
ビデオスクラップブックによる映像シーンの作成と利用に関する研究
概要
近年、コンピュータの性能向上やインターネットの高速化に伴い、Web上で配信・共有されている映像コンテンツの量は増加し続けている。しかし、映像コンテンツの量が増加する一方で、ユーザがそれらのコンテンツの視聴に充てることのできる時間は従来と変わっていない。そのため、ユーザが限られた時間の中で、多くの映像コンテンツの中の必要なシーンを柔軟に検索し視聴するための仕組みが必要とされている。筆者が所属する研究室では、映像コンテンツのシーン単位での検索・視聴を実現する手法として、映像シーンに対してアノテーションを行う研究が行われてきた。その中で、映像シーンを作成し、他のコンテンツに引用することでアノテーションを収集するシステム(Synvie)が開発・運用されてきた。しかし、アノテーションを付与する対象となるシーンの作成があまり行われず、そのためアノテーションもあまり収集できなかった。シーンの引用によって大量にアノテーションを収集するためには、まずはシーンの作成が積極的に行われるようになる必要がある。本論文では、シーンの作成が積極的に行われるようにするためのシステムとして、ビデオスクラップブックシステムを提案する。ビデオスクラップブックシステムでは、コンテンツ視聴時に作成するマーキング情報をシーン作成時に利用する、などの工夫によって、シーンの作成を容易に行えるようにした。ユーザは図[SceneSelect2]に示すインタフェースを用いて、後で再度視聴するシーンを作成しておくことができる。また、作成されたシーンを整理し、検索できるようにすることで、視聴・引用などのシーンの利用を容易に行えるようにした。また、筆者が所属する研究室で用いられている論文執筆支援ツール(TDEditor)の機能を拡張することによって、マルチメディア論文に映像シーンを引用することを可能にした。TDEditorで論文にシーンを引用する際には、図[TDEditorScene]のように、まずはシーンの元のコンテンツを検索し、次に引用するシーンを選択し、最後に選択したシーンのイメージを論文中に挿入する。論文に引用された映像シーンは印刷時には画像として扱われるが、Web上でマルチメディア論文として閲覧する際には、映像として視聴することができる。さらに、シーン作成とシーン引用に関して学生11名による被験者実験を行い、アンケート調査による主観評価を行った。評価実験の結果から、ビデオスクラップブックシステムによってSynvieのシーン作成インタフェースと比べてシーンの作成が容易になったことと、引用するシーンを事前に作成しておけることの有効性が確認された。
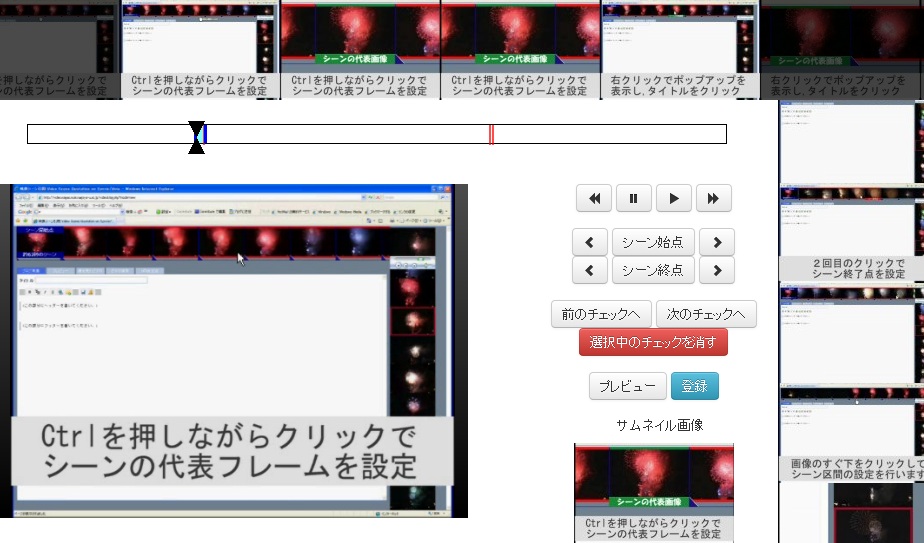
図1: ビデオスクラップブックのシーン作成インタフェース
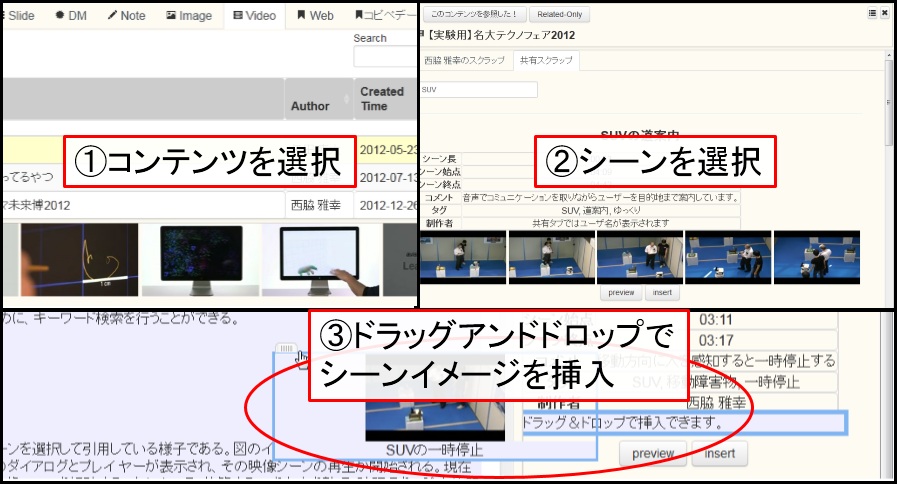
図2: TDEditorでのシーン引用
1 はじめに
近年、コンピュータの性能向上やインターネットの高速化にともない、映像・音楽などのマルチメディアコンテンツがWeb上で頻繁に配信・共有されている。これらのコンテンツには、従来のテレビ番組や映画のような、専門家が作成したコンテンツだけでなく、一般ユーザによって撮影・作成されたコンテンツも多く含まれている。YouTubeやニコニコ動画といった、映像共有サービスの普及や、ブログやSNSなどの発達により、個人やWebコミュニティからの情報発信はますます増加し、影響力を増していくことが考えられる。これらの映像コンテンツは、必ずしも品質の高いものではないが、時として専門家が作成したコンテンツに劣らぬ高い評価を受けることもある。しかし、映像コンテンツの氾濫の一方で、ユーザがそれらのコンテンツの視聴に充てることのできる時間は従来と変わっていない。そのため、ユーザが限られた時間の中で、必要な映像コンテンツの中の必要なシーンを閲覧するための仕組みが必要とされている。
映像コンテンツに対して、関連する情報(メタデータ)を注釈として付与することを、ビデオアノテーションという。著作者や作成日時のような、コンテンツ全体に関する情報に関しては、画像やテキストといった他のコンテンツに対するアノテーションと同様であるが、映像コンテンツは、画像やテキストなどとは異なり、時間によっても進行するため、特定の部分に対してアノテーションを行う場合、座標空間の範囲だけでなく、時間区間もまた指定する必要がある。そのため、一般に映像に対する詳細なアノテーションは、他のコンテンツに比べてハードルが高いとされる。
Web上に氾濫する大量の映像コンテンツの中から必要なシーンだけを探し出すためには、映像シーンに対するアノテーションの仕組みが不可欠である。また、アノテーションは検索のために必要とされるだけでなく、シーンを閲覧している人に対して、そのシーンに関する情報を提示するためにも必要となる。例えば、自分の好きな俳優の登場するコンテンツのシーンを閲覧したい、今映っている野球選手の高校時代の活躍を見たい、今放送されている音楽のアーティストに関する情報を知りたい、といった要求を実現するには、自動解析では困難であるが、アノテーションを人間が作成することでより容易になる。
映像コンテンツにアノテーションを付与するための方法として、動画像処理、音声処理などの機械処理によって映像に対するアノテーションを自動生成する研究が以前から行われている。このような手法は、人手をかけずにアノテーションを作成することができるという利点はあるが、得られる情報は、音声やテロップの情報、カットやオプティカルフローの情報などであり、映像に含まれる意味的な情報をすべて抽出することはできない。また、一般的なビデオカメラを用いて制作された映像コンテンツは、ノイズとなる画像や音声も多く含むため、機械処理の精度が上がらず、そこから作成されるアノテーションの質が低くなるという問題がある。実際に、機械処理のみのアノテーションによって十分な精度で検索などの応用を実現した例はなく、限界があると考えられる。
