の文章中には含まれないようにした.
また,被験者に提示する論文と映像は内容的に関係するもので,大問ごとに異なる論文と映像を用いた.論文は情報科学系のHuman-Computer Interfaceに関係する英語論文で,大問ごとに2本以上で合計のページ数がA4サイズで10ページとなるように選択した.映像は論文に書かれている内容に関するデモ映像や発表映像で,大問ごとに複数の映像を提示する.映像の長さは平均5分35秒(3分35秒?9分21秒)であった.また,論文と同じく映像の言語も英語である(ただし,問題文は日本語).
被験者は,実際に当該分野の論文を読解する必要がある情報科学系の大学4年生5名,修士課程3名の計9名で,TOEICスコアの平均は585.5(465-715)であった.また,実験で使用するタブレット型デバイスは被験者全員が日常的に利用しており操作に慣れている.9名をTOEICスコアと学年を参考に1グループ3名の3グループに分けた.
4.2 実験の手順
実験はグループごとに,表に示す順番と問題セットで行った.それぞれのソフトウェアを用いた実験の前に,実験に利用しない問題セットを用い,5分間,ソフトウェアの使い方をレクチャーした.
その後,事前知識をできるだけ均一化することと,動画の閲覧中に問題に回答することを防ぐ目的で,出題した問題に関係する映像シーン(平均46秒,31秒?1分28秒)を最初から最後まで閲覧してもらった.
次に,大問1問について10分の制限時間を設定し,それぞれのソフトウェアを用いて問題に回答してもらった.これは,被験者に可能な限り迅速に問題に回答する事を促すためである.また,小問への回答は「正しい・間違い」の答えと同時に,その回答の根拠となるパラグラフを示してもらった.
三つの手法それぞれに,上述の方法で問題セット,大問3問を解いてもらい,その回答とかかった時間を記録した.
4.3 実験結果と考察
1, F検定による有為確率(***p<0.001, n.s. 5%水準で有為でない)2, GoodReader, TDAnnotator, Docvie 3, グループ1?3 4, 問題セット1?3
1, Tukeyの方法による有為確率 (*p<0.05, **p<0.01 ***p<0.001)
上述した条件の下で行った実験の結果について述べる.本実験では,Docvieの有効性を読解効率の観点から評価するために,大問の回答にかかった平均時間と,問題セットごとの正答率を算出した.
それぞれの結果を示す前に,3手法の間で大問の回答時間と正答率の平均値に差があるかどうかを分散分析で確認した結果を表に示す.結果から,大問の回答にかかった平均時間と正答率の両方で手法間に有為差(p<0.001)が認められた.そこで,Tukeyの方法を用いて多重検定を行った.その結果を表に示す.以降,この分析結果に触れながら結果について考察する.なお,分散分析,多重検定にはR 2.15.0(http://www.R-project.org)を用いた.
図および表に,大問の回答にかかった平均時間を示す.大問の回答にかかった時間は,映像または映像シーンを閲覧し終わって大問への回答開始の合図とともに計測した.結果を見ると,GoodReaderを用いた場合に比べて,TDAnnotatorでは75.6秒,Docvieでは171.3秒早く回答することができている.表に示した多重検定の結果から,各手法間に有為差が認められた.なお,10分の制限時間内に大問に答えられなかった場合には,600秒として計算している.制限時間内に答えられなかった大問の割合を表に示す.GoodReaderを用いた場合,制限時間内に大問に回答できなかった割合が5割を超えている.
このような結果が現れたのは,GoodReaderでは論文部分がハイライトされていないため,何も手がかりのない状態でどこが重要な部分かがわからず,論文を最初から読んだためだと考えられる.また,TDAnnotatorとDocvieで差が出たのは,Docvieではどの部分が重要かというだけでなく,常に関連コンテンツが表示されている状態で閲覧できるようになっていたため,複数の論文を行き来しながら答えを探すことができ,答えに到達するまでの時間が短くなったと考えられる.
また,表よりグループ間に有為傾向(p=0.097)が見られた.この傾向は,グループ1がDocvieを用いて問題セット3に取り組んだとき,制限時間内に回答できなかった問題がなかったためだと考えられる.表では問題セット間の大問の回答にかかった平均時間の有為差は見られなかった(p=0.285)が,問題セット3が他の問題に比べて容易であった可能性がある.問題セットの難易度,個人の能力差についてより詳細に分析するためには,実験の規模を拡大する必要があると考えられる.
図および表に,問題セットごとの正答率を示す.正答率は,ある問題セットに対する被験者の正答数を問題セットに含まれる小問題の数で割ったものである.ここで,正答としたのは,制限時間内に回答が行われ,問題に対する答えが合っていて,かつ被験者が示した回答の根拠となるパラグラフ中に適切な記述が含まれている場合とした.これは,誤読している場合や勘で答えている場合を不正解とするためである.
正答率も,Docvieを用いた場合が最も高く,続いてTDAnnotator,最後にGoodReaderの順であった.表から3手法の正解率の平均値に5%水準で有為差が認められた.GoodReaderを用いた場合の正答率が5割程度と低いのは,制限時間を超えてしまうことが多かったこと,手がかりが少ないために根拠となるパラグラフを探すことが難しかったことが挙げられる.TDAnnotatorとDocvieの間で差がみられたのは,Docvieでは関連コンテンツにアクセスしやすく,映像中心モードで論文に比べて把握しやすい映像を閲覧し,それを手がかりに関連する論文部分を読むことができたためだと考えられる.
以上の結果から,関連するコンテンツを利用して論文読解を支援するシステムとして,DocvieはTDAnnotatorと比較して,効率的に内容を把握できると考えられる.
5 まとめと今後の課題
本研究では,論文と映像の部分要素に対するアノテーションの獲得と蓄積を行うための仕組み,部分要素間の関係情報を取得するための仕組みを,先行研究を拡張することで準備した.そして,獲得したメタ情報を利用するシステムの一例として,論文読解支援システムを提案した.提案システムは,メタ情報を用いてユーザが閲覧中のコンテンツに関連する他のコンテンツの一部を提示し,その理解を促進する仕組みを実現した.さらに,評価実験を行って,提案システムを用いることで効率的にコンテンツの内容を把握できることを確認した.
論文読解支援をさらに充実したものにするためには,ユーザが論文の内容をどの程度まで理解したかを量る指標の提案や,論文の内容を適切に理解するためのアノテーションを偏りなく獲得する仕組みを実現する必要がある.
そのために,我々は,論文閲覧システムや映像閲覧システムだけでなく,論文執筆支援システムに部分要素の作成や部分要素間の関連付けを獲得する仕組みを埋め込むことで,論文に対する有用なメタ情報を獲得,蓄積できる仕組みを実現することにも取り組んでいく予定である.