
ボードコンテンツの構造化と再利用に基づく継続的ミーティング支援システムに関する研究
概要
近年,社会は企業・団体などの組織において,知識が高い価値をもつ知識社会へと変化しつつあり,組織に所属するナレッジワーカーの諸活動の中から,いかに知識を抽出するかということが注目されている.現在のナレッジマネジメントシステムが対象とするのは,報告書や提案書などの成果物,メールシステムや掲示板システムでのユーザーのアクティビティといった,コンピュータで扱うことが容易なデジタル情報に限られている.しかしながら,ナレッジワーカーの諸活動には,コンピュータを通じて得られるものだけではなく,他の人間と顔をあわせ,時間と空間を共有しながら行う,実世界における多様な活動が含まれる.
そこで,著者は,実世界における諸活動の中でもミーティングに注目する.企業や研究室などの組織では,多様なミーティングが行われている.新商品を提案するプレゼンテーション,物事を決定し遂行するための教授会や取締役会議,アイディアを煮詰めるためのブレインストーミング,日常の研究や仕事の中で生じた疑問や問題点を解決するためのミーティングなど,目的に応じて参加人数や設備,準備期間などは様々である.
なかでも,プロジェクトあるいはチームなどの共通の目標を持つ複数のメンバーが集まって,継続的かつ頻繁に行われる小規模のミーティング(以降,継続的ミーティングと呼ぶ)は,目標に向かって仕事や研究を円滑に進めていくために重要な役割を担っている.このようなミーティングの議題は,問題や疑問,企画などのアイディア出し,タスクの進捗管理など多岐に渡る.ミーティングを行うことによって,各個人が抱えている問題を解決したり,他者からの意見を参考に新しい知見を得たりすることができる.そして,話し合われた内容に基づいて各個人が自らの仕事や研究を遂行していく.
継続的ミーティングはナレッジワーカーが日常的に行うものであり,報告書や設計書,プログラムやデザインといった成果物が生み出される背景となるアイディアや知識がやり取りされている.このことから,継続的ミーティングにおける話し合いの内容を適切に記録・蓄積し,ナレッジワーカーが必要に応じて閲覧したり検索したりできる環境を構築することで,よりよい知識活動を実現できると考えられる.
また,一般にミーティングを円滑に進行するためには,ミーティングの参加者間で事前に持っている情報のずれが少ないことが条件として挙げられる.そのため参加者には,ミーティング前に適切な資料を作成することが求められるが,作成にかかる労力は小さくない.そこで,ナレッジワーカーが日頃の知識活動の中で作成したコンテンツ,メモ書きや画像,スケッチなどを資料として利用できるようにすることで,資料作成にかかる労力を低減できると考えられる.
以上のことから,本研究では,一般的な少人数で行われるミーティングで利用されるホワイトボード,フリップチャート,黒板,大型のコルクボードなどの道具(以下,ボードと総称する)を情報的に拡張し,話し合いの内容を記録するミーティング支援システムを実現した.また,個人の知識活動の中で生み出され利用されるコンテンツを記録するためのミーティングクラウドを実現する.
具体的には,TimeMachineBoardと呼ばれるミーティング内容を記録するための仕組みと,iStickyと呼ばれる個人の活動に関わるコンテンツを集約しTimeMachineBoardに情報を入力するためのクライアントソフトウェアを実現した.TimeMachineBoardは,大型ディスプレイをボードとして用いる.また,iStickyはタブレット型デバイスで動作する.TimeMachineBoardとiStickyは,互いに協調的に動作してミーティングを支援する.iStickyを用いて作成されたコンテンツ,およびTimeMachineBoardを用いて行われたミーティングの内容は,すべてミーティングクラウドに記録される.
ミーティングクラウドに蓄積された過去のミーティング内容や個人の知識活動の中で作成したコンテンツは,必要に応じて取り出してiStickyに保存し,持ち歩くことができる.また,ミーティングクラウドに保存された情報,あるいはその一部をボードに提示して話し合ったり,他のコンテンツに埋め込んで新たなコンテンツを作成したりすることができる.
TimeMachineBoardは,ボードコンテンツ(ボードに提示された内容の記録)の構造やボードコンテンツ同士の関係の情報を,ミーティング参加者の行動に伴って自動的に記録する.具体的には,参加者が内容を分かりやすく整理するために,ボード要素をツリー状に配置することで,コンテンツの内部構造が自動的に得られる.また,議論の重複を防ぐために,過去のボードコンテンツの一部を進行中のミーティングで提示することによって,ボードコンテンツ間の関係情報が自動的に得られる.これらの情報は,これまでは労力をかけて作成しなければならなかったが,本システムでは,ミーティングを円滑にするための機能を参加者が活用することで,ボードコンテンツの検索や要約に必要な情報を自動的に獲得することができる.
本システムを2008年9月から継続的に運用し,ミーティング内容を記録・蓄積してきた.記録・蓄積されるミーティングの量がある程度以上に増加すると,ボード内容のスナップショットを一覧表示にしたり,単純な検索を実現するだけでは,目的とするボードコンテンツを検索したり,継続的なミーティングの内容を把握することが難しくなる.記録・蓄積されたボードコンテンツをより有効に活用するためには,ミーティング参加者がミーティング中の限られた時間の中で効率的に過去のコンテンツを把握できるようにする仕組みが必要になる.
そこで,複数のボードコンテンツの中から重要な要素を発見するために,ボードコンテンツに関わる多様な情報を用いてロジスティック回帰分析を適用し,70%程度の精度をもつ重要要素の発見手法を実現した.また,ロジスティック回帰分析の結果,木構造の付与や引用によって獲得できるグラフ情報が重要要素の発見に有効であることが確認できた.
ミーティングの記録・構造化に関する研究は数多く行われているが,ミーティング間の関係を適切に考慮しているものは少ない.一般に行われている小規模のミーティングは散発的に行われるものではなく,継続的に行われることが多い.過去のミーティング内容をより柔軟に利用することができれば,それまでの経緯を踏まえた議論を促進し,個人の,ひいては組織全体の知識活動を活性化することができると考えられる.
1 序論
1.1 背景
1960年代半ば,Bellが産業革命以後続いてきた工業社会の終焉とその未来を予見し,情報を取り扱う諸活動が社会の中心となる,脱工業社会の可能性を唱えた.以来40年の間に社会は,Bellの予見通り情報革命を迎え,本格的な情報社会へと移り変わってきた.そして,社会はTofflerやDruckerがその訪れを予見したように,知識が高い価値を持つ知識社会へと変貌を遂げようとしている.
知識が企業・団体における,最も重要な財産あるいは活動の資源として捉えられる知識社会において,現場で直接知識を取り扱うナレッジワーカーの諸活動の中から,いかにして知識を抽出・蓄積していくかということが注目されている.野中らは,組織がナレッジワーカーの創り出す知識を抽出・蓄積・増幅していくための実践的な仕組みとしてナレッジマネジメントの重要性を提唱している.そして,組織に属するナレッジワーカーそれぞれが経験的に蓄積している,形式的言語では表現することができない主観的な知識である暗黙知を,形式的言語で表現することが可能で客観的な知識である形式知へと,変換するプロセスとしてSECIモデルを定義している.
SECIモデルでは,この変換プロセスを4つのフェーズに分解する.共同体験などによって暗黙知を獲得・伝達する共同化(Socialization),得られた暗黙知を共有できるように形式知に変換する表出化(Externalization),形式知同士を組み合わせて新たな形式知を創造する連結化(Combination),利用可能となった形式知を基に個人が実践を行い,その知識を体得する内面化(Internalization)である.そして,それぞれのフェーズが「ナレッジワーカー同士の暗黙知を共有するための場」を通じて,個人・グループ・組織の相互作用の中で,ダイナミックに循環することによって個人,および組織の知識が量的にも質的にも増幅される.
ナレッジマネジメントを情報処理技術で支援する取り組みは,データマイニングやデータウェアハウス,グループウェアなどが挙げられる.なかでも一般的なグループウェアは,CSCW (Computer Supported Cooperative Work)と呼ばれるコンピュータによる協同作業支援に関する学術分野に基づくシステムの総称であり,具体的なものとしてはサイボウズ(サイボウズ:サイボウズ製品サイト|cybozu.com http://www.cybozu.com/(2012年10月2日))やLotus Notes(Lotus Notes:IBM Lotus Software - Japan:http://www-01.ibm.com/software/jp/lotus/(2012年10月2日))などが挙げられる.これらのシステムには,組織内部や外部とのコミュニケーションを円滑に行うためのWebメール機能,メンバーとスケジュールを共有するスケジューラ機能,メンバー間の打ち合わせや議論を行うための掲示板機能など,組織内の知識創出を支援する様々な機能が存在する.グループウェアの有用性は広く認知されており,中小企業の約47%がグループウェアを導入しているという調査結果も報告されている(ノークリサーチ:2011年中堅・中小企業における「グループウェア」の利用実態とユーザ評価に関する調査報告 http://www.norkresearch.co.jp/pdf/2011itapp_gw_rel.pdf(2012年10月2日)).
しかし,現在利用されているグループウェアの多くが「うまく情報が集まらない」「情報を蓄積しても有効に活用できない」といった同様の問題を抱えている.そしてそれは,知識を創出する主体であるナレッジワーカーが知識を組織に還元するインセンティブをどのように与えるか,モチベーションをどのように維持していくか,という運用的な課題であると同時に,ナレッジワーカーに負担をかけず自然に情報を抽出できるシステムをいかに構築するか,という技術的課題でもある.この問題に対してDavenportらは,ナレッジワーカーが業務プロセスの中で自然に知識を取り扱えるように,業務で利用する情報システムに知識を提供あるいは利用するための仕組みを埋め込んでいくことが重要であると指摘している.また,小林は,これまでのナレッジマネジメントシステムで蓄積される情報は設計書や提案書など業務に関する成果物だけであり,「どのようにしてその成果物が作成されたのか」という成果物に至るまでの背景情報が蓄積されていないために,組織内で培われた知識がメンバー間で効率的に継承されない点を指摘している.
上述のようなグループウェアにおける情報の蓄積・利用の問題にアプローチしたシステムとして,近年,ナレッジワーカーに直接,報告書や提案書など,なんらかの成果物を登録させる形態ではなく,ナレッジワーカーのアクティビティを記録しマイニングする形態のナレッジマネジメントシステムが注目されている.このようなシステムは,より個人の活動に近いメールや社内掲示板・ブログなどのシステムを利用したコミュニケーションから知識を抽出しようという試みである.具体的な製品として,Knowledge Market(リアルコム株式会社:ナレッジマネジメントツール「KnowledgeMarket EnterpriseSuite」.http://www.realcom.co.jp/it/knowledgemarket.html(2010年12月11日))などがあり,ナレッジワーカーの活動を中心に据え,ナレッジマネジメントを業務プロセスに埋め込むことで,知識を効率的に抽出し,利用できるようにすることに注力したシステムを実現しようとしている.
これらのシステムが対象とするのは,コンピュータで扱うことが簡単なメールや掲示板・ブログなどの情報が中心である.それはすなわち,すでにナレッジワーカーによって形式言語で表現された情報である.しかし,組織におけるナレッジワーカーのアクティビティには,現在コンピュータを通じて収集できるものだけでなく,多様な実世界インタラクションが含まれる.角らは,インターネットと実世界を対比して,インターネットは言語に大きく依存した情報がやり取りされているが,実世界の社会生活における対面コミュニケーションは言語情報だけでなく,身振り手振り,視線,立ち居地や姿勢,表情といった多くの非言語的な情報に支えられていると述べている.このような,人間同士が実際に対面して様々な状況を共有しながら行われる,言語的情報だけでなく非言語的情報を含む実世界インタラクションでは,より多くの暗黙知がやり取りされている.しかしながら,多くの実世界インタラクションは,記録が難しいために形式化されず,ナレッジマネジメントシステムに取り込むことができていない.
これらのことから,本研究では会議に着目する.会議は,企業・研究室などの組織において,所属するナレッジワーカー同士が互いに意見交換を行うことによって個人の暗黙知を獲得・伝達する共同化にあたる作業である.会議には様々な形態があり,例えば,学会の研究発表のように多人数の参加者が一堂に会して行われる発表形式のフォーマルな会議や,商品のアイディアを出し合うようなブレインストーミング,些細な話題についてに話し合うような限られた人数で行われる簡単なミーティングなどが挙げられるであろう.多人数が集まって行われるような会議において会議を円滑に進行させるためには,十分な事前準備が必要であるとされる.著者の所属する研究室では,以前からディスカッションマイニングと呼ばれる研究室のゼミを対象とした会議支援システムを提案している.ディスカッションマイニングが対象としているのは,事前準備を必要とするフォーマルな会議である.このような会議だけでなく,より日常的に行われているミーティングの中から知識を抽出し蓄積していくことも必要である.
そこで,本研究ではプロジェクトあるいはチームなどの共通の目標を持つ複数のメンバーが集まって,継続的かつ頻繁に行われる小規模のミーティング(以降,と呼ぶ)に注目する.継続的ミーティングは,目標に向かって仕事や研究を円滑に進めていくために重要な役割を担っている.このようなミーティングの議題は,問題や疑問,企画などのアイディア出し,タスクの進捗管理など多岐に渡る.ミーティングを行うことによって,各個人が抱えている問題を解決したり,他者からの意見を参考に新しい知見を得たりすることができる.そして,話し合われた内容に基づいて各個人が自らの仕事や研究を遂行していく.
継続的ミーティングはナレッジワーカーが現場で日常的に行うものであるから,そこには従来のグループウェアなどのナレッジマネジメントシステムが知識抽出の対象とするような報告書や設計書,フォーマルな会議の議事録,プログラムやデザインといった成果物になる以前の背景となるアイディアや知識が含まれている.さらに,最近のグループウェアが新たに解析の対象に加えている,メールや掲示板での非同期型コミュニケーションでは得られない,対面同期型コミュニケーションならではの,より自然で豊富な情報がやり取りされている.これらのことから,継続的ミーティングを記録し,構造化し,コンテンツ化することで,これまでのナレッジマネジメントシステムでは抽出できないより詳細なKnow Whoや,形式化された知識同士の関連などを抽出できると考えられる.
そして,このような知識活動の中で重要な役割を担っている,継続的ミーティングを円滑化し,効率的に行えるようにすることで,よりよい知識活動を実現することができると考えられる.
本研究で取り組む継続的ミーティングにおける問題点は以下の3点である.
1.2 情報的に拡張したボード
継続的ミーティングの問題点として,という点を挙げた.ミーティング内容が適切に記録されて,いつでも取り出せるような状態でミーティング参加者の手元になければ,という問題点も解決に至らない.
ミーティングを記録しコンピュータで取り扱えるようにするための研究は古くから行われている.一つは,映像および音声情報を解析し,参加者の挙動や音声の変化を抽出したものを利用する方法である.これらの研究では,ミーティングの様子を撮影した映像と音声を解析し,ミーティング参加者の挙動や音量の変化をイベントとして抽出することで,動画を閲覧する際の手がかりとして利用している.また,ミーティングの議事録を音声認識により作成し,インデックス化を行う研究がある.この研究はミーティングを対象とし,音声認識によって議事録の書き起こしを行っている.しかし,これらの手法では,パターン認識の精度に限界があるため正確な情報が得られず,現在のところあまり実用的ではない.さらに,参加者の挙動や音声の変化が必ずしも議論内容に合致したものではないため,議論構造や会話の文脈などの意味を考慮した解析を行うことが困難である.
一方で,一般的な少人数で行われるミーティングでは,ホワイトボード,フリップチャート,黒板,大型のコルクボードなどの道具(以下,と総称する)がミーティングで話し合われている内容を可視化するために利用される.ボードを用いることで,ミーティング参加者がお互いに考えていること,ミーティングで話し合われたことについての共通認識を形成することができる.
ボードが用いられるミーティングを支援する情報環境に関する研究の代表格として,Xerox PARCのUbiquitous Computingが挙げられる.Ubiquitous Computingそのものは,実環境中にあまねくコンピュータが存在することを指す概念であり,Liveboardと呼ばれる大型のリアプロジェクションディスプレイを用いて実現された電子ボードと,PARCPADと呼ばれるタブレット型デバイス,PARCTABと呼ばれる個人用の携帯型デバイスを実現し,それぞれが協調的に動作する仕組みを提唱している.
Ubiquitous Computingにおけるミーティングでは,Liveboardをボードとして用い,電子ペンでフリーハンドの絵を書き込んだり,画像や図形などのオブジェクトを作成したり,それらを移動したりしながら話し合いを行う.PARCPADには,Liveboardに表示されている内容を表示することができ,スタイラスを用いてストロークを書き込み,Liveboardに反映できる.さらに,PARCTABはLiveboardに表示されている内容を指示するためのポインタとして利用される.
そこで著者は,Xerox PARCが提唱したLiveboardとPARCPAD,PARCTABの組み合わせによるミーティング支援システムを参考に,大型の液晶ディスプレイやタブレット型デバイスなど現在の技術を利用した新たな継続的ミーティング支援システムを実現する.具体的には,継続的ミーティングで用いられるボードとして大型ディスプレイを用いる.そして,参加者がそれぞれ,大型ディスプレイに,タブレット型デバイスを用いて話し合いたい事を提示しながらミーティングを行える.
本研究では,ミーティングに用いられたボードの内容をと呼び,ボードコンテンツの要素(参加者が提示する内容)をと呼ぶ.本システムでは,ボードコンテンツの構造やボードコンテンツ同士の関係の情報をミーティング参加者の行動に伴って自動的に記録する.例えば,参加者が内容を分かりやすく整理するために,ボード要素をツリー状に配置することで,コンテンツの内部構造が自動的に得られる.これによって本節冒頭に述べた,ミーティング内容の適切な記録が難しい,という問題点にアプローチする.
また,過去のミーティング内容が活かされない,という問題を解決し,議論の重複を防ぐために,過去のボード要素を進行中のミーティングに提示できるようにした(この行為をと呼ぶ).さらに,引用することで,ボードコンテンツ間の関係情報が自動的に得られる.これらの情報は,これまでは労力をかけて作成しなければならなかったが,本システムでは,ミーティングを進行するための機能を参加者が活用することで,ボードコンテンツの検索や要約に必要な情報を自動的に獲得することができる.
1.3 本研究の目的
本研究の目的は,上述した継続的ミーティングの問題点を解決するための継続的ミーティング支援環境を構築することにある.個人の知識活動の経過や成果を記録・蓄積し,それらを利用して行われる継続的ミーティングを適切に記録する.そして継続的ミーティングの記録を,振り返って閲覧したり,進行中のミーティングで検索して必要な部分を共有できるようにする.また,継続的ミーティングは,個人および組織の知識活動において継続的に行われるものであるから,支援環境・システムも継続的に運用可能でなければならない.
本研究において,知識活動とは「あるテーマに対して継続的にアイディアを創造し,知識として理論化・具体化する活動」を指す.継続的ミーティングは,個人および組織の知識活動を円滑に進めるために行われるものであるから,継続的ミーティングを支援し,その効率を高め円滑に行えるようにすることによって,知識活動をよりよいものにすることができるであろう.
1.4 アプローチ
上述した目的の下,継続的ミーティングを支援する以上,構築した環境およびシステムは,長期的な運用を前提に設計されるべきである。実験などの短期的な運用を前提としたシステムではユーザーに我慢して利用してもらえるようなことが,長期的な運用を前提とすると,許されないことが多い。そこで,支援環境を構築,デザインするにあたって,全体に共通のコンセプトとして,「コンピュータを用いた検索や要約などの実現に必要な情報を獲得するために,人間に新たな負荷をかけないこと」を掲げている.
1.5 個人の知識活動を蓄積するクラウド
問題点のひとつに,という問題点を挙げた.ミーティングを円滑に進行させるためには,話し合いを行う前や,話し合っているその最中に提示できる資料を事前に用意しておくことが重要である.例えば,会議のアジェンダや図・表・グラフ・スケッチなどを用いて会議内容を説明する書類,これから行うタスクの一覧や論文,過去のミーティングの議事録などといった印刷資料や,パワーポイントや映像・画像などのデジタルコンテンツなどである.このようなコンテンツはボードと同じように,ミーティングを円滑に進行するために利用される.しかし,そのような資料をミーティングの度に作成することを要求されると,ミーティング参加者の負荷が高まってしまう.
そこで著者は,ミーティングの内容だけではなく,ナレッジワーカーが日常的に行っている知識活動で作成する,テキストメモや画像,映像,手描きのスケッチ,プレゼンテーション,論文などの知識活動の経過や成果を,コンテンツとしてクラウドサーバに記録し,その活動内容をナレッジワーカーがタブレット型デバイスや個人のPCなどから必要なときに取り出せる仕組みを実現する.
ナレッジワーカーはこの仕組みを用いて知識活動を行い,結果として記録されたコンテンツを,ミーティングで利用する.これによって,ミーティングに参加するために必要な資料を作成する手間を低減し,かつ他のミーティング参加者と情報を共有するために十分な情報を提示できるであろう.
1.6 本論文の構成
本論文の構成を以下に示す.
2章で,本論文で取り扱う知識活動について明確にし,知識活動における継続的ミーティングの役割を説明する.そして,継続的ミーティングの問題点について,詳細に述べ,継続的ミーティングを支援する環境に必要な要素について考察する.
3章では,ナレッジワーカーが日常的に行っている知識活動の中で記録されるコンテンツを,効率的に閲覧・検索するために,どのようなメタ情報を付与して記録するべきかについて述べる.さらに,コンテンツを効率的に閲覧できるインタフェースを実現し,比較実験を行う.そして,新たに作成した,知識活動から獲得したメタ情報を利用して実現したインタフェースを用いることで,効率的な閲覧ができることを示す.
4章では,2章,3章で述べた内容を踏まえて実現された継続的ミーティング支援システムについて詳述する.継続的ミーティング支援システムは,TimeMachineBoardと呼ばれるミーティング内容を記録するための仕組みと,iStickyと呼ばれる個人の活動に関わるコンテンツを集約しTimeMachineBoardに情報を入力するためのクライアントソフトウェアによって構成される.本システムは2007年から開発を開始し,2012年現在まで運用している.5年の運用の間に,システムの仕組みやユーザインタフェースが徐々に更新されている.運用によって廃止された機能についても,なぜ廃止されたのかという考察を加えて説明する.
5章では,ボードコンテンツの構造化手法について述べる.ボードコンテンツの構造情報は,システムが検索や要約などの高度利用を実現するために必要な情報である.同時に,ミーティング参加者が,進行中のミーティングにおける話し合いの内容を把握するために,ボードの内容を並べ替えたり移動させたりする自然な行為でもある.本研究では,ミーティング参加者が行うこの自然な行為から,高度利用に必要な構造情報を獲得する方法を実現した.構造化手法についても,過去に廃止されたグループ化機能と,現在利用されているツリー機能について述べる.
6章では,継続的ミーティング支援システムによって記録・蓄積されたボードコンテンツを,効率的に閲覧・検索するためのインタフェースについて述べる.また,過去のミーティング内容を活かした話し合いを実現するために,過去のボードコンテンツの一部を進行中のボードに提示する引用の仕組みと,引用によって得られる複数コンテンツ間の関連を利用した複数ミーティングの閲覧インタフェースについて述べる.
7章では,継続的ミーティング支援システムを長期間にわたって継続的に運用しつづけた結果,蓄積された多量のボードコンテンツから,重要な部分を発見するための手法について実験を交えて説明する.また,この手法を用いた,複数のミーティングコンテンツを効率的に閲覧できるインタフェースについても述べる.
さらに,8章では関連研究について述べ,9章で本論文をまとめ,今後の課題について述べる.
1.7 ミーティング内容の適切な記録が難しい
ミーティングの記録を録る一般的な方法として,書記を用意することが考えられる.しかし,専門の書記を用意することは,少人数で行われる継続的ミーティングでは困難である.また,参加者から書記を任命することも考えられるが,議事録を作成することと話し合うことを同時に行うのは,やはり困難である.
会議を映像や音声で記録する研究は多様に行われており,マルチメディア議事録を効率的に閲覧するための仕組みも研究されている.マルチメディア議事録は,他の記録方法に比べ豊富な情報量を持つが,しばしば映像や音声を伴うため閲覧にどうしても時間がかかってしまう.また,ボードを利用するミーティングで一番手軽な記録方法は,ボードを撮影して画像ファイルとして記録することであろう.しかしながら,話し合いの内容が網羅的に含まれるようにボードを利用しなければ,その画像を閲覧して内容を充分に想起するのは,時間が経過するに従って困難になる.
継続的ミーティングの記録方法としては,記録の手軽さと,その記録を閲覧したときに話し合いの内容を十分想起できる情報量が含まれているか,ということが重要であると考えられる.
1.8 過去のミーティング内容が活かされない
ミーティングを阻害する,ひとつの要因として,過去に話し合ったことを参加者が忘れていて,同じ内容について議論が起こってしまうことが挙げられる.過去のミーティング内容が適切に記録されていて,過去ミーティングにおいて行われた話し合いの経過と結果が,進行中の話し合いにおいて適切に提示されるならば,その内容に基づいて話し合いが深化・発展するであろう.
1.9 資料の準備に手間がかかる
一般に,ミーティングを円滑に進行させるためには,十分な事前準備が必要であるとされる.参加者が事前に適切な資料を作成せず,参加者間で情報の共有が適切に行われないと,議論が迷走して,本来話し合うべきことに辿り着くまでに時間がかかってしまう.しかしながら,そのような資料を作成するのは一般的に負荷が高い.頻繁に行われるミーティングの場合,ミーティングで話し合おうとすることの背景をすべて順を追って説明する必要はないが,話し合いのたたき台となるような資料は必要である.
2 知識活動における継続的ミーティングとその支援
本論文では,会議の中でもプロジェクトあるいはチームなどの共通の目標を持つ複数のメンバーが集まって,継続的かつ頻繁に行われる小規模のミーティング(以降,と呼ぶ)に着目し,継続的ミーティングの記録と再利用による知識の獲得,そして,よりよい継続的ミーティングを実現するための支援を目標としている.
本章ではまず,知識活動におけるミーティングの役割について述べ,ミーティングの種類を列挙して,著者が取り組んだ継続的ミーティングの立ち位置を明らかにする.また,継続的ミーティングで利用されるボードの役割と,ボードをどのように利用すれば,より円滑で効果的なミーティングを実現できるかについて述べる.最後に,ボードを用いたミーティングをどのように支援するべきかについて述べる.
2.1 ミーティング内容の適切な記録
話し合いの結果を適切に記録することが困難である,ということを問題点として挙げた.記録には話し合いの内容を想起できるだけの充分な情報が含まれていなければならない.しかし,継続的ミーティングにおいて記録を作成するために専門の書記を用意するのは困難である.また,参加者から書記を任命し,話し合いに参加しながら議事録を作成するのも大きな負担を強いることになる.映像や音声でミーティングを記録する場合には閲覧に時間がかかる.話し合いに利用されたボードを写真などで記録したものは手軽に議事録を作成でき閲覧も容易だが,ボードに話し合いの内容を適切に整理しておかないと,後で振り返ったときに内容を理解できない,話し合いの内容が網羅されていないといった問題が起きる.
本研究では,日常的な活動の中で記録されるコンテンツ,そして,そのコンテンツを携帯しているタブレット型端末から検索して提示し,並べ替えたりまとめながら話し合うことのできる情報的に拡張されたボードを実現する.参加者は,2つの道具を用いて,ミーティングで話したいと思ったこと,その結果がボードに提示され,並べ替えたりまとめながら話し合い,さらにその結果をボードに提示する.最終的にボードには,ミーティングの結果として,後で振り返って内容を想起できる充分な量の情報が提示されると考えられる.本研究では,このボードに表示されたミーティングの結果を記録する.そしてこの記録をと呼ぶ.
さらに,ボードはその内容を参加者間で共有するための道具であるから,本システムを用いて記録されるボードコンテンツは複数の参加者が,ボードの内容を協調的に作成したものである.ボードに提示した内容が分かりにくかったり,提示したものが適切に配置されていなければ,他の参加者が指摘したり,移動させたり,内容を編集したりする.このような協調的な作業によって作成されるボードコンテンツは,閲覧しやすく,話し合いの内容を適切に表したコンテンツとなるであろう.
ボードコンテンツは,ボードに提示したものだけでなく,ボードに提示したものをどのように操作したのかという情報を含む.ボードの内容を適切に並べ替えたり移動させたりする行為は,参加者が話し合いの内容を適切に把握できるように,同じトピックに属する情報は近くに寄せたり,抽象・具体関係でインデントさせたりする.このような内容を把握しやすくするための操作から得られる情報は,ボードコンテンツの構造情報であり,ボードコンテンツの検索や要約などの高度利用を実現するために重要なてがかりとなる.そこで,このような操作を観察し,適切に話し合いの内容を整理できるような仕組みを導入し,同時に適切なボードコンテンツの構造情報を取得するための機能をボードに実現した.
2.2 過去の話し合いが活かされない
過去の話し合いの内容が現在行われているミーティングで活かされず,同じ議論が繰り返されたり,同じ内容を再度説明しなければならなかったりすることを問題点として挙げた.過去に行われた話し合いの内容が適切に参照されれば,同じ議論・同じ説明をするにしても,過去の話し合いに基づいて話し合いの深化・発展が期待できる.
継続的ミーティング支援システムを用いて話し合いを行うことによって,その内容がボードコンテンツとして記録・蓄積される.これを参加者の日常的な知識活動を記録するために携帯しているタブレット端末から閲覧できるようにした.さらに,ミーティング中に過去のボードコンテンツから,進行中のミーティングで必要な部分を検索して,ボードに提示できるようにした.これによって,明示的に過去の話し合いの内容や結果を,進行中のミーティングの俎上にあげることができ,同じ話の繰り返しや,過去のミーティングを無視した話し合いを防ぐことができると考えられる.
本研究では,過去のボードコンテンツを進行中のミーティングにおいて提示する行為をと呼ぶ.議論の重複を防ぐために,過去のボード要素を引用することで,ボードコンテンツ間の関係情報が自動的に得られる.このボードコンテンツ間の関係を用いることで,提示した内容の並べ替えを行ったときに獲得した単一のボードコンテンツの構造とあわせて,継続的に行われるミーティング全体をグラフとして扱うことができるようになる.
さらに,ミーティングが継続的に行われ,2年3年と長期にわたってボードコンテンツが記録・蓄積されると,過去に行われたミーティングの内容を把握することが次第に困難になる.そこで,複数のボードコンテンツの内容から,重要な内容を発見して提示することができる仕組みを実現する.ミーティング中に過去の話し合いの内容を探す場合や,過去の話し合いの内容を振り返って閲覧する場合に,閲覧や検索の手がかりとして,一連のボードコンテンツの中から重要な内容を提示することで,効率的に目的の話し合いを見つけることができると考えられる.
2.3 知識活動とは
知識創造企業やナレッジマネジメントなどの言葉に代表されるように,現代社会における知識の重要性が高まっている.今後,どのようにして質の高い知識をより多く創造・管理できるか重要になると予想される.
知識には形式的言語で表現可能な形式知と表現不可能な暗黙知の2つがあり,これらの知識がダイナミックに相互作用することによって知識が創造される.この形式知と暗黙知の相互作用はSECIモデルと呼ばれ,以下の4つのプロセスのスパイラルとして表現される(図).
:経験を共有することによって,個人の暗黙知からグループの暗黙知を創造するプロセス
:暗黙知を,メタファ,コンセプト,モデルなどの共有できる形式知に変換するプロセス
:共有された形式知を組み合わせて新たな知識体系を創り出すプロセス
行動による学習によって形式知を暗黙知として体得するプロセス
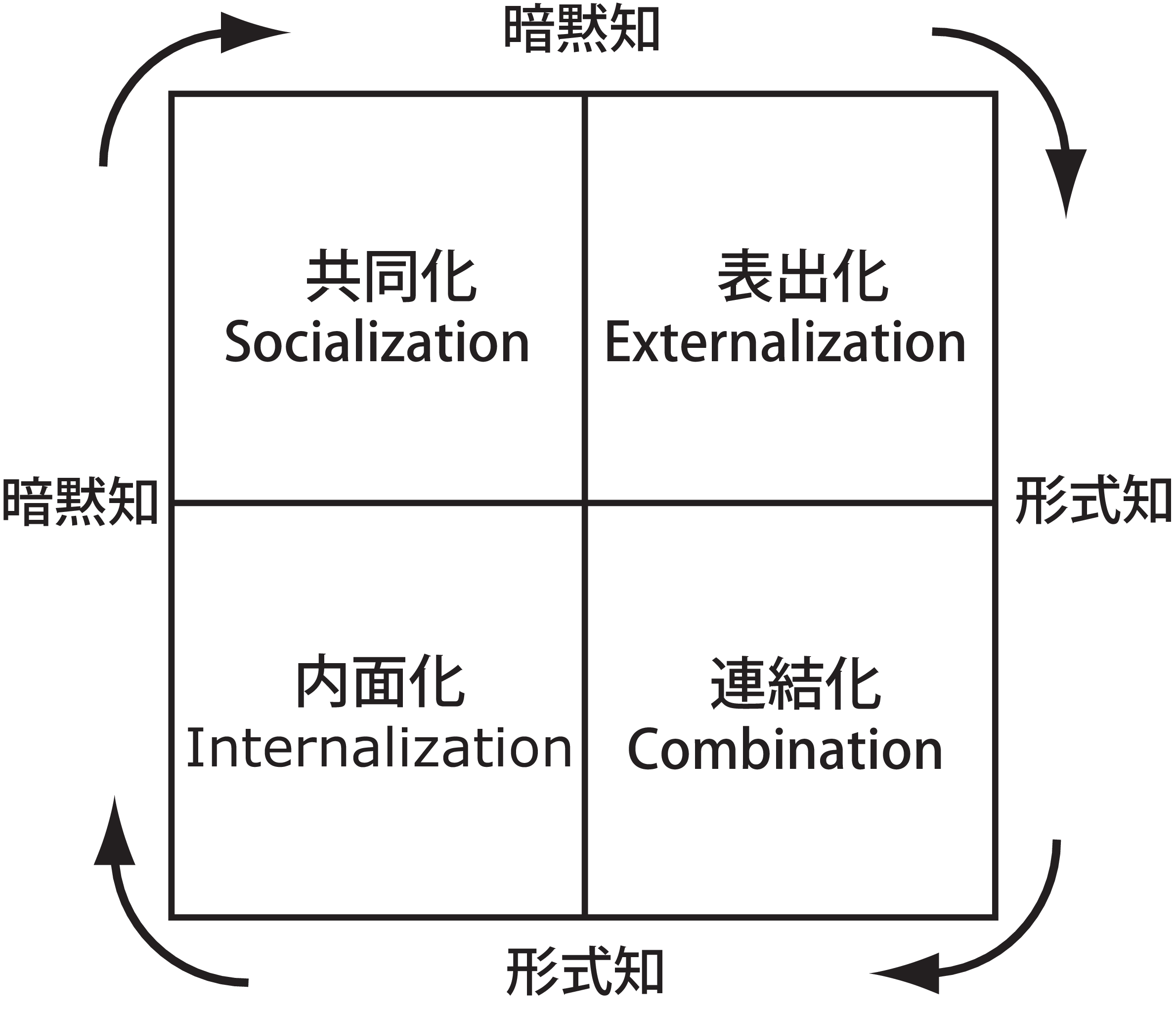
図2.1: SECIモデル
また,個人が創造した知識がその個人が属する組織に結晶化され,さらには組織間にわたる知識として結晶化される(図).この過程は共同化に相当する暗黙知の共有から始まる.そして,共有された暗黙知は新しいコンセプトという形の形式知へ変換される.そして,変換されたコンセプトに追究する価値があるかを示すために正当化を行った後に,プロトタイプなどの原型を作成する.このようなプロセスを通じて構築された知識はグループや組織,そして組織外へ移転される.このような1)暗黙知の共有,2)コンセプトの創造,3)コンセプトの正当化,4)原型の構築,5)知識の移転という5つのフェーズを経ることによって,スパイラルが生まれ,個人の知識が組織の知識として変換されていく.
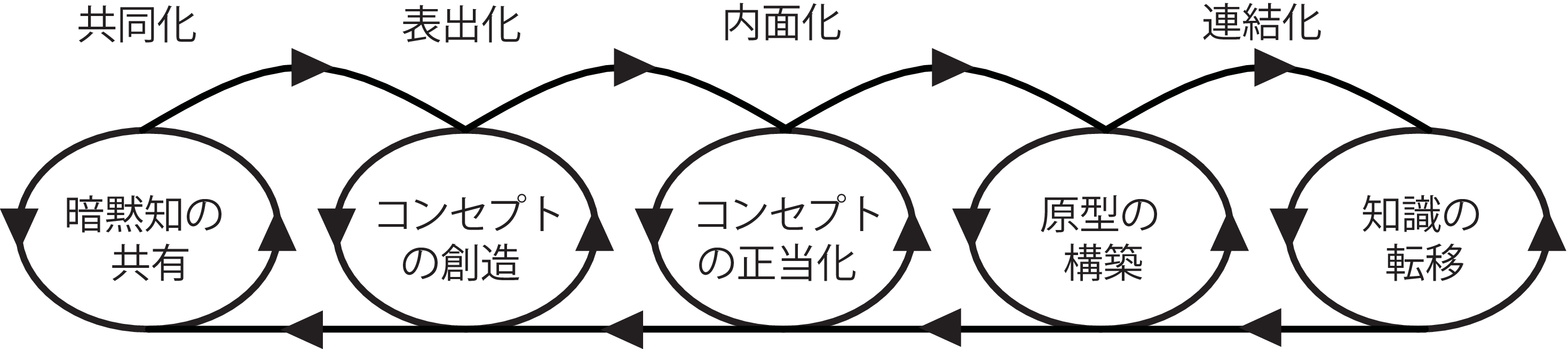
図2.2: 組織的知識創造プロセス
そして,このような知識スパイラルが複合的に実践されることによって,組織的な知識創造が行われる.