別の手法として、機械処理による自動解析によって得られたシーン区間や、人手によって決定されたシーン区間に対して、アノテータと呼ばれる専門家が詳細なアノテーションを作成する研究が行われるようになった[1]。この方法で得られるアノテーションは、質が高く、非常に有用なものであるが、アノテーションを作成するための人的コストが非常に大きい。一般ユーザにとっては、アノテーションにかかるコストがそれによって得られる利益に見合ったものであることが少ないため、アノテーションを作成する必要性が相対的に低い場合が多い。また、詳細なアノテーションを作成するにはアノテータが映像の内容に関して深い知識を持っている必要があり、その点においても、この手法は一般ユーザによって投稿された映像に対するアノテーションとしては不適切であると言える。
現在、ブログやSNS、電子掲示板などのコミュニケーションサービスが多く存在し、サービス利用者も増加傾向にある。これらのサービスを利用する一般人が発信する情報には、非常に意味のある情報が含まれ、時には社会に対して大きな影響を与えることもある。最近では、国内最大の電子掲示板である2ちゃんねるだけでなく、「ツイート」(tweet)と称される短文を投稿できるTwitterや、世界中のユーザとコミュニケーションが可能なインターネットコミュニティFacebookといったサービスも普及してきている。エジプトで起きた大規模デモの原動力として挙げられるほどに、それらのサービスから発信された情報が社会に大きな影響をもたらしていることからも、一般ユーザの発信する情報にもある程度の価値があることがわかる。
このようなコミュニケーション活動から、検索に有効なアノテーションを得るための研究が、筆者が所属する研究室で進められた。その結果、開発されたのがオンラインビデオアノテーションシステムSynvie[2]である。また、Synvieで収集されたアノテーションに基づいて映像シーン検索を行うシステムDivie[3]も開発された。Divieでは映像シーンを検索できるだけでなく、シーンを含む映像コンテンツ全体の俯瞰支援も可能である。
また、学術的な内容の映像シーンと、論文の関連する部分との間に引用関係を付けることで、シーン検索の精度を上げるためのシステムも開発された[4]。このシステムでは、文章と内容の質が高い論文テキストを用いることで、シーン検索において有用である特徴語を獲得するだけでなく、論文テキストによる映像シーンの俯瞰支援も行い、シーンやその周辺の映像内容を効率よく理解できるようになっている。また、論文テキスト中に存在する語の共起頻度からタグ同士の関連度を求めることで、関連タグを提示して検索を容易にする仕組みも作成された。
ここまでは、ユーザが未知の映像シーンを発見するためのアノテーションを集めるために行われてきたことを述べた。しかし、一般ユーザが映像コンテンツ全体ではなく、自分の必要としている部分だけにアクセスしたいと感じるのは、すでに視聴した経験があるシーンを再発見する場合にもある。一度見た映像コンテンツの特定の部分だけを何度も見直したい、という場合にも、映像の部分区間をシーンとして扱うことが必要となってくる。例えば、映画やドラマの中で、感動したシーンや演出のすばらしかったシーン、演劇の発表を録画した映像のうち、家族や友人が演じている人物が登場しているシーン、あるいは、スポーツにおける得点シーンなどが、何度も繰り返して見たいという要求が多い、代表的なシーンだと予想される。テレビ番組におけるスポーツの試合のハイライト映像において、結果を左右した得点シーンやプレイが、同じ番組中に何度も繰り返して放送されることや、ドラマや映画から短い1シーンのみを切り出した動画が、動画共有サイトに投稿され、何人ものユーザによって何度も繰り返し再生されていることなどからも、映像の中の必要な一部分のみを再生したいという要求が存在すると考えられる。
現在、大手動画共有サイトであるYouTubeにおいては、URLにタイムコードを記述することで、再生開始の位置を指定することが可能である。このサービスを活用し、映像コンテンツのURLと目的のシーンの始まるタイムコードを保持しておくことで、目的のシーンに直接アクセスすることができる。しかし、そのタイムコードにメタデータを付与して保管しておくことができないため、ユーザはそのタイムコードがどの映像コンテンツのどのような内容を表しているのかを、システムの外部で記憶、あるいは記録しておかなくてはならない。また、指定できるのは開始位置のみであるため、必要なシーンの視聴が終わり、視聴を完了する場合には、ユーザ自らが判断し、操作しなくてはならない。一方、ニコニコ動画においては、ループ動画と呼ばれる動画が多数投稿されており、映像コンテンツ中の一定の区間のみを繰り返し再生し続ける機能が存在している。しかし、その機能を設定できるのは投稿者だけであるため、視聴者側はシーン区間を指定することができず、ループ設定された動画では、繰り返しを行わずに映像を最後まで見ることもできない。また、その区間が繰り返し再生される区間である、という以上の情報は保持していないため、その区間の情報を検索に応用することも不可能である。
ユーザが個人的に所有する映像コンテンツであれば、映像編集ツールなどを使用することによって必要な部分以外を削除したり、必要な部分のみを選択して、別の映像コンテンツとして保存したりすることは可能である。しかし、別のコンテンツとして映像シーンを保存してしまえば、作成されたシーンは、元となったコンテンツの一部分である、という情報を保つことが難しくなり、そのシーンの前後の映像を見ようと思っても、それらのシーンを機械的に探し出すことができなくなる。それに対して、映像コンテンツそのものには手を加えずに、シーン区間の情報をアノテーションとして保存する手法であれば、Web上の映像コンテンツからもシーンを作成することができるだけでなく、コンテンツ全体の視聴と切り替えることもでき、元のコンテンツと選択されたシーンとの間の関係も保持できる。
映像コンテンツの一部だけを何度も繰り返し視聴したいという要求は、ユーザが映像コンテンツに対してシーン区間というアノテーションを付与するモチベーションになり得ると筆者は考えている。しかし、たとえユーザにシーン区間のアノテーションを行うモチベーションがあったとしても、コンテンツの視聴中には、コンテンツの視聴に集中したい場合が多いことが予想される。その一方で、視聴中にシーンとして残しておきたいと感じたタイミングを何らかの形で残しておかなければ、シーン区間を指定するためにコンテンツの最初から見直して目的の部分を探し出さなくてはならない。場合によっては、コンテンツそのものを検索する必要すらあるかもしれない。このコストが、シーン区間のアノテーションに対するモチベーションをなくす要因の1つになっていると考えられる。