組織における知識創造や研究活動に共通する点は,テーマ(コンセプト)の一貫性である.たとえば,企業で新たな商品コンセプトが生み出されれば,企業内のメンバーがそれぞれの視点からそのコンセプトを満たすためのアイディアを出し合い,まとめていくことによって新しい商品が生み出される.また,研究活動では,いまだに解決されていない問題点を研究のテーマとして扱う.その問題点を解決するために独自の視点からアプローチを行い,新たな知識や技術を生み出していく.本研究では,企業組織における知識創造や研究活動のように「あるテーマに対して継続的にアイディアを創造し,知識として理論化・具体化する活動」をと呼ぶ.
そして,この知識活動に従事する者をと呼ぶ.ナレッジワーカーは,高度の専門能力,教育または経験を備えており,その仕事の主たる目的は知識の想像,伝達または応用にある.
ナレッジワーカーの知識活動には,調査や実験・検証・議論など様々なプロセスがある.例えば,何らかの仕事を遂行するために必要な情報を取得するために,Webや書籍・論文などの文献を調査したり,アイデアの妥当性を確認するために実験を行ったりする.調査や実験の結果を分析し,検証を行うことで問題点に直面したり,それを解決するために新たなアイデアや知識が生まれる.そして,このような活動の中で得られた知見に基づいて,他者とコミュニケーションを行う中で意見を出し合い,活動にフィードバックする.それぞれのプロセスは単独で行われるのではなく,相互に影響しあいながら繰り返し行われる.
2.4 知識活動におけるミーティング
前節で知識活動の概略について示した.野中らは,個人の知識活動によって結晶化された知識が,組織によって共有・結晶化されるには,知識創造プロセスにエネルギーを与え,生み出される知識の質を決定する場が必要であると述べている.「場」の概念には,単に物理的な空間だけではなく,電子メールや掲示板,チャットルームといった仮想的な空間や,同じ経験の共有,同じアイデアの共有といった心理的な空間を含んでいる.
他者とのコミュニケーションが行われる場の中でも,会議やミーティングはナレッジワーカーが一堂に会してナレッジワーカー同士の暗黙知を共有するための,『個人が直接対話を通じて相互に作用しあう「場」』として,重要な意味を持つ.そこで行われるコミュニケーションによって調査・実験・検証などについての,違う視点からの意見や新しいアイデアなどを得ることができる.
なお,書籍や論文によって「会議」が「ミーティング」よりも規模の大きいものに対して用いられる傾向にあるが,本論文においては「会議」と「ミーティング」は,「参加者がコミュニケーションを行う場,およびそこで行われるコミュニケーションそのもの」を指して用い,先行研究で使われている場合以外では「ミーティング」を主に用いる.
2.4.1 ミーティングの種類と役割
ミーティングは,目的,参加者の人数や質,場所,準備の必要性,アウトプットの種類などの多様なの切り口によってその役割が変わる.例えば,意思決定や目標の共有を目的とした役員会議や,アイディアの創出を目的としたブレインストーミング,廊下ですれ違い様に行われる立ち話や,情報共有を目的とした朝礼などが挙げられる.セミナーや勉強会,発表会,説明会などもミーティングのひとつと言えるだろう.このように多種多様なミーティングが研究や仕事のプロセスの中で日常的,かつ頻繁に行われている.
著者の所属する研究室において行われているミーティングは3種類ある.第一に,学生が研究を行っている過程で分からないことがあったときに,教授や先輩にする相談であり散発的に行われる最もカジュアルなコミュニケーションである.第二に,学生が所属するプロジェクトで1週間に1-2回,定期的に行われる少人数のプロジェクトミーティングがある.これは,プロジェクトのテーマを割り振られた学生が,それぞれの課題を持ち寄って話し合う場である.第三に,月に1度程度の頻度で研究室に所属する学生全員が参加して行う全体ミーティングがある.このミーティングは発表者と参加者にわかれ,発表者が日頃行っている研究の成果を資料にまとめ,それを用いて発表を行い,参加者が議論するというスタイルである.
ミーティングの規模や目的はそれぞれ違う.カジュアルなコミュニケーションはある個人が抱えている課題や問題を解決するために行われることが多い.あるプログラムの実装方法についてや,スケジュールの確認,プレゼンテーションの校正などといった内容である.目的,時間の長短や人数の多寡,準備の要否,場所など,決まった型がなく,相談を持ちかけた側の目的が達成されれば終了することが多い.
プロジェクト単位で行われるミーティングは,同じ目標あるいはテーマを共有しているメンバ同士が定期的に集まって,目標やテーマを解決するために少人数をアイディアや意見を出し合って行われるミーティングである.各個人はプロジェクトの目標やテーマに向かって割り振られたタスクの進捗の報告や問題点の指摘,新たなアイディアの提示や割り振りなどをミーティングにおいて行う.カジュアルなコミュニケーションに比べて,報告や問題点の提示を行うため,ミーティング前に準備が必要となる.
研究室全員が参加するミーティングは,それぞれのプロジェクトにおいて各人が行ってきた日頃の成果を周知し,成果について議論を行い,研究の方向性を決めたり,各人の抱えている問題や課題について,プロジェクトミーティングよりも広範な視座からの意見をもらう機会である.より多数の人間を拘束する.そのため,不要な議論や議論の停滞を防ぐためには,周到な準備が必要となる.
著者の所属する研究室を例にいくつかの種類のミーティングについて述べたが,これらを類型化するひとつの切り口は,話し合いに必要な準備にかかる時間的負担であると考えられる.カジュアルなコミュニケーションに負担をかけてしまうと仕事や作業が滞ってしまうだろう.プロジェクトミーティングに参加するにあたって,話す内容について考えたり,簡単な資料を用意したりしていないと,話し合いの方向が定まらないが,準備に負担をかけすぎると定期的に行うことが参加者の苦痛になってしまう.また,全員参加のミーティングでは,周到な準備を行っておかないと,話し合おうとすることの文脈を知らない人に,その内容を理解してもらえず話し合いが停滞してしまう.
カジュアルなコミュニケーションは先述したように個人の知識活動を円滑にするために行われる.プロジェクトミーティングや全員参加のミーティングでは,少人数のグループや組織の知識活動を円滑化するために行われている.しかし,グループや組織の知識活動も分解すれば,グループや組織を構成する個々人の知識活動の集合と捉えることができる.いずれのミーティングにも共通するのは,「個人の知識活動を円滑にするために行われる」と考えられる.
2.4.2 ミーティングで利用される道具と情報
ミーティングは,他者とのコミュニケーションである.コミュニケーションを円滑に行うためには,話し合いの目的や,目的に対してこれまでどのようなことが行われてきたのか,これから行う予定なのかといった背景知識をミーティング参加者間で共有している必要がある.共有が適切に行われていない場合,議論が迷走したり,必要のない議論が行われてしまう.
ミーティング参加者間で目的や背景知識を共有するためには,目的や背景知識を単に口頭で話すだけでなく,何らかの資料を配布したり,プレゼンテーションを行ったりする必要がある.背景や問題が複雑であればあるほど,議論のたたき台となる情報を文章や図などを用いて説明した資料が必要となる.
そして,ミーティングの規模が大きくなればなるほど,目的や背景知識の共有が難しくなる.そのため,必要な資料の質もミーティングの規模に応じて高くなる.例えば,立ち話のカジュアルなコミュニケーションで30ページのプレゼンテーションを見せられてから議論に入るのは大仰であろう.あるいは,研究発表会のようなミーティングで,A4一枚の資料で発表者の研究の背景を説明し理解してもらうことは困難であろう.そこで,ミーティングの規模に応じた資料を用意し,適切な道具を用いて,ミーティング参加者に伝える必要がある.
カジュアルなコミュニケーションでは,相談者が相談しようとする相手がその相談の背景や目的を理解して答えるのに十分な資料や情報を与えればよい.
プロジェクトミーティングでは,参加者全員に目的と背景知識を理解してもらうためには,相応の準備が必要になるだろう.しかし,プロジェクトに属している以上,そのプロジェクトがなぜ行われているのかという背景はすでに共有されている事を前提とし,簡単な資料,システムのモックアップや設計書などをたたき台として,話し合いを行えばよい.
参加者が多いミーティングでは,発表者がなぜその仕事や研究を行っているのか,というところから説明する必要があるだろう.話の全体を理解してもらうために枠組みを説明し,詳細を理解してもらうためにデモンストレーションや図などを用いて説明する必要があるだろう.一般的にはPowerPointやKeyNoteなどのプレゼンテーションスライドを用いて発表が行われる.
紙の資料を配布しない場合,小型のタブレット型デバイスや,液晶ディスプレイ,大型ディスプレイ,プロジェクタとスクリーンなどを用いて資料を提示する.
プロジェクトミーティングのように,参加者が自由に発言して話し合いをするようなミーティングの場合,話し合われた内容を書き留めたり,整理したりするためにボードが用いられる.
2.4.3 ファシリテーション技術
ファシリテーションとは,組織に属するナレッジワーカーが参加するミーティングをより円滑に行い,問題解決,アイディア出し,合意形成を支援し促進していくためのノウハウである.ファシリテーションを行う,ファシリテータの役割は,ミーティングのの目的や方向性を明確にし,ナレッジワーカーのモチベーションを引き出しコミュニケーションを円滑にすることにある.
ミーティングを円滑に進行し有益なものとするためには,極端に言えば事前に,議題・内容・議論するべき項目,必要な合意あるいは結論,ミーティングを行うことによって得られる効用などのミーティングの諸要素を明確化し,また,ミーティングの内容にあった型を選択して,参加者がその型について理解し共有していればよいであろう.さらに参加者全員が議論の最中にこれらの情報を常に意識し,客観的かつ俯瞰的な視座に立って,議論に参加すればよい.しかし,このようなミーティングを日常的に運営するのは極めて困難である.個人の経験や知識はばらばらであり,参加者それぞれの立場や思惑も違う.そのため,時間ばかりかかって結論の出ないミーティングや,鶴の一声ですぐに終わるが内容に乏しいミーティングが行われている.このようなミーティングにおいて,ミーティングを中立的に進行し,ミーティングに方向性を与え,議論を誘発して,より有益なものにする役割を担うのがファシリテータである.
ファシリテーション技術には,座席や設備・どのようなツールを使うかなどミーティングそのものに関する技術,議論を促す・アイディアを募る・時間の管理など議論の進行に関する技術,そしてボードやPost-itなどのツールを用いて議論内容の可視化を行い参加者が議論内容を把握することを支援する技術などがある.なかでも議論内容の可視化については,グラフィックファシリテーションと呼ばれ,様々な書籍がでている.グラフィックファシリテーションは,どのようにして議論の内容をボードやPost-itを用いて分類・整理してミーティング参加者に提示すれば,ミーティング参加者がより正確に議論内容を把握できるか,という技術である.ファシリテータがグラフィックファシリテーションを行うことで,ミーティング参加者は議論内容を正確に把握しながら議論に集中して,よりよいミーティングを行うことができるようになる.
2.5 資料作成の手間
資料作成に手間がかかってしまうと,継続的に行われるミーティングのコストが上がってしまい,ミーティング参加者の負担となってしまうことを問題点として挙げた.同時に,適切な資料が提示されなければ,話し合いが迷走したり,本来話し合うべき内容に辿り着くまでに不必要な時間がかかってしまう.いかにして,資料作成の手間を低減してミーティングのコストを下げ,同時に適切な資料を用意できるようにするか,という2つのバランスを取る必要がある.
そこで,ミーティング参加者の日々の活動を記録するためのシステムを構築した.このシステムで記録するのは,ミーティング参加者が仕事や研究のなかで日常的に作成する,テキストメモやプレゼンテーション資料,手描きのスケッチ,画像,映像,論文といったコンテンツである.これらのコンテンツを,各個人のPCや日常的に携帯することのできるタブレット型デバイスで作成し,コンテンツを記録するクラウドサーバに記録するシステムを構築する.
このようなシステムを導入することで,個人の知識活動の記録を広範囲に蓄積することができる.そして,ミーティングに参加した際に,話し合いの場に必要なコンテンツを検索し,情報的に拡張されたボードに提示できるようにした.これによって,ミーティング用に特別な資料を作成する手間を軽減し,かつ話し合いの論点を明確にするための適切な資料を提示できる.
2.6 継続的ミーティングとは
ミーティングが,多様な状況下で様々な参加者の知識活動をよりよいものにするための場として機能していることを述べた.著者の所属する研究室では,以前からディスカッションマイニングと呼ばれる研究室のゼミを対象としたミーティング支援システムを提案している.ディスカッションマイニングが対象としているのは,事前準備を必要とするミーティングである.
本研究で注目する継続的ミーティングは,より日常的に,少人数のグループで行われるミーティングである.プロジェクトあるいはチームなどの共通の目標を持つ複数のメンバーが集まって,個人および組織の知識活動の中で継続的かつ頻繁に行われる継続的ミーティングは,目標に向かって仕事や研究を円滑に進めていくために重要な役割を担っている.
継続的ミーティングの議題は,問題や疑問,企画などのアイディア出し,タスクの進捗管理など多岐に渡る.ミーティングを行うことによって,各個人が抱えている問題を解決したり,他者からの意見を参考に新しい知見を得たりすることができる.そして,話し合われた内容に基づいて各個人が自らの仕事や研究を遂行していく.
一般的な継続的ミーティングは次のように進行する.各参加者は,日常の知識活動の結果を持ち寄り,他の参加者と共有し,それらに基づいて話し合い,話し合いの結果を自らの知識活動にフィードバックして活動を継続する.
持ち寄る知識活動の結果には,タスクの進捗状況,問題点,新たに生じた課題,新たな知識などが挙げられる.そして,これらを,自分のために整理したり,他者に説明するための資料としてまとめたりしたものを,ミーティングで他の参加者に提示する.話し合いの過程で出てきた意見,解決策やアイディアは,継続的ミーティングで一般的に用いられるボードに書き留められる.話し合いの結果は,ボードを写真に撮ったり議事録として清書したりして,ミーティング参加者に配布され,各参加者は他者の意見を自身の活動にフィードバックする.
2.6.1 継続的ミーティングの問題点
継続的ミーティングの役割は,それぞれの参加者の知識活動と,グループの知識活動を円滑にして,知識活動の成果をよりよいものにすることである.
知識活動を円滑にするため,継続的ミーティングは日常的かつ頻繁に行われるものであるため,継続的ミーティング自体の効果を高めることで,よりよい知識活動を実現できるだろう.しかし,一般には,不必要な議論が起こったり,時間だけ長々とかかって結果が出なかったりする.そのため継続的ミーティングを行うことが却って,円滑な知識活動の障害になることも少なくない.
以下に,継続的ミーティングにおける一般的な問題点を列挙する.
2.6.1.1 ミーティング内容の適切な記録が難しい
本節の冒頭で述べたように,ミーティングは個人および組織の知識活動を円滑にするために行われるものであり,知識活動の中で行われるミーティングで他の参加者から得た多様な意見やアイディアを活動にフィードバックして行くことが重要である.
意見を適切にフィードバックするためには,話し合いの経過や結果の中でその後の知識活動に必要な要素を過不足なく記録し,いつでも参照できる必要があるだろう.
継続的ミーティングを記録する方法はいくつか考えられる.まず,書記を用意して話し合いの記録を取る方法である.これは,最も一般的な方法であり,適切な人選をすれば効果的な議事録を作成できる.しかし,書記を参加者の中から選出すると,書記をすることに追われてしまい,その参加者は話し合いに参加することが困難になる.また,話し合われていることに対してあまり詳しくない参加者に書記を任せると,その人が理解できない内容が議事録から抜けてしまったり,議事録に誤解が含まれてしまったり,適切に話し合いの内容を要約できなかったりする.かといって,話し合われている内容についてよく知っていて,話し合いの内容を適切に要約できる人は,書記をするよりも積極的に話し合いに参加するべきであったりする.こうした事情から,ファシリテータの問題と同じように,少人数で行っているミーティングにおいて専任の書記を用意するのは困難である.
また,会議内容を音声や映像で記録する研究が数多く行われている.ChiuらはLiteMinutesと呼ばれるWebブラウザ上でマルチメディア議事録を作成するシステムの研究を行っている.LiteMinutesは,カメラが設置された部屋の中でスライドを用いた議論を行い,議論の様子を映像・音声情報として記録する.また,書記が無線ラップトップPC上で専用のツールを用いることで,議論内容をテキストとして入力する.テキストの入力された時間は自動的に取得され,その時間情報を用いて関連するスライドや映像・音声情報と入力されたテキストとの間にリンク情報を付与する.
このような研究で記録されるマルチメディア議事録は,議論内容がほぼすべて記録されており,インデキシングされた映像や音声を専用のブラウザで効率的に閲覧できるようになっている.しかし,映像や音声によって構成される議事録は,テキストの議事録とは違い閲覧するのに時間がかかる.頻繁に行われる継続的ミーティングにおいては,規模の大きなミーティングとは違い,より手軽にミーティング中に得た議論の内容を確認してフィードバックできる必要があるだろう.
そこで,継続的ミーティングで用いられるボードの記録を取る方法が考えられる.ボードの最終状態や,ボードが消される前の状態を写真で撮って,それを共有するやり方である.この方法は手軽で人を用意する必要もないため一般的に実施されている.しかし,フィードバックされるべき意見がボード上に網羅されていて,かつ整理されていないと,内容の把握が困難になる.ミーティング中に書かれたホワイトボードの内容は,特に意識して利用しない限り雑然としていて,清書しなければ時間が経過した後に見返したときにその内容を理解できない場合が多い.
2.6.1.2 過去のミーティングの内容が活かされない
継続的ミーティングは,少人数のグループで行われるミーティングである.グループは同じ目標を共有するナレッジワーカー同士で作られている.同じ目標を共有して話し合われたミーティングの結果は,その後のミーティングでも参照されてしかるべきであるし,過去のミーティングに基づいて議論を積み上げて行くことで,よりよい成果を得られるはずである.
しかし,一般的には,同じ話の繰り返し,過去の話し合いを踏まえずに新たに議論を行って結論が変わってしまう,ということが頻繁に起こる.
これは,過去に行ったミーティングの内容を忘れていたり,誤解していたりするのが主な原因であろう.過去に行われたミーティングをすべて覚えているナレッジワーカーは少ないだろう.また,紙で記録された過去のミーティングの議事録をすべて会議に持ち込むのは難しい.
2.6.1.3 資料の準備に手間がかかる
項で述べたように,ミーティングをより円滑に行うためには,参加者が話し合えるだけの背景知識を共有するために,相応の準備が必要である.特に,規模が大きくなればなるほど,参加者全員で発表や発言に対する背景知識が共有されていることを前提とすることが困難になる.そのため,準備に時間をかけてスライドやデモンストレーション映像などを作成する必要が出てくる.しかし,このような資料の作成は,時間的負荷が大きく,継続的ミーティングのように頻繁に行われるミーティングでこのような準備をするのは困難である.
継続的ミーティングは頻繁に行われるものであるため,研究や仕事をなぜ行っているかといった,抽象度の高い背景情報の説明は必要ないことが多い.そのため,参加者がある程度の背景知識を共有していることを前提に,直面している課題が何であるかを共有することになる.かといって,資料やシステムのモックアップなどを準備する必要がないわけではない.あるミーティング参加者が,ある課題についてミーティングを通して適切な意見やアイディアを他の参加者から得るためには,その課題についての背景知識を共有するための資料が必要である.ただし,多人数で行われるようなミーティングにおいて必要な体裁の整った資料は必要なく,作成途中のインタフェースや統計ソフトの出力結果,個人のメモ書きをまとめたものなど,日常の知識活動の過程で生まれたコンテンツを提示すればよい.
2.7 継続的ミーティングの支援
節において継続的ミーティングの概略と問題点について述べた.継続的ミーティングは,個人および組織の知識活動を円滑にするための場である.この場をより円滑で効果的な場にすることができれば,知識活動の質を高めることができると考えられる.本論文では,継続的ミーティングを支援するシステムを構築し運用して知識活動を支援することを目標とする.本節では,上述した継続的ミーティングの問題点に基づき,支援システムに求められることについて述べる.なお,支援システムの詳細については章において詳述する.
2.8 本章のまとめ
本章では,知識活動において継続的ミーティングがどのような役割を果たしているのかを述べた.本研究において,知識活動とは「あるテーマに対して継続的にアイディアを創造し,知識として理論化・具体化する活動」であり,ミーティングは個人および組織の知識活動を円滑にする役割を持つと述べた.
本研究では,ミーティングの中でも少人数で継続的かつ頻繁に行われるミーティングに注目し,継続的ミーティングと総称してその支援を目的とする.継続的ミーティング支援システムについて考える前に,1)ミーティング内容の適切に記録が困難,2)過去のミーティング内容が活かされない,3)資料作成に手間がかかる,という3つの問題点を挙げた.
次に,これらの問題点に基づき,継続的ミーティングを支援するために必要なシステムについて述べた.支援システム全体のコンセプトとして「コンピュータで検索や要約などを実現するために必要な情報を獲得するために,人間に不必要な負荷をかけないこと」を掲げ,日常的な活動の中で記録されるコンテンツを記録・蓄積し,そのコンテンツを携帯しているタブレット型端末から検索して提示し,並べ替えたりまとめながら話し合うことのできる情報的に拡張されたボードを実現する.
そして,ボードに提示された内容をボードコンテンツとして記録する.さらに,話し合いの過程で参加者が行った,ボード内容の並べ替えや移動といった情報をボードコンテンツの構造情報として獲得する.
さらに,過去のミーティング内容に基づいた話し合いを実現するために,過去のボードコンテンツから適切な部分を引用して,進行中のミーティングに提示して話し合える機能を実現する.過去のボードコンテンツを効率的に検索して閲覧できるようにする.
次章では,日常的な活動の中で記録するコンテンツをどのようにして,記録するべきか,記録をどのように利用できるようにするべきか,ということについて述べる.
3 知識活動におけるコンテンツとそのメタ情報
3.1 知識活動におけるコンテンツ
一般にコンテンツは,テレビ番組や映画,音楽のように多数の人間に対して公開されている娯楽用のメディアという印象がある.辞典によれば,コンテンツとは以下のような意味を持っている(新村 出編,広辞苑 第六版,岩波出版,2008年.).
1. 中身.内容. 2. 書籍の目次. 3. 放送やインターネットで提供されるテキスト・音声・動画などの情報の内容.
最後の定義に従うと,1.それ自体が意味のある内容を持っている,2.(Web上のコンテンツの場合)インターネットを通じて公開されている,という2点がコンテンツとして成立するための要件だと考えることができる.本研究では,このような要件を踏まえながらコンテンツの概念を再定義する.
ナレッジワーカーは日常的な知識活動の中で多種多様な情報を生み出し,利用する.例えば,活動内容をテキストでメモしたり,自身の考えを整理するために手描きでスケッチを描いたり,統計ソフトでグラフなどを生成したり,データベースやネットワーク設計では図を書いたりする.あるいは,調査のためにWebサイトや論文を読んだり,映像を閲覧する.さらに,それらの成果をまとめてPowerPoint(Microsoft PowerPoint:PowerPoint2010 - Office.com: http://office.microsoft.com/ja-jp/powerpoint/(2012年10月1日))やKeynote(Keynote:アップル - iWork - Keynote - 魅力的なプレゼンテーションを簡単に.http://www.apple.com/jp/iwork/keynote/(2012年10月1日))を用いたプレゼンテーションを作ったり,報告書や企画書,論文としてまとめたりする.そこで本研究では,知識活動を通じて生み出され,また利用されるさまざまな情報をと呼ぶ.
近年では,コンテンツをクラウドに保存して必要なときに検索して,いつでも取り出せたり,他者と共有したりできるようになってきている.例えば,テキストメモであればEvernote(Evernote:「すべてを記憶する」http://www.evernote.com/(2012年10月1日))やCatch(Catch:「Catch.com」 http://catch.com/(2012年10月1日))が挙げられる.どちらもPCをはじめタブレット型デバイスやスマートフォンなど多様なデバイスに対応していて,基本的にはテキストでメモを書いてそれをクラウドに保存し,必要なときに検索して取り出すことができる.また,画像・映像などをノートの中に埋め込むことができるようになっている.同様に,画像であればFlickr(Flickr:「Welcome to Flickr - Photo Sharing」http://www.flickr.com/(2012年10月1日)),手描きのスケッチであればSkitch(Skitch:「Skitch - Annotate, edit and share your screenshots and images...fast」http://skitch.com/jp/(2012年10月1日)),スライドならばSlideShare(SlideShare:「Upload & Share PowerPoint presentations and documents」http://www.slideshare.net/(2012年10月1日))などが挙げられる.論文や映像などはDropbox(Dropbox:「Dropbox - 生活をシンプルに」https://www.dropbox.com/(2012年10月1日))やSkyDrive(SkyDrive:「無料の大容量オンラインストレージ SkyDrive - Windows Live on MSN」http://windowslive.jp.msn.com/skydrive.html(2012年10月1日))などのオンラインストレージに保存されることが多い.
3.2 コンテンツのメタ情報
ナレッジワーカーが新たなコンテンツを作成する場合,それまでの知識活動において生み出した,多種多様なコンテンツを埋め込んだり手直ししたりして利用する場合がある.その際,利用するコンテンツが作られた理由や現象,要求,あるいはそのコンテンツについて話し合われた内容,そのコンテンツを作成したときに参考にした情報などが分かれば,新たなコンテンツを作る参考にでき,よりよいコンテンツを作ることができるだろう.このような,あるコンテンツが作られた背景や,コンテンツの利用履歴,コンテンツに対して外部から与えられた情報などを,と呼ぶ.
土田らは,大学研究室における研究活動において生み出される情報をコンテンツ,TODOやノートなどの一部分を引用して他のノートやプレゼンテーションに埋め込む行為を引用と定義している.多様なコンテンツを引用しながら作成したプレゼンテーションを,会議で利用することによって,会議で得られた他者からの意見をプレゼンテーションと関連づけて記録できるシステムを実現している.このシステムを用いて知識活動を継続的に行うことで,コンテンツおよび,コンテンツ間の引用関係と,それに対する文脈情報が蓄積される.
継続的ミーティングでは,コンテンツをミーティングを円滑に進行させるために必要な事前準備した資料として扱う.ミーティング参加者が抱える問題点や課題について議論する前に,他の参加者間で情報を共有するためにコンテンツを提示し,また議論途中に分からないことがあれば,適宜検索して適切なコンテンツを話し合いの俎上に挙げることで,論点を明確にしながら話し合いを進めることができる.そして,継続的ミーティングでコンテンツを利用することで,継続的ミーティングにおける他ユーザからの意見を,コンテンツに対する文脈情報として獲得することができる.
継続的ミーティング支援システムが,コンテンツの全体しか提示できない仕組みであると,提示される情報の量が多すぎて他の参加者と共有したい情報が分からなくなってしまう.例えば,100行あるテキストメモ,20枚あるプレゼンテーションファイル,20分の映像などが提示された場合,提示された内容のどの部分を理解することが求められているのかが分からず,話し合いを円滑にするどころか,かえって阻害してしまうことになりかねない.
資料のどの部分について話し合うのかを明確にするためには,資料の全体だけでなく,どの部分かを明示できるようにする必要がある.コンテンツの部分を明示するためのメタ情報に関する研究には,梶らの提案するElementPointerや,Sawhneyらの映像の内部構造を表現するための仕組みであるHypervideoがある.Hypervideoは,映像を複数の映像シーンに分割するメタ情報を付与し,テキストなどの他のコンテンツと関連付けて扱えるようにすることで,映像を取り扱いやすくするための仕組みである.また,長尾らは,映像シーンに対するメタ情報をWeb上のコミュニティ活動から獲得する,オンラインアノテーションを提案している.オンラインアノテーションの実装である山本らのSynvieでは,映像の部分要素である映像シーンを引用したブログ記事を書けるようにすることで,映像シーンの定義とそれに対するテキストアノテーションを獲得し,映像シーンの検索に応用している.
本研究では,コンテンツの部分要素の定義と,コンテンツの全体および部分要素に対する文脈情報を,総じてと呼ぶ.コンテンツの作成時,および継続的ミーティングや新たなコンテンツの作成時に獲得したメタ情報を蓄積することで,コンテンツの閲覧や検索,要約などの高度な応用を実現することができる.
次節以降,コンテンツに付与されたメタ情報を利用して,関連付けられた複数のコンテンツを効率的に閲覧するためのインタフェースについて述べる.
3.3 論文と映像に対するメタ情報を利用した読解支援
仕事や研究をよりよいものにしたり,新しいアイディアや企画を生み出すためには,新しい研究や技術はもとより,先行する研究や技術の調査が非常に重要である.このような調査は,しばしば対象としている分野の論文やマニュアル,書籍などの文書を読むところから始まる.
ある文書が理解しやすいかどうかを考える場合,文書全体の構成,文章の論理性,文体や図・表が充実しているかなどが問われる.なかでも,著者の想定した読者が,実際の読者と合致しているかが特に重要な要素であろう.例えば,学習を始めて間もない初学者が専門分野の論文を充分に理解するためには,その文書が書かれた背景を認識することや基礎知識の蓄積が不可欠になる.その論文の文章や,挙げられている参考文献だけを読んでも,その内容を充分に理解するのは困難であろう.そして,特に論文などでは初学者が内容を理解するために必要な基礎的な事柄が詳述されることは少ない.初学者でなくとも,システムの動作や実験風景などについて,文書に含まれるテキストや図だけでは状況を充分に理解することが困難な場合がある.
このような場合,参考文献に挙げられている文書だけでなく,元の文書の内容に関連する様々なコンテンツを参考にすることが理解の補助となる.例えば,システムのデモビデオや,文書に書かれている内容について会議や学会などで発表された時の記録映像,あるいはその発表資料や開発したシステムの詳細な設計図,関連分野の基礎的な内容に関する書籍など,元の文書そのものには含まれていないが,内容の理解の補助となるコンテンツである.
しかし,関連するコンテンツを寄せ集めただけでは,効果的な読解支援は期待できない.論文に対する理解を促進する目的で,1時間を超えるような映像が提示されたとしても,論文の一部を理解するためにそのような映像を閲覧するのは時間的な負荷が高い.そのため,ある文書の部分を理解するために必要な映像の部分を切り出して提示することが必要であると考えられる.
例えば,大学の研究室では,毎年,新たに学生が配属されてくる.一般に,このような学生に研究室の教授や先輩が執筆した論文を読ませて,理解させるのは困難である.その理由のひとつとして,研究室で行われてきた研究の背景知識が乏しく,その論文を読んだだけでは,その内容を充分に理解できないことが挙げられる.このような場合,論文の部分に対して,その部分の理解を補助するような映像が関連付いていれば読解の補助になるであろう.
説明のため,より具体的に,著者が所属する研究室に配属された学部4年生に本論文を読ませることを考える.本論文に,後述のSynvie(映像アノテーションシステム)やDocvie(論文読解支援システム)のインタフェースの動作を説明した映像の部分や,関連研究それぞれの論文の一部分が適切に関連付いていれば,内容の理解がより容易になると考えられる.学生が,Synvieを拡張して実現した映像シーンに対するアノテーション画面の映像を閲覧し,その映像シーンと関連付けられた,Synvieについて記述された論文の引用インタフェースに論文の部分や,Synvieの先行研究であるiVAS(本文の参考文献ではないので脚注に論文への参照を入れる.D Yamamoto and K Nagao. IVAS: Web-based Video Annotation System and its Applications. In Proc. of the 3rd International Semantic Web Conference (ISWC2004), pp. 7--11, 2004.)やCo-Annotea,Annotea(同上,J. Kahan, M.-R. Koivunen, E. Prud'Hommeaux, and R.R. Swick. Annotea: An Open RDF Infrastructure for Shared Web Annotations. Computer Networks, Vol. 39, No. 5, pp. 589--608, 2002.)のインタフェースについて説明した論文の部分や映像の部分を参考にして読み進めていけば,本論文への理解が深まるであろう.
このような状況は,大学の研究室だけでなく一般的に起こりうる.本研究では,文書の読解,中でも論文の効率的な読解を支援するために,論文と映像の部分要素の定義とその関係に基づいて関連コンテンツを閲覧できるシステムについて提案する.
論文を充分に理解するためには,その背景になる知識がなければならない.論文を効率的に読解するためには参考文献だけでなく,関連する様々な種類のコンテンツを閲覧することが有効であると考えられる.文書に関連するコンテンツの効率的な閲覧を支援するためには,論文や映像などのコンテンツの部分要素を獲得すること,部分要素間の関係情報を獲得すること,そして,部分要素とその関係情報に基づいて文書と文書に関連するコンテンツの効率的な閲覧を支援するインタフェースを構築する必要がある.以下に,それぞれの課題についての関連研究を示す.
文書に対するアノテーションを行う研究は数多く行われている.中でもXLibrisでは,電子文書の部分要素に対してペンタブレットを用いて注釈を付与することができ,注釈を含む文書の部分要素をユーザ間で共有する仕組みを実現している.
また,本研究では取り扱わなかったが,映像だけでなく学会発表や講義で利用するスライドやミーティングの音声など,様々なマルチメディアコンテンツの部分要素に対するアノテーションを利用することで,論文読解を支援できると考えられる.例えば,KamらのLivenotesやDavisらのNotepalsでは,講義中のスライドの一部分に対して講義の受講者がアノテーションを付与できる.
これらのマルチメディアコンテンツ間の関係を獲得する手法に関して,HunterらのCo-Annoteaがある.Co-Annoteaはマルチメディアコンテンツの部分要素に対するアノテーションと,部分要素間の関係を付与できるシステムである.付与したアノテーションに基づいて,複数のマルチメディアコンテンツを読み込んでアノテーションを確認しながら閲覧することができる.
コンテンツの部分要素を組合せて新たなコンテンツを作成することに注目した研究について,ChambelらのHTIMELをあげる.HTIMELでは,映像シーンとテキストの部分要素,画像を組合せたハイパーメディアコンテンツをユーザが自由に作成できる環境を実現している.HTIMELは,コンテンツを組合せてハイパーメディアを作成することができるが,そのコンテンツの閲覧者はハイパーメディアの作成者が意図した範囲のコンテンツしか閲覧することができない.
本研究では,コンテンツの部分要素とその関係を利用して,論文の読解を支援するためのインタフェースを実現する.論文読解を支援するためには,他のユーザが付与したアノテーションを手がかりに読解できるようにすることが有効であろう.テキストによるアノテーションだけでなく,映像や他のマルチメディアコンテンツの部分要素が互いに関連付けていれば,閲覧している部分要素と関連付いているコンテンツを辿って閲覧することができる.先述したCo-Annoteaにおいても,部分要素に関連付けられた他のコンテンツの部分要素を,単一のインタフェース上で閲覧できる仕組みを提供している.Co-Annoteaのユーザはコンテンツの部分要素間が関連付いている限り,アノテーションを辿って行くことで,多種多様なコンテンツを閲覧することができるが,論文読解などの特定の用途に特化してはおらず,またインタフェースに対しての定量的な検証も行われていない.
そこで本研究では,まず著者の所属する研究室で研究開発が行われてきた,コンテンツにアノテーションを行うためのシステムを適宜拡張することで,ユーザが日常的な研究活動で閲覧する論文や映像の部分要素に対するアノテーションと,部分要素間の関係を記録する.そして,獲得したアノテーションに基づいて,ユーザが注目しているコンテンツの種類(論文または映像)に応じた,関連するコンテンツの部分要素を効率的に閲覧できるインタフェースを実現する.さらに,実現したインタフェースの論文読解に対する有効性を検証した.
なお,ユーザのアノテーション行為そのものが学習や読解の支援につながるとするActive Readingという手法があるが,本研究では,次節で説明するアノテーションの仕組みをコンテンツの部分要素に対するアノテーションを獲得するためにのみ用い,アノテーションを付与する過程における学習・読解支援については別の機会に扱うことにする.