そこで、本研究では、映像シーンの作成にかかるコストを小さくするシステムを提案する。提案システムで可能になることは、映像コンテンツの気に入った部分に目印を付けておくこと、作成した映像シーンとそれを含むコンテンツとの関係を保持すること、作成したシーンを別ユーザと共有できることである。また、作成したシーンを応用する方法として、作成したシーンを他のWebコンテンツに引用することができる。
映像コンテンツ視聴中に、気に入ったタイミングで目印を付けておくことによって、次回以降にそのコンテンツを視聴する際には、Web全体の大量のコンテンツの中から検索することなく、自分が目印をつけたコンテンツの中から簡単に探し出してアクセスすることができる。また、視聴時に付けた目印を参考にすることで、後にシーン区間を決定する際に、映像全体から目当てのシーンを探し出すコストを大きく減らすことができる。一般的な動画共有サイトにおいても、視聴中のコンテンツを自分の再生リストに登録する仕組みはすでに存在し、頻繁に用いられている。そのため、この目印をつけるための操作に対してユーザが感じるコストは、比較的小さいと考えられる。
シーンを作成する際には、コンテンツ視聴時に付けた目印を参考にして、シーン区間を決定する。シーンの始点と終点は、目印の周辺のサムネイルを参考にしておおまかな位置からコンテンツを再生しながら、任意のタイミングを指定できる。また、作成したシーンを保存する際には、映像コンテンツを投稿する時のように、タイトルやコメント、タグを入力して、整理しておくことができる。これらの入力は、手間のかからないものではないが、ソーシャルブックマークシステムが一般ユーザに広く浸透していることからも分かるように、ユーザ自身がコンテンツを整理するために付与する必要最低限のアノテーションに必要なコストは、惜しまれないと考えられる。こうして集まったアノテーションを活用すれば、作成されたシーンに対するメタデータを用いて、映像コンテンツにシーン検索用のメタデータを作成することも可能になると思われる。
シーン作成者によって共有状態に設定されたシーンは、別ユーザから簡単にアクセスできるようになっており、そのシーン区間が自分の作成しようとしているシーンと同一である場合には、新規にシーンを作成する必要がない。また、別ユーザが定めたシーン区間を参考にして、自分にとって必要なシーン区間を新たに設定することもできる。もちろん、共有状態にするかどうかはユーザの自由であり、自分専用のシーンを作成することもできる。映像シーンの共有によって、コミュニケーションの一環としてシーン作成が行われるようになれば、シーン作成に対する関心が高まると考えられる。また、シーンを共有する際には、自分だけが分かるようなものではなく、共有した他者がシーンを見つけやすいような、分かりやすいタイトルやタグが付けられる可能性が高くなると考えられる。
また、他のWebコンテンツに映像シーンを引用する際にも、このシステムで作成しておいたシーンをそのまま活用することができる。従来も映像シーン引用の仕組みは存在したが、今回提案するシステムでは、シーンをあらかじめ作成・整理しておくことができるため、実際にシーンを引用するタイミングで、コンテンツ及び引用したいシーンを探す必要がなく、コンテンツの作成に集中することができる。また、共有状態にある別ユーザのシーンも引用することができるので、場合によっては自分でシーンを作成しなくてもよい。シーンを引用する際にも、元のコンテンツの情報やシーン作成時に付与した情報を活用することにより、比較的簡単に目的のシーンを探し出すことができる。
最後に、本論文の構成について述べる。
2章において、筆者が所属する研究室でこれまで行われてきた、映像シーンに関する研究について述べる。3章において、映像シーンの管理・共有システムであるビデオスクラップブックシステムとシーン作成UIの評価実験について述べる。4章では、映像シーンの応用の1つであるシーン引用と、シーン引用を通して、さらにどのようなことが可能になるか展望を述べる。また、従来のシーン引用との比較実験とその結果について述べる。5章で関連研究について述べた後、6章で本研究のまとめと今後の課題について述べる。
2 映像シーンに対する従来の取り組み
本章では、筆者が所属する研究室でこれまで行われてきた映像シーンに関する研究と、本研究で改善すべき点について述べる。詳細は次以降の節で解説するとして、まずは各研究の概要を述べる。
まずは、半自動アノテーションシステムとビデオアノテーションエディタに関して述べる。半自動アノテーションとは、機械処理によって得られる情報と人手による意味情報の入力を組み合わせたアノテーション手法であり、アノテーションの作成にコストがかかるものの、良質なアノテーションを得ることができる。半自動アノテーションのためのツールであるビデオアノテーションエディタでは、アノテーションとしてテキストの他に意味属性を付与することで、柔軟なシーン検索が実現された。
次に、オンライン映像アノテーションシステムSynvieと、Synvieによって獲得されたアノテーションを基に映像シーン検索を行うシステムDivieに関して述べる。オンライン映像アノテーションとは、映像アノテーションに必要な情報をネットワークを通じてリアルタイムに収集し応用に反映させる手段である。人手によってアノテーションが作成されているものの、アノテーションを行うユーザがコストを感じにくいという特徴がある。SynvieではWebコミュニティの活動に注目したアノテーションの獲得が行われた。また、獲得されたアノテーションから生成されたタグの選別と、タグを用いた検索システムDivieが開発された。
次に、映像コンテンツの部分である映像シーンと論文の一部(段落や文など)とを関連付けることで映像シーンにアノテーションを付与する仕組みに関して述べる。アノテーションを作成するのではなく、論文という1つのコンテンツからアノテーションを得るという点で、先の2つの仕組みとは大きく異なっており、また論文の理解を促進するという側面も持っている点で、作成された映像シーンの応用として大きな可能性を持っている。