3.4 論文と映像のアノテーションの獲得
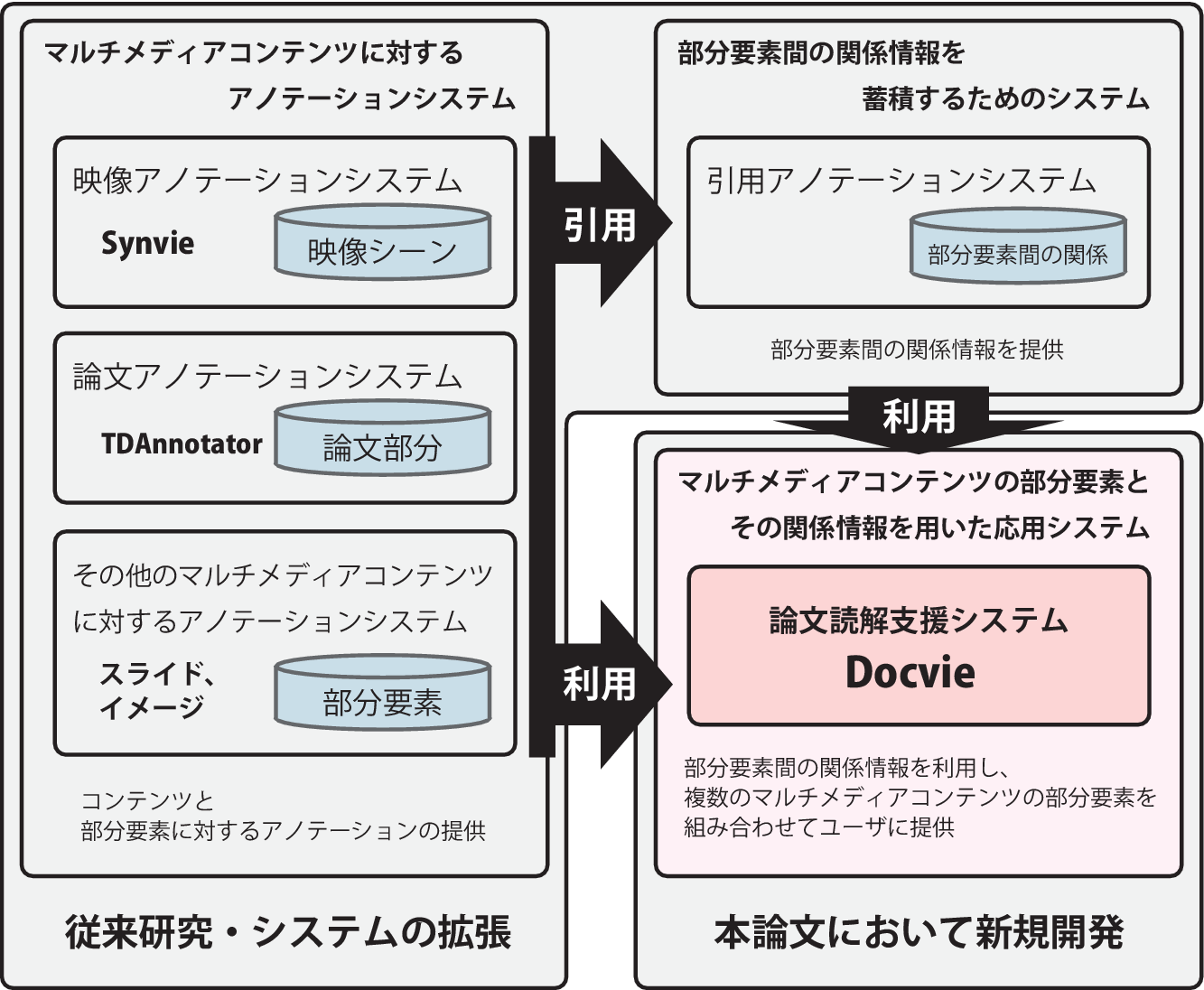
図3.1: コンテンツの部分要素間の関係を利用した論文読解支援の仕組み
図に示すように,論文に関連するコンテンツの効率的な閲覧を実現するためには,論文と映像の部分要素,および部分要素間の関係情報を獲得する必要がある.本研究では,論文の部分要素を取得するためのシステムとして,文書に対するアノテーションを行うことのできる様々な先行研究を参考にしてTDAnnotatorと呼ばれる新たなシステムを構築した.また,映像の部分要素を取得するための仕組みとして,これまでに研究・開発を行ってきた映像アノテーションシステムSynvieの映像シーン引用ブログを記述するためのインタフェースを利用して,映像シーンを定義して保存するためのインタフェースを開発した.さらに,部分要素間の関係情報を獲得・蓄積するために,引用アノテーションシステムを構築し,論文と映像の部分要素を引用できるようにした.なお,いずれの仕組みも,コンテンツの部分要素とその関係を獲得するために,先行研究を参考にして開発したり利用したりすることで実現しており,特に新規性はない.また,将来的には,関連付けるコンテンツの部分要素は映像に限らずスライドやイメージなども利用できるようにする.
先述したように,ユーザはこれらのアノテーションの仕組みを用いて,同じプロジェクトで研究している他のユーザと協調して,部分要素に対するアノテーションを行う.そして,日常的な研究活動の中でアノテーションを行える仕組みによって映像や論文へのアノテーションを蓄積していく.それぞれのアノテーションシステムは,別々のサーバで稼働しているが,ユーザ情報の管理を集中的に行うユーザ管理サーバを用いて,シングルサインオンを実現している.これによって,ユーザは認証を一度行うだけで全システムを利用することができ,それぞれのシステムが記録するアノテーションと関連付けされるユーザ情報は全システム共通である.また,それぞれのシステムは,他のシステムと連携するために,自身が管理しているコンテンツの情報を提供するAPIを実装している.
次に,映像と論文のそれぞれについて部分要素に対するアノテーションを作成する仕組み,両者の関係を獲得する仕組みについて詳述する.
3.4.1 論文へのアノテーション
論文に対するアノテーションを作成・閲覧するために,TDAnnotatorを開発した.TDAnnotatorの論文読解インタフェースを図に示す.この画面では論文の各ページが画像に変換され,アノテーションが付与された論文の部分が,状態ごとに色分けされた矩形で表示される.この矩形は,ユーザが論文の一部分に対してアノテーションを付与するために定義・作成する論文の部分要素である.以後,この矩形領域をと呼ぶ.赤い矩形で表される論文部分は(図中の論文中段右側の細線の矩形)はアノテーションが付与されていることを示す.また,青い矩形で表される論文部分(同,左上の太線の矩形)は,項で述べる関連付けの仕組みを用いて,映像シーンが論分部分に関連付けられていることを示しており,これは節で述べる実験で利用する.

図3.2: TDAnnotatorの画面
TDAnnotatorでアノテーションを行うためには,まず,画面に表示される論文上でマウスドラッグ操作を行って矩形範囲を選択(続けて複数の矩形範囲を選択することで複数の矩形範囲に対するアノテーションも可能)し,選択した矩形範囲をクリックすると,その矩形に対するアノテーションを入力するダイアログが表示される.このダイアログで矩形内容(本文,数式,グラフ,表,図,タイトル),文章タイプ(翻訳,書き起し,コメント),アノテーションの本文を入力する.
なお,すでに定義された論文部分の内側の部分に対してアノテーションを行う場合にも新たにアノテーションを付与する場合と同様に,インタフェース上でドラッグ操作を行うことで新たな論文部分を定義できる.このような他の論文部分に包含された論文部分を選択する場合には,1回目のクリックが論文部分の選択となり,選択された論文部分がハイライトされ,2回目のクリックでダイアログが表示される.
アノテーションの登録を行うと,データベースには上述の矩形範囲(論文のページ番号,位置,サイズ)の集合,矩形内容,文章タイプ,アノテーションの本文,論分部分を含む論文のID,アノテーション作成者の全システム共通のIDが記録される.
また,他のユーザが定義した論文部分やユーザ自身が以前に定義した論文部分に対してアノテーションを付与することもできる.論文上に配置された論文部分をクリックするとアノテーション一覧が表示され,「Add Annotation」ボタンを押すことで既存の論文部分に対してアノテーションを付与することができる.この場合,データベースにはすでに定義された矩形範囲のIDとアノテーションが関連付けられて保存される.
付与されたアノテーションは付与したユーザのみが編集・削除を行える.ただし,矩形範囲に付いては,指し先のないアノテーションを防ぐために,他者がアノテーションが行っていたり,後述の仕組みで関連付けが行われている場合は,削除することができない.
論文上に表示される矩形を選択することで,付与されているアノテーションの内容を閲覧できる.また,論文に対するアノテーションはユーザ間で共有され,あるユーザが付与したアノテーションが後続のユーザの読解時の手がかりとなると考えられる.
3.4.2 映像へのアノテーション
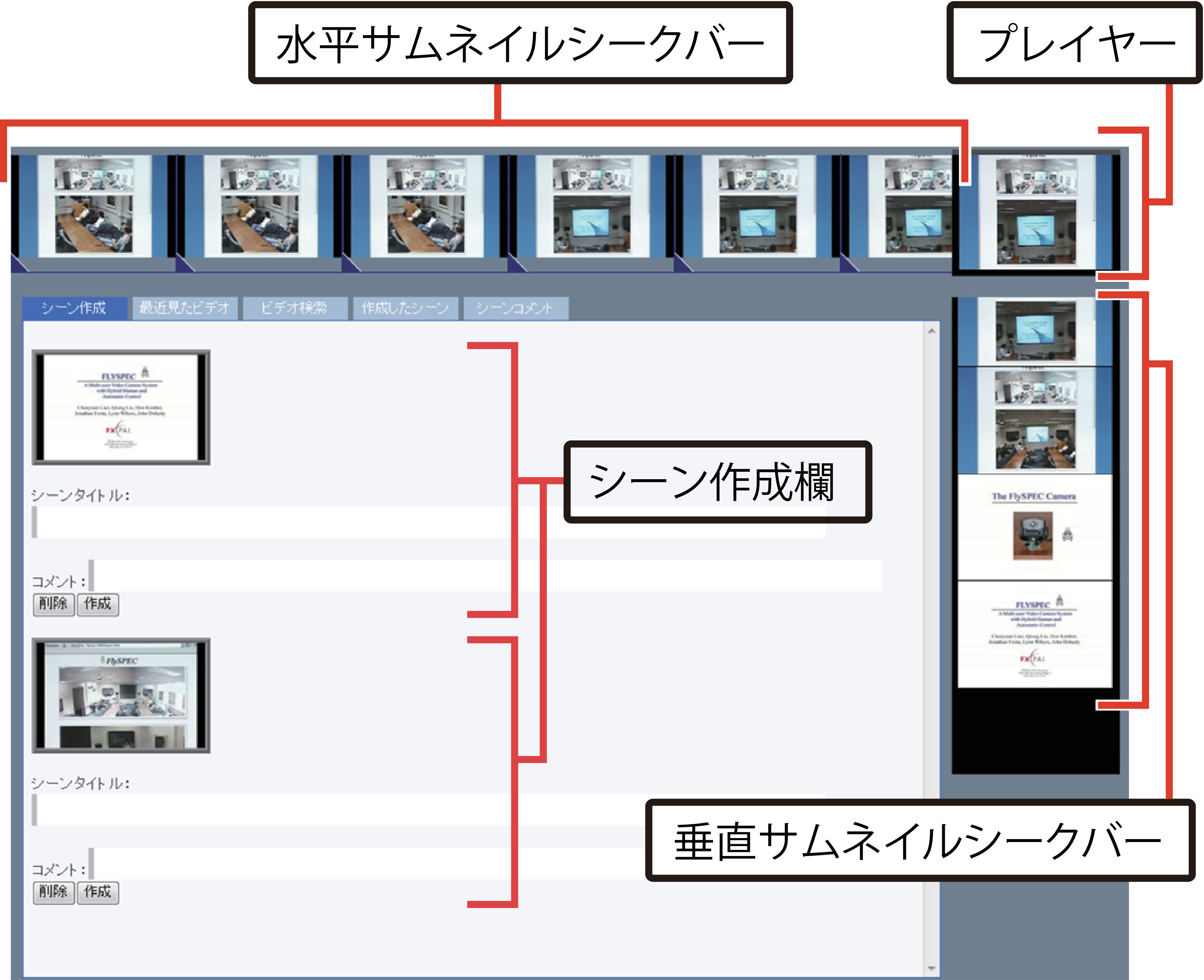
図3.3: 映像シーンを引用するインタフェース
図に映像シーン引用を行うためのユーザインタフェースを示す.引用を行うためには,まず引用したいシーンを含む映像コンテンツを,ユーザの閲覧履歴やキーワード検索を用いて読み込む.画面は,右上に配置された映像を再生するためのプレイヤー,そして,プレイヤーの水平方向・垂直方向に一定時間ごとのサムネイル画像を並べたシークバー(以下,と呼ぶ)によって構成される.映像の再生を開始すると映像に同期して左右,上下にそれぞれサムネイル画像が移動する.また,サムネイル画像をドラッグすることでプレイヤーをシークできる.水平サムネイルシークバーは1秒間隔でサムネイル画像が表示され,引用する映像シーンを決定するために利用する.垂直サムネイルシークバーは映像を素早くシークするために利用する.
シークして引用したいシーンを発見したら,水平サムネイルシークバー上で開始フレームと終了フレームを選択することで引用するシーン区間を設定できる.引用するシーン区間を決定すると,映像シーンがシーン作成欄に追加されタイトル入力欄が表示され,タイトルを設定するとシーンの作成が完了する.これにより,映像シーンの開始・終了時間,タイトルを獲得できる.
すでに定義されたシーンはサムネイルシークバー下部に表示され,自分で定義したシーンと同じように,他のユーザが定義したシーンに対して新たなアノテーションを付与することができる.
定義したシーンは,TDAnnotatorと同様に指し先のないアノテーションを防ぐため,他人がアノテーションを付与していたり,後述の仕組みで関連付けされている場合には削除できない.
データベースには,シーンの開始時間,終了時間,タイトル,シーンを含む映像のID,全システム共通のアノテーション作成者のIDが映像シーンの情報として記録される.
3.4.3 論文と映像の部分要素の関連付け
本研究では,論文・映像の部分要素間の関係情報を獲得するための仕組みとして,引用アノテーションシステムを利用した.このシステムは,ユーザがスライドや,そのスライドを利用して発表した会議において他者から得られた発言(映像とテキストによって表される)を引用しながらメモを書き,メモの内容を振り返ったり俯瞰したりしながら自身の活動をよりよくしていくためシステムである.ユーザはクライアントアプリケーションを自身のPCにインストールして利用する.本研究では,引用アノテーションシステムで引用できるコンテンツとして新たに映像と論文を追加し,引用する映像と論文の部分要素に関するメタ情報を蓄積しているTDAnnotator(論文),Synvie(映像)などの各システムから,コンテンツの部分要素を読み込み,必要な部分を引用したメモを作成できる.ユーザが同じメモにコンテンツの部分要素を引用(これをと呼ぶ)したという情報を用いることで,部分要素間の関係を獲得する.
部分要素を管理する各システムには,引用アノテーションシステムにコンテンツの部分要素を読み込むために,部分要素一覧画面が用意されている.引用アノテーションシステムから「映像シーンの検索」「論分部分の検索」メニューを選択すると,ブラウザが起動して各システムの一覧画面に遷移する.一覧は,コンテンツのタイトル,部分要素に付与されたアノテーション本文などのテキストを対象とした全文検索によって絞り込むことができる.そして,部分要素ごとに「引用」ボタンが設置されており,このボタンを押すと,クライアントアプリケーションが立ち上がって,部分要素が読み込まれノードとして表示される.
図に引用アノテーションシステムで表現されるノードの種類を示す.あるコンテンツの部分は,コンテンツを表すコンテンツノードとそれに接続された部分要素ノードによって表現される.これは,1つのコンテンツから複数の部分を引用した場合に,それらが元は1つのコンテンツから引用されたことを明示するためである.映像シーンは,その映像シーンを含む映像ノードに接続された部分要素ノードとして表現される.映像ノードをダブルクリックするとSynvieで再生され,映像シーンノードの場合は,映像中の特定のシーンのみが再生される.論文部分も映像シーンと同様に,論文ノードに接続された部分要素ノードとして表現され,論文ノードをダブルクリックすると該当論文がTDAnnotatorで表示され,論文部分ノードの場合にはTDAnnotator上で論文部分がハイライトされる.
次に,図に,読み込んだコンテンツの部分要素を引用してメモを作成する手順を示す.ユーザは,引用アノテーションシステム上で引用したい映像シーンおよび論文部分ノードを選択して(図(1)),コンテキストメニューを開き「メモ」を選択する(図(2)).すると,メモのタイトルを入力するフォームが表示され(図(3)),ユーザがタイトルを入力し,決定することでメモノードが作成される(図(4)).作成されたメモノードをダブルクリックすると,内容を編集でき,必要に応じて映像シーンや論文部分ノードの追加・削除を行うことができる.
データベースには,メモのテキスト,関連付けられた部分要素のURIの集合,それぞれの部分要素を包含するコンテンツのURIが全システム共通のアノテーション作成者のIDと関連付けられて保存される.引用アノテーションシステムは個人の研究活動を支援するためのシステムであるため,作成されるメモは個人的な内容を含む可能性があり,メモのテキスト内容は共有するのに適さない.そのため,メモに引用されたノード間の関係情報のみを他のユーザと共有する.
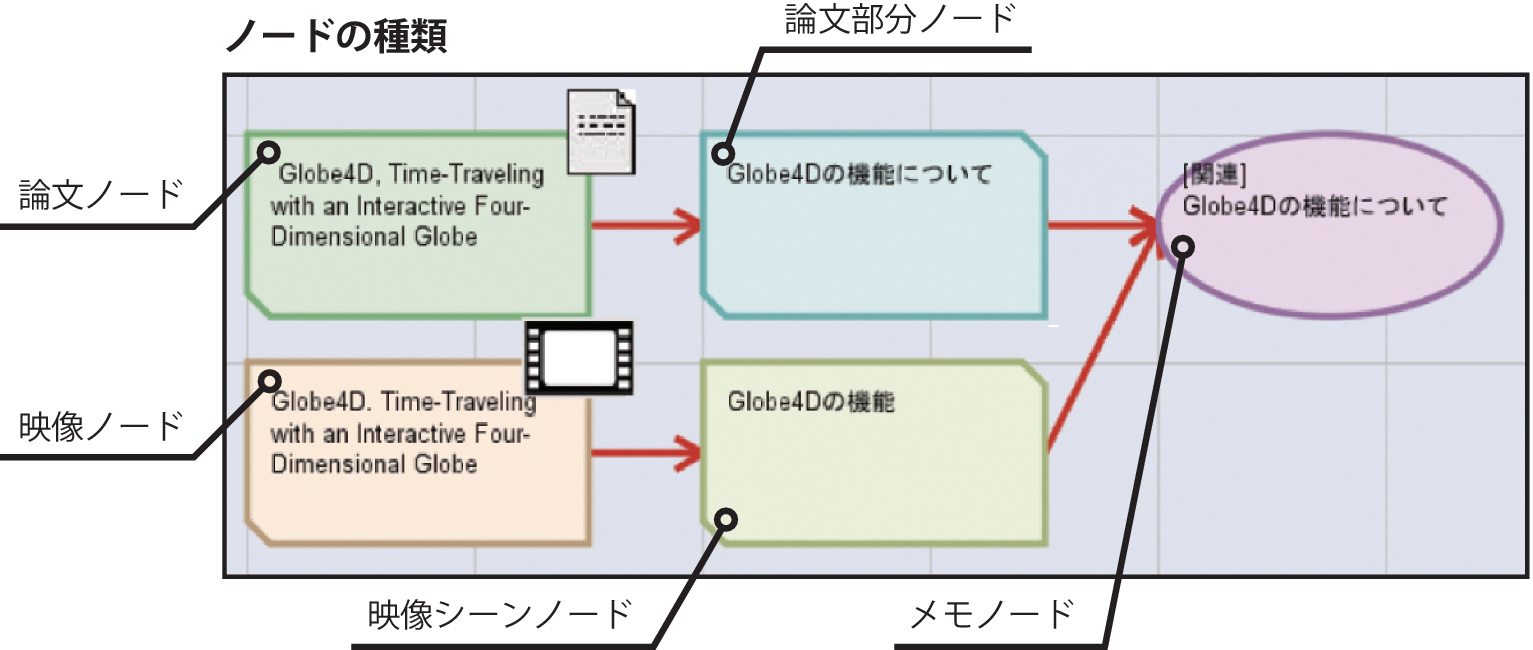
図3.4: 引用アノテーションシステムにおけるノードの種類
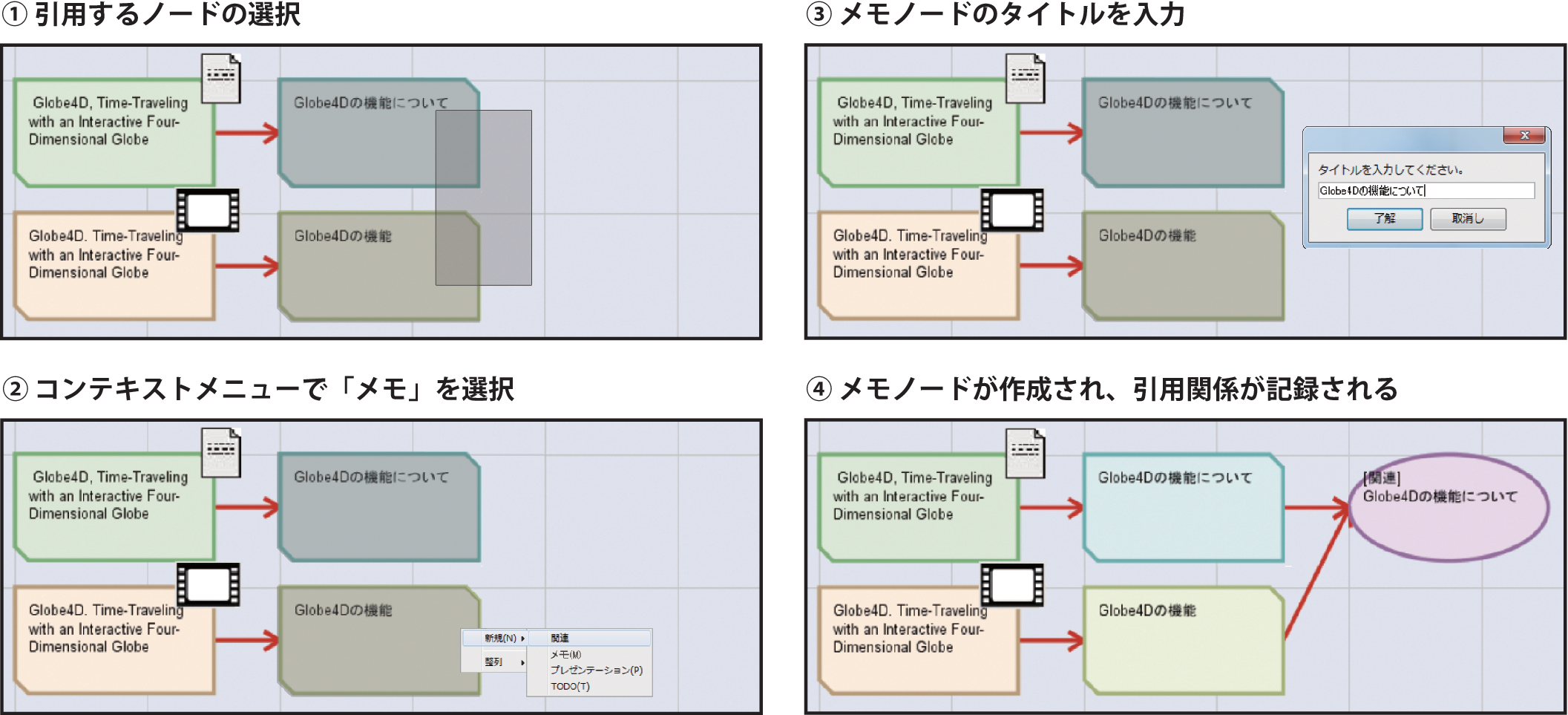
図3.5: 引用アノテーションシステムにおける関連付け手順
3.5 論文読解支援システム Docvie
これまでに説明した仕組みを利用して取得した,映像の部分要素,論文の部分要素,そして部分要素間の関係情報を利用して論文の効率的な読解を支援するシステム,Docvieについて述べる.
3.5.1 Docvieのコンセプト
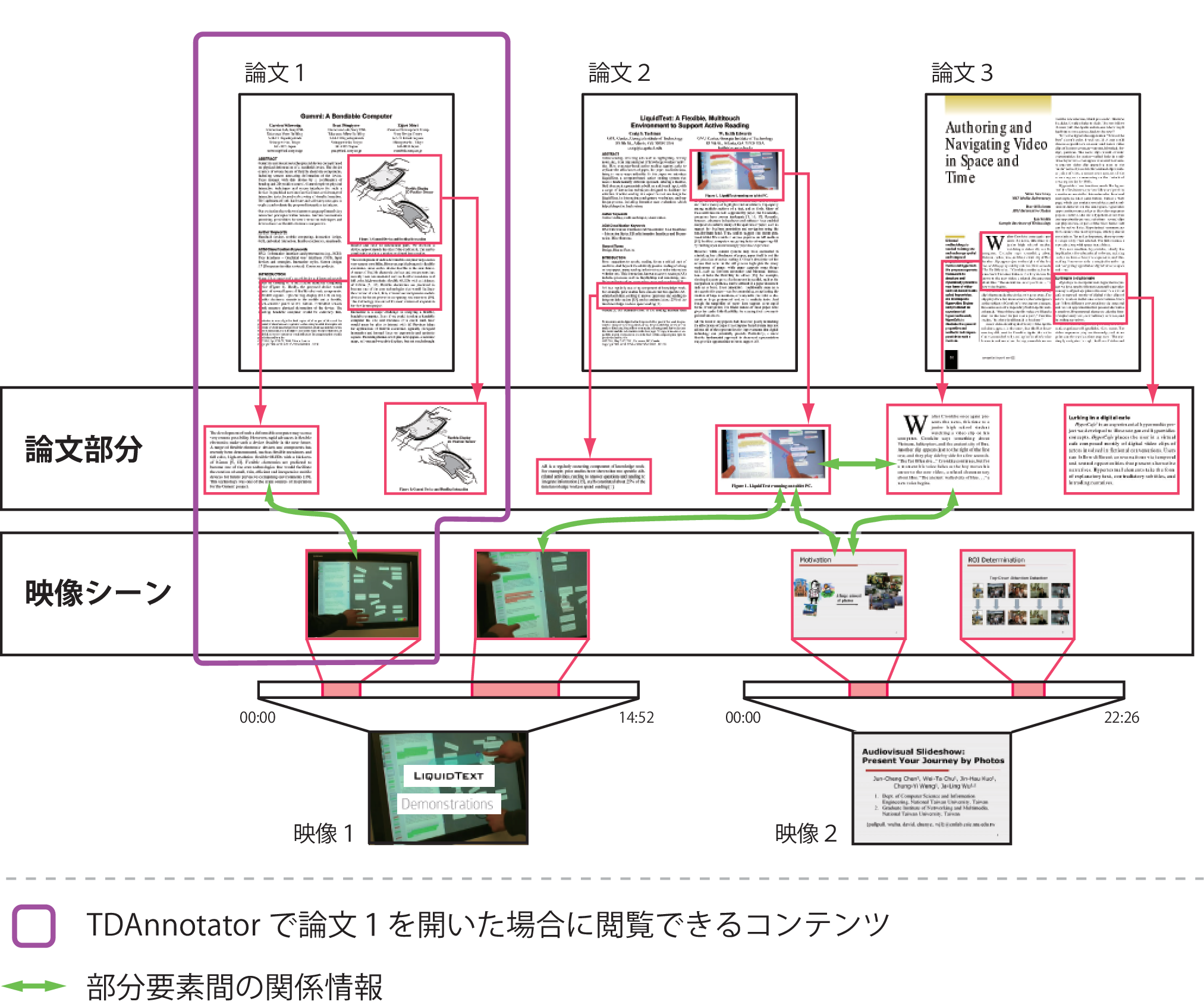
図3.6: 論文と映像の部分要素間の関係の模式図
論文の読解を支援するためには,その論文に関係するコンテンツを効率的に閲覧できるようにする必要がある.Docvieでは,図に示すどのコンテンツから閲覧を開始しても,部分要素間の関係を辿ることで,すべてのコンテンツを閲覧することができる仕組みを実現した.
Docvieでは論文だけでなく,論文・映像をユーザが注目しているコンテンツの種類に応じてインタフェースを切り替えて閲覧できる.論文に注目している場合には,論文の読解中に関係情報を利用して,論文部分に関連した映像シーンなどを視聴しながら閲覧できる.また,映像に注目している場合には,映像の視聴中にシーンに関連する論文部分などを参照しながら閲覧できる.それぞれのコンテンツの種類に応じたインタフェースを切り替えて閲覧することで,そのコンテンツに対する理解を深めることができると考えられる.
この2種類の閲覧インタフェースを,論文を主として閲覧する,映像を主として閲覧すると呼ぶ.
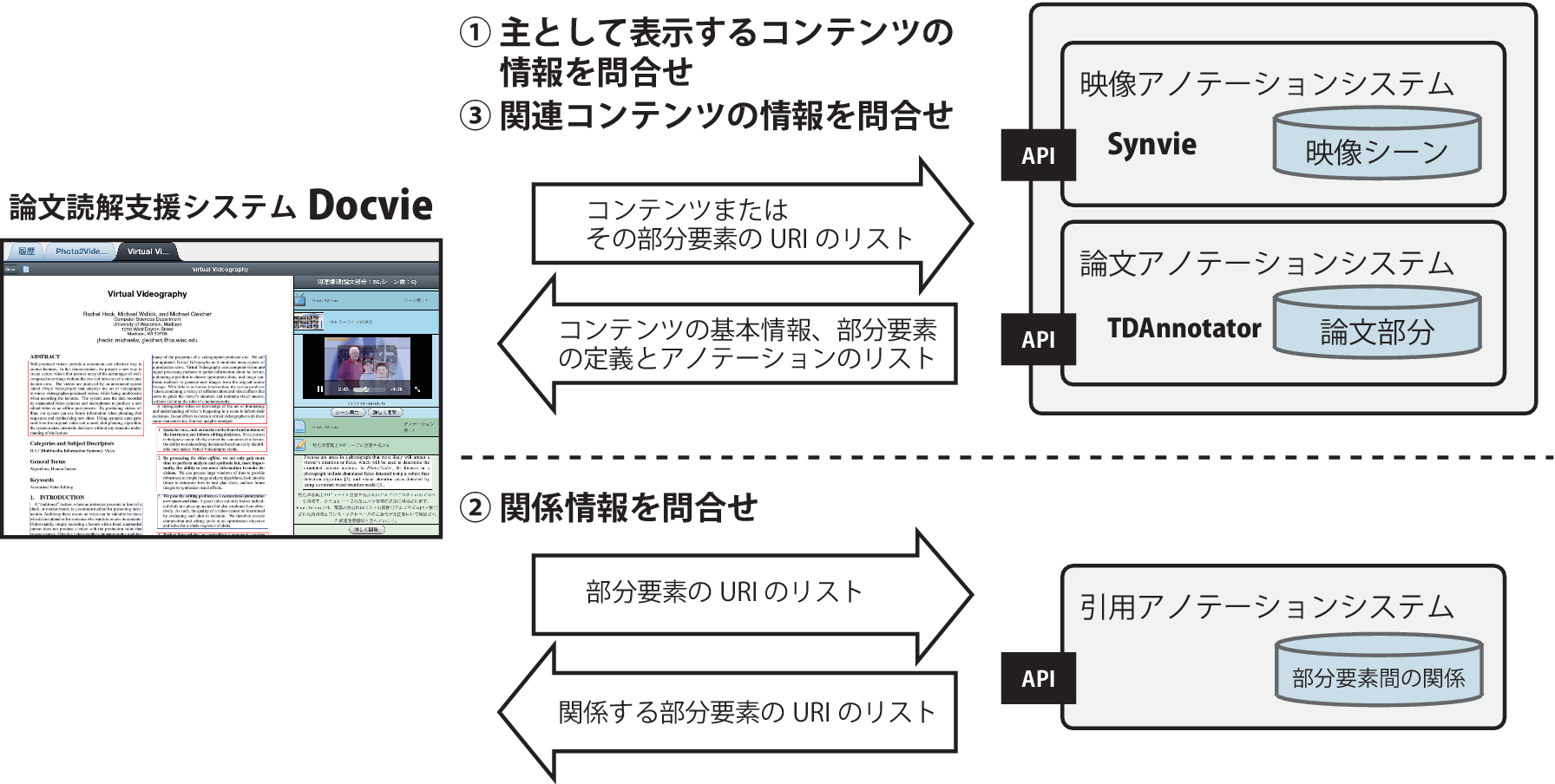
図3.7: Docvieにおけるデータ取得の流れ
Docvieにおけるデータ取得の流れを図に示す.まず,ユーザがコンテンツを読み込むと,Docvieはコンテンツの種類(論文,映像)に応じてTDAnnotator,Synvieが提供するAPIに,そのコンテンツのURIをキーにコンテンツの情報を問い合わせる(図(1)).APIはそのコンテンツの基本的な情報(論文の場合は画像の情報やタイトル,著者など.映像の場合は映像ストリームのURIやタイトル,作者など)と共に,コンテンツの部分要素の情報(論文の場合は矩形範囲が定義された論文のページ番号と位置・サイズの集合,映像の場合はシーンの開始・終了時間)と,その部分要素に付与されたアノテーション(アノテーション本文,アノテーション作成者のIDなど)のリストを返す.次にDocvieは,取得した部分要素のURIのリストをキーに,引用アノテーションシステムに関係情報を問い合わせる(図(2)).引用アノテーションシステムは,与えられた部分要素に関連付けされた部分要素のURIのリストを返す.Docvieは,受け取った部分要素のURIのリストをコンテンツの種類ごとに分けて,TDAnnotatorおよびSynvieにそれぞれ問い合わせる(図(3)).それぞれのシステムは部分要素とそれを含むコンテンツの情報を返す.Docvieは,このようにして取得したデータを用いて,ユーザが閲覧しようとしているコンテンツに応じてユーザインタフェースを変更する.
以降,それぞれのインタフェースについて詳述する.
3.5.2 論文中心モード
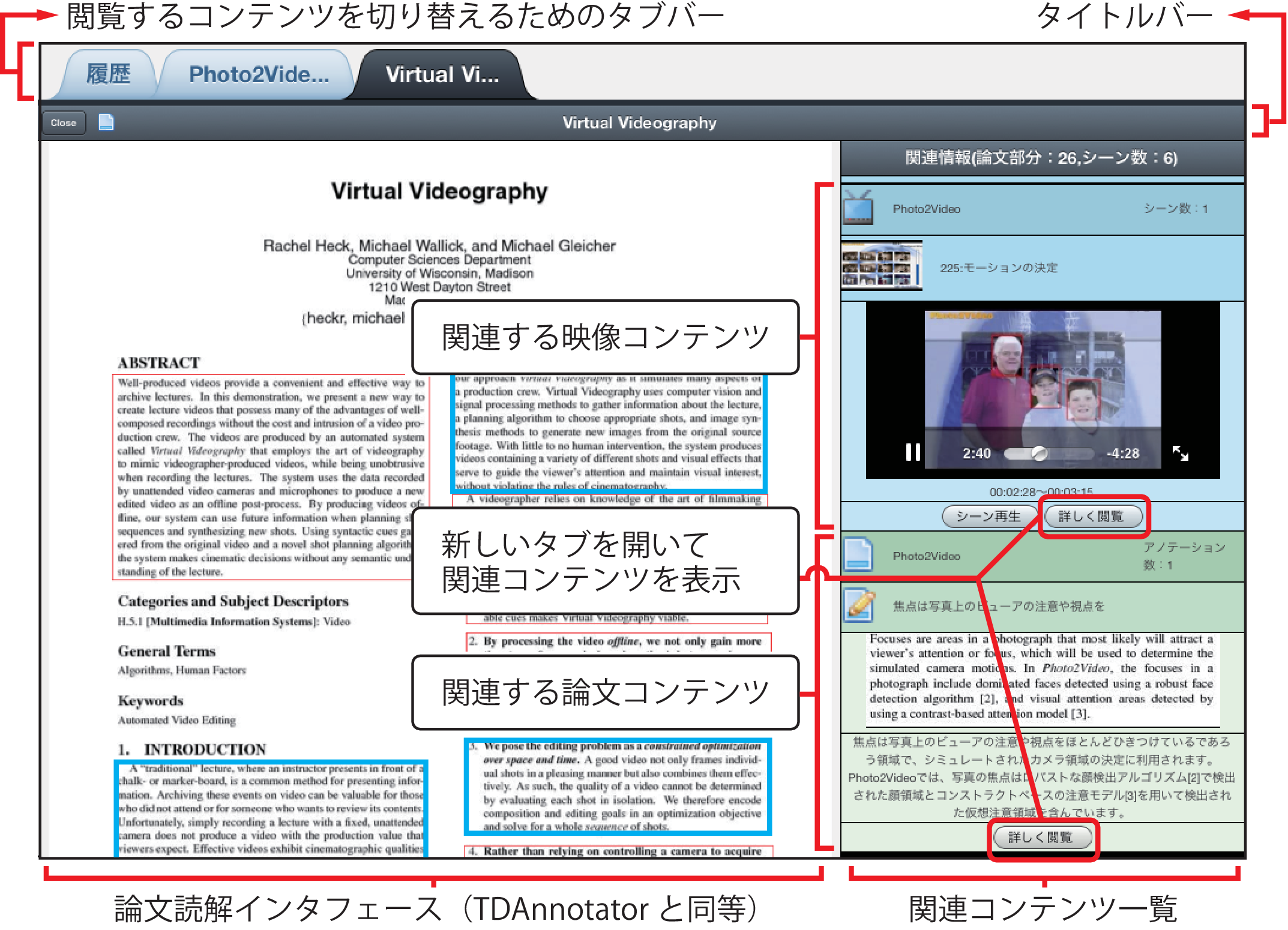
図3.8: Docvieの論文中心モードの画面例
論文中心モードの画面を図に示す.画面の上部には,現在開いている論文を含むコンテンツがタブとして配置されている.論文中心モードで表示しているコンテンツだけでなく,後述する映像中心モードで開かれているコンテンツもタブとして表示され,タブを切り替えながら閲覧できる.タブバー直下のタイトルバーには,現在開いている閲覧画面を閉じるためのボタン,閲覧モードを表わすアイコン,コンテンツのタイトルが表示される.そして,画面の左側にTDAnnotatorと同等の論文閲覧インタフェースが,右側に論文に関連するコンテンツの一覧が表示される.この画面では,主として閲覧する論文を,関連コンテンツを参照しながら読解することで理解を深めることを支援する.
論文上には,TDAnnotatorでアノテーションが付与された論文の部分要素を矩形で表現している.TDAnnotator上での表示と同じく,アノテーションが付与された論文部分は赤い枠線の矩形(論文読解インタフェース上の細線の矩形)で,映像シーンが関連付けられている論文部分は青い枠線の矩形(同,太線の矩形)で表示される.これらの部分は,ユーザによって情報が付与されている部分であり,付与されている情報を読解の手がかりとして参照することで,論文に対する理解を深めることができると考えられる.論文上の矩形を選択すると,関連コンテンツ一覧の中にある,選択した論文部分に関連するコンテンツにフォーカスし展開表示される.
関連コンテンツ一覧には,閲覧している論文に関連するコンテンツが,コンテンツの種類を把握しやすいように種類ごとに色分けされて表示される.映像が青色(関連コンテンツ一覧の上側)で,論文は緑色(同,下側)である.
関連コンテンツ一覧に表示される関連する論文の情報は,初期状態では,それぞれの論文のタイトルが表示される.タイトルを選択すると,その論文の部分要素に付与されたアノテーションの書き出しが一覧表示される.さらに部分要素を選択すると,その部分要素の内容とそこに付与されたアノテーションが表示される.またそれぞれに「詳しく閲覧」ボタンが設置されており,このボタンを押すと部分要素を含む論文が新たなタブとして追加される.