最後に、これらの手法における、映像シーンの扱いに関する問題点を挙げて、本研究の目的につなげる。
2.1 映像シーンに対する半自動アノテーションシステム
映像コンテンツに対して、効率よくアノテーションを作成するためのツールとして、ビデオアノテーションエディタ[1]が開発された。このツールでは、映像コンテンツを自動解析した後、アノテーションを行う人間が解析結果を修正・補完して意味的な記述を行うことで、映像シーン検索の精度を実用的なレベルに引き上げることができる。
ビデオアノテーションエディタでは、まずは自動的にカットおよびショットの検出が行われる。ここでいうカットとは、映像に大きな変化があった時刻(転換点)のことで、カットから次のカットまでの区間をショットと呼ぶ。このカットの検出では、映像を1フレームごとに色情報をヒストグラム化した後、このヒストグラムを直前のフレームのヒストグラムと比較し、差が閾値を越えた場合に新たなカットとして認識される。こうして自動的に抽出されたショットは人手で簡単に分割・併合できるようにされている。
自動的にカットを検出するだけでなく、映像中に登場する人や動物、テロップなどのテキストといったオブジェクトの出現する時間と消滅する時間を自動的に取得して、オブジェクトに対するアノテーションを付与することができる。この情報は編集や検索の際に非常に有用になる。
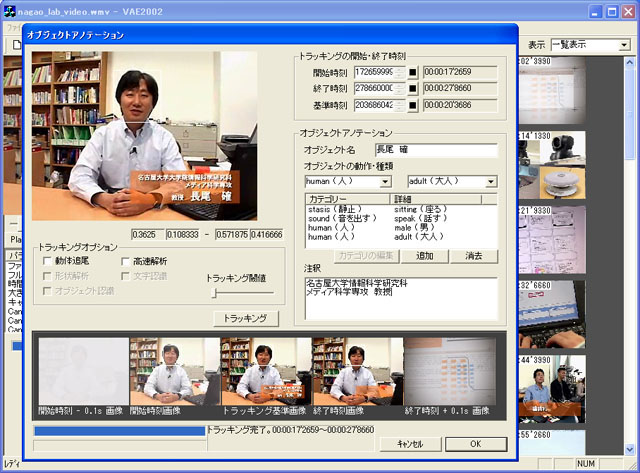
図2.1: VideoAnnotationEditorのインタフェース
このシステム上でアノテーションを行う際には、先に解析によって得られたショットやオブジェクトを選択する。選択された対象に付与する意味属性アノテーションのカテゴリを選択した後、カテゴリの中から意味属性を選択する。図[vae]はこのインタフェースを用いてオブジェクト(人物)に対してアノテーションを行っているところである。この意味属性は複数選択することが可能で、その組み合わせによってアノテーションの対象に関する正確な記述を行うことができる。アノテーションを自然言語だけではなく、意味情報の選択という方式で行うことで、意味内容を一意にとらえやすくなっている。また、解析されたデータとともに、そのデータの意味する内容を記述することによって、アノテーションデータ単独で意味内容が理解できるようになっており、それによって特定のアプリケーションに依存しにくく、永続性・独立性の高いアノテーションデータが得られるように工夫されている。
さらに、ビデオアノテーションエディタによって得られたアノテーションに基づいた、自然言語を用いた検索システムも開発された。この検索においては、自然言語による検索要求文を解析してキーワードに分解した後、得られたキーワードとアノテーションデータとの直接的なマッチングだけでなく、キーワードの中で色や明暗を表すものを用いて、アノテーションデータに含まれるカラーヒストグラムとのマッチングも行っている。それによって、「暗い」というキーワードに対して、人手によるアノテーションが行われた部分のみでなく、自動解析による明暗の情報も検索結果に反映できる。また、検索要求文の後方の単語の方が文章の根の方に近く、重要であるという予想から、検索要求文の前の方に現れたキーワードの重みづけを小さく、後ろの方に現れたキーワードの重み付けが大きくされた。こうして、自然言語の検索要求文が検索結果のソーティングに活用されている。
2.2 SynvieによるWebコミュニティ活動に基づく映像アノテーションの獲得
人手と機械処理を組み合わせたアノテーションの方式は、応用システムを開発する上で極めて有効である。しかし、専門家が映像コンテンツに対してアノテーションを作成するのには多大な人的コストがかかり、機械的に映像コンテンツの意味を解析することができない限り、大幅なコスト低減は見込めない。そのため、商用コンテンツのような、アノテーションのコストに見合った効果が見込まれる映像コンテンツでなければ現実的には適用できないという欠点がある。
そこで、ブログやSNSといったWebコミュニティ活動に目をつけ、映像コンテンツとそれらを効果的に結びつけることで、コミュニティにおける自然な活動から映像コンテンツに対するアノテーションを獲得するためのシステムSynvie[2]が開発された。このシステムでは、Webコミュニティにおいて行われている2種類の活動に対応する仕組みが提供された。1つ目は、映像コンテンツの任意のシーンに対して、コンテンツの内容に対する感想や評価などの情報の関連付けを支援する掲示板型コミュニケーションの仕組みであり、2つ目は、任意の映像シーンを引用したブログエントリの生成を支援するブログ型コミュニケーションの仕組みである。これらの仕組みを作成することによって,ユーザ同士の映像を題材としたコミュニケーションを支援する。
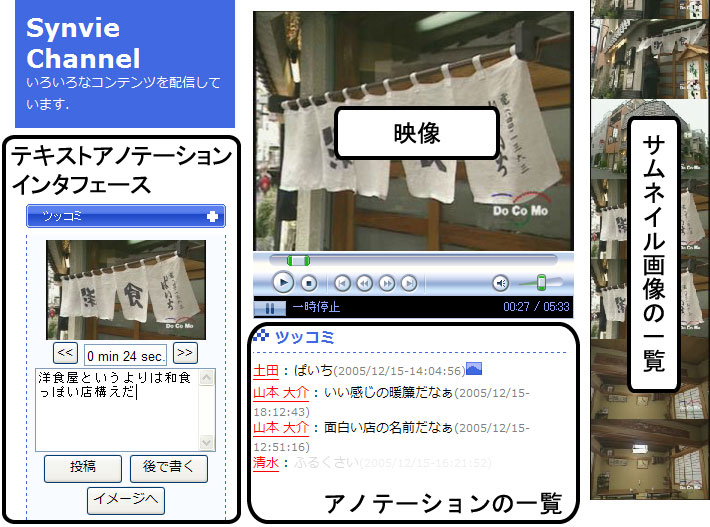
図2.2: シーンコメントインタフェース
まず、掲示板型コミュニケーションの仕組みに関して解説する。これは映像コンテンツにおける現在再生中のショットに対して、映像コンテンツの閲覧を中断することなく簡単にコメントを投稿することができる仕組みである。また、図[Synvie0]のように、現在の映像に同期したコメントが表示される。これにより、ユーザは映像コンテンツに対して、電子掲示板感覚で他のユーザとコミュニケーションを図ったり、関連情報を提示したりすることが可能になる。こうして投稿されたコメントには、アノテーションとしてそのまま活用できる質の高いテキストであることはそれほど期待されていない。コメントを投稿したことをきっかけとして、後で述べるシーン引用に基づくブログ執筆を促すことが掲示板型コミュニケーションの目的である。
また、映像コンテンツ中のあるショットだけでなく、閲覧中のコンテンツの静止画像に関して、任意の領域を矩形選択して、それに関するアノテーションを投稿できるシステムも作られた。このシステムでは、前述の簡易なコメント投稿システムとは異なり、映像の閲覧を一時的に停止する必要がある代わりに、より詳細で対象が明確なアノテーションを付与可能であり、映像上の登場人物やオブジェクトの名称の記述、テロップの書き下しや見落としがちな部分についての注釈などの、コメントと比較すると説明的なアノテーションが作成されることが想定されている。