また,関連する映像の情報は,初期状態では,それぞれの映像のタイトルが表示される.タイトルを選択すると,その映像に含まれるシーンのタイトルとサムネイルが一覧表示される.一覧の中から映像シーンを選択すると,その映像シーンのタイトルとシーンを再生するためのプレイヤーが表示される.プレイヤー下部の「シーン再生」ボタンを押すことで映像をシーンから再生することができる.論文の部分要素と同じく「詳しく閲覧」ボタンが設置されており,このボタンを押すことで,そのシーンを含む映像全体を閲覧する画面が新たなタブとして追加される.
このように,関連コンテンツ一覧を段階的に展開できるようにすることで,論文に多くの情報が関連付けられた時に,関連コンテンツを俯瞰し,どの情報を閲覧するかが選択しやすくなると考えられる.論文閲覧時に論文に関連付けられた情報を効率よく閲覧できるようにすることで,関連する情報を探す負担を軽減し,論文読解の効率を向上させることができる.
3.5.3 映像中心モード
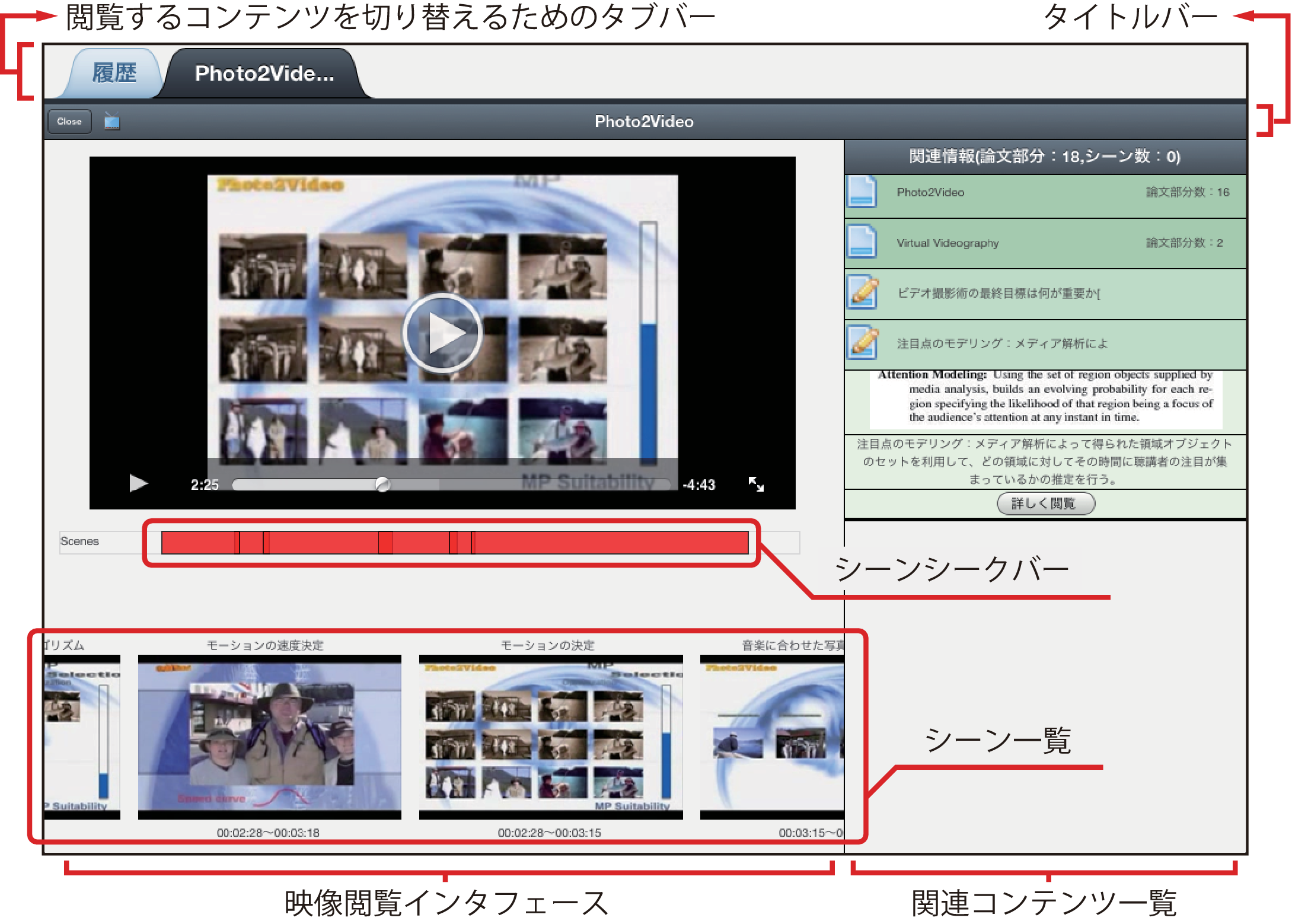
図3.9: Docvieの映像中心モードの画面例
映像中心モードの画面を図に示す.画面左側に映像閲覧インタフェースが表示されるほかは,論文中心モードと同様である.画面右側の関連コンテンツ一覧には,映像に関連した情報が一覧表示される.この画面では,主として閲覧する映像を,関連コンテンツを参照しながら視聴することで理解を深めることを支援している.
映像閲覧インタフェースは,映像のプレイヤー,その直下のシーンシークバー,最下部の映像に含まれるシーン一覧で構成される.シーンシークバー上には映像の再生時間が表示される.また,映像のどの部分がシーンとして定義されているかをシーンシークバー上に表現することで,映像のどの部分がシーンとして定義されているかを俯瞰することができ,ユーザが映像全体の中から映像シーンを選択する手がかりとなる.
シーンシークバーの下部には,映像に含まれているシーンのリストが表示される.リストには,Synvieで映像シーンを作成する際に付与したシーンタイトルとシーンの代表サムネイル,シーンの開始・終了時間が表示される.サムネイルを選択することで,対応するシーンがプレイヤーで再生される.また,サムネイル画像を表示することで,ユーザは,映像を再生する前にシーンの情報を閲覧することができるため,映像へのアクセスを効率的に行うことができると考えられる.ユーザは,シーンシークバーとシーン一覧を用いることで,映像にどのようなシーンが含まれているかを俯瞰することができる.
論文中心モードでは,論文上に表示された矩形を選択することで関連する情報が自動的に展開されるが,映像中心モードでは,映像の再生時間に応じて,その時間を含むシーンに関連するコンテンツが展開される.映像の再生に同期して関連コンテンツを自動的に提示することで,ユーザは視聴中のシーンについての理解を深めることができると考えられる.
3.6 論文読解支援システムDocvieの評価実験
前述した,Docvieが提供する論文読解のためのインタフェースの有効性を確かめるため評価実験を行った.Docvieの比較対象としてTDAnnotatorを利用できるようにするため,TDAnnotatorを用いて映像を閲覧できるようにした.図に示すように,節の方法で映像シーンが関連付けられた論文部分は青色の枠線(図中では,論文左上の太線の矩形)で表示される.通常の論文部分と同様に,この部分をクリックしてアノテーションを開くと,映像シーンと論文部分の情報が表示される.この提示方法は単純なもので,提示された映像シーンに対して別の論文の部分要素が関連付いていたり,その映像シーンを含む映像の他の映像シーンに,別の論文部分が関連づいていたりしても,それをユーザが知ることはできない.
例えば,図に示すように,ユーザが論文1を閲覧しているときに,論文1の部分要素に関連付けられた映像1の部分要素を閲覧することはできるが,同じく映像1に関連付けられている論文2を,映像1との関係を辿って閲覧することはできない.Docvieでは提示された関連コンテンツを辿って他の映像や論文を閲覧することができ,ユーザが注目するコンテンツの種類に応じた適切なインタフェースを提供している.
本実験では,TDAnnotatorとDocvie,動画と映像の閲覧に利用される一般的なツール(本実験では,GoodReader(http://www.goodiware.com/goodreader.html)と呼ばれるPDFとMPEG-4形式の動画を別々に閲覧できるソフトウェアを用いた)の3つのソフトウェアを被験者実験を通して比較することで,Docvieで実現した機能が有効に働いているかどうかを,読解効率(回答時間および正答率)の観点から検証した.
3.6.1 実験の内容

図3.10: 実験に用いた大問の例
本実験は,被験者に論文と映像を閲覧してもらい,その内容に関する問題を解いてもらう形式である.論文と映像の閲覧にはタブレット型デバイスを用い,GoodReader,TDAnnotator,Docvieのいずれかのソフトウェアを用いた.
被験者に提示した問題は,回答に際して被験者に提示される複数の論文と映像の内容に対して「正しい・間違い」で答えることができ,提示された論文の中に答えの根拠となるパラグラフが必ず含まれるように作成した.この問題それぞれをと呼び,同じ論文に対する小問を3問あわせたものをと呼ぶ.図に被験者に提示した大問の例を示す.大問3問あわせたものをと呼び,3種類用意した.また,アノテーションが付与されている部分だけを読めば答えられる問題とならないように,根拠となるパラグラフがTDAnnotatorとDocvieで表示される,アノテーションが付与されていることを表す矩形の文章中には含まれないようにした.
また,被験者に提示する論文と映像は内容的に関係するもので,大問ごとに異なる論文と映像を用いた.論文は情報科学系のHuman-Computer Interfaceに関係する英語論文で,大問ごとに2本以上で合計のページ数がA4サイズで10ページとなるように選択した.映像は論文に書かれている内容に関するデモ映像や発表映像で,大問ごとに複数の映像を提示する.映像の長さは平均5分35秒(3分35秒?9分21秒)であった.また,論文と同じく映像の言語も英語である(ただし,問題文は日本語).
被験者は,実際に当該分野の論文を読解する必要がある情報科学系の大学4年生5名,修士課程3名の計9名で,TOEICスコアの平均は585.5(465-715)であった.また,実験で使用するタブレット型デバイスは被験者全員が日常的に利用しており操作に慣れている.9名をTOEICスコアと学年を参考に1グループ3名の3グループに分けた.
3.6.2 実験の手順
実験はグループごとに,表に示す順番と問題セットで行った.それぞれのソフトウェアを用いた実験の前に,実験に利用しない問題セットを用い,5分間,ソフトウェアの使い方をレクチャーした.
その後,事前知識をできるだけ均一化することと,動画の閲覧中に問題に回答することを防ぐ目的で,出題した問題に関係する映像シーン(平均46秒,31秒?1分28秒)を最初から最後まで閲覧してもらった.
次に,大問1問について10分の制限時間を設定し,それぞれのソフトウェアを用いて問題に回答してもらった.これは,被験者に可能な限り迅速に問題に回答する事を促すためである.また,小問への回答は「正しい・間違い」の答えと同時に,その回答の根拠となるパラグラフを示してもらった.
3つの手法それぞれに,上述の方法で問題セット,大問3問を解いてもらい,その回答とかかった時間を記録した.
3.6.3 実験結果と考察
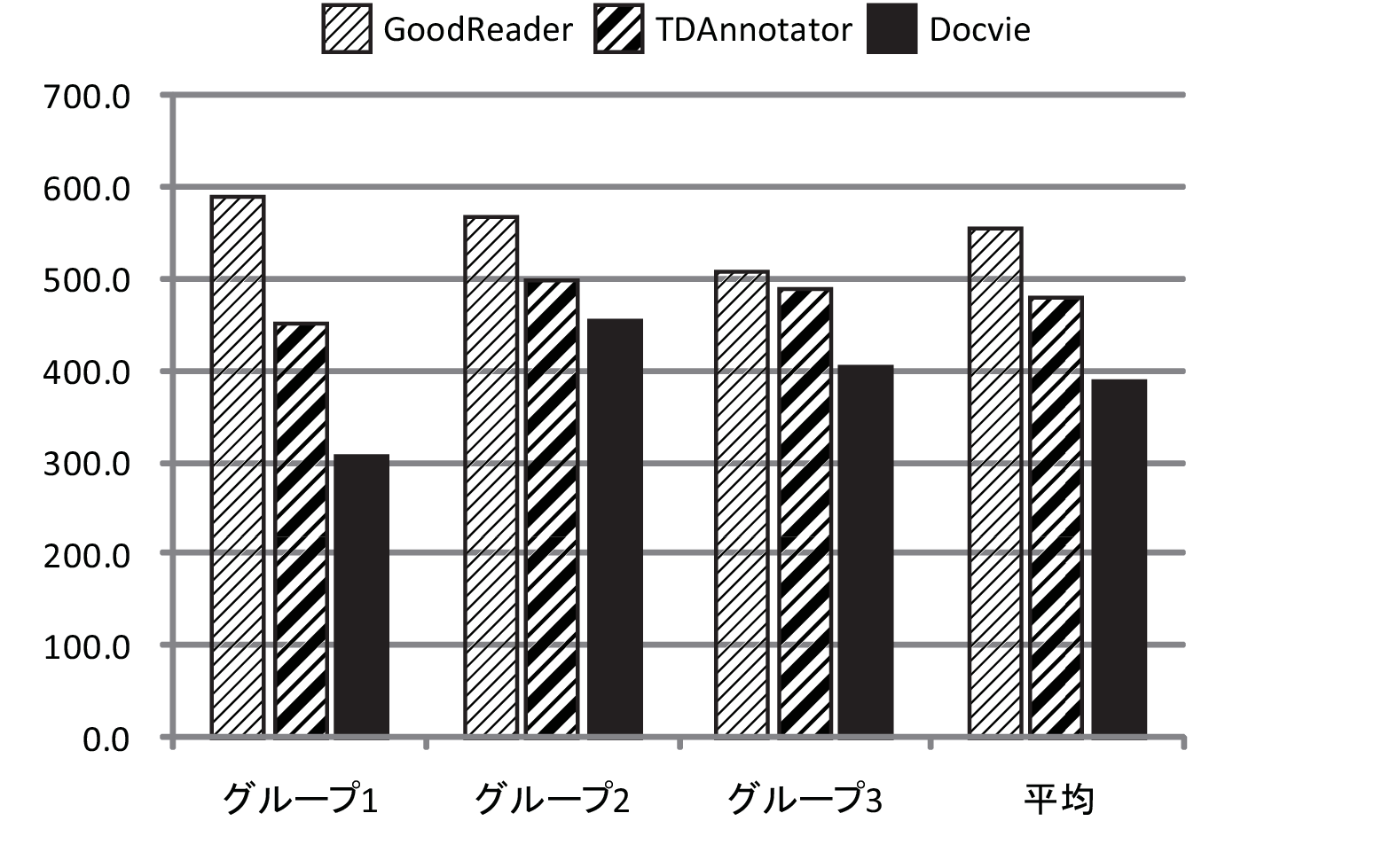
図3.11: 大問の回答にかかった時間(単位:秒)
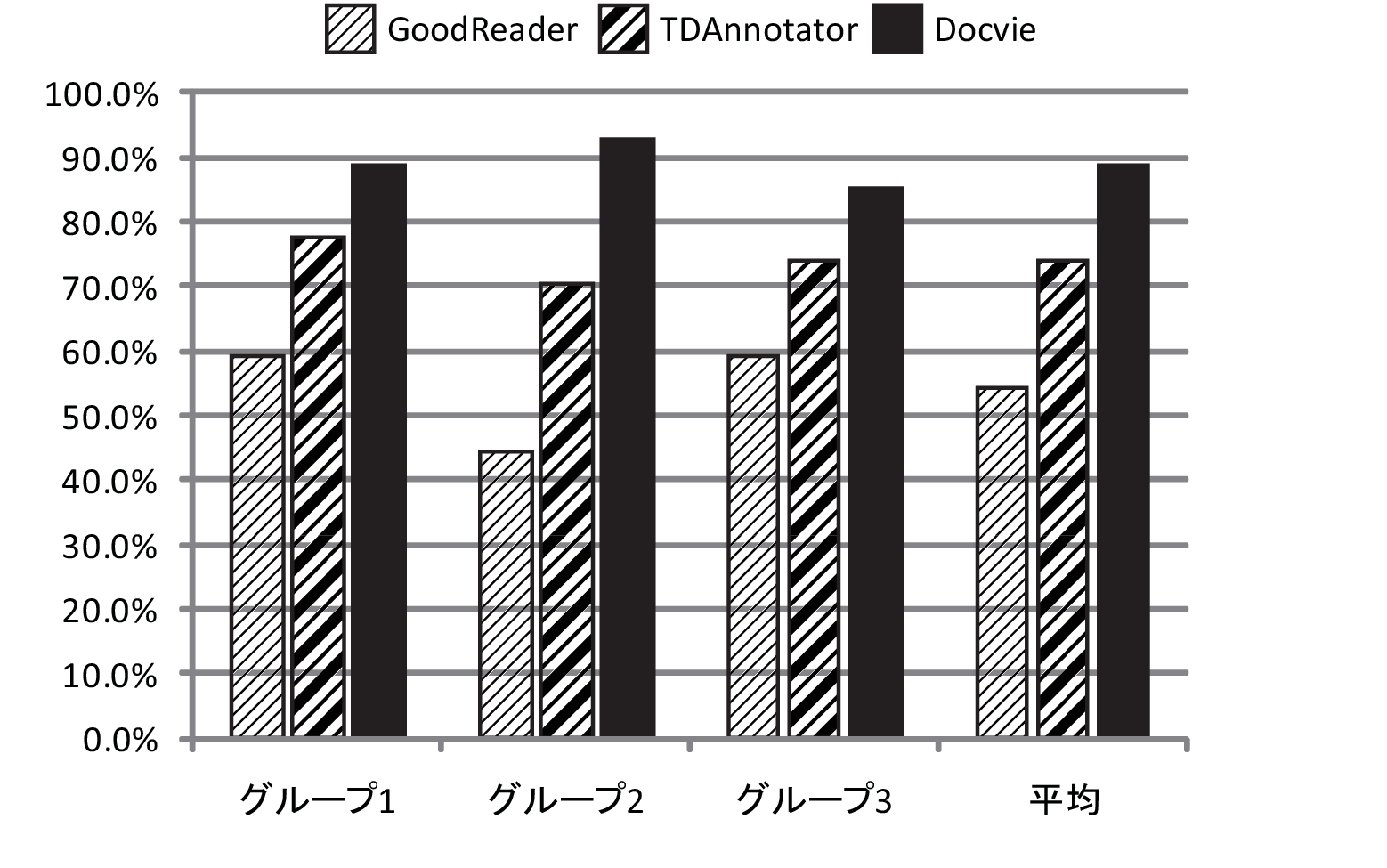
図3.12: 正答率
上述した条件の下で行った実験の結果について述べる.本実験では,Docvieの有効性を読解効率の観点から評価するために,大問の回答にかかった平均時間と,問題セットごとの正答率を算出した.
それぞれの結果を示す前に,3手法の間で大問の回答時間と正答率の平均値に差があるかどうかを分散分析で確認した結果を表に示す.結果から,大問の回答にかかった平均時間と正答率の両方で手法間に有意差(p<0.001)が認められた.そこで,Tukeyの方法を用いて多重検定を行った.その結果を表に示す.以降,この分析結果に触れながら結果について考察する.なお,分散分析,多重検定にはR 2.15.0(http://www.R-project.org)を用いた.
図及び表に,大問の回答にかかった平均時間を示す.大問の回答にかかった時間は,映像または映像シーンを閲覧し終わって大問への回答開始の合図とともに計測した.結果を見ると,GoodReaderを用いた場合に比べてTDAnnotatorでは75.6秒,Docvieでは171.3秒早く回答することができている.表に示した多重検定の結果から各手法間に有意差が認められた.なお,10分の制限時間内に大問に答えられなかった場合には600秒として計算している.制限時間内に答えられなかった大問の割合を表に示す.GoodReaderを用いた場合,制限時間内に大問に回答できなかった割合が5割を超えている.
このような結果が現れたのは,GoodReaderでは論文部分がハイライトされていないため,何も手がかりのない状態でどこが重要な部分かが分からず,論文を最初から読んだためだと考えられる.また,TDAnnotatorとDocvieで差が出たのは,Docvieではどの部分が重要かというだけでなく,常に関連コンテンツが表示されている状態で閲覧できるようになっていたため,複数の論文を行き来しながら答えを探すことができ,答えに到達するまでの時間が短くなったと考えられる.
また,表よりグループ間に有意傾向(p=0.097)が見られた.この傾向は,グループ1がDocvieを用いて問題セット3に取り組んだとき,制限時間内に回答できなかった問題がなかったためだと考えられる.表では問題セット間の大問の回答にかかった平均時間の有意差は見られなかった(p=0.285)が,問題セット3が他の問題に比べて容易であった可能性がある.問題セットの難易度,個人の能力差についてより詳細に分析するためには,実験の規模を拡大する必要があると考えられる.
図及び表に,問題セットごとの正答率を示す.正答率は,ある問題セットに対する被験者の正答数を問題セットに含まれる小問題の数で割ったものである.ここで,正答としたのは,制限時間内に回答が行われ,問題に対する答えが合っていて,かつ被験者が示した回答の根拠となるパラグラフ中に適切な記述が含まれている場合とした.これは,誤読している場合や勘で答えている場合を不正解とするためである.
正答率も,Docvieを用いた場合が最も高く,続いてTDAnnotator,最後にGoodReaderの順であった.表から3手法の正解率の平均値に5%水準で有意差が認められた.GoodReaderを用いた場合の正答率が5割程度と低いのは,制限時間を超えてしまうことが多かったこと,手がかりが少ないために根拠となるパラグラフを探すことが難しかったことが挙げられる.TDAnnotatorとDocvieの間で差がみられたのは,Docvieでは関連コンテンツにアクセスしやすく,映像中心モードで論文に比べて把握しやすい映像を閲覧し,それを手がかりに関連する論文部分を読むことができたためだと考えられる.
以上の結果から,関連するコンテンツを利用して論文読解を支援するシステムとして,DocvieはTDAnnotatorと比較して,効率的に内容を把握できると考えられる.
3.7 本章のまとめ
本章では,まず,知識活動において生み出され利用されるコンテンツについて,「知識活動を通じて生み出され,また利用されるさまざまな情報」と定義した.そして,コンテンツが知識活動の中でどのように作られたか使われたか,という文脈情報が知識活動を円滑にする上で重要な役割を果たしていることを述べた.また,文脈情報に加えて,コンテンツに対する部分要素の定義をメタ情報と呼び,蓄積されたメタ情報を利用することで検索・要約などの高度利用が可能になることを述べた.
メタ情報の応用例として,論文と映像の部分要素に対するメタ情報を利用して効率的な論文読解を実現するインタフェースについて述べた.具体的には,論文と映像の部分要素に対するアノテーションの獲得と蓄積を行うための仕組み,部分要素間の関係情報を取得するための仕組みを,先行研究を拡張することで準備した.そして,獲得したメタ情報を利用するシステムの一例として,論文読解支援システムを提案した.提案システムは,メタ情報を用いてユーザが閲覧中のコンテンツに関連する他のコンテンツの一部を提示し,その理解を促進する仕組みを実現した.さらに,評価実験を行って,提案システムを用いることで効率的にコンテンツの内容を把握できることを確認した.このことから,知識活動の中で獲得できるメタ情報を適切に応用することで,多様な応用を実現できると考えられる.
Docvieのように複数のコンテンツ,あるいはその一部分を編纂してユーザーに提示する仕組みは多数存在する.近年では,Webサービスが提供するAPIやコンテンツを組み合わせて,ユーザにとって価値のある新たなコンテンツを自動的に生成するコンテンツマッシュアップと呼ばれる技術が一般化している.また,基礎技術として用いているHTMLは,テキスト情報と画像や映像を組み合わせるための仕組みである.さらに,部分要素を定義し,それらを適切に組み合わせる研究も多数行われている.Docvieの新規性は,論文読解という目的に絞ったこと,蓄積されたメタ情報を利用して論文読解のためのインタフェースを実現し,被験者実験を行って有効性を確認したことにある.
4 継続的ミーティング支援システム
4.1 システム概要
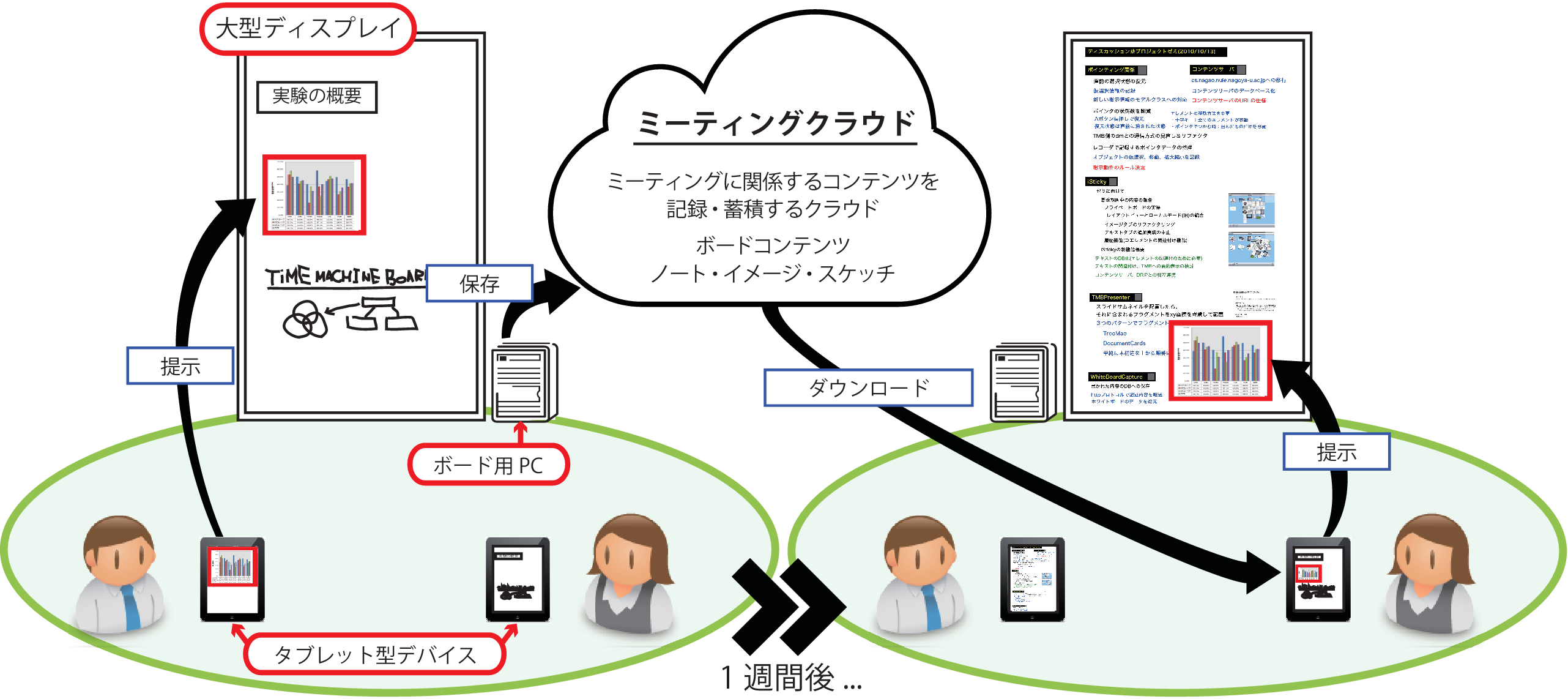
図4.1: システム概要
本章では,章で述べた継続的ミーティングの問題点とそれに対するアプローチを具現化した,継続的ミーティング支援システムについて述べる.
-
ミーティング内容の適切な記録が難しい
-
過去のミーティング内容が活かされない
-
資料の準備に手間がかかる
「コンピュータを用いた検索や要約などの実現に必要な情報を獲得するために,人間に新たな負荷をかけない仕組み」というコンセプトに基づいて,情報的に拡張されたボードと,個人の知識活動の中で生み出され利用されるコンテンツを記録するためのクラウドを実現することで,上述の3つの問題にアプローチする.
継続的ミーティング支援システムは,TimeMachineBoardと呼ばれるミーティング内容を記録するための仕組みと,iStickyと呼ばれる個人の活動に関わるコンテンツを集約しTimeMachineBoardに情報を入力するためのクライアントソフトウェアによって構成される.図に本システムの概要を示す.TimeMachineBoardは,大型ディスプレイをボードとして用いる.また,iStickyはタブレット型デバイスで動作する.TimeMachineBoardとiStickyは,互いに協調的に動作してミーティングを支援する.iStickyを用いて作成されたコンテンツ,およびTimeMachineBoardを用いて行われたミーティングの内容は,すべてミーティングクラウドに記録される.
継続的ミーティングシステムを利用するユーザは,iSticky,TimeMachineBoardおよびミーティングクラウドに共通の識別子によって特定することができ,それぞれの仕組みで記録されたログをユーザごとに利用することができる.なお,ミーティングクラウドに記録されるコンテンツの情報は,ユーザが操作をしない限りそのユーザのみが閲覧できるようになっている.
4.2 iSticky
iStickyは,大きく分けて2つの機能を持つ.ひとつは,ナレッジワーカーの日常的な知識活動の中で生み出されるコンテンツを作成・管理する機能である.そして,もうひとつは,情報的に拡張されたボードであるTimeMachineBoardとの連携機能である.iStickyは,タブレット型デバイスで動作し,ナレッジワーカーが日常的に持ち歩いて利用することを想定している.また,iStickyはミーティングクラウドと接続されており,作成されたコンテンツはミーティングクラウドに保存することができる.ここでは,知識活動の中で生み出されるコンテンツを記録する機能について述べ,TimeMachineBoardとの連携機能については節で述べる.
iStickyで作成・管理できるコンテンツは,テキストのメモ,画像,手描きのスケッチ,TimeMachineBoardを用いて作成されたボードコンテンツである.iStickyはタブレット型デバイス用の単一のアプリケーションとして実現されており,作成・管理するコンテンツごとに機能が分かれていて,それぞれタブによって切り替えることができる.以降,テキストのメモの作成・管理機能を行えるタブを,同様に画像のタブを,スケッチのタブを,ボードコンテンツのタブをと呼び,これらを総称してと呼ぶ.
iStickyはミーティングクラウドと接続されており,作成したコンテンツはサーバに保存できる.ミーティングクラウドに保存される情報は,コンテンツの種類,種類に応じたデータ(画像なら幅や高さ,スケッチならば手描き線の情報など)に加え,誰が・いつ・どのコンテンツを作成または更新したかというメタ情報を記録する.ミーティングクラウドのコンテンツは,iStickyだけでなく個人のコンピュータからもアクセスでき,画像やテキストなどをアップロード・作成・編集・削除することができる.
テキストタブでは,アイディアや備忘録,TODOといった内容をメモとして書くことができる.図にテキストタブのインタフェースを示す.テキストタブでは,テキストが行ごとに管理されており,行を選択してコピーしたり切り取ったりすることができ,他のノートにペーストすると,ノート間の関係が文脈情報としてミーティングクラウドに記録される.
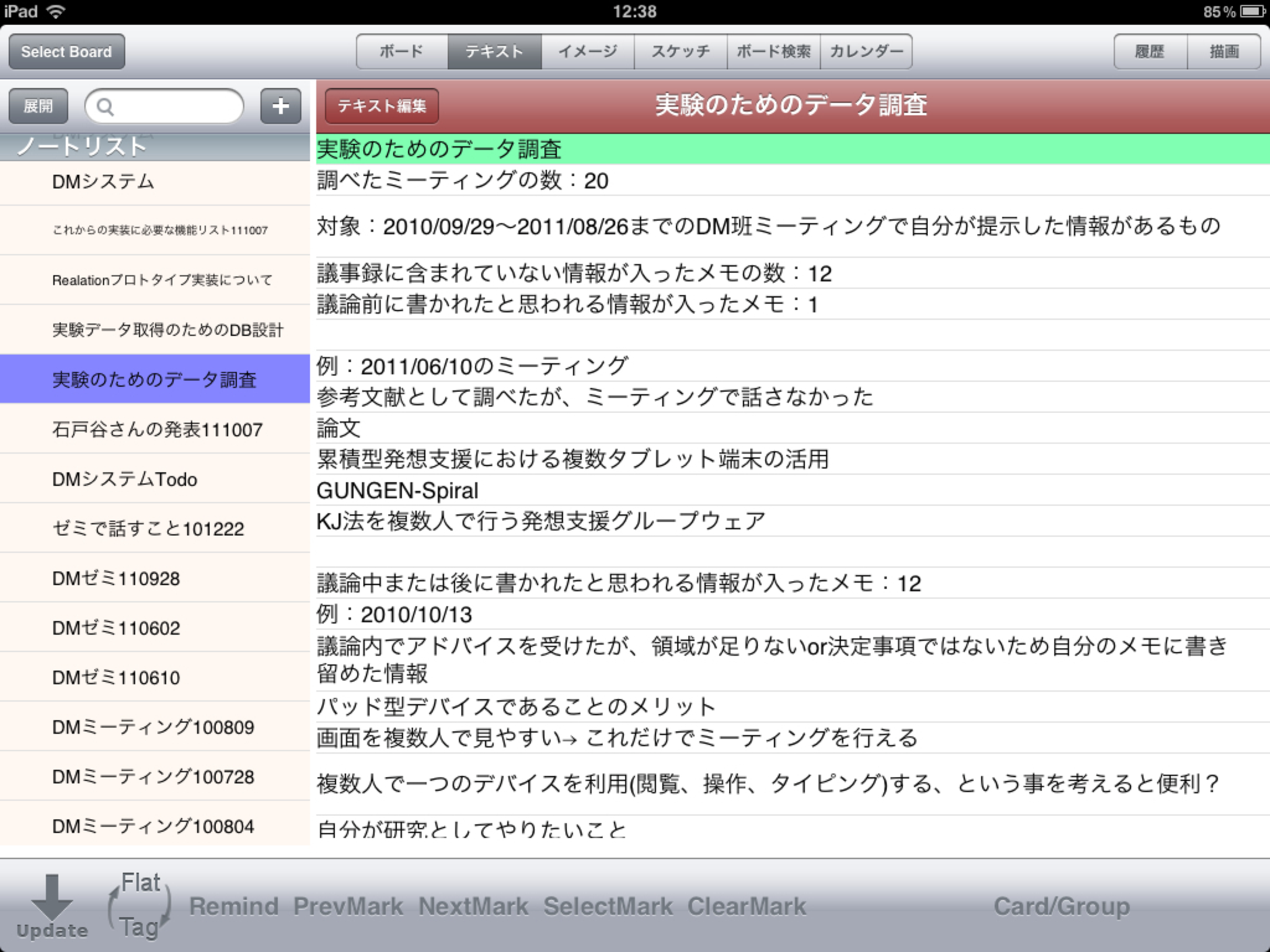
図4.2: iStickyのテキストタブ
イメージタブでは,写真や画像などを蓄積,編集することができる.例えば,開発中のシステムのスクリーンショットや動作風景を撮影した写真などを蓄積し,必要に応じてトリミングや簡単な加工を行うことができる.図にイメージタブのインタフェースを示す.イメージタブではディレクトリ構造を作ることができ,各ディレクトリは画像を積み上げた塊として表現される.ディレクトリを開くと,それぞれの画像を閲覧することができる.
図4.3: iStickyのイメージタブ
スケッチタブは,文章だけでは表現が困難な,例えばシステムフローやシステムのインタフェース設計などの視覚的表現が必要とされる内容を簡単なスケッチとして作成する機能を持つ.図にスケッチタブのインタフェースを示す.
図4.4: iStickyのスケッチタブ
ボード検索タブについては節で説明する.ミーティングクラウドに保存されたコンテンツは,プロジェクトのメンバー間で共有することができるようになっている.
以上の機能を,日常的に携帯するタブレット型デバイスで動作するアプリケーションとして実現する.これによって,ナレッジワーカーの知識活動によって生み出されるコンテンツを保存することができる.そして,コンテンツの編集・利用履歴といったコンテンツの文脈情報を記録することができる.
4.3 TimeMachineBoard
TimeMachineBoardは継続的ミーティングの内容を記録するための仕組みである.ミーティングクラウドに記録された,個人の知識活動によって作成されたテキスト,スケッチ,イメージなどを,iStickyを用いてTimeMachineBoardに提示することができる.
4.3.1 TimeMachineBoardのコンセプト
継続的なミーティングをより効率の良いものにするためには,ミーティングの参加者がこれまでにどのようなことをやってきたのか,どのようなことを話し合ってきたのかを共有している必要がある.ミーティングに至る経緯を共有できていないと,同じ内容の話し合いを何度も行ったり,過去の話し合いに基づいた話し合いができなくなったりする.そのため,過去のミーティングの内容をいつでも検索して振り返ることができる必要がある.また,進行中のミーティングに検索した内容を提示し,明示的に過去のミーティングの内容を参加者間で共有できる仕組みも必要となる.
このようなミーティングを記録するための研究は様々に行われている.小規模なミーティングに関する研究は,ホワイトボードを用いることを前提としたものが多い.電子的なホワイトボードに関する研究は,Elrod らの Liveboardを始めとして数多く行われている.これらのシステムでは,プロジェクタや大型ディスプレイを用いて電子的なホワイトボードを実現し,そこに描かれたストローク情報や転送されたテキストをどのように取り扱うか,電子的なペンをどのように利用するか,というペンとボードのユーザインタフェースに主眼が置かれている.
また,ホワイトボードの内容を記録することに主眼を置いた研究には,Wilcoxらの DYNOMITE のようにホワイトボードの内容と音声を関連づけて記録するものや,Zhang らの研究のようにカメラ映像を用いてホワイトボードの内容を記録するもの などが挙げられる.特に,Golovchinsky らの ReBoardでは,カメラ映像でホワイトボードの変更点を監視して,変更が検出されたときのホワイトボードの内容を画像化し,Webブラウザを用いて閲覧できるようにすることで,ホワイトボードの内容の共有と検索を実現している. しかし,ホワイトボード上に描かれるストロークを画像コンテンツとして記録するため,当然ながらテキストを用いて検索をすることはできない.
TimeMachineBoardでは,一般的な少人数のミーティングで利用されるホワイトボード,フリップチャート,黒板,大型のコルクボードなどのボードに替えて,大型のディスプレイを用いる.図にボードに提示される情報の一例を示す.ボードには,議論の内容を参加者全員が共有し理解しながらミーティングを進めるために,手書きの文字や図,テキスト・イメージなどのボード要素を入力・表示することができる.参加者は,表示したボード・要素を移動・拡大縮小させながら,分類・整理することでミーティングを進行する.

図4.5: ボードコンテンツの例
ボードに情報を入力する方法には,ペン,ポインタ,そして前節で述べたiStickyがある.図(右)に示すようなペンはボードの近くに立ってボード要素の移動・拡大縮小・手描きで文字や図を書くことができる.図(左) に示すようなポインタはボードから離れた場所からボード・要素を指示することや移動・拡大縮小をすることができる.

図4.6: ポインタ(左)とペン(右)
iSticky は,ボードタブと呼ばれるTimeMachineBoardのボードの内容を表示する機能を持ったタブを経由して,テキストメモや画像・スケッチなどのコンテンツをTimeMachineBoardに転送し,それらのテキストや図・写真などに対して移動・拡大縮小操作を行うことができる.それぞれのデバイスやiStickyには参加者固有の IDが設定されていて,ボードに対する情報の入力や操作が行われた時,どの参加者がどの行為を行ったのかをシステムが知ることができるようになっている.
それぞれのミーティングにおいてTimeMachineBoardに提示された内容は,ミーティング終了時にサーバーに検索可能なボードコンテンツとして記録される.ボードコンテンツは,いつ・誰が・どのボードに対してどのような内容のボード・要素を入力し操作したのかという情報から構成される.本システムを用いてミーティングを行うことで,ボードコンテンツを自動的に記録することができる.
ボードはボード要素を自由に配置できるモード(以下と呼ぶ)と,ボード要素を木構造を用いてその場で構造化していくモード(以下と呼ぶ,構造化の詳細については章で述べる)の2種類がある.自由配置モードは,一般的なホワイトボードとして利用したり,簡単なプレゼンテーションを行うために利用することを想定している.木構造モードは,ミーティング内容を木構造として整理しながら議論を進めることができるモードである.木構造モードでは,ミーティング最中に木構造に当てはめて内容を整理することによって,ボード要素間の関係を獲得することができ,ボードコンテンツの高度利用に役立てることができる.図に,木構造モードにおけるミーティング内容の整理の様子を示す.木構造モードでは,ボードに提示したボード要素について,既に提示されているボード要素の内容との関連を考え,ボード要素間に木構造で表現される親子関係などの関連付けを行い,ボード要素を配置する.ボードに提示したボード要素を操作して,関連付けたいボード要素の近くに配置すると,その位置関係を機械的に処理して,それらのボード要素を関連付ける.関連付けられたボード要素は,図中に示すように木構造の階層に合わせて,親ノードとなるボード要素の右下に子ノードのボード要素が自動で配置される.図中のボード要素間に引かれた線はその線の両端のボード要素が木構造によって関連付けられていることを示す.
この木構造モードの仕組みにより,各ボード要素間がどのような関係にあるかを確認しながら,議論を進めていくことができる.
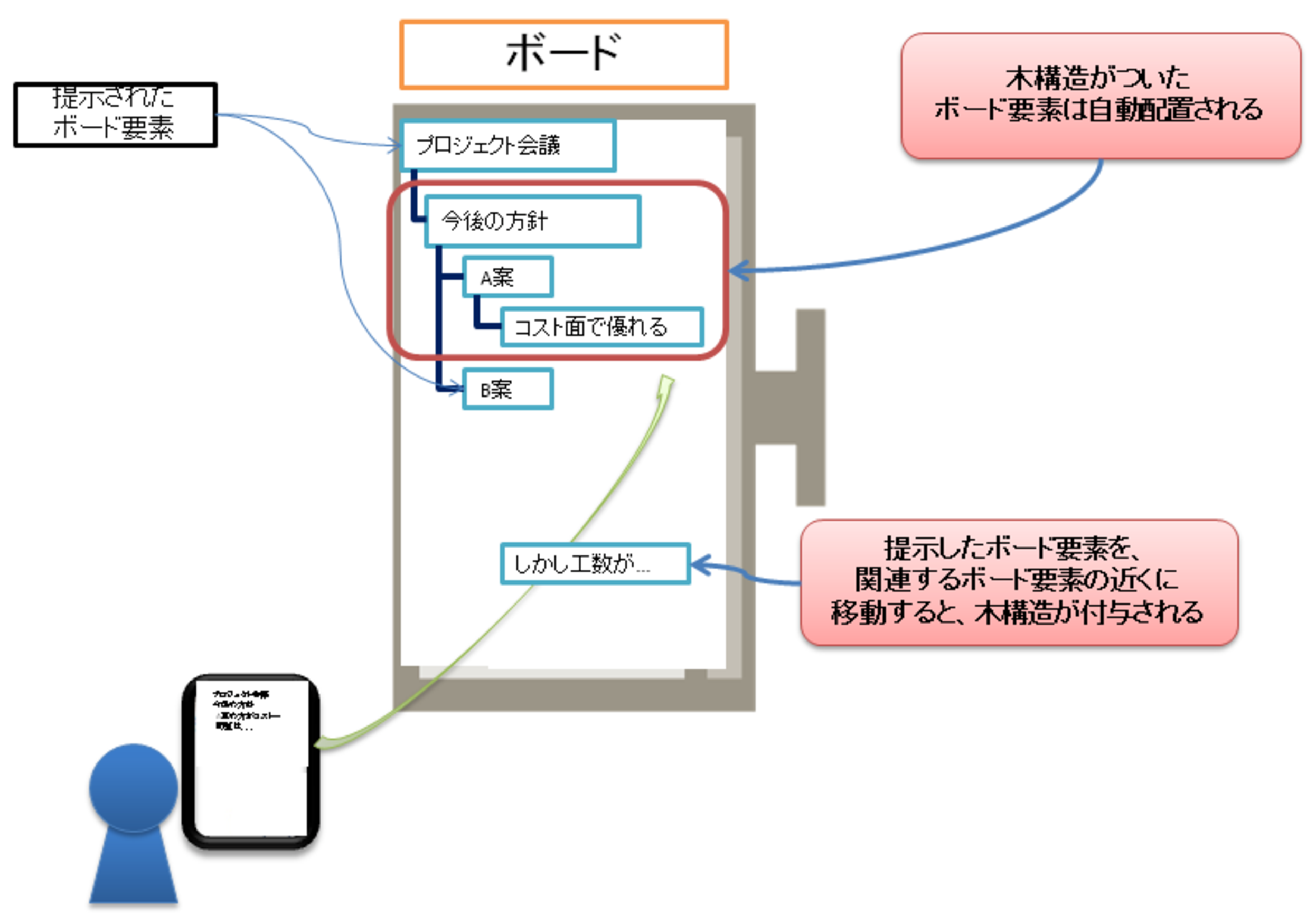
図4.7: 木構造モードにおけるミーティング内容の整理
次項以降では,TimeMachineBoardのシステム構成と,諸機能について述べる.
4.3.2 システム構成
TimeMachineBoardのシステムは,大きく分けて二つの要素から構成される.一方はボードを中心とした直接ミーティングを支援するミーティング環境で,もう一方はミーティング参加者が直接意識することのないミーティングクラウドである.
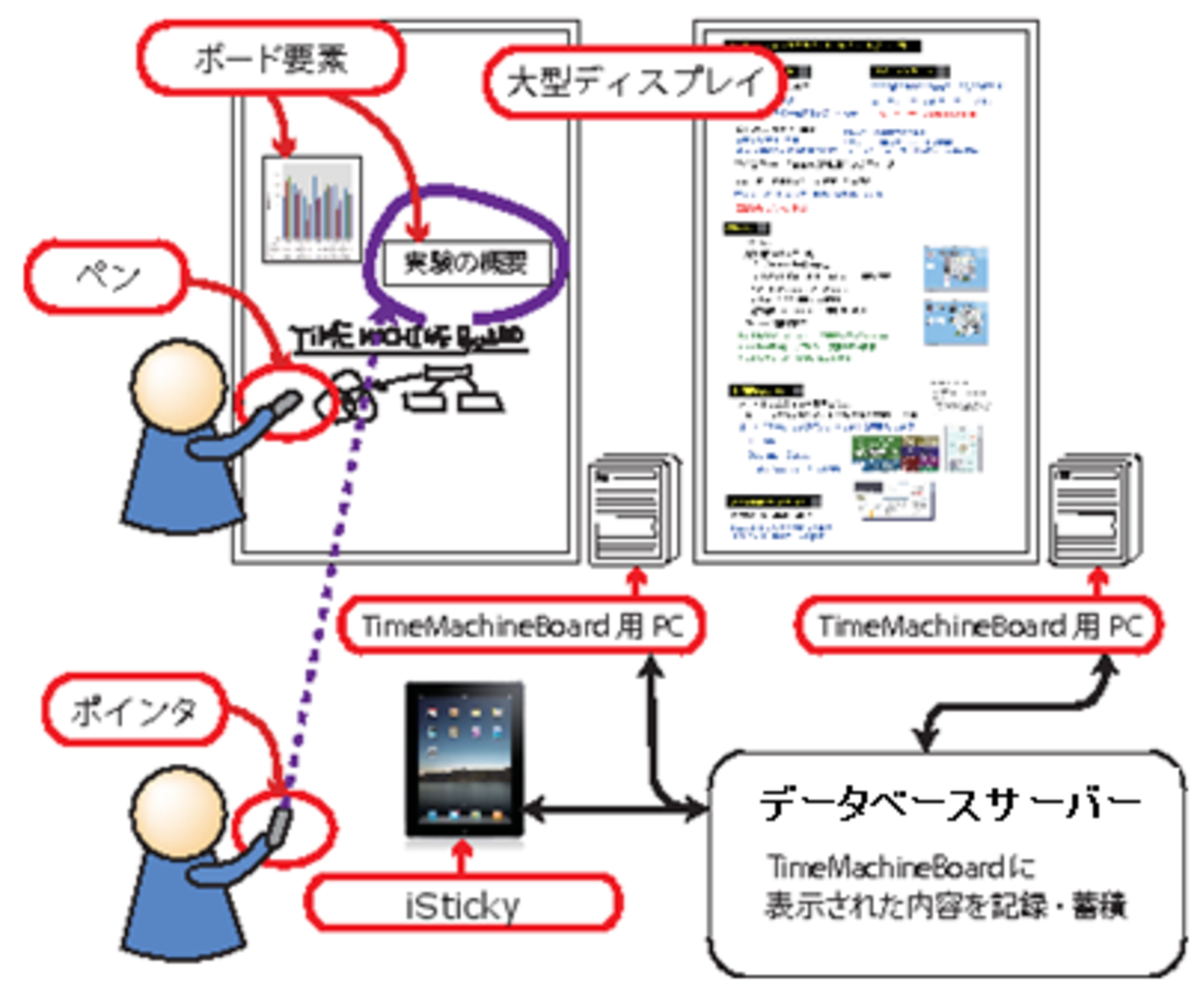
図4.8: TimeMachineBoardのシステム構成
ミーティング環境には複数のボードを設置できる.それぞれのボードは,1台の大型ディスプレイとそれに接続されたコンピュータで構成され,TimeMachineBoardの基本プログラムがインストールされている.それぞれのボードはミーティングクラウドと接続されていて,ボードコンテンツを後述するミーティングクラウドに記録する.参加者が利用するペン,ポインタ,iStickyにはそれぞれに共通するユーザ固有のIDが割り振られていて,どのユーザがどのボード要素に対して操作を行ったのかを,デバイスに依存せず識別することができる.
ボードに利用する大型ディスプレイは縦置き,横置きのどちらでも利用することもでき,保存されるボードコンテンツはディスプレイの向きによってサイズが変更される.現在,実際にプロジェクトミーティングで利用されているボードは,65インチの大型ディスプレイを縦置きで利用している.
ミーティングクラウドは,ボードコンテンツを記録・蓄積するだけでなく,ミーティング環境に存在するボードの情報,参加者のユーザ情報,プロジェクトの情報などを集中的に管理している.ミーティングクラウドでこれらの情報を管理することで,ボードコンテンツを検索したり,iStickyにダウンロードしたりすることが容易にできる.例えば,あるユーザが何らかの理由で参加できなかったミーティングがあったとしても,ミーティングクラウドからiStickyにダウンロードして,参加したミーティングと同じように閲覧することができる.
次節以降,ミーティングの流れについて説明した後,TimeMachineBoardの諸機能について詳細に説明する.
4.3.3 ミーティングの開始から終了までの流れ
ミーティングの一連の流れは,まず,ユーザがiStickyを用いてミーティングを開始することから始まる.その際,ボードのモード(自由配置モードか木構造モードか),ミーティングの種類(プロジェクトミーティングならばプロジェクト名,デバッグモード,無題などを選択できる.プロジェクトはミーティングクラウドで追加することが可能)を指定することができる.ボードがミーティング開始のコマンドを受け取ると,ミーティングのタイトル(2012/01/21 ビークル班プロジェクトゼミなど)だけが表示された初期状態のボードが表示される.
次に,ミーティング参加者はそれぞれに所有するiStickyからボードに入力したい情報を選択して送信する.ボードは受け取った情報を大型ディスプレイ上にボード要素として表示する.提示できるボード要素の種類と提示方法については項で詳細に述べる.ミーティング参加者はボード要素をペン,ポインタ,iStickyを用いて移動したり,拡大縮小したり,削除したりしてボードの内容を分類・整理しながら話し合いを進行させる.表示されたボード要素の操作方法の詳細については項で述べる.
最後にミーティング終了のコマンドをiStickyからボードに入力すると,ボードに表示されている内容のスナップショットと,ボード要素それぞれの詳細な情報をボードコンテンツとしてまとめてミーティングクラウドに送信する.ミーティングクラウドは受け取った情報を保存し,検索可能な状態で管理する.
4.3.4 ボード要素の入力
ボードに情報を入力するには,ペンを用いて手描きの図や文字を書く,ポインタを用いてストロークを書くなどの方法があるが,ここでは,iStickyのボードタブを利用する方法について記述する.
iStickyのボードタブを図に示す.ボードタブは,図左端に示すようなTimeMachineBoardの操作メニューと,残りの右側に白色で表示されたボード画面から成る.
ボードタブは現在ボードに表示されている内容を,iStickyで閲覧・操作するための機能である.ボードタブにボードの内容を表示するためには,まずボード選択ボタンを押して接続先のボードを選択する.ボードが選択されると,ミーティングが既に開始されている場合にはその内容を,開始されていない場合は空のボードを表示する.

図4.9: iStickyのボードタブ
ミーティングが開始されているボードにiStickyが接続されている場合,ボードタブにはボードの内容が表示される.ミーティング参加者はボードタブを用いて,ボードに情報を入力したり,表示されている内容を操作したりできる.本項では情報を入力する手段について述べ,次項では表示されている情報を操作する手段について述べる.
ボードに情報を入力する方法は,ボードタブで直接情報を入力する方法,前述のテキスト・イメージ・スケッチ・ボード検索タブから直接ボードに入力する方法,後述の履歴機能を用いてボードタブから情報を入力する方法の3種類がある.
ボードタブで直接入力できる情報は,テキストと手描きのストロークである.テキストを直接入力するためにはテキスト編集ビューを利用する.図に,ボードタブ上に編集ビューが表示されている様子を示す.テキストを入力したい場合は図の左下のテキスト編集ボタンを押す.すると,図中央に示すようにポップアップビューが出現し,その左側の白い領域に入力したいテキストを打ち込み,必要であればテキスト編集ビューの右側に配置されているカラーボタンでテキストの色を変更したり,その下にあるフォントサイズの調整バーを動かしてテキストのフォントサイズを変更する.そして,OKボタンを押すと,編集ビューで入力されたテキストがボードに入力される.また,テキストを入力した後であっても,ボード要素を2回タップすると,同様にテキスト編集メニューがポップアップし,内容・色・フォントサイズを変更することができる.図の中では,提示されたボード要素である「ターゲットとする層,シチュエーション」を選択してテキスト内容を編集している.ストロークは左メニューのマーカーボタンを押しながらボード部分をドラッグすると入力することができる.ストロークの色やサイズは,同じく左メニューのストロークスタイル選択ボタンを押すと表示されるストロークスタイル選択ビューで設定できる.また,直線・片側矢印・両側矢印・矩形などのストロークの種別は,ストロークタイプ選択ボタンを押すと表示されるストロークタイプ選択ビューで選択することができる.
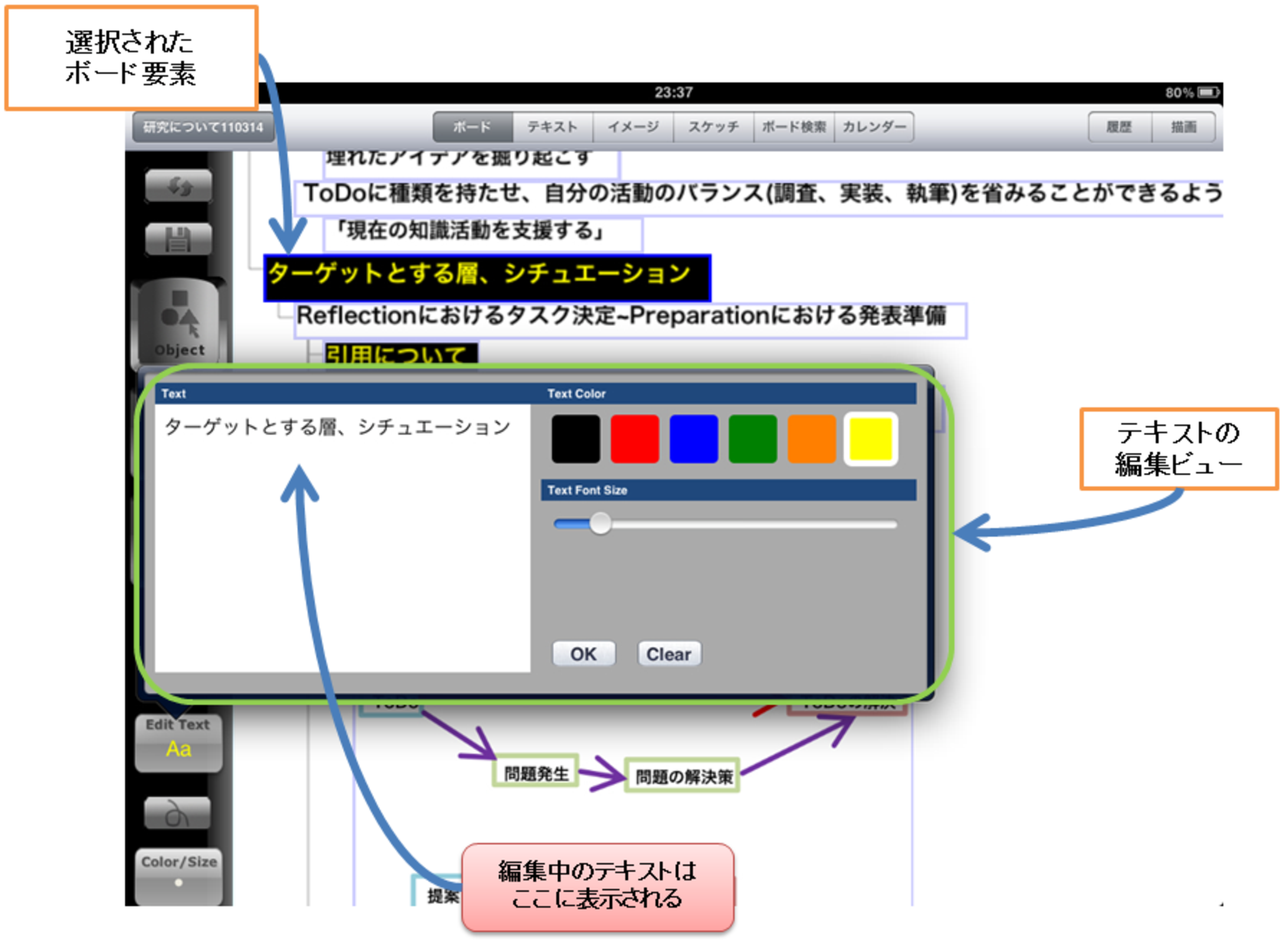
図4.10: テキストの編集ビュー
個別のコンテンツタブから直接ボードに入力する方法は,コンテンツタブの実装によって様々であるが,テキストの場合は,テキストタブを開いて転送したいメモの転送したい行を選択して長押しすることで出てくるポップアップメニューから行うことができる.図に,テキストタブでポップアップメニューが出現している画面を示す.テキストタブで転送したいメモの行を選択すると,図中に示すようにテキストの背景が紫色になる.そして,その状態で押し続けると,その行のテキストの編集やボードへの転送を行うためのポップアップメニューが出現する.そのポップアップメニューの中から[Transfer to Board]を選択することで,選択されたテキストがボードに入力される.イメージやスケッチ,ボード検索でも同様の実装がなされており,転送したいコンテンツを選択してボードタブを介さずに情報を入力することができるようになっている.この場合,ボードタブ上のどの位置に表示するかは選択できず,ボード上で空いている場所に適宜表示される.
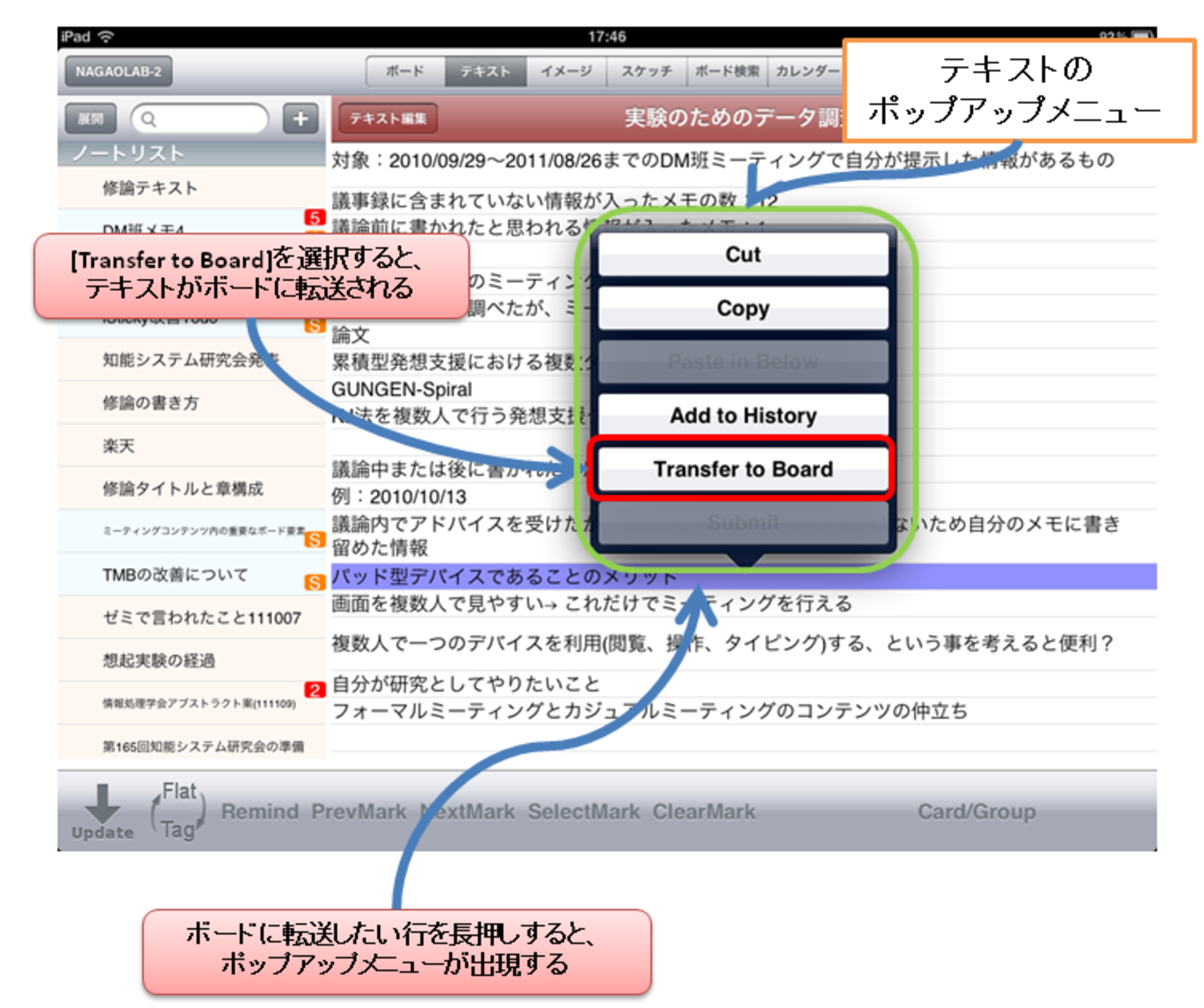
図4.11: テキストのポップアップメニュー
スケッチタブの機能で,テキストタブで作成したメモやイメージタブに保存されている画像をスケッチに利用できることを述べたが,それと同様の操作で,テキストや画像およびスケッチをTimeMachineBoardに入力することができる.iStickyの画面右上にある履歴ボタンを押すことで,履歴ポップアップビューを開くことができる.履歴ポップアップビューを開くとテキストまたはイメージを選択できる.テキストまたはイメージを選択するとコンテンツを履歴に格納した順にソートされた一覧が表示される.テキストの場合は,テキストタブにおいて選択した行が一覧として表示され,イメージの場合はイメージタブで閲覧した画像およびスケッチが一覧に表示される.
履歴機能を用いてボードタブに情報を入力するには,ボードタブを開いた状態で,このテキストまたはイメージ履歴一覧を開き,表示されているコンテンツの中から入力したいものを選択する.選択されたコンテンツはボードタブ上に表示され,移動させることができ,位置と大きさ,テキストの場合にはさらに色を変更することができる.履歴機能を用いることで,ユーザはコンテンツタブに保存されている情報をボードに入力するためにコンテンツタブとボードタブを行き来する必要がなくなる.
履歴機能を用いてiStickyで作成したコンテンツの部分をTimeMachineBoardに入力した際,入力元のコンテンツの一部あるいは全体と出力先のボード要素の間には引用関係が発生する.iStickyでは,この「どのコンテンツのどの部分をどのボードに提示したか」という文脈情報を記録している.この文脈情報はミーティングクラウドにアップロードされ,iStickyのコンテンツとTimeMachineBoardのボードコンテンツがどのように関係しているかの情報が蓄積される.この履歴機能によって行われたボードへの入力は,iStickyのコンテンツからボードコンテンツへの引用として扱われる.
ここで,履歴機能におけるテキストの扱いについてはさらに詳述する必要がある.ボード上に非常に長いテキストが表示されてしまうと,ボード内容が文字だらけになり,進行中のミーティングにおいても,ボードコンテンツとして保存され後で振り返る場合でも,内容を理解するのに時間がかかってしまう.そこで,ボードに表示するテキストができるだけ簡潔で分かりやすいものになるように,長いテキストを履歴に入れる時とボードに入力しようとした場合に,図に示すようなテキスト整形ビューをポップアップするようにした.なお,URLや論文タイトルのように短くしてしまっては意味のないものの場合は,整形をキャンセルしてそのまま送信できる.
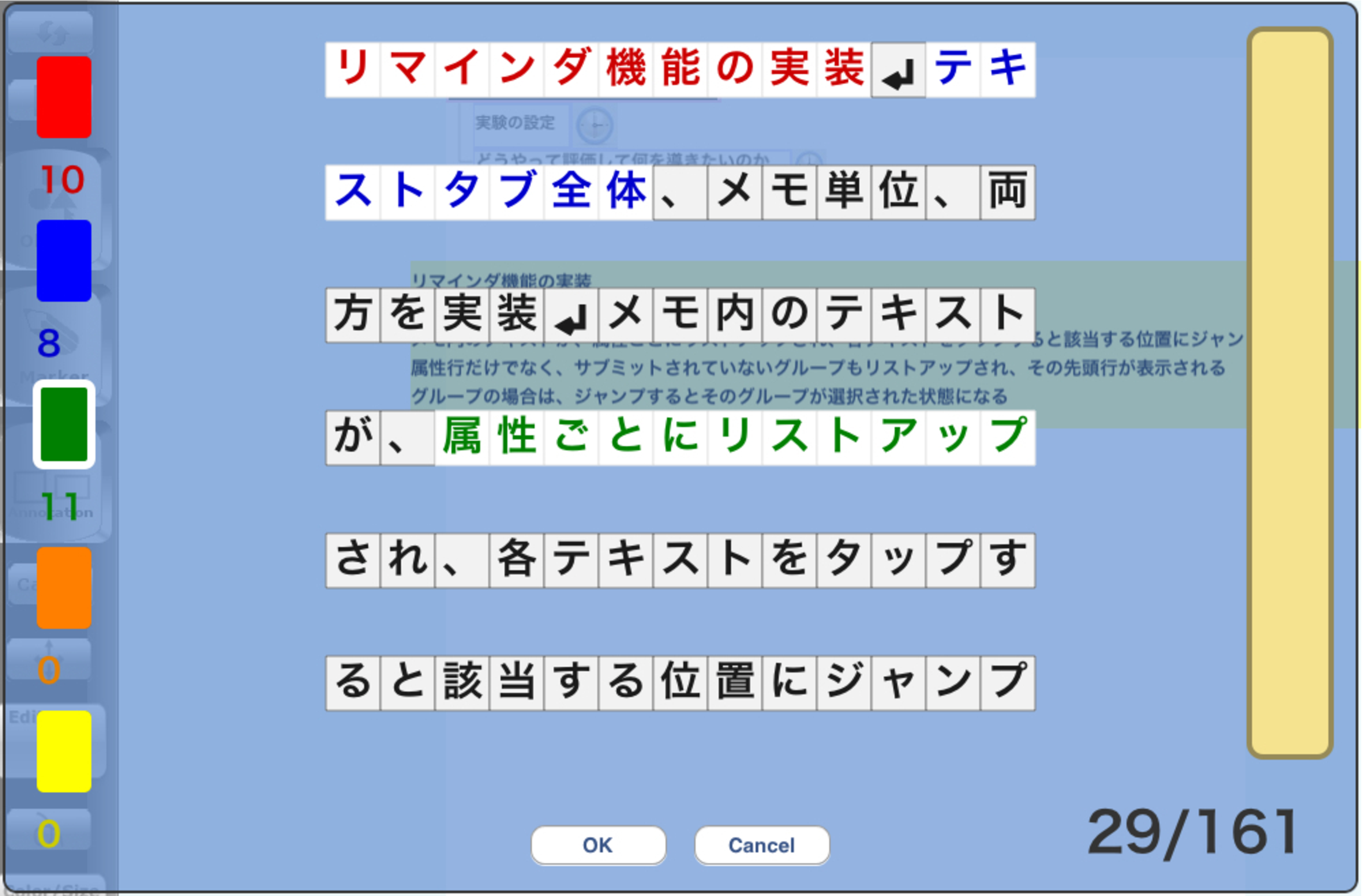
図4.12: テキスト整形ビュー
テキスト整形ビューは,長いテキストの中から必要な部分を選択して短縮することができる.表示されているテキストの下側にあるテキスト選択スペースをドラッグすることで,TimeMachineBoardに表示するテキスト内容を選択することができる.選択したい文字の直下を指でドラッグすると,文字がハイライトされ,文字を選択することができる.文字をドラッグして文字の位置を変更することができ,ハイライトされている部分をドラッグすると選択されている部分をグループとして移動することができる.これによって簡単な編集を行ってボードに適切なテキストを入力することができる.また,文字を選択すると図の右下にはテキストの全文字数と選択された文字数が表示され,テキスト長を意識しながらできるだけ簡潔なテキストにすることができる.
さらに,長いテキストを1つのボード要素として入力するのではなく,複数のボード要素に分割したいという要求がある.そこで,図左側の5色のボックスから一つの色を選択してから,文字選択を行うことでハイライト色が変わるようにした.ハイライトの色が違う文字は別のボード要素としてボードに入力される.
このように,情報の入力方法が多様なのは,ユーザがミーティングの場面に応じて入力方法を柔軟に選択して情報を入力できるようにすることで,ボードに情報を入力することに費やす時間をできるだけ少なくして,ミーティングの進行を妨げないようにするためである.
4.3.5 ボード要素の操作
ボードに表示されているボード要素の移動,拡大縮小,削除,テキストの編集などの操作は,ポインタ,ペン,iStickyのボードタブを用いて行うことができる.それぞれの方法によって実行できる操作に多少の差異はあるが,ここではボードタブを用いて行う方法についてのみ述べる.
iStickyのボードタブで操作を行うためには,まずボードタブ上で対象のボード要素を選択する必要がある.ボード要素の選択は図に示すボードタブ左メニューのオブジェクトボタンを押した状態で,右側のボード部分からボード要素を選択することで行うことができる.選択されたオブジェクトはハイライト表示される.
なお,iStickyのボードタブでは他者の入力したボード要素を操作できないようになっている.これは,同じボード要素を複数のユーザが同時に操作することで起こるコンフリクトを避けるためである.他者の入力したボード要素を操作できるようにした場合,ボードに表示されている内容と参加者それぞれのボードタブに表示されている内容を自動的に同期したり,他者が操作している間は操作できないようにするなどの複雑な実装が必要になる.TimeMachineBoardでは,そのような複雑な実装を行うことがミーティング参加者の利便性に大きく寄与することはないと考え,単純に他者の入力したボード要素を操作できないようにすることで対応している.そのため,「選択する」と記述している場合,「選択をしようとするユーザが入力したボード要素を選択する」ことを指す.
ボード要素の移動は,ボード要素を選択した状態で,オブジェクトボタンを押したままボード要素の内側から指をドラッグすることで行える.ボードが自由配置モードの場合は,自由に位置を変更することができ,木構造モードの場合には親となるボード要素を選択して移動させることになる.木構造モードの詳細については後述する.
ボード要素の拡大・縮小は,ボード要素を選択した状態で,オブジェクトボタンを押したまま,指2本を画面に当てて開いたり(ピンチアウト)閉じたり(ピンチイン)するピンチ操作することで実行できる.ピンチアウトするとボード要素が拡大し,ピンチインすると縮小する.拡大縮小の動作は,木構造モードでも変わらない.
ボード要素の削除は,ボード要素を選択した状態でボードタブ左メニューの削除ボタンを押すことで実行できる.木構造モードで子ノードを持つノードを削除した場合には,子ノードが元のノードの親ノードに付け替えられ,木構造は維持される.ボード上で削除したとしても,それは削除という操作として記録され,データからは削除されることはない.
このように,ボードタブを用いることで,ボードに情報を入力して表示されたボード内容を,手元のiStickyを用いて操作しながら,ミーティングを進行することができる.iStickyのボードタブは,ペンやポインタを用いる方法とは異なり,共有しているボードそのものを操作するのではなく,個人のiSticky上に表示されたボードの内容を操作する.そのため,ペンやポインタを用いて移動・拡大縮小する方法と比べて直感的ではない.しかし,ボードに入力すべき情報を蓄積しているiStickyが,ボードの操作にも対応していることで,情報をボードに入力して適切な位置に配置することが比較的容易に行える.ボード要素の整理整頓に必要な操作にかかるコストを低減することで,ミーティングの本質である話し合いに集中することができる.
4.3.6 過去のボードコンテンツの検索
ミーティング中に議論を阻害せず過去の議論を参照できるようにするためには,保存されている過去のボードコンテンツをすばやく検索・閲覧できる必要がある.そこでiStickyの機能として図に示すような検索インタフェースを開発した.この検索インタフェースは,ボード検索タブという形で,iStickyが持つ大きな機能の1つとして位置付けられている.検索インタフェース上部には,過去に行われたミーティングのボードコンテンツの最終状態を表すイメージを時系列順に並べたボードイメージビューを配置した.ビューを左右にスクロールすることで蓄積された議論コンテンツの一覧を閲覧でき,必要に応じて選択したボードイメージを拡大して閲覧することができる.