次に、映像シーンを引用したブログエントリの作成を支援するシステムに関して解説する。ブログでは、エントリごとに、PermalinkやTrackbackなどの仕組みによって、異なるサイトにまたがるエントリ間のリンクや引用を可能にしている。また、エントリに対してコメント投稿機能を用意することによって、読者からのフィードバックを取得可能である。この仕組みを映像コンテンツのシーンに対して適用することによって、映像シーン単位でのアノテーションや引用を実現するためのシステムが開発された。
このシステムにおいては、引用するシーンの時間区間はユーザによって決定される。引用シーンを決定するインタフェースとして、1つの映像コンテンツ内の、コメントを付けた周辺のシーンのみを引用するシンプルなインタフェースが開発された。また、このインタフェースの問題点を改善し、さらに複数の映像コンテンツから複数のシーンを個別に引用、あるいは共引用するためのインタフェースが開発された。
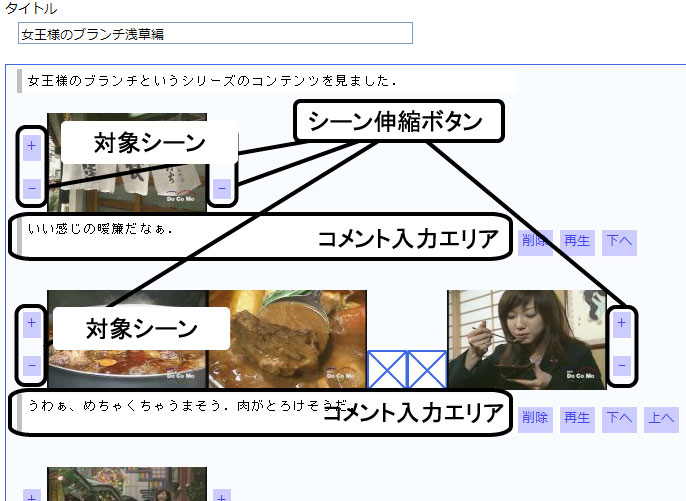
図2.3: 1つの映像コンテンツからのシーンの引用インタフェース
前者のインタフェースでは、引用シーンをショット単位で時間的に展開させることで、引用シーンの時間範囲の修正・変更が可能であり、より正確にシーンを選択することができる。具体的には、シーン伸縮ボタンを押して引用シーンを時間的に前後に伸縮させることによって、正確に引用シーンを選択する。また、このシーンに対応するコメントを編集することも可能である。これは,シーンの流れやストーリを対象としたビデオブログエントリを記述するのに適したインタフェースであると同時に、より詳細なアノテーションを施すためのツールとしての側面も持っている。
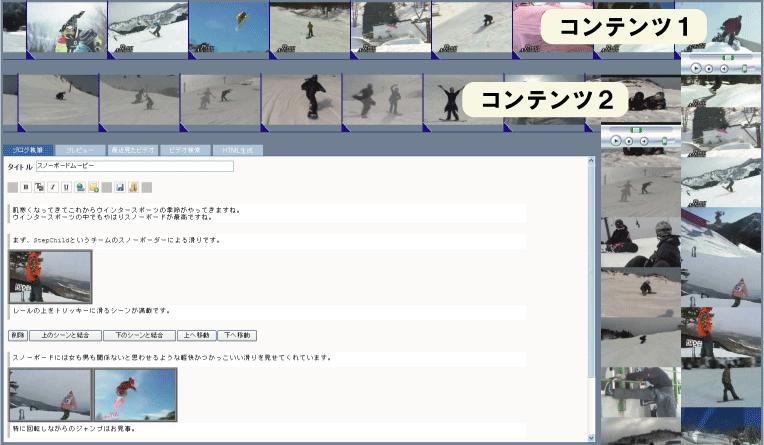
図2.4: 複数コンテンツからのシーン引用インタフェース
後者のインタフェースでは、図[synvie2]のように、ブログへと引用したい複数の映像コンテンツに対応するサムネイルシークバーが、層上に表示されている。サムネイルシークバーは、右上に表示される小さなビデオウィンドウと、水平方向及び垂直方向に伸びる、現在のメディア時間を基準とした連続ショットに対応するサムネイル画像から構成されている。水平シークバーでは、映像のシークとブログへと引用するシーン区間の指定が可能であり、垂直シークバーでは、おおまかにビデオをシークすることが可能である。水平シークバーを用いてシーン区間を指定する際には、1回目のクリックでシーンの開始フレームを、2回目のクリックで終了フレームを、3回目以降のクリックで微調整を行う。サムネイルシークバーを採用することで、ストリーミングビデオのシーク時のタイムラグによるシーンの見落としの回避が図られている。また、複数の映像コンテンツからシーンを引用できるので、複数コンテンツにまたがるアノテーションが作成できる。
実際には、ユーザは後者のインタフェースを用いてビデオブログエントリを作成する。作成されたビデオブログエントリは、HTML文章として表現されると同時に、アノテーションデータベースに登録される。登録されたアノテーションは、ユーザによって入力されたそのままの形になっており、機械的に処理できる形式であることが保証されていない。そこで、3つの観点による、アノテーションの解析が行われた。アノテーションテキストからのタグの抽出、アノテーションや映像シーンの各々の重要性の計算、各々のアノテーション間やシーン間の関連性についての考察である。
1つ目のアノテーションテキストからのタグの抽出では、コンテンツ全体に対するアノテーションから得られたタグをコンテンツタグ、シーンに対するアノテーションから得られたタグをシーンタグと、タグを2種類に分類した。また、アノテーションテキストを形態素解析によって形態素に分解し、それぞれの形態素から名詞・動詞・形容詞・形容動詞・未知語を抽出した。ただし、未知語は固有名詞として扱い、さらに一般的に不要語と判断可能な形態素(例えば、する、 ある、など)や代名詞、非自立な品詞も除外された。こうして得られたそれぞれの形態素の基本形がタグとして扱われた。
2つ目のアノテーションやシーンの重要性に関しては、アノテーションの重みはそのアノテーションがシーンの内容をどれだけ的確に表現できているかの指標によって、シーンの重みは頻繁に参照されるシーンほど重要であるという指標によって計算された。具体的には、まずアノテーション対象の粒度(すなわちシーンの長さ)、アノテータ(ブログ作成者)の信頼度、アノテーションの取得方法による信頼度からアノテーションの重みが計算された。こうして計算されたアノテーションの重みを基にして、より重みの大きいアノテーションが多く付与されているシーンほどシーンとしての重要度が高いものとした。
3つ目のアノテーション間およびシーン間の関連性については、1つのビデオブログエントリで複数のコンテンツが同時に引用された場合、そのビデオブログエントリの内容に基づいて、これらのコンテンツの意味的な関連性を分析することが可能になる。
2.2.1 タグの選別とDivieによる映像シーン検索システム
Synvieによって得られたアノテーションテキストには、映像コンテンツの内容とは関係のないものが含まれていることが容易に想像された。そのため、シーンタグを選別して、そのシーンに対して適切なタグのみを残すためのシステムが開発された[3]。また、選別システムによって適切と判断されたタグを基にした、シーン検索のインタフェースが開発された。
はじめは、タグの選別を機械処理によって行うよう試みられた。まずは、TF-IDF(Term Frequency-Inverse Document Frequency) によるシーンタグの重み付けが試みられた。しかし、この手法は大量のドキュメント数を必要とするため、有効な選別を行うことはできなかった。次に、Google Web API(http://code.google.com/)を利用し、コンテンツに付与されたタグと、シーンタグの共起関係から重み付けを行った。しかし、コンテンツに付与されているタグには、コンテンツ内部のシーンに関係するものが詳細に含まれているわけではなく、シーンに関係するキーワードよりも、一般的なキーワードとの共起関係が強くなってしまったため、この手法によっても有効な選別は行えなかった。これらの結果を踏まえて、機械処理による自動的なタグ選別によって有用な選別結果を得るのは困難であるという結論に至った。
そこで、コストを可能な限り抑えながらも、人手によってタグの選別を行うためのシステムが開発された。そのシステムでは、オンラインで不特定多数の人間の手でタグの選別を行うことによって、1人当たりにかかるコストを抑えながらも適切なタグ選別を可能にしている。
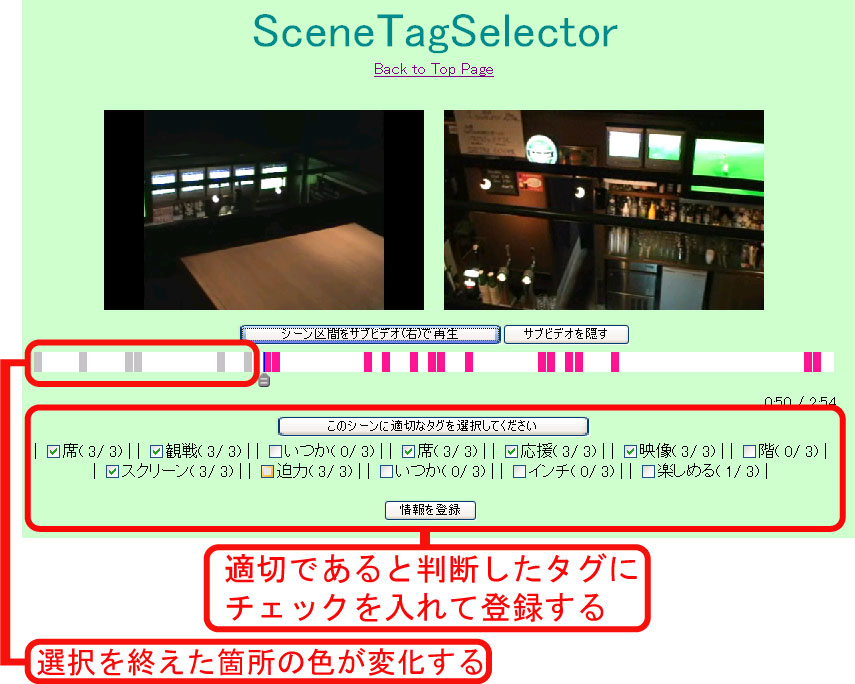
図2.5: シーンタグの選別
開発されたタグ選別システムの概要に関して解説する。このシステムでは、映像コンテンツの再生中に、タグが付与されたタイムコードに至ると、自動的に再生が停止されて該当するタグが適切かどうかを選択するように表示される。このシステムのインタフェースでは、あらかじめ2つのビデオウィンドウが用意されており、タグの選別を行う間には、片方のウィンドウの再生は停止した状態のままだが、もう片方のウィンドウで、タグが付与されているシーン区間やその周辺の映像を閲覧することができる。図[divie1]は、実際にこのインタフェースでタグを選別している様子である。シーンに関連付いたタグはシーンの開始時間に対する情報ではなく、そこから始まる、もしくはその周辺のシーンに対する情報である。そのため、タグが適切であるかどうかを選択する際にはシーンのみではなくその周辺の情報も閲覧できる必要があるため、ウィンドウを2つ設置する設計がなされた。また、オンラインで不特定多数のユーザによってタグ選別が行われることが前提とされているため、タグの選別時には、それまでに行われた選別の履歴が表示されるようになっている。新たにタグ選別を行うユーザは、その履歴を参考にしてタグ選別を行うことができる。
実際にこのシステムによってタグを選別した結果、Synvieによって得られたシーンタグのうち約3分の1が適切なタグであると判定された。これによって、Webコミュニティにおける自然な活動によって得られたアノテーションには、有用な情報が含まれていると実証された。また、このシステムを用いたタグの評価にかかった時間を、比較実験用に作成されたシーンタグ作成ツールを用いてタグを作成するのにかかった時間と比較したところ、シーンタグを新規に作成するよりも、Synvieによって得られたシーンタグを選別する方がコストが小さくなることが実証された。
次に、適切と判断されたシーンタグによるシーン検索システムについて述べる。オンラインビデオアノテーションを基に作成されるシーンタグには、タグが関連付けられるシーンがユーザの興味のあるシーンに偏るという問題点がある。また、人気のあるコンテンツにはシーンタグが多く付けられるが、そうでないコンテンツにはあまり付かないことも問題になる。この問題から、アノテーションの量にも依存するが、コンテンツ全体を網羅するほどの量のシーンタグを作成することは非常に困難であると考えられる。また、タグの本質的な特徴として、タグの付与されていない箇所は、検索にヒットしないという問題がある。そこで、検索結果として、シーンをランキング表示するのではなく、シーンの元になったコンテンツをランキング表示し、そのコンテンツ中のシーンに関する情報を提示することで、コンテンツから目的のシーンを発見できるシステムが開発された。
このシステムを用いて検索を行う際には、検索キーワードを入力することもできるが、品詞によってカテゴリ分けされたシーンタグの中から目的のタグを選択することもできる。このタグはキーワードを1文字入力するごとに検索結果が絞り込まれるインクリメンタル検索の仕組みにより、容易に選択することが可能となっており、かつシーンが1つもヒットしないタグを検索することがないようになっている。
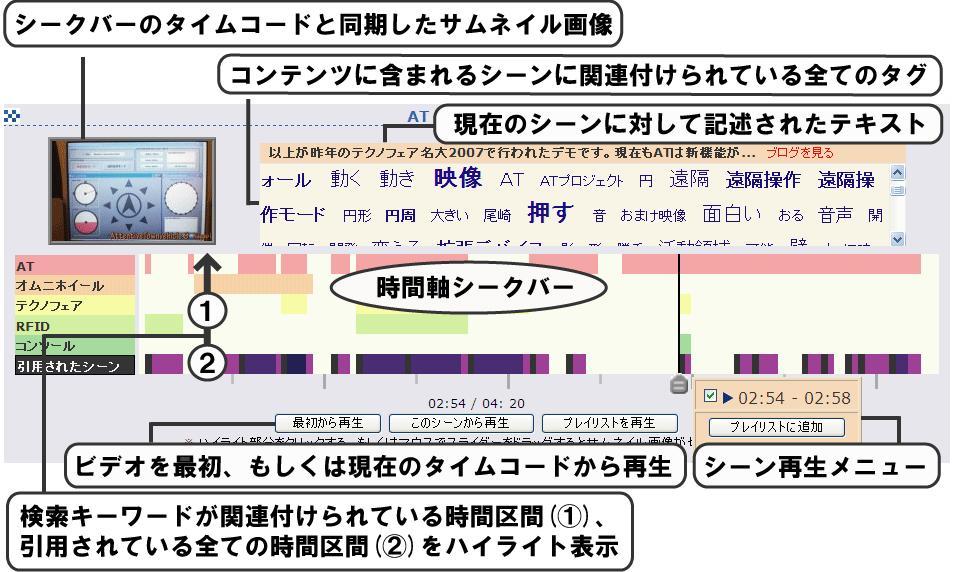
図2.6: Divieのシーン検索結果
検索にヒットしたコンテンツは、図[divie2]のように、コンテンツ中の各シーンの情報、タグが付与されている時間区間、タグが付与されていない時間区間の情報、付与されているシーンタグの一覧などが表示される。この多くの情報をWebブラウザ上で効率よく表示するインタフェースが開発された。検索結果画面には、シーンのサムネイルや、コンテンツから作成されたシーンに関連付けられたシーンタグの一覧が表示される。また、タイムラインが表示され、検索クエリに用いられたタグと、シーンタグ一覧からクリックされたタグが関連付けられた区間がタイムライン上でハイライト表示される。さらに、タグとは別に、シーンを引用したブログのテキストも表示できるようになっている。
2.3 映像シーンと論文部分の引用関係によるアノテーションの獲得
Webコミュニティの活動に基づくアノテーションの獲得は、ユーザの自然な、あるいは自発的に行われる行為による結果をアノテーションとして活用するものであるため、アノテーションとしてユーザが感じるコストは極めて低い。しかし、ユーザが映像コンテンツへのアノテーションを行っているという認識を持たずに記述した内容をアノテーションとして利用するため、検索用のアノテーションとしての質はあまり高くない。シーンの内容に間接的にも関係しない内容が記述されるケースが生じることは避けられない。また、アノテーションとして獲得されたテキストが文法的に正しいとは限らないため、文章としての解析がうまくいかない場合もあった。
そこで、テキストを不特定多数のWebコミュニティユーザから集めるのではなく、テキストの質が比較的高いと思われる論文に目を付け、論文の部分と映像の部分であるシーンとを関連付けることで、シーンに対するアノテーションを作成することが試みられた[4]。論文はその研究分野に関して専門的な知識を持った研究者によって執筆されたものである。よって、このアノテーション手法で映像に関連付けられたテキストには、一般ユーザのコメントなどのテキストからは得られない、専門用語などの特徴語が多く含まれることが期待された。このような特徴語は、学術的な内容を含む映像シーンを検索する際に、非常に有用なタグになると考えられる。また、論文中のテキストは、査読などが行われている、ある程度洗練された文章であるので、文法的に的確であると考えられる。そのような文章からは、容易に語と語の関連性を統計的に獲得できると考えられた。そこで、この考えに基づき、アノテーションとして収集されたテキストの文章に現れる語の共起頻度からタグの関連性を計算し、それを利用した映像シーン検索を実現した。