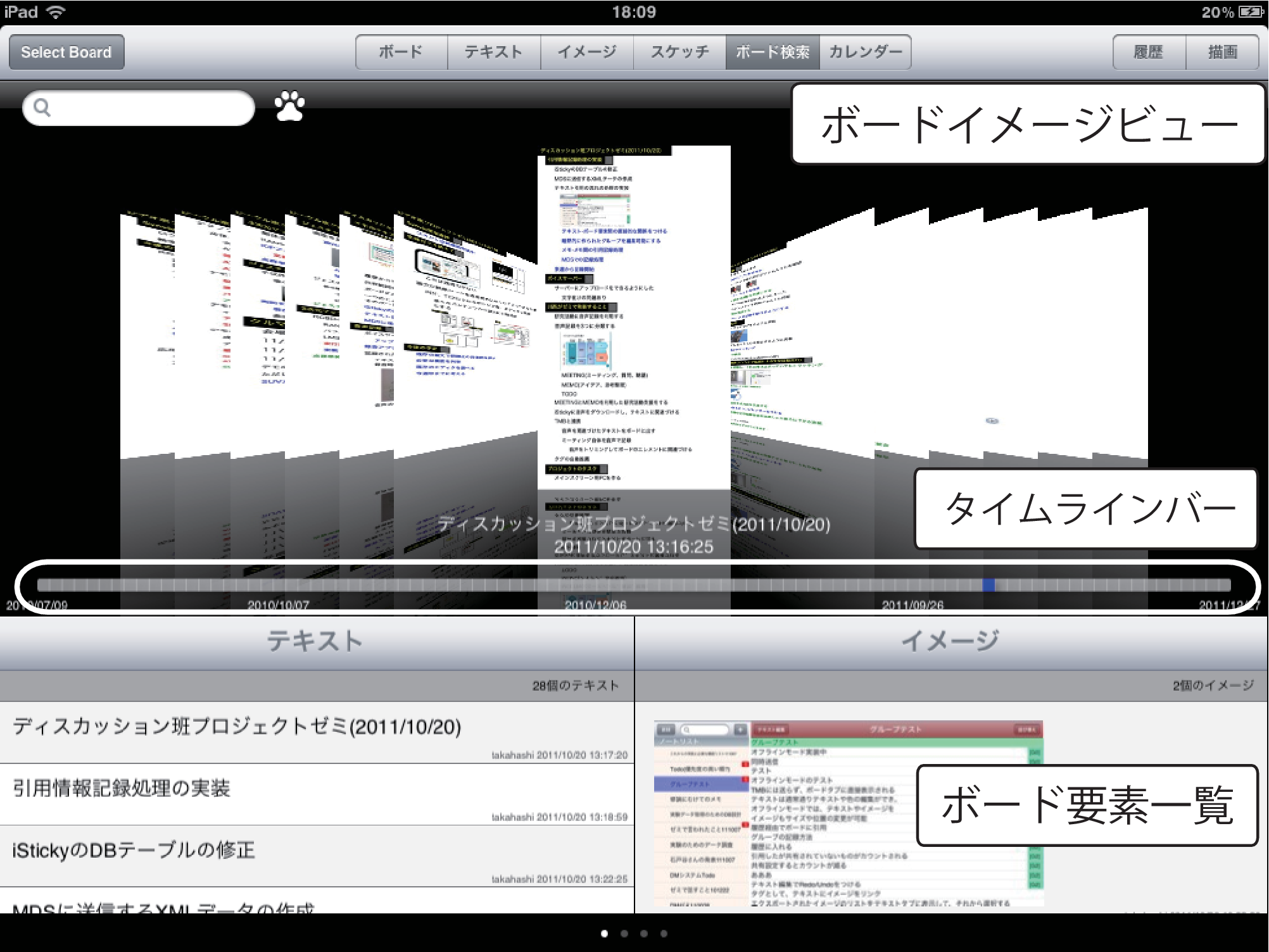
図4.13: iStickyのボード検索タブ
ボードイメージビューに表示されるボードコンテンツの一覧は,iStickyのユーザが参加した全てのミーティングのボードコンテンツが新着順に表示され,必要に応じてボードコンテンツに含まれるテキストを用いた全文検索,テキストから抽出されたキーワード,エレメントの情報,プロジェクト情報,参加者の情報などを組み合わせて検索することで表示を絞り込むことができる.
また,参加していないミーティングのボードコンテンツ,例えば,欠席してしまったミーティングや過去のプロジェクトメンバーで行ったミーティング,興味のある他のプロジェクトのミーティングなどは,後でミーティングクラウドからダウンロードしてボードイメージビューに追加することができる.
ボードイメージビュー下部にはタイムラインバーを配置し,ボードイメージビューをスクロールせず,すばやく必要なボードコンテンツを見つけられるようにした.図に,タイムラインバーを操作してボードコンテンツの情報が表示されている画面を示す.図中央に配置されているタイムラインバーは,記録されている議論コンテンツの中で一番古いものと最新のものの時間を左右にプロットし,タイムラインバー上を指で選択することで,タイムライン上の位置に応じた時刻に行われたミーティングのボードコンテンツやミーティングが行われた時刻などの詳細情報が,図中で示すようなポップアップビュー内に表示される.また,指を離さずそのままタイムラインバー上をドラッグすると,ドラッグ先の位置に応じた過去のボードコンテンツの情報がが入れ替わって表示される.
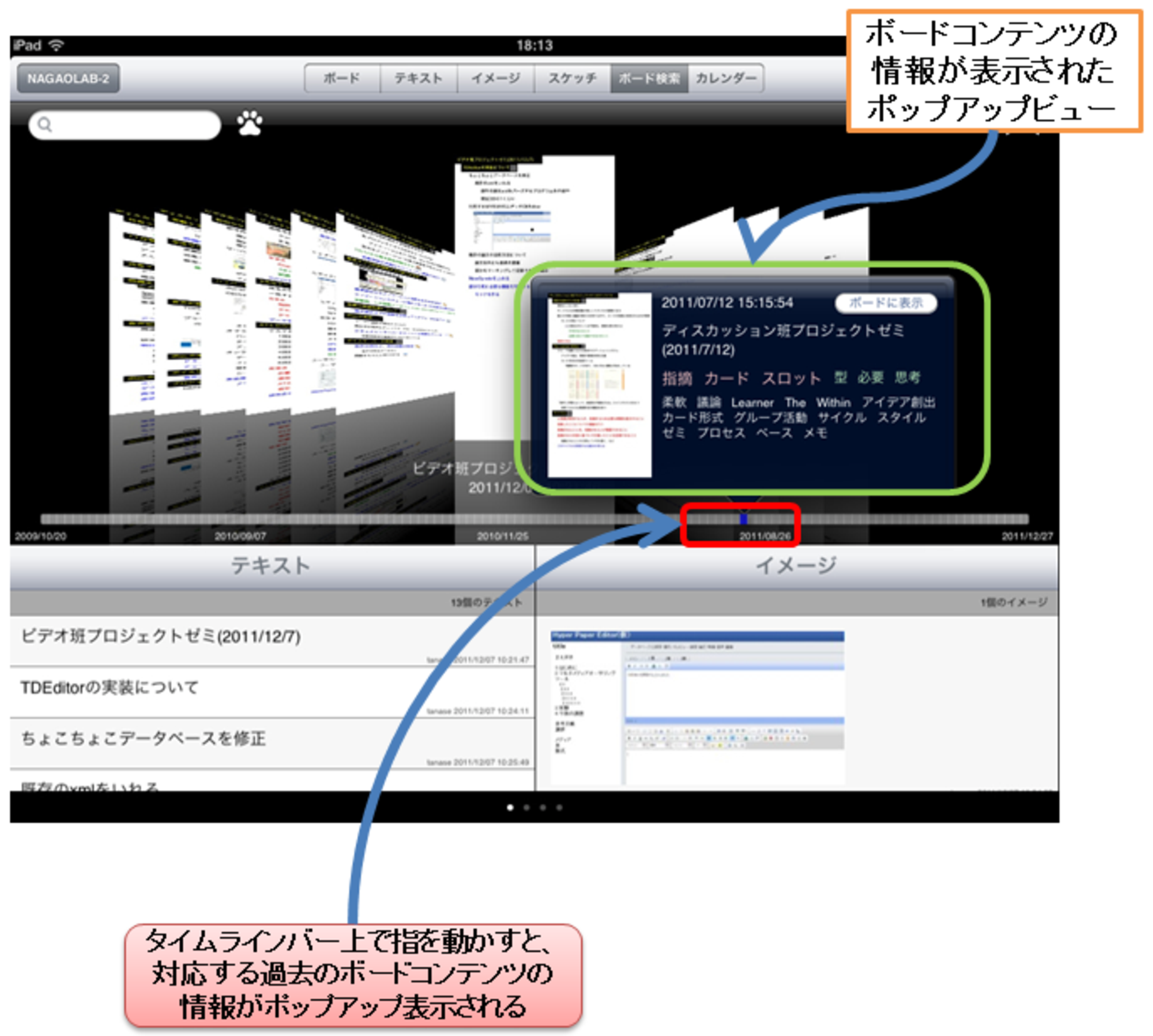
図4.14: ボードコンテンツの情報のポップアップ表示
検索インタフェースを用いて議論コンテンツを検索して閲覧することで,過去の議論内容を想起することができる.ボードイメージの内容だけで,詳細な内容を想起できない場合には映像を閲覧することもできるようになっているが,LeeらのPortable Meeting Recorderのように議論内容を音声や映像として振り返ったり,書き起こしテキストを読んだりすることは,議論内容を振り返るには時間がかかりすぎる.本システムでは,ミーティング中に効率良く複数のミーティングを閲覧できるようにし,文脈を手掛かりに議論内容の想起を支援することに主眼を置いているため,映像を用いて詳細に議論内容を振り返る方法については,単に映像を再生・閲覧できるということに留めている.
また,この検索インタフェースを経由して,ボードコンテンツに含まれるテキストやスケッチをiSticky内のメモやスケッチに引用することで再利用することができる.
図に示す検索インタフェース下部のボード要素一覧には,ボードコンテンツに含まれるボード要素がテキスト・イメージ・スケッチという種類ごとにリストアップされている.このリストから再利用したいボード要素をタップで選択するとポップアップビューが表示され,テキストやイメージはそれぞれ対応する履歴リストに格納される.その後,テキスト履歴経由で既存のテキストメモに挿入したり,作成中のスケッチにテキストやイメージを配置することができる.この際,iStickyからTimeMachineBoardへコンテンツを入力したときと同様に,ボードコンテンツの部分がiStickyのコンテンツに引用されたという情報が記録される.
4.3.7 自動アノテーション機能
iStickyを用いて日常的に書き込んでいるノートの一部の内容をボードに提示した場合に,そのノート内の関連する情報(ボード内容を補完するテキスト)をサーバーに送信して共有する仕組みを実現した.その情報は自動的にボードコンテンツと統合され,ボードへのアノテーション情報として参照できる.
ここでのアノテーションは,ノート内の長い文章をボードに提示する際に短くまとめた場合の,元の長い文章そのものである場合や,ボード要素として提示したテキストを含むノート内の(ボード要素の元になったテキストを含む)関連する部分を任意に選択したものである場合がある.
実例を示すと,「ループ解決のアルゴリズムの調査・実装」というボード要素に対して,「地図生成するときに,位置の誤差によってループした部分がうまく重ならない問題に対してのアルゴリズムの調査・実装をする.具体的にはFast SLAMのアルゴリズムを確率ロボティクスの本で勉強する」というノートの部分が関連付けられ,アノテーション情報としてボードコンテンツと統合されている.
アノテーション情報は検索インタフェースで閲覧することができ,特定のボード要素を選択したときに提示される.これにより,ボードコンテンツだけではその内容を想起できなかったとしても,より詳細にその内容を確認することができる.
4.4 本章のまとめ
前章までの考察に基づき,Xerox PARCが提唱したボードとタブレット型デバイスが協調的に動作するミーティング支援システムを参考に,現在の情報技術を用いて,継続的ミーティングを支援するシステムを実現し,その構成と機能について述べた.
継続的ミーティング支援システムは,TimeMachineBoardと呼ばれるミーティング内容を記録するための仕組みと,iStickyと呼ばれる個人の活動に関わるコンテンツを集約しTimeMachineBoardに情報を入力するためのクライアントソフトウェアによって構成される.TimeMachineBoardは,大型ディスプレイをボードとして用いる.また,iStickyはタブレット型デバイスで動作する.TimeMachineBoardはXerox PARCのLiveboard,iStickyはPARCPADとPARCTABに相当し,互いに協調的に動作してミーティングを支援する.iStickyを用いて作成されたコンテンツ,およびTimeMachineBoardを用いて行われたミーティングの内容は,すべてミーティングクラウドに記録する.
本システムを用いてミーティングを行うことで,日常の活動の中で蓄積されたテキスト,イメージ,スケッチ,過去のミーティング内容の一部をボードに提示して整理しながら話し合うことができる.さらに,ミーティング中に参加者が行った行動から木構造や引用関係を自動で獲得し,ボードコンテンツとしてミーティングクラウドに蓄積される.
ミーティングクラウドに記録されたボードコンテンツの木構造や引用関係は,知識活動において生み出されたコンテンツのメタ情報である.これらのメタ情報を有効に活用する事で,ボードコンテンツの検索や要約と行った高度利用を実現する事ができる.さらにコンテンツの文脈情報を蓄積することで,コンテンツを閲覧したり利用したりする際に,過去のボードコンテンツや関連するコンテンツを芋づる式に閲覧していくことができる.
5 ボードコンテンツの構造化
5.1 ボードコンテンツの構造
ミーティングで行われた話し合いの記録は,いつ・誰が・どのボードに対してどのような内容のボード要素を入力・操作したのかという情報と,ミーティング環境に設置したマイクロフォンを用いて記録した音声から構成される.記録した話し合いの内容はミーティング終了時にデータベースに保存され,環境に設置されているどのボードからでも検索することが可能なボードコンテンツとして蓄積されている.また,同様に,後述するボードコンテンツブラウザ及び知識活動支援システムからもアクセスできる.
ミーティングで行われた話し合いを通して得られる問題の解決策や新しい知見を各参加者が有効に活用することで,その後の知識活動やミーティングをよりよいものにすることができる.著者は,過去の話し合いの内容をミーティング中に再利用することが,過去の話し合いの内容に基づいたよりよいミーティングを可能にすると考え,記録された過去のボードコンテンツをボードに表示されている内容に基づいて検索し,検索されたボードコンテンツ全体を同一または別のボードに表示して,その一部を選択し進行中のミーティングに引用する機能を実現している.
しかし現在,本システムで実現されている引用の仕組みでは,検索して提示された過去のボード全体を閲覧することで,過去の話し合いの内容を全員で把握し現在のミーティングに役立てることは可能であるが,全体の中から必要な部分を選び出すためには時間がかかり,進行中のミーティングを妨げてしまう場合があった.効果的に過去のボードコンテンツを再利用できるようにするためには,進行中のミーティングの文脈に沿った過去のボードコンテンツの一部分を適切な単位で提示するような仕組みが必要だと考えられる.
ミーティング中に限らず,話し合いの内容を様々な用途で再利用するには,文脈に応じて,適切な単位のボードコンテンツを提示する必要がある.そのためには,ボードコンテンツを構造化しなければならない.ボードコンテンツが話題ごとに分割されていて,それら分割された部分について「進捗報告か,議論か」という話題の種類や,「なぜその話し合いが行われたのか」「どのような話し合いの結果として出てきたものか」といった文脈を表す部分間の関連が付与されていなければならない.
電子ホワイトボードの内容を構造化する先行研究を挙げると,Moranらの研究ではペンストロークを用いてボード上に境界線を引いたり表示されているものを囲んだりすることで,ストロークをグループ化する仕組みを実現している.またMynattらのFlatlandではストロークを用いて明示的にセグメントを定義することはもちろん,時間や空間・内容を考慮して自動的にセグメントを設定し,移動・拡大縮小や一部分だけのプレイバック,さらにビヘイビアという概念を導入してセグメントの内容に応じた機能を提供するといった提案を行っている.
著者は,話し合いの内容を表す要素をボードに表示されているボード要素と定義して,ミーティング中に,要素のグルーピング,単一のボードコンテンツ内および複数のボードコンテンツ間にまたがる要素間の関連,要素に対する属性をボードコンテンツに付与するためのツールを開発した.
ミーティング中にできる限りの構造を付与しておくことで,ミーティング後にその話し合いの内容が,どのような文脈で出てきた話だったのかを理解するための手がかりになると考えられる.できるだけユーザーがミーティング中に行う自然な行動の中で簡便に,かつ必要十分な構造化を行えるようにツールの設計を行った.
5.2 ボードコンテンツの構造化手法
ミーティングにおいてボードは,参加者が話し合いたいこと,話し合ったことを提示して参加者全員で共有し,ミーティングの流れや論点を把握するために利用される.ボードを効率的に利用するためにグラフィックファシリテーションと呼ばれる手法がある.これはグラフィックファシリテータと呼ばれる専門の人間が,ミーティングで話し合われた内容を論理的・視覚的に整理しながらボードに記述して行くことで,ミーティングをより有益にするための手法である.
小規模で継続的なミーティングにおいては,このような専門家を用意して話し合いを行うことは難しい.そこで著者は,ミーティングの参加者が,ミーティング中にボード内容を木構造に並べ替えできる仕組みを導入した.参加者が提示した内容を木構造に並べ替えて話し合うことで,提示した内容の論理的なつながりが可視化され,ミーティング中はもとより,記録されたボードコンテンツをあとで見返すときに内容が把握しやすくなる.
5.2.1 コンテナによる構造化
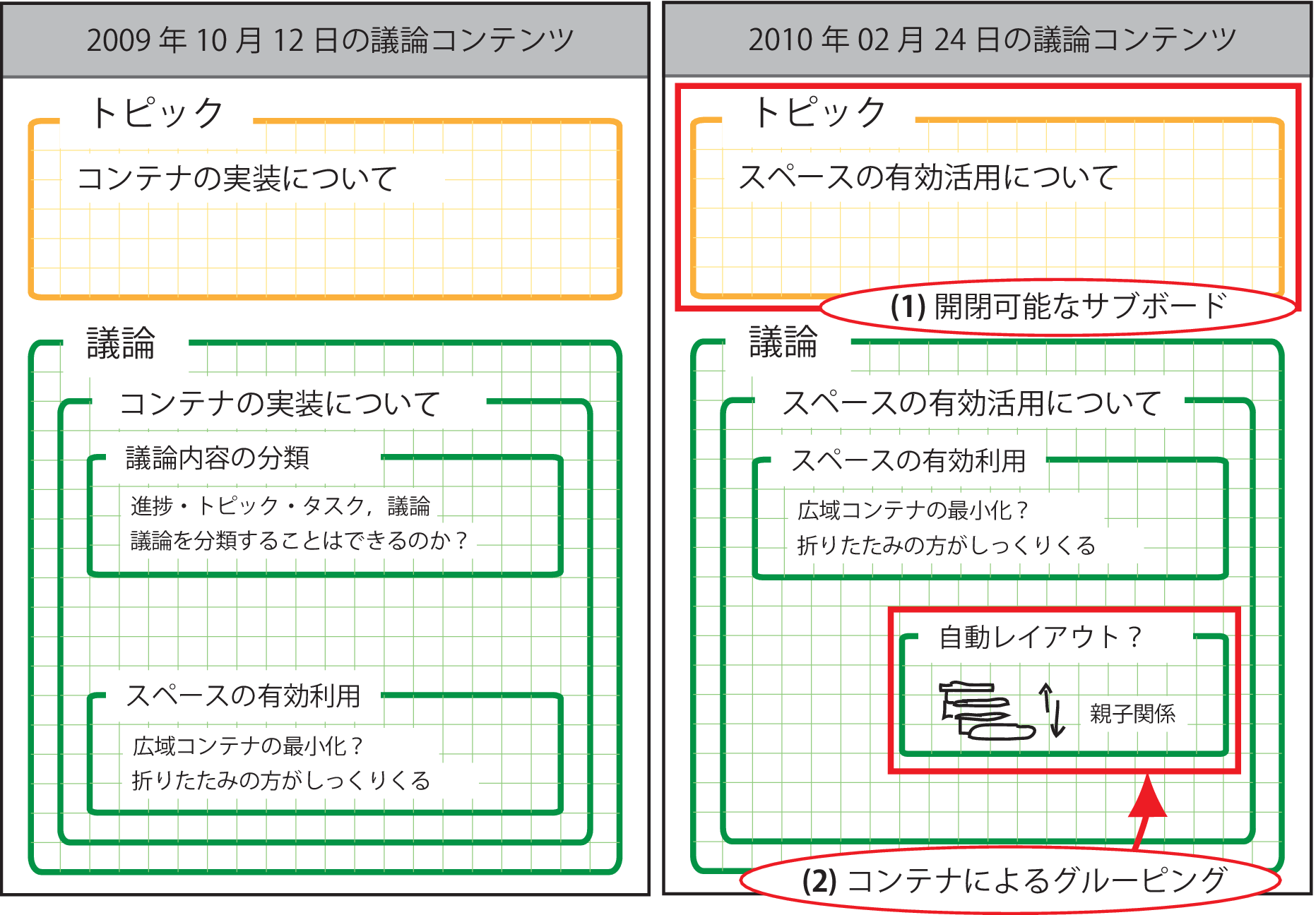
図5.1: コンテナによるボード要素のグルーピング
図(1)・(2)のような領域をコンテナと呼び,ボード要素を内部に配置してグルーピングできるようにした.これによって話題ごとにボード内容を分割し,ボードコンテンツの部分として扱うことが可能になる.
コンテナには内容のタイプを属性として設定することができる.著者の所属する研究室で行われたプロジェクトミーティングにおける話し合いの内容には,進捗報告・トピック・議論・タスクという4つの種類があることが分かった.
コンテナの基本機能として,任意のタイトルを設定することができ,内部に配置されたボード要素をまとめて移動・拡大縮小することができる.また,コンテナ自体もボード要素として扱って,他のコンテナの中に配置して入れ子構造を表現することができる.基本的なコンテナとは別に,図(1)のような,ボードの限られた領域を有効に利用できるようにするためのサブボードを用意した.これはWindowsにおけるウィンドウと同じように最小化・元のサイズに戻す・最大化という操作を可能にしたコンテナで.ミーティング開始時に4種類の内容タイプを属性として設定したサブボードを,ボード全体を分割するように設置する.
コンテナの作成はいつでも行うことが可能で,前章で述べたiStickyを用いることで明示的に作成することができる.また,サブボード間での要素の移動が行われた場合,新たなコンテナを生成する.例えば,トピック属性のサブボードから議論属性のサブボードにボード要素が移動した場合には,移動したボード要素はトピック属性のサブボードに残し,移動したボード要素のコピーをコンテナに配置して,議論属性のサブボード内に生成する.これによって,トピックごとに議論属性のコンテナを生成することができる.議論属性のサブボードからタスク属性のサブボードにボード要素が移動した場合,あるいは進捗属性のサブボードにボード要素が移動した場合には,移動操作を行った参加者の名前がタイトルとして設定されたコンテナをそれぞれのサブボード内に生成する.さらに,議論属性のサブボードに含まれるコンテナが,サブボードの外側に移動した場合には,そのコンテナに含まれる内容を保持したまま,より柔軟に領域を利用できるサブボードに変換する.
コンテナやサブボードを単なるボード要素をグルーピングするための道具としてだけではなく,分類・整理しながら話し合いを行うためのツールとして利用することで,話し合いを行いながらボードの内容を分割することが可能になる.

図5.2: ボードコンテンツとコンテナ
コンテナによる構造化を実現した当初は,コンテナを用いることで話し合いの内容をトピックごとに分割することができ,ミーティングが円滑に進行するものと期待した.実際に本機能を運用して記録されたコンテンツを図に示す.2ヶ月間の運用を行ったが,図とほぼ同様の結果であった.
記録されたコンテンツを観察したところ,
-
議論属性のコンテナが他の属性のコンテナに比べて,コンテナに配置される内容の自由度が高く,内容が適切に分割されなかった.
-
コンテナ内に配置されたボード要素間の関係が表せなかった.
ということが分かった.また,実際に利用したミーティング参加者の意見から,コンテナ作成のための操作が直感的でなく習熟が困難であったことから,むしろ,ミーティングの進行を阻害してしまう結果となった.
5.2.2 木構造による構造化
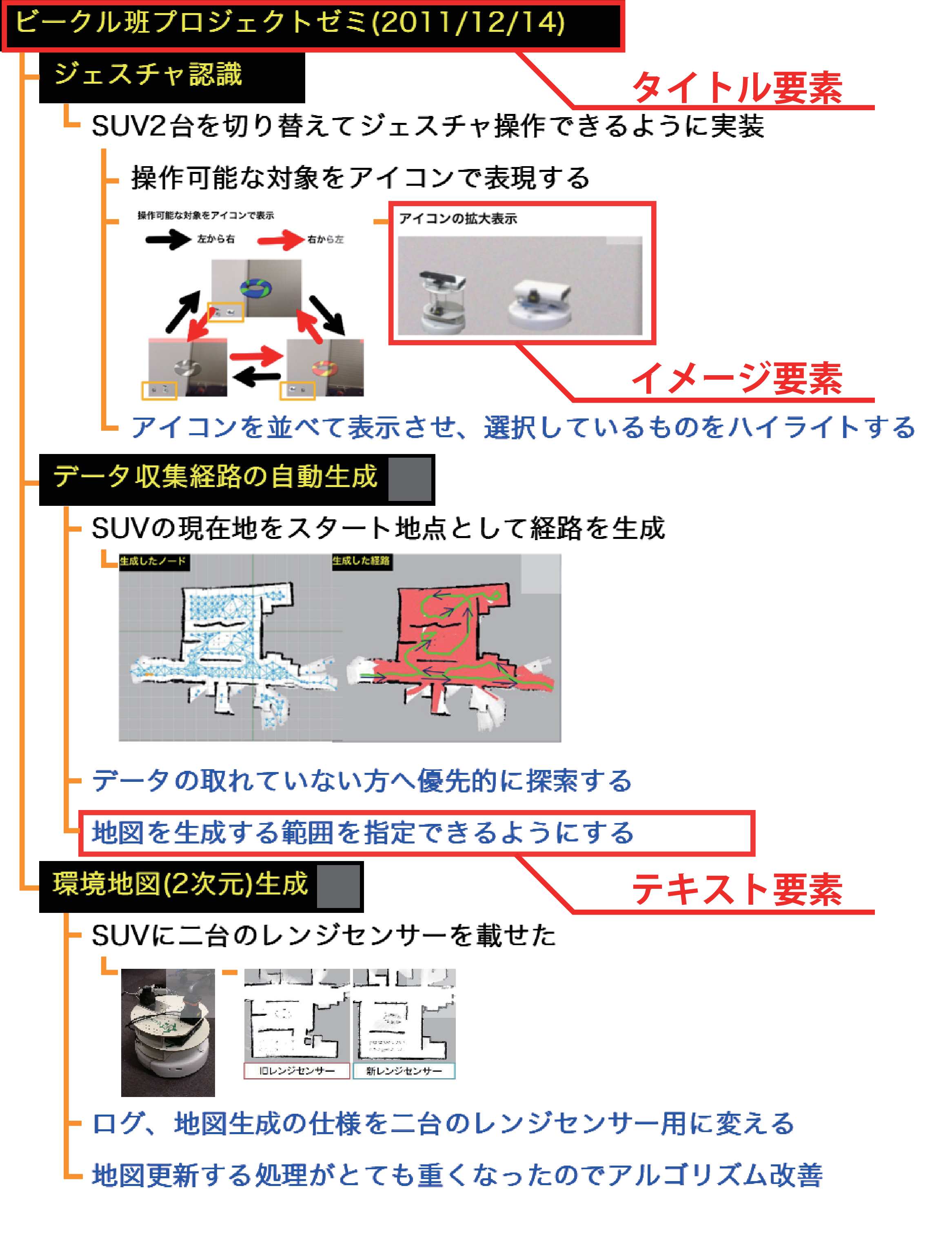
図5.3: ボードコンテンツと木構造
コンテナによる構造化の実装は,ミーティングの進行を阻害してしまう結果になってしまった.しかし,話し合いの内容を整理しながら話し合うことがボードコンテンツの構造化に繋がることが分かった.そこで,別の手法を用いて話し合いの内容を整理しながら話し合える,前述の問題点を考慮した機能を実現する必要があった.
そこで,コンテナが抽象的に表現している入れ子の木構造はそのままに,直接ボード上に木構造を表現する事にした.具体的には,図に示すように,ボードの最も左上にあるボード要素(と呼ぶ)をルートノードとした木構造を作成できるようにした.参加者は新たなボード要素を提示する前に,そのボード要素が,すでに表示されているどのボード要素の子になるのかを考慮する必要がある.ただし,任意のタイミングでボード要素を選択して,親の付け替えや移動ができる.なお,図中の各ボード要素間を結ぶ木構造を表す線は,説明のため便宜的に書き加えたものである.実際には,親ノードを決定しようとするときに,親ノードと選択しているボード要素との間,親ノードの祖先の間に木構造を示すガイド線が表示される.本研究では,このそれぞれのボードコンテンツに作成された木構造における親子関係を,ボード要素間のリンクとして扱う.
また,タイトル要素の直下の子ノード,第2階層に位置するボード要素は,トピックタイトルを表すというルールが自然にでき,当初の狙い通り,話題ごとにボードコンテンツが整理されるようになった.このそれぞれのボードコンテンツに作成された木構造における親子関係を,ボード要素間のリンクとして扱う.
コンテナによる構造化の問題点で,議論属性のコンテナが適切に分割されない,という問題点を挙げた.木構造の場合は,親子関係,兄弟関係によって,ボード上に表示されている全てのボード要素の関係が表されており,関係がコンテナよりも把握しやすい.そのため,ミーティング参加者同士で話し合って親の付け替えを行ったり,移動をしながら話し合いを進める事が容易になり,結果として構造も整理される事となった.
また,習熟に関しても,ミーティング中に木構造を作成することを要請した当初は,参加者にとまどいがあったが,ミーティング参加者はすぐに習熟した.これは,木構造は,あるボード要素を提示したときに,既に表示されているボード要素の親とするか,子とするか,兄弟とするかという判断をするだけであることがひとつの要因として挙げられる.コンテナによる構造化の場合,コンテナを作成する手間,コンテナの開閉をする手間が必要であったが,木構造による構造化の場合は親子関係を作るためにそのような操作は必要ない.手間の低減と手順の簡略化が習熟のしやすさに繋がったと考えられる.
5.3 本章のまとめ
本章では,前章で説明した継続的ミーティング支援システムの構成要素であるTimeMachineBoardを用いて行うミーティング内容の構造化手法について述べた.
ミーティング内容の構造化とは,話し合いを円滑にするために,ボードに提示された話し合いの内容を表すボード要素をまとめたり移動したりすることを指す.ミーティングを観察すると,ボード要素を自由に配置できる場合であっても,内容が近いボード要素を近くに寄せたり,内容同士の関係によって少しずらして配置したり,並列に並べたりする.
そこで,より効率的にミーティング内容を構造化できるようにするため,まず,コンテナを用いたグルーピングによる構造化を実現した.機能を実現した当初は,コンテナを用いることで話し合いの内容をトピックごとに分割することができ,ミーティングが円滑に進行するものと期待した.しかし,むしろ,ミーティングの進行を阻害してしまう結果となった.
次に,木構造による構造化を実現した.木構造による構造化では,ボードに表示されている全てのボード要素間の関係を獲得できる.また,属性を廃止することによって適切な粒度でボードの内容が分割されるようになった.さらに,親子関係を付与する操作だけで構造化できるため習熟が容易であった.
ミーティング参加者が,ミーティングを円滑に進行するためにボードコンテンツの構造化を行うことによって,参加者に特別な負荷をかけることなくボードコンテンツの内部構造を獲得することができる.そして,獲得したボードコンテンツの内部構造を利用することで,単一のミーティングにおいていくつのトピックがあるか,イメージの内容を表すキャプションなどといった情報を獲得することができる.
6 ボードコンテンツの再利用
6.1 ボードコンテンツの検索と閲覧
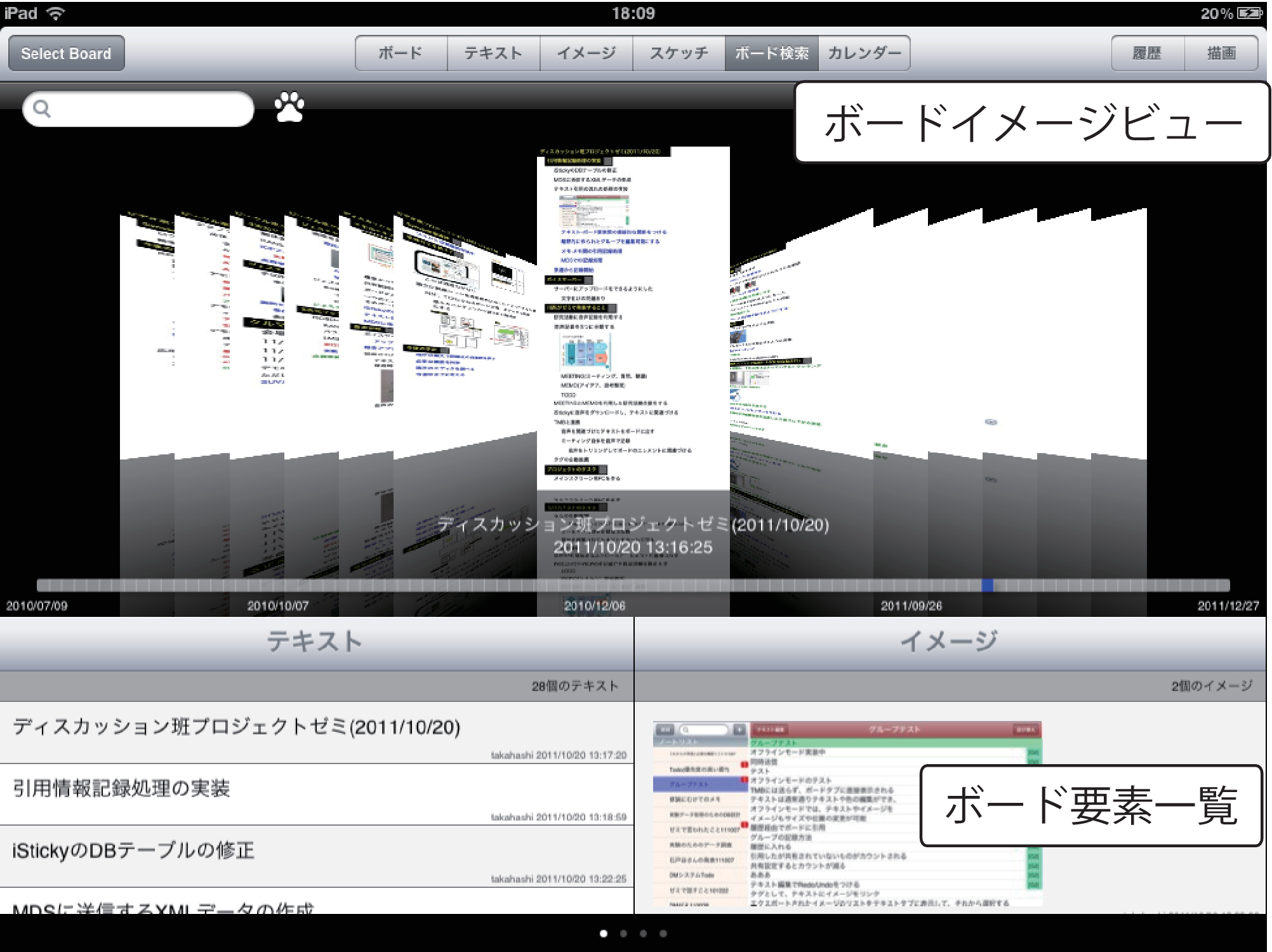
図6.1: 検索インタフェース
過去のミーティングで作成されたボードコンテンツをいつでも手軽に参照できるようにするために,iStickyの機能として図に示すような検索インタフェースを開発した.検索インタフェース上部には,過去に行われたミーティングの最終状態を表す画像(この画像をと呼ぶ)を時系列順に並べたボードイメージビューを配置した.ビューを左右にスクロールすることで蓄積されたボードコンテンツを一覧でき,必要に応じて,選択したボードイメージを拡大して詳細に閲覧することができる.
ボードイメージビューに表示されるボードコンテンツの一覧は,iStickyのユーザー(iStickyがインストールされたタブレット型デバイスの所有者)が参加した全てのボードコンテンツが新着順に表示され,必要に応じてボードコンテンツに含まれるテキストを用いた全文検索,テキストから抽出されたキーワード,ボード要素の情報,プロジェクト情報,参加者の情報などを組み合わせて検索することで表示内容を絞り込むことができる.
ボードイメージビュー下部にはタイムラインバーを配置し,ボードイメージビューをスクロールせず,すばやく必要なボードコンテンツを見つけられるようにした.タイムラインバーは記録されているボードコンテンツの中で一番古いものと最新のものの時間を左右にプロットし,タイムラインバー内の任意の場所を選択するとポップアップでボードイメージと詳細情報が表示され,ドラッグ操作を行うと次々に情報が入れ替わって表示される.
6.2 ボードコンテンツの引用
検索して閲覧するだけでなく,進行中のミーティングに過去のミーティング内容の一部を明示的に提示して話し合うことで,議論の繰り返しを防ぐことができると考えられる.
そこで,過去のボードコンテンツの一部分の引用を実現するために,検索インタフェース下部にボードイメージビューで選択しているボードコンテンツに含まれる画像・テキストなどのボード要素を一覧表示するビュー(ボード要素一覧)を配置した.
ボード要素一覧から引用したいボード要素を選択すると,ポップアップで情報が表示される.選択したボード要素が画像の場合は拡大縮小して内容を確認し引用することができる.
ボード要素を選択して引用を行うと,現在のボードに,選択したボード要素が表示される.ボード上に提示された要素は引用が行われているということを明示するためにハイライトされ,参加者がiSticky上でその要素を選択すると,検索インタフェースに遷移し,引用された要素を含むボードコンテンツが表示される.記録される引用情報は,引用を行ったユーザー,引用元・引用先のボードコンテンツの識別子と引用元・引用先のボード要素の識別子から構成される.引用情報にはボードコンテンツ間のリンク情報が含まれているため,複数のボードコンテンツ間にまたがるボード要素間リンクとして扱うことができる.

図6.2: ボードコンテンツのグラフ
図に引用機能によって関連付けられた継続的な複数のボードコンテンツの一部を示す.過去に行われた議論と進行中の議論が結びつけられて蓄積されていくことで,あとで継続的なミーティングによって記録された複数のボードコンテンツを見返す際の手がかりとして利用できるだけでなく,トピックの抽出や要約などの高度な応用を実現する際の重要な情報として利用できる.
そして,それぞれのボード要素をノードとし,章で説明したそれぞれのボードコンテンツに対して作成された木構造における親子関係から獲得したボード要素間の関係と,引用によって獲得した複数のボードコンテンツ間にまたがるボード要素間の関係をエッジとして定義することで,複数のボードコンテンツを一つのグラフとして扱うことができる.
6.3 議論コンテンツの引用
過去の議論コンテンツを検索し閲覧するだけでなく,ミーティング中に過去の議論コンテンツの一部をボードに表示することで,過去の議論の文脈を意識しながら議論することができ,同じ議論の繰り返しや議論のヌケ・モレを防ぐことにつながると考えられる.