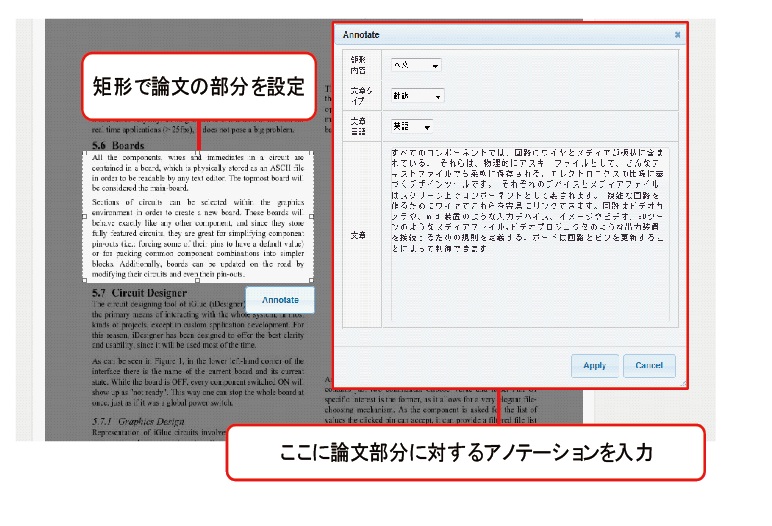
図2.7: TDAnnotator
まずは、論文部分と映像シーンとの関連付けに関して述べる。論文の部分の選択は、筆者が所属する研究室で開発されたTDAnnotatorを用いて行われる。TDAnnotatorは、論文の任意の部分を矩形選択して、その部分に対してアノテーションを付与することができるシステムである(図[tda])。映像部分であるシーンの区間指定は、前述のSynvieのものとほぼ同じ方式で行われたため、詳細については省略する。こうしてそれぞれの対応する部分だけを抜き出された論文テキストと映像シーンを、次に述べるDRIPシステムを用いて関連付けることで、アノテーションの獲得が行われた。
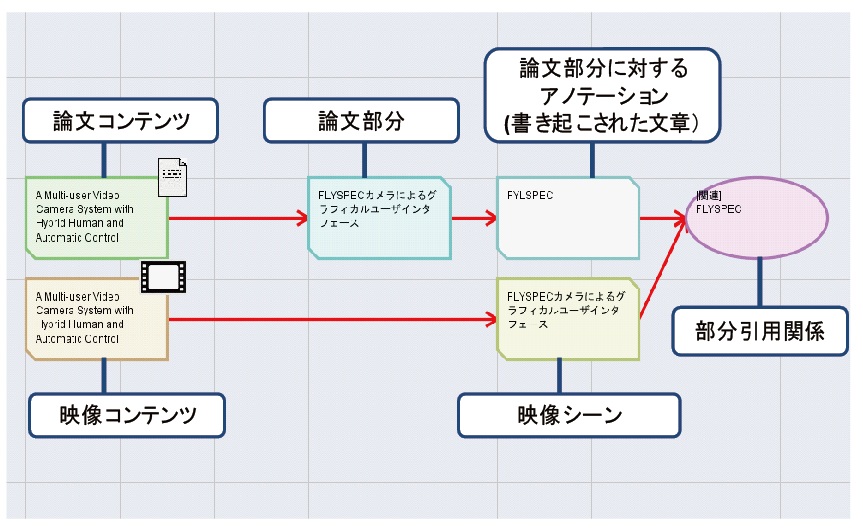
図2.8: 映像シーンと論文部分との関連付け
DRIP(Discussion-Reflection- Investigation-Preparation)システム([5])もまた、筆者が所属する研究室で開発されたシステムであり、ユーザはゼミコンテンツの引用や、タグの付与を行うことで、ゼミコンテンツを要約・分類・整理し、そこから導出される、文献調査やシステム構築といった様々なタスク内容の作成を行うことができる。また、コンテンツをノード、コンテンツ間のリンクをエッジとみなしたグラフ構造を有しており、ユーザは必要に応じてその配置を自由に変更できる。コンテンツにはゼミコンテンツや、そこから生まれた発言、タスクに関するノートがあり、新たに作成したノードを既にあるノードに対して関係付けを行うこともできる。このDRIPシステムで論文部分と映像シーンを参照可能にしたうえで、それらの関連付けが行われた(図[tdr])。
こうして関連付けを行うことで、映像シーンに対するアノテーションとして論文テキストが獲得された。獲得された論文テキストは、検索に活用しやすくするために形態素解析され、シーンタグを得たのち、論文テキスト内における共起頻度からタグ同士の関連度が計算された。この関連度を用いることで、検索キーワードとしてタグが選択された際に、関連するタグを提示することが可能になり、ユーザが目的のシーンを検索するための有用な手掛かりが提供される。また、タグだけでなく、論文タイトルや論文テキストによるシーン検索も可能になっており、関連付けられた論文の情報を用いた柔軟な検索システムが構築された。
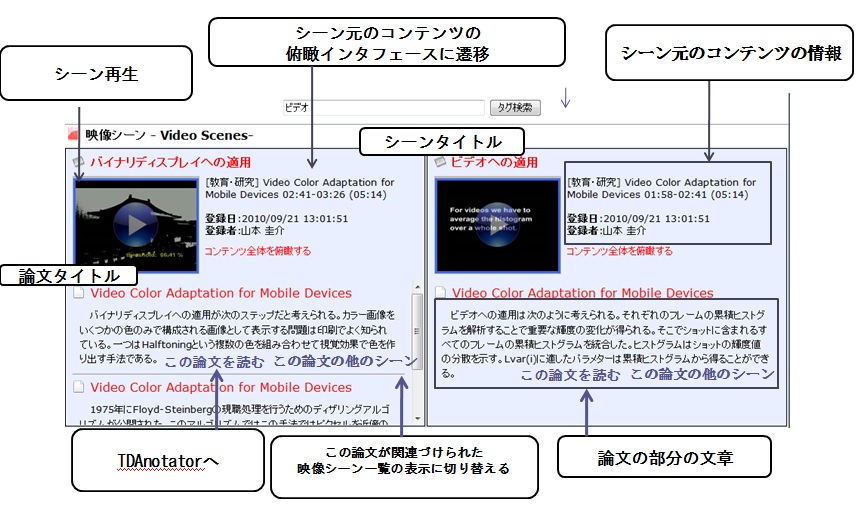
図2.9: 論文が関連付いたシーンの検索結果
検索結果としては、図[tdr]のように、シーンのタイトル、シーンのサムネイル、及び、シーンに関連付けられた論文の部分の文章、さらにその論文のタイトルが表示される。このシステムで収集される論文のテキストは、信頼性の高いアノテーションとして利用することができるため、この検索インタフェースではピンポイントに映像シーンを検索できるようにされた。ユーザは論文の文章を閲覧することでその映像シーンの内容を概ね理解することができるだけでなく、関連付けられている論文のうち、興味のある論文のタイトルをクリックすることで、論文タイトルをクエリとした映像シーンの検索結果が表示される。また、TDAnnotatorへのリンクが設置されており、映像と関連付いた部分を読んで興味を持った論文があれば、すぐに全体を閲覧することができる。
2.4 従来のシーン作成・引用に関する問題点
ここまで述べてきたように、筆者が所属する研究室では、様々な方法を用いて映像コンテンツの時間区間にアノテーションを付与して、それを基にして映像シーンの検索を行う研究が行われてきた。各々の目的に合わせたシステムによって、映像の部分をシーンとして区切るという行為は、その中で様々な手法で行われてきた。しかし、アノテーションを獲得するための過程の一部としての側面が強かったため、シーン作成そのものを目的としたシステムが存在していなかった。
そのため、一度作成したシーンを再びユーザ自身が閲覧することは不可能ではないが、シーン検索などの1ステップを間におく必要があり、かつ、シーンを保存し、検索可能な状態にするためには引用を行う必要があった。しかし、そのようなシステムでは、ユーザが同じシーンを何度も繰り返し見直したい、あるいは、気に入った部分を後ですぐに見直せるようにしておきたい、といった要求に応えるのに適しているとは言い難い。そのような目的のためには、任意のタイミングでシーンを作成可能にして、シーン検索とは別に、各ユーザが作成したシーンをまとめて管理できるシステムが必要となる。
また、従来のシステムで任意のWebコンテンツへのシーン引用を行う場合には、その作成時にシーン区間を指定する必要があった。しかし、エンターテインメント性の高いWebコンテンツへの引用のように、その場でのフィーリングをコンテンツ化する場合には問題がなくても、何かを詳細に解説しているブログの作成や、論文への引用など、映像コンテンツの閲覧から引用先のコンテンツを作成するまでに時間が空くような場合においては、コンテンツ閲覧時に感じた、「このシーンは後で使える」といった感覚を必ずしも維持できるとは限らない。それどころか、シーンを引用したいコンテンツを特定できるクエリを記録もしくは記憶しておかなければ、後にコンテンツを引用する時になって検索して再発見するのが困難になる。
しかし、シーンをあらかじめ作成しておくのであれば、このような問題は解決される。映像コンテンツ中の任意の部分を指定して、それをシーンとして保存しておくことで、映像部分を利用するためのシーン作成と、映像コンテンツ視聴から引用先コンテンツの作成までのタイムラグによって生じる問題を解決できると考えられる。そこで、本研究では、映像コンテンツから任意の部分を選別して、シーンとして管理できるビデオスクラップブックシステムを提案する。本システムの詳細について次の3章で述べる。