そこで,過去の議論コンテンツの一部分を抜き出してボードに入力する(以下ではこの行為をと呼ぶ)ために,検索インタフェース下部にボードイメージビューで選択している議論コンテンツに含まれる画像・テキストなどのボード要素一覧を表示するボード要素リストビューを配置した.
ボード要素リストビューから引用したいボード要素を選択すると,ポップアップで情報が表示される.選択したボード要素が画像の場合は拡大縮小して内容を確認し引用することができる.テキストの場合はボード要素をそのまま引用するか,内容を編集してボードに入力するかを選択することができる.
ボード要素を選択して引用を行うと,ボードに選択したボード要素が表示されて,引用情報が記録される.引用情報は,引用を行ったユーザー,引用元・引用先の議論コンテンツの識別子と引用元・引用先のボード要素の識別子から構成される.引用情報には議論コンテンツ間のリンク情報が含まれているため,複数ミーティング間の文脈情報として扱うことができる.
ここで,テキストの場合は,元の議論コンテンツに含まれるテキスト情報を議論の俎上に上げる場合に,その内容を編集したいことがよくある.例えば「要約機能の実装(公開は今週末を予定)」というテキストを,その後のミーティングで公開したことを報告するときに,「要約機能の公開」としたい場合などである.この場合の行為はテキスト情報の引用ではなくリンク付けとなる.
本インタフェースを用いた引用を実現した2010年9月から2011年2月までの間に引用は158回行われた.このうち直前のミーティングからの引用は108回,2回前のミーティングからの引用は39回,それ以前のミーティングからの引用は11回であった.結果をみると,直前のミーティングから引用されることが多かった.今後,長期間の運用を通して議論コンテンツの数が増えるに従い有用な議論が埋もれてしまう可能性もあるため,議論参加者が過去の議論を発見できるような仕組みが必要であると考えられる.
6.4 ボードコンテンツの性質
本システムは,2008年9月から運用を行っている.記録の対象は著者の所属する研究室で行われている3つの研究プロジェクトのミーティングであり,1年間にプロジェクトあたり20?30回行われている.運用を行う中でさまざまなフィードバックを受けて改良を加え,ユーザビリティの向上,ボードコンテンツの検索・閲覧を実現した.
現在,検索・閲覧が可能なボードコンテンツは249個(2009年9月から2011年12月までに行われたプロジェクトミーティング)である.ミーティングの平均時間はおよそ1時間53分であった.また,ボードに入力された情報の内訳はストロークが262本,テキストが5428個,画像およびスケッチが760個であった.このうちテキストは1ミーティングに平均21.8個含まれており平均長は全角48.2文字で,ホワイトボードと比較するとボードに提示されるテキストの量が非常に多い.また,画像およびスケッチは1ミーティングに3.1個含まれており,ミーティング参加者が積極的に画像を用いて説明していることが分かる.
また,引用機能を実現した2010年9月から2011年12月までに引用は599回行われた.このうち直前のミーティングからの引用は431回,2回前のミーティングからの引用は121回,それ以前のミーティングからの引用は47回であった.
3つの研究プロジェクト(個人用知的移動体,会議支援,マルチメディアコンテンツ)は2人から4人のメンバー(学部4年生,博士前期課程の学生)とプロジェクトリーダー(博士後期課程の学生,教職員)で構成され,5年から10年間,同じテーマで研究が続けられている.学生は学部4年生から博士前期課程卒業までの3年間,基本的に同じプロジェクトに所属して研究を行う.そのため,4月に新しくプロジェクトに配属された後の一時期を除いて,参加者は同じプロジェクトの他の参加者がどのような研究を行っているか,問題は何か,目的は何かといった事柄を共有してミーティングに参加している.
著者の所属する研究室で行っているプロジェクトミーティングは,各参加者が前回のミーティングから今回のミーティングの間に行った活動の進捗,活動の中で明らかになった問題点や課題,およびそれらについて考えたことをボードに提示して報告することから始まる.各参加者は,一人の参加者がボード要素を提示できるボード上の領域が限られていることから,話し合いたいことを要約して提示する.そして,その報告を受けて議論がなされる.この議論が平均2時間のミーティング時間の大半を占める.最後に,議論の経過や結論,議論の結果発生したタスクをボードに書き加える.これを参加者の人数分繰り返す.
最後に,ボードの内容が過不足ないか,重要な議論の結果が漏れていないかを全員で確認し,必要ならボードの内容に手を加えて,ミーティングを終了する.ミーティングが終了するとサーバに保存され,閲覧・検索,再利用が可能になる.
6.4.1 ボードコンテンツの内容と引用関係
表に,2011年11月8日から11月28日までに行われたプロジェクトミーティング(全9回,3プロジェクト各3回ずつ)のボードコンテンツに含まれるボード要素を内容別に分類した結果を示す.提示されたボード要素は238個で,そのうちタイトル要素やトピックタイトルなどボードの内容を構造化するためのものは41個(全9回のボードコンテンツに占める割合,17.2%),参加者が行った活動を報告するために出したボード要素は167個(70.2%)で,議論の結果としてボードに追加されたものは30個(12.6%)であった.
結果を見ると,本システムを用いて記録されたボードコンテンツに含まれるボード要素はその7割が報告によって構成されており,議論の経過や結果が1割強と少ないことが分かる.これは,議論をしながらボード要素を提示することが難しいこと,ボードの面積が限られていることに起因する.そのため,ボード要素として提示される議論の内容は,結論や重要なものが選択的に提示されている.重要かそうでないかボードに残すべきかどうかという判断はプロジェクトリーダーがミーティング中にその場で行って,参加者に指示することが多い.
このようにしてボードコンテンツとして残される議論の経過や結果は,単一のボードコンテンツに注目すると少ないが,それらが引用されて複数のボードコンテンツにわたって議論されることは少なくない.表に引用元(被引用)のボード要素の内容を分類した結果を示す.また表に引用先のボード要素の内容を分類した結果を示す.ボードコンテンツ1に含まれるボード要素Aがボードコンテンツ2に引用されたとき,ボードコンテンツ1(引用元)におけるボード要素Aの内容を分類したものが表で,ボードコンテンツ2(引用先)におけるボード要素Aの内容を分類したものが表である.
構造要素の被引用回数が15回(全被引用回数の31.9%),引用回数が17回(全引用回数の38.6%)と多いのは,ミーティング間におけるトピックの継続を表すために,トピックタイトルをミーティング間で引用することが多いためである.また,報告に分類されるボード要素の被引用回数が合わせて10回(全被引用回数の21.3%)と少ないのは,報告に分類されるボード要素はそのミーティングにおいて,それまでの活動を他の参加者と共有するために使われるためであると考えられる.そして,引用回数が合わせて27回(全引用回数の61.4%)と多いのは,過去のミーティングで話し合われた内容を引用して報告に利用しているためである.
そして,報告をきっかけに行われた議論の結果としてボードに追加された要素の被引用回数は22回(全被引用回数の46.8%)で,ボードに提示された議論の結果を示す要素のうち73.3%が次回以降のミーティングで引用されており,引用先では主に報告に分類されるボード要素として提示されている.引用回数が0回なのは,その場で行われた結果として追加されるボード要素のため,過去のミーティングから引用されることは少ないからである.
報告に分類されるボード要素の被引用回数が少ないことから,報告を次のミーティングで引用することはほとんどない.しかし,直接の引用関係になくとも,周辺のボード要素が引用され,報告と議論を繰り返しながら複数のミーティングに渡って提示されている.このような継続する話題を表すボード要素間の関係は,要約などの応用を実現する上で大きな手がかりとなる.
しかしながら,議論の経過や結果が詳細にボードコンテンツとして記録されていないため,長時間が経過してしまうと後から振り返ってその議論がどのような議論であったかを思い出すことは難しい.本研究では,この問題に対して,継続的かつ頻繁に行われるミーティングにおいては,ボードコンテンツに全ての議論内容が記録されている必要はなく,議論内容や結論を端的に表すボード要素が記録されていて,それがミーティング中に行われた議論を想起する手がかりになればいいと考えている.また,複数のボードコンテンツの内容を俯瞰する仕組みを提供することで,単一のボードコンテンツを閲覧して内容を把握するだけで議論を想起するのではなく,継続するミーティング全体の把握を支援できる.
6.4.2 ボード要素とアノテーション
また,報告に分類されるボード要素は,ボードコンテンツに占める割合が全体の7割と高い.ボード要素は,参加者が日常的に記述しているノートの一部分であり,また,その内容が適切でなければ他の参加者から指摘され,削除,編集が行われる.そうしてボードコンテンツの一部として残されたボード要素は,参加者の活動内容の要約であると考えられる.そこで,ボード要素の量的な特徴を分析するために節で述べたアノテーションについて調査を行った.また,ミーティング終了後プロジェクトリーダに,ミーティングで話された内容の中で,アノテーションに含まれる,プロジェクトメンバに覚えておいてほしい重要なキーワードおよび文をマーキングしてもらった.
表にボード要素,アノテーション,アノテーションの重要部分について平均文字数と平均自立語数(ミーティング9回の平均,一般的な不要語除去および連続する自立語の連結処理済み)を示す.文字数でみると,ボード要素として現れている内容はアノテーション全体の9.5%(17.4/182.4)であり,自立語数でみると12.5%(3.3/26.5)と,9割の情報が欠落していることが分かる.ボード要素が個人の活動内容の要約であると見なすためには,ボード要素の内容がアノテーションの内容を適切に簡略化していなければならない.
そこで,ボード要素とプロジェクトリーダが選択したアノテーションの部分を比較した.文字数でみると,ボード要素はアノテーションの重要部分の41.1%(17.4/42.3)で,自立語数でみると52.3%(3.3/6.3)であった.ボード要素と重要部分の自立語で重複するものは1ボード要素あたり1.4個で,重要とされる部分の内容を最低限含んでいることが分かる.
以上の結果から,報告に関するボード要素が参加者の活動内容の要約と見なせる可能性がある.ただし,ボード要素に含まれる自立語が活動内容を適切に表すキーワードであるかどうかを調査して,より詳細に分析する必要がある.
このように,ボード要素を個人の活動内容を想起するためのきっかけとして利用することは可能であり,ボード要素からアノテーションを閲覧できるようなインタフェースを実現することで,より詳細な想起を支援することができると考えられる.
6.5 ミーティング文脈の可視化による議論想起支援
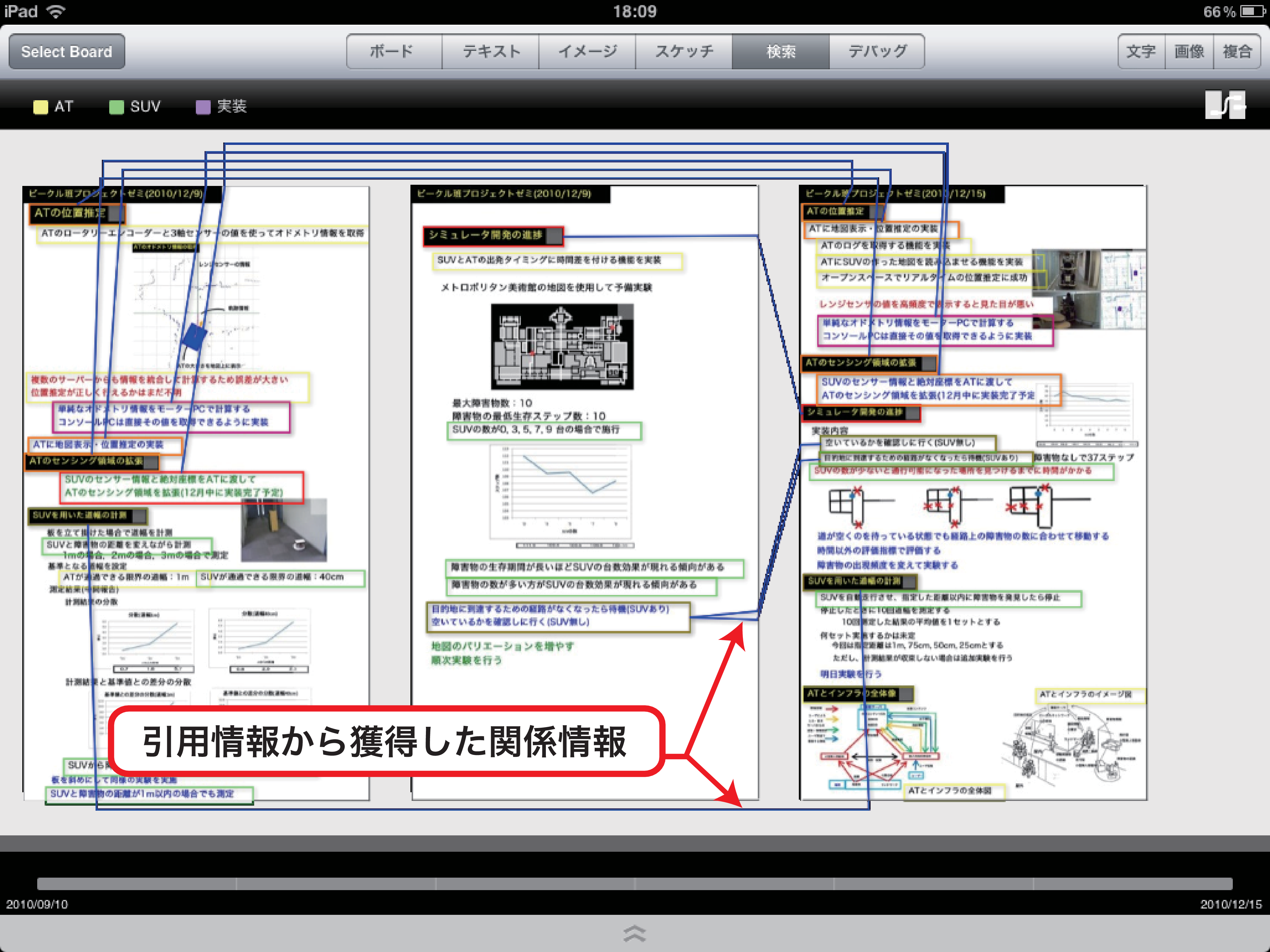
図6.3: ミーティング文脈の可視化インタフェース
上述の検索インタフェースは,個々のミーティングの内容を閲覧するためのもので,複数のミーティング間の文脈を意識することは難しい.例えば,あるミーティングにおいて実装の進捗について報告があったとき,その実装がなぜ必要となったのかということを確認することができれば,同じ議論を繰り返す必要がなくなり,進捗に対する意見やアドバイスが過去の議論を踏まえたものになると考えられる.
過去の議論を検索してボード要素の引用をすることで,ボード要素の引用・被引用関係から,過去のミーティングと現在のミーティングの間の関係情報を獲得することができる.そして,関係情報を議論コンテンツの一部として蓄積していくことで,複数ミーティング間の文脈情報として扱うことができる.この文脈情報を可視化し,ミーティング間の文脈を意識しながら議論コンテンツを閲覧するためのインタフェースを検索インタフェースと同じくiStickyの機能として開発した.
ボード要素の引用・被引用関係を単純に線で結び可視化するだけでは,全体の文脈が分からなくなってしまう.そこで,ボードイメージを背景として表示することで,ミーティングの内容を確認しながら複数のミーティング間の関係を閲覧できるようにした.具体的には,図に示すように,ボード要素をノード,文脈情報をノードとノードを繋ぐエッジとして可視化する.これによって,一連の議論がどのようにして継続して続けられてきたかを把握することができるようになる.
さらに,このインタフェースで表示されているボード要素の中から必要なものを選択して引用することもできるようにした.複数ミーティング間の文脈を意識しながらノードを選択できるようにすることで,検索インタフェースを用いて引用を行うよりも,より過去に遡ったミーティングの議論内容を発見して引用できるようになると考えられる.
このインタフェースをミーティング中に利用することで,過去の議論内容を想起するだけでなく,過去に行ってきたミーティングの文脈を意識することができる.そして,発見した有用な過去の議論を現在の議論の俎上に上げて参加者間で共有することで,ミーティングをよりよいものにできる.
6.6 本章のまとめ
本章では,ミーティング中に過去に行われた議論内容を検索して引用するための仕組みと,獲得した引用・被引用関係を用いて複数ミーティング間の文脈を可視化することで,過去の議論の想起を支援する仕組みについて述べた.
1回1回のミーティングの記録・構造化に関する研究は数多く行われているが,一般に行われている小規模のミーティングは散発的に行われるものではなく,個人と組織の知識活動の中で継続的に行われるものである.それぞれのミーティングから過去のミーティング記録への関係情報を獲得・蓄積し適切に利用することができれば,過去の議論を踏まえた新たな議論を促進し,個人の,ひいては組織全体の知識活動を活性化することができるであろう.
|
タイプ |
詳細 |
個数 |
全体に占める割合 |
平均出現数 |
|
構造要素 |
ボードを構造化する要素 |
41 |
17.2% |
4.6 |
|
報告 |
タスクの進捗 |
108 |
45.4% |
12.0 |
|
課題,考えたこと |
59 |
24.8% |
6.6 |
|
|
小計 |
167 |
70.2% |
18.6 |
|
|
議論 |
議論を受けて出たタスク |
18 |
7.6% |
2.0 |
|
議論の経過,結果 |
12 |
5.3% |
1.3 |
|
|
小計 |
30 |
12.6% |
3.3 |
|
|
合計 |
238 |
100.0% |
26.4 |
|
タイプ |
詳細 |
被引用回数 |
提示回数に対する割合 |
全被引用回数に対する割合 |
|
構造要素 |
ボードを構造化する要素 |
15 |
36.6%(15/41) |
31.9%(15/47) |
|
報告 |
タスクの進捗 |
10 |
9.3%(10/108) |
21.3%(10/47) |
|
課題,考えたこと |
0 |
0.0%(0/59) |
0.0%(0/47) |
|
|
小計 |
10 |
6.0%(10/167) |
21.3%(10/47) |
|
|
議論 |
議論を受けて出たタスク |
14 |
77.8%(14/18) |
29.8%(14/47) |
|
議論の経過,結果 |
8 |
66.7%(8/12) |
17.0%(8/47) |
|
|
小計 |
22 |
73.3%(22/30) |
46.8%(22/47) |
|
|
合計 |
47 |
19.7%(47/238) |
100% |
|
タイプ |
詳細 |
引用回数 |
提示回数に対する割合 |
全引用回数に対する割合 |
|
構造要素 |
ボードを構造化する要素 |
17 |
41.5%(17/41) |
38.6%(17/44) |
|
報告 |
タスクの進捗 |
22 |
20.4%(22/108) |
50.0%(22/44) |
|
課題,考えたこと |
5 |
8.5%(5/59) |
11.4%(5/44) |
|
|
小計 |
27 |
16.2%(27/167) |
61.4%(27/44) |
|
|
議論 |
議論を受けて出たタスク |
0 |
0.0%(0/18) |
0.0%(0/44) |
|
議論の経過,結果 |
0 |
0.0%(0/12) |
0.0%(0/44) |
|
|
小計 |
0 |
0.0%(0/30) |
0.0%(0/44) |
|
|
合計 |
44 |
18.5%(44/238) |
100% |
|
タイプ |
平均文字長 |
平均自立語数 |
|
テキストボード要素 |
17.4 |
3.3 |
|
アノテーション |
182.4 |
26.5 |
|
アノテーションの重要部分 |
42.3 |
6.3 |
7 継続的ミーティング内容からの重要要素の発見とその評価
本章では,前章までに説明したミーティング支援システムを継続的に運用することによって,得られたボードコンテンツから重要な要素を自動的に選択する手法を実現し、その評価を行った.
7.1 評価対象データ
2010年4月から2012年3月までの2年間について分析を行った.4月は新たなテーマでのミーティングが始まる時期で,3月は学生が卒業していく時期にあたる.2年間に記録されたボードコンテンツに含まれるテキスト要素とイメージ要素の数と割合を表に示す.表中のテキスト要素の数にはタイトル要素は含まれない.全体としては2年間の130セッションで3394個のボード要素が提示され,テキスト要素が2881個(84.9%),イメージ要素が513個(15.1%)であった.年度別に見るとボード要素のテキスト要素とイメージ要素の比率はほぼ同じであった.ただし,プロジェクトごとに見るとばらつきがあり,プロジェクトAではイメージが多用される傾向にある.
テキスト要素のみの年度・プロジェクトごとの内訳を表に示す.2年間に記録された2881個のテキスト要素に対して要約の正解データを作成するために,重要だと思われる要素に対してマーキングを行った.まず,ボードコンテンツを開いて,ボードコンテンツに含まれる各ボード要素に対して「重要である」とマーキングするための専用アプリケーションを作成した.先述したように,重要な要素の定義は「継続的な複数のミーティングにおける,プロジェクトにとって重要な要素」とする.次に,それぞれのプロジェクトのリーダーと構成メンバー1名(両名ともミーティング参加者)2名ずつ(3プロジェクトで計6名)に,年度ごとのデータに対して「新たにミーティングに参加する学生のために,1年間のミーティング内容のうち,全体の30%を抜粋してください」という課題を与え,専用アプリケーションで,相談しながらマーキングしてもらった.以降,この手順によって重要であるとマーキングされた864個(30%)のテキスト要素を,それ以外をと呼ぶ.
分析対象のテキスト要素の属性は,大別すると以下の4種類になる.
-
要素そのものを表す情報}
要素の位置やサイズ,文字色,文字列の長さ,要素の種類,提示された時間
-
構造から得られる情報}
エッジの数,木構造中のノード位置,子要素の数,子要素の種類,親要素の種類
-
引用情報から得られる情報}
引用回数,親の引用回数,子の引用回数,引用された要素か,親/子が引用された要素か
-
テキスト解析結果から得られる情報}
これらのテキスト要素の属性を,文字色やはい・いいえで計数されるカテゴリデータについては表に,また,引用回数などのカウントデータとX座標などの量的データについては表(全体)と表(年度別)にそれぞれ示す.
要素そのものが表す情報で,位置や幅,提示された時間は値のばらつきが大きい.また,文字色はその色の意味合いや使いかたがプロジェクトごとに違っているが,黄色は背景が黒色になり,他の色に比べて一番目立つ色でタイトル要素にも利用されているため,プロジェクトに共通してトピックを表す色として利用されている.
構造から得られる情報で,「親の?」「子の?」とあるのは,ある要素の木構造における親ノード,子ノードの種類や出現数を示す.なお構造が木構造のため親ノード数は常に1である.また,ノード位置とは木構造中のルート要素(タイトル要素)からの階層の数を表しており,タイトル要素の子要素が1,孫要素が2となる.
引用関係から得られる情報で,「引用された」はある要素が,過去の他のミーティングから引用されてきた要素であるか否かを示し,「引用回数」はある要素が,継続するミーティングで引用された回数を示す.2年間のミーティングで引用は690回行われており,引用機能が日常的に利用されていると考えられる.なお,引用は同一プロジェクトのセッション間で行われており,プロジェクトが異なるもの同士で引用が行われたことは一度もなかった.
テキスト解析結果から得られる情報は,テキスト解析の前処理として要素に含まれるテキスト情報をIgo(Igo - Java形態素解析器,http://igo.sourceforge.jp/)を用いて形態素解析を行い,名詞のみを抽出し,名詞名詞連結によって複合名詞を生成した.以後,この前処理済みの名詞を単にと呼ぶ.次に式()で表されるtfidfの計算を行った.tfidfは一般的に用いられる単語に対する重み付けの手法であり,多くのドキュメントに出現する一般的な語の重みが低く,特定のドキュメントにしか出現しない語の重みが高くなる.
式(1) \mathrm{tfidf} = \mathrm{tf} \cdot \mathrm{idf}
式(2) \mathrm{tf_{i,j}} = \frac{n_{i,j}}{\sum_k n_{k,j}
は,式()で計算される.ここで,
は,ある語
のボードコンテンツ
における出現回数,
はボードコンテンツ
における総語数である.以降この
を語の出現頻度と呼び,「語の出現頻度の合計」は,ひとつのテキスト要素に含まれる語の
の合計である.またidfは,式()で表される.
式(3) \mathrm{idf_i} = \log \frac{|D|}{|\{d: d \ni t_{i}\}|}
ここで,は総ボードコンテンツ数(ここでは,2年間130回のボードコンテンツをドキュメント群とする),
は語
を含むボードコンテンツ数である.「tfidfの合計」は「語の出現頻度の合計」と同様に,ひとつのテキスト要素に含まれる語の
の値を合計したものである.
|
プロジェクト名 |
2010/4 - 2011/3 |
2011/4 - 2012/3 |
全体 |
|||
|
テキスト |
イメージ |
テキスト |
イメージ |
テキスト |
イメージ |
|
|
A |
415(75.6%) |
134(24.4%) |
682(79.7%) |
174(20.3%) |
1097(78.1%) |
308(21.9%) |
|
B |
488(88.1%) |
66(11.9%) |
407(93.6%) |
28(6.4%) |
895(90.5%) |
94(9.5%) |
|
C |
540(90.3%) |
58(9.7%) |
349(86.8%) |
53(13.2%) |
889(88.9%) |
111(11.1%) |
|
合計 |
1443(84.8%) |
258(15.2%) |
1438(84.9%) |
255(15.1%) |
2881(84.9%) |
513(15.1%) |
|
プロジェクト名 |
2010/4 - 2011/3 |
2011/4 - 2012/3 |
全体 |
||||||
|
正解 |
不正解 |
合計 |
正解 |
不正解 |
合計 |
正解 |
不正解 |
合計 |
|
|
A |
127 |
288 |
415 |
205 |
477 |
682 |
332 |
765 |
1097 |
|
B |
144 |
344 |
488 |
122 |
285 |
407 |
266 |
629 |
895 |
|
C |
162 |
378 |
540 |
104 |
245 |
349 |
266 |
623 |
889 |
|
合計 |
433 |
1010 |
1443 |
431 |
1007 |
1438 |
864 |
2017 |
2881 |
|
属性名 |
値 |
2010/4 - 2011/3 |
2011/4 - 2012/3 |
全体 |
||||||
|
正解 |
不正解 |
合計 |
正解 |
不正解 |
合計 |
正解 |
不正解 |
合計 |
||
|
文字色 |
黒 |
322 |
645 |
967 |
327 |
645 |
972 |
649 |
1290 |
1939 |
|
橙 |
2 |
10 |
12 |
3 |
4 |
7 |
5 |
14 |
19 |
|
|
赤 |
13 |
33 |
46 |
3 |
40 |
43 |
16 |
73 |
89 |
|
|
緑 |
4 |
32 |
36 |
12 |
38 |
50 |
16 |
70 |
86 |
|
|
青 |
50 |
131 |
181 |
40 |
187 |
227 |
90 |
318 |
408 |
|
|
黄 |
42 |
159 |
201 |
46 |
93 |
139 |
88 |
252 |
340 |
|
|
引用された要素か |
はい |
147 |
170 |
317 |
132 |
241 |
373 |
279 |
411 |
690 |
|
いいえ |
286 |
840 |
1126 |
299 |
766 |
1065 |
585 |
1606 |
2191 |
|
|
親が引用された要素か |
はい |
136 |
180 |
316 |
215 |
316 |
531 |
351 |
496 |
847 |
|
いいえ |
297 |
830 |
1127 |
216 |
691 |
907 |
513 |
1521 |
2034 |
|
|
子が引用された要素か |
はい |
51 |
114 |
165 |
90 |
102 |
192 |
141 |
216 |
357 |
|
いいえ |
382 |
896 |
1278 |
341 |
905 |
1246 |
723 |
1801 |
2524 |
|
|
親がイメージ要素か |
はい |
0 |
14 |
14 |
1 |
4 |
5 |
1 |
18 |
19 |
|
いいえ |
433 |
996 |
1429 |
430 |
1003 |
1433 |
863 |
1999 |
2862 |
7.2 実験方法
前節で説明した属性を用いてロジスティック回帰分析を行った.ロジスティック回帰分析は,結果が2値の場合に用いられる回帰分析手法で,複数の変数(説明変数)を用いて結果(目的変数)を推定するためのモデルを構築することができる.色や引用された要素かどうかなどの質的変数を扱えること,説明変数が目的変数にたいしてどの程度独立した影響力を持つのかを単純な値で扱えることから,ロジスティック回帰分析を用いた.
式(4) P(y|x_1,\cdots,x_i) = \frac{1}{1 + e^{-(\alpha + \beta_1 x_1 + \cdots + \beta_i x_i)}}
ここで,は目的変数,
は説明変数,
は切片,
は回帰係数を示す.また
は説明変数の組み合わせ
に対して
が1の値を取る条件付き確率(0.0?1.0)である.この条件付き確率をと呼ぶ.また,説明変数が目的変数に対してどの程度独立した影響力があるかをオッズ比と呼ばれる数値で表すことができる.
式(5) \frac{e^{-(\alpha + \beta_1 x_1 + \beta_2 (x_2 + 1) \cdots + \beta_i x_i)}}{e^{-(\alpha + \beta_1 x_1 + \beta_2 x_2 + \cdots + \beta_i x_i)}} = e^{\beta_2}
式()は,ロジスティック回帰分析において,ある説明変数を1増加させたときのオッズ比を表す.オッズ比が1であれば,説明変数
の値が変化しても正解確率に対する影響力は同じであり,1より小さければ,説明変数
の値が大きくなるほど回帰係数の値に応じて正解確率が下がり,1より大きければ,説明変数
の値が大きくなるほど回帰係数の値に応じて正解確率が上がる.
実験のため2年間に記録されたボードコンテンツを2010年4月?2011年3月(以降と呼ぶ)と2011年4月?2012年3月(以降と呼ぶ)の1年ずつに分け,2010年度のデータをロジスティック回帰分析の対象としてモデルを構築した.そして,構築したモデルを当てはめて正解の推定を行った.それぞれの年度のボードコンテンツに含まれるテキスト要素の属性を表,表,表に示す.
ロジスティック回帰分析を適用する前に,不適切な説明変数について除去・前処理を行った.まず,説明変数相互間の相関が強い属性,独立でない属性を除去した.このような説明変数が含まれたデータにロジスティック回帰分析を適用すると分析が失敗するためである.具体的には,要素のサイズ(幅と高さ)と文字列長に強い相関(要素の幅と文字列長の相関係数:0.862,要素の高さと文字列長の相関係数:0.643)が認められた.要素の幅の分散が大きい(幅の標準偏差が207.1)ことから文字列長を用い,説明変数から幅と高さを除去した.また,エッジ数が子ノード数,引用回数の合計数(厳密には親ノードへのリンク,被引用リンクが含まれる)のためエッジ数を除去した.次に,要素の文字色に関して,利用方法がプロジェクトごとに違う文字色を除去し黄色(プロジェクト共通で,黄色はトピックを表す文字色として利用される)のみを用いた.X座標,Y座標(ピクセル数で,画面は縦置きの1080x1920)は他の説明変数に比べて値が大きく,分析結果の比較が分かりにくくなるため,1000で割って用いた.同様の理由で提示された時間も60で割って用いた.また,2010年度のデータにおいて「親がイメージ要素か」は値が「はい」のとき,必ず不正解を示し,ロジスティック回帰分析に利用できないため説明変数から取り除いた.
なお,ロジスティック回帰分析にはR 2.15.0(http://www.R-project.org)を用いた.
|
属性名 |
正解 |
不正解 |
全体 |
|||
|
平均 |
S.D. |
平均 |
S.D. |
平均 |
S.D. |
|
|
X座標(px) |
79.1 |
77.1 |
107.9 |
121.9 |
99.3 |
111.2 |
|
Y座標(px) |
741.6 |
498.8 |
932.9 |
523.2 |
875.5 |
523.3 |
|
幅(px) |
529.8 |
207.1 |
460.8 |
215.4 |
481.5 |
215.2 |
|
高さ(px) |
55.3 |
12.6 |
53.1 |
10.6 |
53.7 |
11.3 |
|
文字列長 |
19.2 |
11.5 |
16.0 |
10.4 |
16.9 |
10.8 |
|
提示された時間(秒) |
1184 |
1869 |
1899 |
2415 |
1685 |
2288 |
|
エッジ数 |
3.64 |
2.09 |
2.03 |
1.63 |
2.51 |
1.93 |
|
ノード位置 |
2.07 |
0.69 |
2.38 |
0.90 |
2.29 |
0.86 |
|
引用回数 |
0.50 |
0.55 |
0.15 |
0.37 |
0.26 |
0.46 |
|
親の引用回数 |
0.56 |
0.56 |
0.36 |
0.51 |
0.42 |
0.53 |
|
子の引用回数 |
0.18 |
0.57 |
0.16 |
0.56 |
0.17 |
0.56 |
|
子ノード数 |
1.72 |
1.81 |
0.64 |
1.28 |
0.96 |
1.54 |
|
子イメージ数 |
0.44 |
0.67 |
0.02 |
0.15 |
0.14 |
0.44 |
|
語の出現頻度の合計 |
0.60 |
0.67 |
0.55 |
0.66 |
0.57 |
0.66 |
|
tfidfの合計 |
0.08 |
0.06 |
0.07 |
0.06 |
0.07 |
0.06 |
|
属性名 |
2010/4 - 2011/3 |
2011/4 - 2012/3 |
||||||||||
|
正解 |
不正解 |
全体 |
正解 |
不正解 |
全体 |
|||||||
|
平均 |
S.D. |
平均 |
S.D. |
平均 |
S.D. |
平均 |
S.D. |
平均 |
S.D. |
平均 |
S.D. |
|
|
X座標(px) |
74.0 |
100.2 |
108.6 |
155.2 |
98.2 |
141.8 |
84.2 |
42.3 |
107.2 |
75.0 |
100.3 |
67.7 |
|
Y座標(px) |
791.6 |
515.8 |
948.9 |
534.2 |
901.7 |
533.5 |
691.3 |
476.4 |
916.9 |
511.7 |
849.3 |
511.8 |
|
幅(px) |
522.4 |
213.9 |
451.3 |
218.5 |
472.7 |
219.5 |
537.3 |
200.1 |
470.3 |
211.9 |
490.4 |
210.6 |
|
高さ(px) |
56.1 |
15.5 |
53.3 |
13.6 |
54.1 |
14.3 |
54.4 |
8.6 |
52.9 |
6.2 |
53.4 |
7.1 |
|
文字列長 |
20.8 |
13.8 |
16.7 |
11.9 |
17.9 |
12.7 |
17.6 |
8.2 |
15.3 |
8.4 |
16.0 |
8.4 |
|
提示された時間(秒) |
1197 |
1909 |
1853 |
2406 |
1656 |
2287 |
1171 |
1829 |
1944 |
2424 |
1713 |
2289 |
|
エッジ数 |
3.46 |
1.95 |
2.01 |
1.61 |
2.44 |
1.84 |
3.83 |
2.21 |
2.05 |
1.66 |
2.58 |
2.01 |
|
ノード位置 |
2.08 |
0.69 |
2.28 |
0.90 |
2.22 |
0.85 |
2.05 |
0.69 |
2.49 |
0.89 |
2.36 |
0.86 |
|
引用回数 |
0.49 |
0.56 |
0.14 |
0.35 |
0.24 |
0.46 |
0.51 |
0.54 |
0.16 |
0.38 |
0.27 |
0.46 |
|
親の引用回数 |
0.41 |
0.53 |
0.28 |
0.48 |
0.32 |
0.50 |
0.71 |
0.56 |
0.43 |
0.52 |
0.51 |
0.55 |
|
子の引用回数 |
0.18 |
0.57 |
0.18 |
0.58 |
0.18 |
0.58 |
0.18 |
0.57 |
0.15 |
0.54 |
0.16 |
0.55 |
|
子ノード数 |
1.52 |
1.74 |
0.68 |
1.36 |
0.93 |
1.53 |
1.91 |
1.85 |
0.61 |
1.19 |
1.00 |
1.54 |
|
子イメージ数 |
0.41 |
0.70 |
0.02 |
0.17 |
0.14 |
0.44 |
0.47 |
0.65 |
0.01 |
0.13 |
0.15 |
0.43 |
|
語の出現頻度の合計 |
0.65 |
0.76 |
0.53 |
0.69 |
0.56 |
0.71 |
0.55 |
0.56 |
0.58 |
0.63 |
0.57 |
0.61 |
|
tfidfの合計 |
0.08 |
0.07 |
0.06 |
0.06 |
0.07 |
0.06 |
0.08 |
0.06 |
0.08 |
0.06 |
0.08 |
0.06 |
7.3 モデルの構築
次に,すべての属性を説明変数,正解か否かを目的変数としたロジスティック回帰分析を行った.その結果を表に示す.結果中の有意確率はWald検定によるもので,目的変数に対して傾きが有意であるかどうかを示す.
|
変数名 |
係数 |
標準誤差 |
p値 |
O.R. |
|
|
切片 |
-2.228 |
0.379 |
p<0.001 |
*** |
- |
|
X座標(px) |
-1.405 |
0.738 |
0.057 |
n.s. |
0.250 |
|
Y座標(px) |
-0.360 |
0.150 |
0.017 |
* |
0.700 |
|
ノード位置 |
-0.017 |
0.114 |
0.880 |
n.s. |
0.980 |
|
黄 |
-1.435 |
0.321 |
p<0.001 |
*** |
0.240 |
|
文字列長 |
0.036 |
0.008 |
p<0.001 |
*** |
1.040 |
|
提示された時間(秒) |
0.000 |
0.000 |
0.254 |
n.s. |
1.000 |
|
子ノード数 |
0.630 |
0.076 |
p<0.001 |
*** |
1.880 |
|
子イメージ数 |
2.585 |
0.292 |
p<0.001 |
*** |
13.260 |
|
引用された要素 |
1.047 |
0.170 |
p<0.001 |
*** |
2.850 |
|
親が引用された要素 |
0.692 |
0.174 |
p<0.001 |
*** |
2.000 |
|
子が引用された要素 |
-0.928 |
0.300 |
0.002 |
** |
0.400 |
|
引用回数 |
1.574 |
0.167 |
p<0.001 |
*** |
4.830 |
|
子の引用回数 |
-0.785 |
0.171 |
p<0.001 |
*** |
0.460 |
|
語の出現頻度の合計 |
-0.088 |
0.084 |
0.294 |
n.s. |
0.920 |
|
tfidfの合計 |
-0.256 |
1.925 |
0.894 |
n.s. |
0.770 |
ロジスティック回帰分析の結果から,変数を減らしながら,AIC(赤池情報量基準, Akaike Information Criteria)が最も低い最適なモデルを選択した.選択した最適なモデルを用いたロジスティック回帰分析の結果を表に示す.
テキスト解析結果の「語の出現頻度の合計」および「tfidfの合計」はモデルから除去された.テキスト解析結果の属性がうまく作用しなかったのは,テキスト要素が参加者がミーティングで話したいこと,ミーティングで話し合ったことを要約した内容であるため文章の絶対量が少ないこと,そして,ミーティングで話し合われる内容が専門的で特徴語が一般語のように頻出することなどが考えられる.また,文字列長に関してはオッズ比が1.030と他の説明変数に比べて結果に対する影響力が少なかった.
また,モデルには,構造情報と引用情報を利用した物が多く残った.「引用された要素」,「親が引用された要素」のオッズ比は2.810,1.970であり,引用された要素とその子要素が他のテキスト要素に比べて重要であることを示している.特に子イメージ数のオッズ比(12.590)が高い.これはイメージ要素がその親となるテキスト要素を説明するために使われることが多く,かつ参加者がイメージ要素を用いて説明を行うようなテキスト要素は,他のテキスト要素に比べて重要であるということを示している.
さらに,子ノード数,引用回数のオッズ比(それぞれ,1.890,5.000)が高いことからエッジが集中するような要素が他のテキスト要素に比べて重要であることが分かる.ただし,同時に文字色が黄色(背景色が黒,ミーティングではトピックを表す文字色として利用されている)であることと子の引用回数,「子が引用された要素」のオッズ比(それぞれ,0.230,0.460,0.400)が1以下であることから,タイトルノード直下(ノード位置:1)のトピックを表す要素がそうでない要素に比べて,重要ではないことが分かる.つまり,トピック名として使われるテキスト要素にはエッジが集中することが多いが,重要性が低いことを示している.
|
変数名 |
係数 |
標準誤差 |
p値 |
O.R. |
|
|
切片 |
-2.322 |
0.243 |
p<0.001 |
*** |
- |
|
黄 |
-1.486 |
0.311 |
p<0.001 |
*** |
0.230 |
|
文字列長 |
0.028 |
0.006 |
p<0.001 |
*** |
1.030 |
|
子ノード数 |
0.638 |
0.074 |
p<0.001 |
*** |
1.890 |
|
子イメージ数 |
2.533 |
0.284 |
p<0.001 |
*** |
12.590 |
|
引用された要素 |
1.033 |
0.168 |
p<0.001 |
*** |
2.810 |
|
親が引用された要素 |
0.678 |
0.172 |
p<0.001 |
*** |
1.970 |
|
子が引用された要素 |
-0.907 |
0.298 |
0.002 |
** |
0.400 |
|
引用回数 |
1.609 |
0.162 |
p<0.001 |
*** |
5.000 |
|
子の引用回数 |
-0.770 |
0.170 |
p<0.001 |
*** |
0.460 |
7.4 モデルの当てはめ
前項で示した,2010年度のデータに対するロジスティック回帰分析の結果から得られたモデルを2011年度のデータに当てはめ,すべてのテキスト要素について正解確率を計算した.そして,値の大きい順に並べ,上位から要約率に応じた個数のボード要素を選択した(すなわち,cut-off値を設定して正解・不正解を推定することはせずに,正解確率の高い順に選択した).その結果を表,図に示す.結果中の適合率は選択した結果にいくつ正解のテキスト要素が含まれるかを示し,再現率は選択された正解のテキスト要素が全正解要素に対していくつ抽出されたかを示す.F値は式()で表される適合率と再現率の調和平均(値域:0.0?1.0)で,検索性能を示すために用いられる.
式(5) \mbox{F値} = \frac{2 \times \mbox{再現率} \times \mbox{適合率}}{\mbox{再現率} + \mbox{適合率}}
正解の割合は全ボード要素の3割のため,要約率30%の場合,選択するボード要素の数と正解の数が同数になり,適合率と再現率が同値になる.
また,プロジェクトごとの要約率に応じた適合率の推移を表および図に示す.なお,確率順に並べ替えて選択するため,全体の結果はプロジェクトごとの結果の平均にはならない.
|
要約率(%) |
適合率(%) |
再現率(%) |
F値 |
|
10 |
91.61 |
30.54 |
45.80 |
|
20 |
88.85 |
59.44 |
71.23 |
|
30 |
73.49 |
73.49 |
73.49 |
|
40 |
61.67 |
82.52 |
70.59 |
|
50 |
53.28 |
89.04 |
66.67 |
図7.1: 要約率ごとの重要要素の発見性能
|
要約率(%) |
A |
B |
C |
全体 |
|
10 |
86.11 |
97.44 |
100.00 |
91.61 |
|
20 |
78.47 |
81.01 |
88.73 |
88.85 |
|
30 |
74.54 |
69.49 |
74.77 |
73.49 |
|
40 |
66.32 |
55.70 |
61.54 |
61.67 |
|
50 |
55.40 |
49.24 |
54.75 |
53.28 |
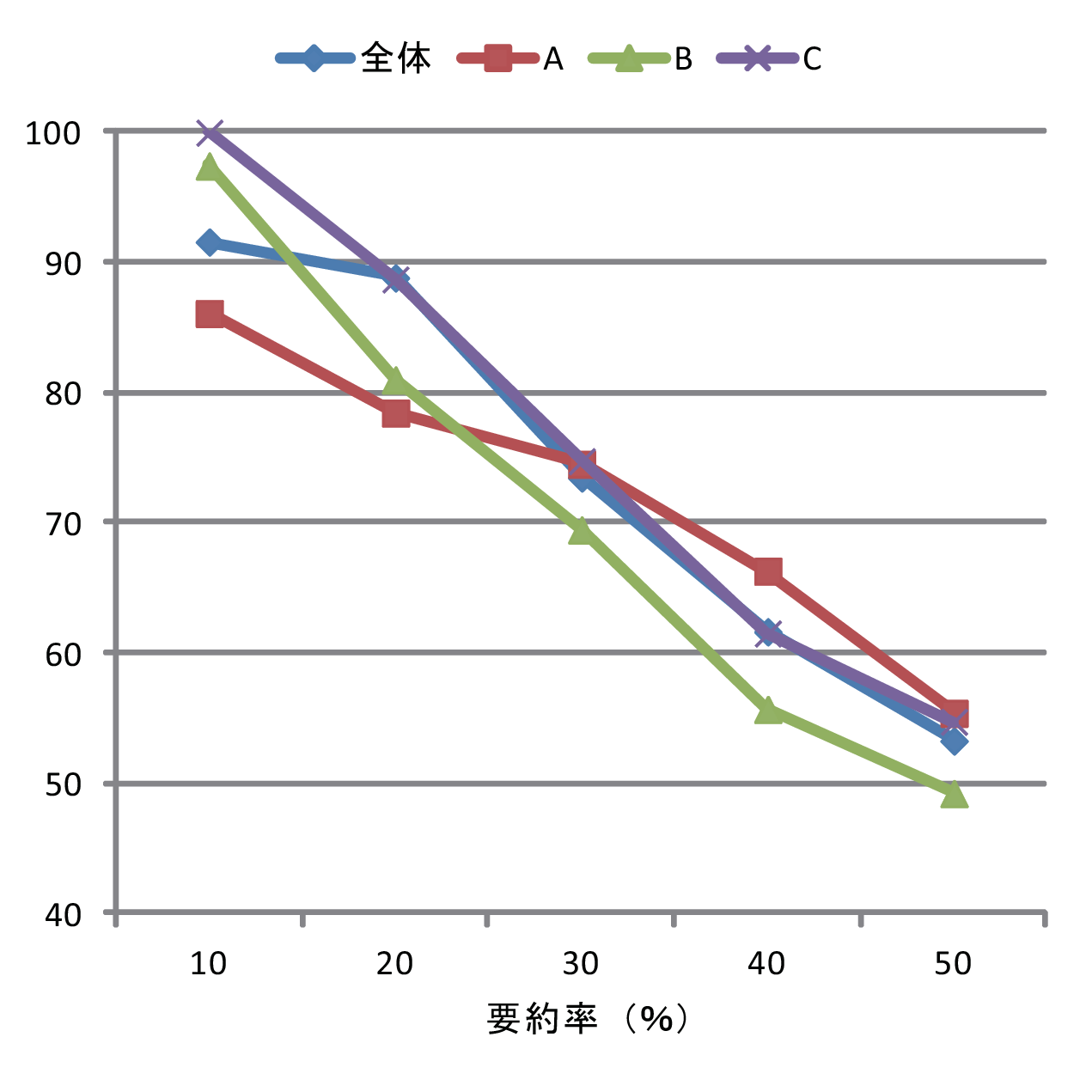
図7.2: プロジェクトごとの重要要素の発見性能(適合率)
7.5 実験結果の考察
この結果から,要約率30%以下の場合に適合率70%以上の性能を示し,選択される要素数が少なく再現率が低い要約率10%の場合を除いた要約率20%から50%のF値が平均70.52と安定した性能を示した.
表に示すロジスティック回帰分析の結果をみると,ミーティング中に行われる参加者の行動(木構造の付与,引用,要素の文字色の変更など)から自動的に獲得した,構造情報と継続的なミーティング間の関係情報が説明変数として重要な役割を果たしている.このようにして重要な要素を決定するために必要な情報を,ミーティングの進行を阻害せずに暗黙的に獲得できることが重要であると言える.
しかしながら,選択されるテキスト要素の数が正解と同数になる,要約率30%の適合率が精度73.49%と,8割を超えなかった.これにはいくつかの要因が考えられる.
まず,イメージ要素の影響が強いことがあげられる.表に示すように,2011年度のボード要素の構成では,イメージの数は15.1%(255個),イメージ要素を子ノードとしてもつテキスト要素は12.2%(175個,木構造のため,1つのテキスト要素が複数のイメージ要素を子に持つことがある)であった.すなわち,手がかりとなるイメージ要素の数が少ないために,イメージを手がかりとして利用できない場合に正解の推定が難しくなったと考えられる.例えば,プロジェクトAに比べて他のプロジェクトはイメージ要素の数が少なく,プロジェクトBでは,要約率が上がり選択する要素が増えると,性能が下がってしまった.
対策として,イメージ要素を増やして行くことが考えられるが,プロジェクトAで使われているイメージ要素の数が,ボードの面積や参加者が画像やスケッチを用意する手間を考えるとほぼ妥当な値であるといえる.
また,節で述べたように,要素の文字色が黄色(背景が黒)で子要素が引用されていて,かつ,子の引用回数が多い要素(すなわち,トピックを表すようなテキスト要素)は正解として推定されにくい.このような要素は2011年度のデータにおいて,8.8%(全テキスト要素1438個中127個,文字色が黄色で子ノード数が2以上,子ノードの引用回数が1回以上)あり,そのうち正解は43個で全正解431個中の10.0%存在する.この43個の内,正解と推定されたのは4個であり,性能を低下させる要因となっている.このようなテキスト要素を正解作成時に正解としてマークしたのは,そのテキスト要素の子要素のうち複数が重要であれば,意味的に子要素の内容を包含するそのテキスト要素が選択されたためであると考えられる.
さらに,子ノードがなく,親ノードも自身も引用されていない要素も正解として推定されにくい.このような要素は2011年度のデータにおいて395個存在し,全体の27.3%を占める.そのうち正解作成時に正解とマークされたのは21個で,全正解中の4.9%であり,正解として推定されたのは2個であった.正解と推定されなかった要素の内容は,「もっと細かい粒度,型を定めることでより詳細なトピックを抽出できる」や「アイデアとそれに関連するコンテンツの間に意味的関係を付与する」など,ミーティングで報告された内容に対する話し合いの結果であることが多かった.
このような問題に対処するためには,正解の推定に利用できる新たな情報を獲得し,重要要素の発見精度の向上を目指すことが重要である.また同時に,ユーザーの要求に応じた柔軟な情報提示の仕組みを実現することも重要である.例えば,継続する一連のミーティングの要約を提示する場合には,重要要素の文脈を表す親ノードの提示,重要要素を含むトピック全体の提示,キーワードによるトピックの絞り込みなどの機能を実現することが考えられる.このような機能が提供されれば,ユーザーがシステムの発見した重要要素を手がかりにして,複数のミーティングを効率的に閲覧できると考えられる.
7.6 本章のまとめ
本章では,継続的なミーティングによって記録される複数のボードコンテンツから重要な要素を副次的に発見することを目的として,ミーティング中に行われる参加者の自然な行動から,コンテンツの構造やコンテンツ同士の関係の情報を自動的に獲得できる仕組みを実現した.これらの仕組みによって獲得した,ボードコンテンツに関わる多様な情報を用いてロジスティック回帰分析を行い,70%程度の精度をもつ重要要素の発見手法を実現した.また,ロジスティック回帰分析の結果,木構造の付与や引用によって獲得できるグラフ情報が重要要素の発見に有効であることが確認できた.
ミーティングの記録・構造化に関する研究は数多く行われているが,ミーティング間の関係を適切に考慮しているものは少ない.一般に行われている小規模のミーティングは散発的に行われるものではなく,継続的に行われることが多い.過去のミーティング内容をより柔軟に利用することができれば,それまでの経緯を踏まえた議論を促進し,個人の,ひいては組織全体の知識活動を活性化することができるであろう.
8 関連研究
本章では,ボード,議論内容の記録,議論の構造化・可視化,メタ情報
ボードコンテンツの再利用,コンテンツのメタ情報の5点において本研究と関連する研究を挙げ,
それらの研究との相違点について述べる.
8.1 ボードに関する研究
小規模なミーティングに関する研究は,ホワイトボードを用いることを前提としたものが多い.電子的なホワイトボードに関する研究は,ElrodらのLiveboardを始めとして数多く行われている.これらのシステムでは,プロジェクタや大型ディスプレイを用いて電子的なホワイトボードを実現し,そこに描かれたストローク情報や転送されたテキストをどのように取り扱うか,電子的なペンをどのように利用するか,というペンとボードのユーザーインタフェースに主眼が置かれている.
また,ホワイトボードの内容を記録することに主眼を置いた研究には,WilcoxらのDYNOMITEのようにホワイトボードの内容と音声を関連付けて記録するものや,Zhangらの研究のようにカメラ映像を用いてホワイトボードの内容を記録するものなどが挙げられる.特に,GolovchinskyらのReBoardでは,カメラ映像でホワイトボードの変更点を監視して,変更が検出されたときのホワイトボードの内容を画像化し,Webブラウザを用いて閲覧できるようにすることで,ホワイトボードの内容の共有と検索を実現している.しかし,例えば,過去の議論内容を引用するなどの複数回の継続的なミーティングに対する支援は考慮されていない.
8.2 議論内容の記録に関する研究
会議で行われた議論の様子を記録する研究は数多く行われている.土田らはDiscussion Miningと呼ばれる対面式の会議を対象として,専用のミーティングルーム内で行われる会議をマルチメディア議事録として記録する研究を行っている.Discussion Miningでは,発表者がスライドを用いて発表を行い,参加者がそれについて議論を行う様子を,ミーティングルーム内に設置された複数台のカメラとマイクを用いて詳細な様子を記録する.また,参加者が発言する際には,専用のデバイスを用いて発言の開始と終了を入力する.その発言内容は書記が専用のツールを用いて記録し,映像・音声とあわせて議事録として保存される.保存された議事録はWebブラウザで閲覧する事ができる.
また,ChiuらはLiteMinutesと呼ばれるWebブラウザ上でマルチメディア議事録を作成するシステムの研究を行っている.LiteMinutesは,カメラが設置された部屋の中でスライドを用いた議論を行い,議論の様子を映像・音声情報として記録する.また,書記が無線ラップトップPC上で専用のツールを用いることで,議論内容をテキストとして入力する.テキストの入力された時間は自動的に取得され,その時間情報を用いて関連するスライドや映像・音声情報と入力されたテキストとの間にリンク情報を付与する.
映像・音声情報を用いて議論の様子を記録する研究例としてPortable Meeting Recorderがある.この研究では全方位カメラと4つのマイクを用いて記録を行う.4つのマイクによって発言者の方向の特定し,その方向の映像情報から人物抽出をする.このように音声処理や映像処理を組み合わせて,映像・音声情報を効率的に閲覧するためのインデックス情報を自動的に付与する.同時にマイクによって取得された発言内容は,音声処理によってテキスト化され,先ほどのインデックス情報と共にメタデータとしてXML形式で記述される.このようにして取得された映像・音声情報とメタデータは,MuVIEと呼ばれるインタフェースで閲覧できる.メタデータを利用することによって,特定の人物が行っている発言だけを閲覧したり,スライドやホワイトボードのビデオを閲覧したりする,といったようにユーザのさまざまな目的に合わせた閲覧方法を提供できる.
いずれの研究においても,議論の様子を映像・音声情報として記録している.そうすることによって,発言内容だけでは補えないノンバーバルな情報も合わせて閲覧できるため,より深い理解につながることが期待できる.しかし,たとえ適切なインデックス情報が付与されていたとしても,一般に映像や音声情報の閲覧には時間がかかる.
本研究においては,頻繁に行われる小規模なミーティングを対象としていることから,記録されたミーティングを再生するためではなく,主にミーティング内容を想起する手がかりとして議事録を作成している.Discussion Miningのように書記を用意して,テキストによる議事録を作成することができれば,発言に対する網羅性の高い議事録を作成する事ができるが,小規模なミーティングにおいては書記を用意することが困難である.そこで,ボードに提示された内容を並べ替えながら話し合った結果をボードコンテンツとして記録している.映像や音声を用いた記録に比べて情報量は少ないが,直近のミーティング内容を確認し作業を行ったり,ミーティングで話し合われた内容の一部を進行中のミーティングで提示したりといった用途には,手軽に閲覧できるボードコンテンツが適していると考えられる.
8.3 議論の構造化・可視化に関する研究
8.3.1 gIBIS
議論の内容を構造化・可視化することによって閲覧者の議論内容に対する理解を深めることが期待できる.その代表的な研究例として挙げられるのが,議論支援グループウェアのIBIS(Issue Based Information Systems)である.IBISでは,共同作業時の問題解決において,発言をIssue(問題),Position(立場),Argument(賛否)の3種類に分類し,それらの関係をリンクとするグラフ構造によって議論を構造化する.そして,IBISをベースとしてGUIによる議論支援を行うシステムがgIBISである.gIBISは議論構造を表すグラフを表示するブラウザ,グラフを構成するノードに関する情報を表示するノードインデックスウィンドウといったコンポーネントから構成されており,ユーザはこれらのコンポーネントを利用して直観的な操作で議論構造の編集を行う.
IBISやgIBISは議論を構造化し,それを可視化することにより,議論の進行の流れを把握しやすくしたという点で意義がある.しかし,議論で発生する発言すべてをこれらのモデルで提案している発言のタイプのいずれかに分類することが難しいという問題点がある.
TimeMachineBoardでは,ボードに提示されているボード要素の位置を変えたり,並べ替えたりすることを議論の構造化と捉え,ボード内容を構造化するために木構造を用いて話し合いの内容を構造化できる仕組みを実現した.ボード内容は参加者全員の合意に基づいてインタラクティブに適切な位置に並べ替えられる.構造を意識しながら話し合うことで,議論内容をより深く理解できるだろう.
8.3.2 Discussion Structure Visualizer
議事録に含まれる言語情報を用いて自動的に議論を構造化・可視化する研究としてDSV(Discussion Structure Visualizer)が挙げられる.DSVでは,従来のテキスト処理による話題構造の抽出に関する研究のような話題の切れ目の同定だけを行うのではなく,話題と話題との関係まで考慮した構造化を目指している.
この研究では,話題の境界を決定するために,類義語の使用(言い換え)や同じ単語の繰り返しといった語彙的結束性を用いている.そして,結束度の低いところから順に話題の境界とみなす.その後,それぞれの話題の特徴ベクトルを求め,特徴ベクトル間の類似度を計算し,その値が閾値以上のものに関してはリンク情報を付与する.分割される話題の数やリンクの数はパラメータによって自由に変更できる.しかし,話題や話題間の関係の抽出をテキスト処理で行っているため,必ずしもその精度は高いものであるとは限らない.これに対し,本研究では,人間がさまざまなデバイスを用いて暗黙的にメタデータを入力するため,その精度はより高いものになる.また,ボードコンテンツの木構造による構造化と,過去のボードコンテンツを進行中のミーティングへ引用することによって,より詳細なボード要素間の関係を抽出することも可能である.
8.4 ボードコンテンツの再利用に関する研究
章では,作成されたボードコンテンツを再利用する手法について述べた.ミーティング内容の記録・検索・閲覧を行うための研究は数多く行われているが,会議コンテンツそのものを知識活動の中で再利用する研究は多くない.
本橋らは,ミーティングシナプスと呼ばれる会議支援システムを提案している.ミーティングシナプスには2つの特徴がある.以下はその引用である.
1点目は,会議中にホワイトボードの書き込み情報をTODOや会議の資料と結びつけることで,TODOから関係する議論内容を参照可能にする点である.
2点目は,日常業務中に作成した文書とその文書の作成中に参考にした文書・Webページの間の参照関係や,同じ話題の議論など会議中の書き込み同士の関係を保存し,後にその関係性を利用して現在の議論に関係する議論経緯や作業経緯を参照可能にする点である.
ホワイトボードの書き込みや日常業務中の文書同士の時間的・空間的・論理的近傍性を利用して関連付けを行い,登録された関係性は情報シナプスと呼ばれる情報関係性管理基盤に保存される.そして,登録された関係性は会議アプリケーションを用いて過去の経緯を検索する際に利用される.
議論と日常業務の情報を関連付けることで,意思決定から業務実行・確認作業までの業務サイクルを支援するという点において,本研究との類似点は多い.しかし,「会議中には,日常業務中の作業結果や過去の会議の議論を確認する場面が発生する」「このように,会議に関係する情報を日常業務や次の会議で再利用する」と述べているように,「過去の議論内容の正確な想起」を「再利用」と定義している点が本研究とは異なる.本研究における「再利用」とは,過去のミーティング内容を参照するだけでなく,その内容を引用しながら新たなコンテンツを作成する部分も含まれる.
ミーティングシナプスのように,会議に付随するコンテンツと会議記録を関連付けることによって,会議内容の参照を効率的に行うための研究としては,GeyerらのTeamSpaceがある.
TeamSpaceは,チームにおける協調作業を支援するためのシステムであり,協調作業において重要な要素(議題やアクション・アイテム)の,会議中における作成・編集時間を用いて,会議風景を記録した動画像のインデキシングを行っている.しかし,本研究ではアクション・アイテムのような結果が生まれるまでに行われる発言そのものを記録する必要があると考えている.たとえば,その場では技術的な問題などによって保留にされたアイディアが,かなり後になってから再び話題に上ることがある.しかし,作成されたアクション・アイテムには,そのアイディアに関する記録はないため,参照することができない.TimeMachineBoardでは,長期間にわたる継続的ミーティングの記録を利用できるようにするために,目的のミーティングを探し出すためのボードコンテンツの検索インタフェース,引用情報を可視化することで,複数のミーティング間の関係を意識しながらボードコンテンツを一覧できる閲覧インタフェースなど実現している.
8.5 コンテンツのメタ情報に関する研究
文書に対するアノテーションを行う研究は数多く行われている.中でもXLibrisでは,電子文書の部分要素に対してペンタブレットを用いて注釈を付与することができ,注釈を含む文書の部分要素をユーザ間で共有する仕組みを実現している.
映像の部分要素を獲得する手法に関係して,Sawhneyらの映像の内部構造を表現するための仕組みであるHypervideoを挙げる.Hypervideoでは,映像を複数の映像シーンに分割するメタ情報を付与し,テキストなどの他のコンテンツと関連付けて扱えるようにすることで,映像を取り扱いやすくするための仕組みである.また,長尾らは,映像シーンに対するメタ情報をWeb上のコミュニティ活動から獲得する,オンラインアノテーションを提案している.オンラインアノテーションの実装である山本らのSynvieでは,映像シーンを引用したブログ記事を書けるようにすることで,映像シーンの定義とそれに対するテキストアノテーションを獲得し,映像シーンの検索に応用している.
これらのマルチメディアコンテンツ間の関係を獲得する手法に関して,HunterらのCo-Annoteaがある.Co-Annoteaはマルチメディアコンテンツの部分要素に対するアノテーションと,部分要素間の関係を付与できるシステムである.付与したアノテーションに基づいて,複数のマルチメディアコンテンツを読み込んでアノテーションを確認しながら閲覧することができる.
本研究では,TimeMachineBoardを用いて話し合った結果を,iStickyを用いて閲覧できるようにした.そして,必要に応じて過去のミーティング内容をTimeMachineBoardに入力し,明示的に話し合えるようにした.iStickyでは過去のミーティング内容だけでなく,様々な種類のコンテンツを取り扱える.参加者がiStickyを用いてボードに提示したコンテンツあるいはコンテンツの一部分を,ミーティングで利用することによって,複数のコンテンツ間の関係を獲得することができる.
9 結論
9.1 本論文のまとめ
本研究では,企業や団体などの組織におけるナレッジワーカーの知識活動のなかでも,少人数で継続的に行われるミーティングに着目し,ボードコンテンツの作成,およびその再利用を統括的にサポートすることで,継続的ミーティングの支援を行う仕組みを提案し,それを具体的に実現した.
章では,知識活動において継続的ミーティングがどのような役割を果たしているのかを述べた.本研究において,知識活動とは「あるテーマに対して継続的にアイディアを創造し,知識として理論化・具体化する活動」であり,ミーティングは個人および組織の知識活動を円滑にする役割を持つ.
そして,継続的ミーティング支援環境について考える前に,1)ミーティング内容の適切に記録が困難,2)過去のミーティング内容が活かされない,3)資料作成に手間がかかる,という3つの問題点を挙げた.
これらの問題点に基づいて,継続的ミーティングを支援するために必要な環境・システムについて述べた.そして,日常的な活動の中で記録されるコンテンツを記録・蓄積し,そのコンテンツを携帯しているタブレット型端末から検索して提示して,並べ替えたりまとめながら話し合うことのできる情報的に拡張されたボードが必要であると述べた.
また,ボードに提示された内容をボードコンテンツとして記録し,話し合いの過程で参加者が行った,ボード内容の並べ替えや移動といった情報をボードコンテンツの構造情報として獲得する仕組みと,過去のミーティング内容に基づいた話し合いを実現するために,過去のボードコンテンツから適切な部分を引用して,進行中のミーティングに提示して話し合える仕組みが必要である.
章では,まず,知識活動において生み出され利用されるコンテンツについて定義した.そして,コンテンツが知識活動の中でどのように作られたのか使われたかという文脈情報が知識活動を円滑にする上で重要な役割を果たしていることを述べた.また,文脈情報に加えて,コンテンツに対する部分要素の定義をメタ情報と呼び,蓄積されたメタ情報を利用することで検索・要約などの高度利用が可能になることを述べた.
メタ情報の応用例として,論文と映像の部分要素に対するメタ情報を利用して効率的な論文読解を実現するインタフェースについて述べた.具体的には,論文と映像の部分要素に対するアノテーションの獲得と蓄積を行うための仕組み,部分要素間の関係情報を取得するための仕組みを,先行研究を拡張することで準備した.そして,獲得したメタ情報を利用するシステムの一例として,論文読解支援システムを提案した.提案システムは,メタ情報を用いてユーザが閲覧中のコンテンツに関連する他のコンテンツの一部を提示し,その理解を促進する仕組みを実現した.さらに,評価実験を行って,提案システムを用いることで効率的にコンテンツの内容を把握できることを確認した.
章では,章までの考察に基づき,Xerox PARCが提唱したボードとタブレット型デバイスが協調的に動作するミーティング支援システムを参考に,現在の情報技術を用いて,継続的ミーティングを支援するシステムを実現し,その構成と機能について述べた.本システムを用いてミーティングを行うことで,日常の活動の中で蓄積されたテキスト,イメージ,スケッチ,過去のミーティング内容の一部をボードに提示して整理しながら話し合うことができる.さらに,ミーティング中に参加者が行った行動から木構造や引用関係を自動で獲得し,ボードコンテンツとしてクラウドに保存する.
章では,章で説明した継続的ミーティング支援システムの構成要素であるTimeMachineBoardを用いて行うボードコンテンツの構造化手法について述べた.
ミーティング内容の構造化とは,話し合いを円滑にするために,ボードに提示された話し合いの内容を表すボード要素をまとめたり移動したりすることを指す.ミーティングを観察すると,ボード要素を自由に配置できる場合であっても,内容が近いボード要素を近くに寄せたり,内容同士の関係によって少しずらして配置したり,並列に並べたりする.
最初に導入したコンテナを用いたグルーピングによるボードコンテンツの構造化は,当初期待した通りには運用できなかった.そこで,木構造によるボードコンテンツの構造化を実現した.木構造による構造化では,ボードに表示されている全てのボード要素間の関係を獲得できる.また,コンテナで付与していた属性を廃止することによって適切な粒度でボードの内容が分割されるようになった.さらに,親子関係を付与する操作だけで構造化できるため習熟が容易であった.
ミーティング参加者が,ミーティングを円滑に進行するためにボードコンテンツの構造化を行うことによって,参加者に特別な負荷をかけることなくボードコンテンツの内部構造を獲得することができる.そして,獲得したボードコンテンツの内部構造を利用することで,単一のミーティングにおいていくつのトピックがあるか,イメージの内容を表すキャプションなどといった情報を獲得することができる.
章では,ミーティング中に過去に行われた議論内容を検索して引用するための仕組みと,獲得した引用・被引用関係を用いて複数ミーティング間の文脈を可視化することで,過去の議論の想起を支援する仕組みについて述べた.
章では,継続的なミーティングによって記録される複数のボードコンテンツから重要な要素を副次的に発見することを目的として,ミーティング中に行われる参加者の自然な行動から,コンテンツの構造やコンテンツ同士の関係の情報を自動的に獲得できる仕組みを実現した.これらの仕組みによって獲得した,ボードコンテンツに関わる多様な情報を用いてロジスティック回帰分析を行い,70%程度の精度をもつ重要要素の発見手法を実現した.また,ロジスティック回帰分析の結果,木構造の付与や引用によって獲得できるグラフ情報が重要要素の発見に有効であることが確認できた.
ミーティングの記録・構造化に関する研究は数多く行われているが,ミーティング間の関係を適切に考慮しているものは少ない.一般に行われている小規模のミーティングは散発的に行われるものではなく,継続的に行われることが多い.過去のミーティング内容をより柔軟に利用することができれば,それまでの経緯を踏まえた議論を促進し,個人の,ひいては組織全体の知識活動を活性化することができるであろう.
9.2 今後の課題
9.2.1 多様な活動への対応
本研究では,ミーティング参加者が作成した様々なコンテンツをボード上に提示して話し合えるようにすることで,ミーティング参加者が資料作成にかける労力を低減するとともに,それらコンテンツ間の関係を獲得している.
ボードに提示されるコンテンツは,ナレッジワーカーの従事するテーマに基づいた知識活動の中で作成されるものである.それらのコンテンツ間には様々な関係が暗黙的に存在していると考えられる.本システムでは,記録されたボードコンテンツの構造情報や,引用関係によってボードコンテンツ間の関係を獲得できる.これらの関係情報を用いることで,ナレッジワーカーの作成したコンテンツ間の関係をコンピュータが取り扱える明示的な関係として抽出できる.このような関係情報を用いることで,コンテンツの推薦や検索,要約などの高度利用を実現することができるだろう.
本研究が目指したのは,ナレッジワーカーが日々の活動の中でコンテンツを作成し,ミーティングのような日常的な活動で利用する.そして,ナレッジワーカーの自然な行為から様々なメタ情報を自動的に獲得する.獲得したメタ情報を用いて,ナレッジワーカーがよりよい知識活動を行うために必要な情報や仕組みを提供する,という循環を実現することである.
本研究ではメタ情報を獲得するための場としてミーティングに着目したが,ナレッジワーカーが行う日常的な活動は,メールのやり取りやチャット,居酒屋での会話や簡単な立ち話,国際会議や研究会など多種多様である.このような活動に対して即座にアプローチすることはできないが,活動をつぶさに観察し,コンテンツの部分要素の定義や部分要素間の関係,文脈情報といったメタ情報を獲得できるような,ナレッジワーカーの自然な行為を発見することが必要であろう.
9.2.2 一般的なWebサービスへの対応
一般的なWebサービスでは,部分要素の定義や部分要素間の関係の付与といったメタ情報を取り扱うための仕組みが提供されていないことが多い.そこで,本研究では,コンテンツの作成とメタ情報を集めるために,TimeMachineBoard(ボードコンテンツ),iSticky(画像,スケッチ,テキスト),Synvie(動画),TDAnnotator(論文)といったシステムを新たに構築したり,著者の所属する研究室の既存研究を利用したりした.
著者の所属する研究室のメンバーは,これらの独自に開発されたシステムを利用することができ,手を加えてよりよいものにすることもできる.
しかし,継続的ミーティング支援システムをより多くの人が利用できるようにするためには,EvernoteやFlickr,SlideShareといったユーザ数の多いサービスに対応していく必要があるだろう.そうすることでユーザの利便性を高め,様々なコンテンツ間の関係を蓄積することができると考えられる.
9.2.3 システムが知識活動に与える影響の定量的評価
本研究では,長期的な運用を念頭に継続的ミーティング支援システムを設計し,具体的にシステムを構築して,実際に運用を行った.そして運用の結果,一定量のボードコンテンツが集まり,ある個人が参加したミーティングのボードコンテンツの内容を把握することが困難になった.そこで,複数のボードコンテンツの中から重要な部分を発見するための手法を考案し,その評価実験を行い,一定の成果が得られたと考えている.
しかしながら,継続的ミーティングを支援するシステムを使った場合,ナレッジワーカーの知識活動にどのような影響があるのか,システムによる副作用にはどのようなものがあるのかといった,システムを使わなかった場合と比較して初めて分かる,本質的な問いに定量的に答えることはできていない.
実際,ミーティングに関する研究は多様に行われているが,未だミーティングシステムを用いることで知識活動にどのような影響が出るのかという指標についての研究はほとんど行われていない.
渡邉らの提案する独自表現率は,会議終了後の結論に対しての合意が,どの程度共通の認識として形成されているかを表す指標であるが,会議の結論をボードに書いてしまえば独自表現率は下がってしまう.そして,独自に表現したからといってその後の知識活動の質について言及できているとは言えない.
また,Branhamらはホワイトボードをカメラでキャプチャして記録しWebブラウザで閲覧できるReboardの運用を通して,ホワイトボードがどのように使われるか,知識活動の中でコンテンツ化されたホワイトボードの内容がどのように利用されるかについて研究を行っている.Reboardは,Liveboardを研究開発したXerox PARCの後継であるFX Palo Alto Laboratoryで開発されたものであるから,ミーティング研究の最先端といえるだろう.それぞれのユースケースについて詳細に言及されていて,参考にはなるが,やはりミーティングが知識活動に与える影響を定量的に表す指標については提案されていない.
このように,ミーティングが知識活動に与える影響を定量的に表す指標の提案は,非常に困難な課題であると考えられる.しかし,著者の所属する研究室においては,本研究をはじめとして,知識活動において生み出されるコンテンツとその文脈情報を記録・蓄積するための仕組みがいくつも実現されている.これらのシステムを利用して,また,新たな仕組みを実現してこれまで記録できなかったコンテンツ・文脈情報を獲得し,その分析を適切に行うことで,解決することができる問題であると考える.
継続的ミーティング支援システムは,運用しはじめてから5年が経過したが,より円滑で実りあるミーティングを実現できるように,今後も研究・開発・運用を継続していく予定である.
謝辞
本論文は,名古屋大学大学院情報科学研究科メディア科学専攻長尾研究室に在籍中の研究成果をまとめたものです.本研究を進めるにあたり,様々な方々より数多くの貴重な御指導・御助言を賜りました.ここに深く感謝の意を表します.
特に,同専攻教授の長尾確先生には,研究内容に関する御助言だけでなく,研究者としての姿勢や研究活動そのものに関する御指導を賜りました.
ここに深謝の意を表します.また,同専攻准教授の松原茂樹先生,同専攻客員教授の中岩浩巳先生,そして長尾研究室助教の大平茂輝先生には,研究内容および本論文の細部にわたり多くの御助言を頂きました.ここに深謝の意を表します.
HIAS学術研究所の長野芳明先生には,幅広い知見に基づいて勉学・研究に対する御指導,御意見をいただきました.また,同研究所の長野純子先生には,多大な御支援をいただきました.
同研究室博士前期課程を卒業されて諸方面で御活躍中の諸先輩方,特に,名古屋大学工学研究科計算理工学専攻河口研究室助教の梶 克彦博士,並びに,名古屋工業大学大学院工学研究科高橋・片山研究室助教の山本大介博士には,在学中に様々な御意見をいただきました.
また,株式会社エングラフィア,土田貴裕博士には,研究に関して行き詰ったときに貴重な御意見をいただきました.また,渡邉 賢さんをはじめとする長尾研究室のメンバーには,ゼミにおける貴重な御意見をはじめ,日々の研究室での活動のなかで大変御世話になりました.
博士前期課程において,長尾研究室の秘書であった金子幸子さんには,大学在籍中から研究活動全般に対する御支援をいただきました.また,現在,同研究室の秘書である鈴木美苗さんには,不自由なく研究活動が行えるように,研究室生活全般に関して御支援をいただきました.
また,株式会社リオの森井義人さんと森井敦子さんには,社会人としての基本的な姿勢から日常生活に至るまで,様々な場面で御指導,御鞭撻を賜りました.
以上の方々をはじめ,本論文を執筆するにあたり,御支援,御協力賜りました全ての方々に,深く御礼申し上げます.
最後に,日々の生活を支えてくださった,両親,家族に心より感謝いたします.