3 ビデオスクラップブック:映像シーン作成・共有システム
ビデオスクラップブックの機能は、大きく3つに分けることができる。1つ目はチェックポイント登録機能、2つ目は映像シーン作成機能、3つ目はコンテンツとシーンの整理・表示機能である。
チェックポイント登録機能は、気に入ったコンテンツや後からシーンを切り出そうと考えたコンテンツを、自分のビデオスクラップブックに登録し、アクセスすることを容易にするための仕組みである。この機能だけであれば、一般的な映像共有サイトのマイリスト機能と同等であるが、チェックポイント登録機能では、コンテンツ中のどのタイミングで登録ボタンが押されたかも記録される。また、ボタンを押した際にダイアログなどの表示もされないので、コンテンツの視聴が特に妨げられないのも特徴である。
映像シーン作成機能は、映像コンテンツ中の意味的なまとまりをもった区間や、ユーザがその部分だけを再度視聴したいと考えた区間を指定して、その区間の情報を映像シーンとして登録して、利用できる状態にする仕組みである。また、必要に応じてシーンにタイトルやコメント、タグを付与することも可能とした。このような直接的な入力は、一般的にユーザのコストが高いものであるが、ユーザが自分自身のために行う行為であることを考慮すると、実際に入力される場合は少なくないと考えられる。
コンテンツとシーンの整理・表示機能はユーザ自らが登録したコンテンツやシーンへのアクセスを容易にするための機能であり、それらのコンテンツやシーンの中から目的のものを絞り込むことができる。各シーンの他のユーザに対する公開設定や、タグの確認と追加などの簡単な管理操作も可能である。また、共有状態にされている、他者の作成したシーンを検索・閲覧して、気に入ったシーンを自分のスクラップブックに登録することも可能である。
これらの3つの機能に関して、次節以降にて詳細に解説する。
3.1 チェックポイント登録機能
ある映像コンテンツから映像シーンとして範囲を指定するには、当然ながら一度はそのコンテンツを視聴する必要がある。そして、視聴したコンテンツの中で実際に映像シーンとして区切られるのは、ユーザがそのコンテンツを視聴しているときに「このシーンが気に入った」や「後で繰り返し視聴したい」、あるいは「この部分は参考になる」などの印象を持ったシーンであると考えるのが妥当である。

図3.1: チェックポイント登録ボタンとチェックポイントシークバー
そこで、コンテンツ視聴中に感じたこのような印象をデータとして残すための仕組みが、チェックポイント登録システム(図[check])である。この機能を利用する際にユーザが行うことは、コンテンツ視聴中に「イイ」と感じたタイミングで「イイネ!」ボタンを押す、という簡単な行為のみである。この操作によって、ユーザが「イイ」と感じたコンテンツがビデオスクラップブックに登録されると同時に、ボタンが押されたコンテンツ中のタイムコードがチェックポイントとして保存される。また、そのボタンが押された日時もデータベースに保存される。「イイネ!」ボタンの右隣にある「シーン作成」ボタンをクリックした場合には、そのタイミングをチェックポイントとして登録した上で、次節で述べるシーン作成ページに移動する。
コンテンツそのものがビデオスクラップブックに登録されることによって、ユーザが次回以降にそのコンテンツの視聴やシーンの作成を行う際には、大量に存在するコンテンツの中から前回用いた検索キーワードを思い出すなどして検索する代わりに、自分のビデオスクラップブックの中から目的のコンテンツを探し出すだけでよくなる。検索の対象となる母集団が小さく、ユーザが必要としない類似コンテンツが候補としてヒットしないだけでなく、チェックポイントの登録を行った日時を用いてコンテンツを検索することができるため、より簡単に目的のコンテンツに到達できる。
チェックポイントとして保存された映像コンテンツ中のタイムコードは、コンテンツ視聴ページのチェックポイントシークバーに赤いラインとして表示される。チェックポイントシークバーでは、つまみをドラッグするか、シークバーの範囲内をクリックすることによって、その時間のシークを行うことができる。シークバー上に表示されているチェックポイントを参考にすれば、以前コンテンツを視聴した際に気に入った部分を容易に再発見できる。また、このチェックポイントシークバーには、他のユーザが保存したチェックポイントも青色で表示される。そのため、ユーザは初めて視聴するコンテンツであっても、そのコンテンツにおいて重要性が高いと推測される部分を知ることが可能であり、時間が不足している際にその部分のみを視聴することや、集中して視聴するべき部分の参考にすることなどができる。
3.2 映像シーン作成機能
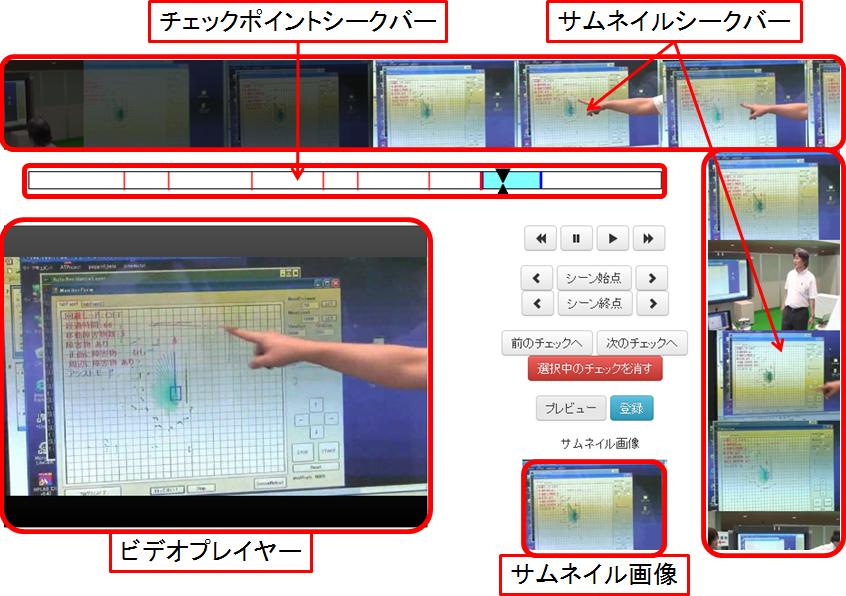
図3.2: ビデオスクラップブックのシーン作成インタフェース
ビデオスクラップブックのシーン作成インタフェース(図[CreateScene])では、図[StartEnd]のボタンを用いてシーン区間を指定する。2.2節で紹介した従来のシーン引用インタフェースで採用されていた、サムネイルのクリックによって始点・終点を指定する方式から変更した理由は2つあり、1つは右クリックやコントロールキーといった、見た目では分からない操作方法を減らすためであり、もう1つはサムネイルから選択したシーンと実際に作成されるシーンとの間に生じる1、2秒のずれをなくすためである。機械処理によって映像からサムネイル画像を作成する際に、完全に等間隔に分ける事は難しいため、その画像のみを用いてシーン区間を指定するとサムネイル上には含まれないシーンが入ってしまったり、逆にサムネイル上では含まれているシーンが切れてしまったりする場合がある。それを防ぐために、コンテンツを実際に再生しながら始点と終点を指定する方式に変更した。

図3.3: シーン区間指定ボタングループ
シーン区間指定ボタンは、ボタンが押されたときに、再生していたコンテンツ中の時間をシーンの始点あるいは終点として設定するためのボタンである。2つのボタンが分かれているのは、一度始点と終点を指定した後にそれらを再度設定し直す際に、個別に変更できるようにするためである。また、始点・終点ボタンの左右にあるボタンは、シーンの始点・終点を1秒ずつ微調整するためのボタンである。

図3.4: プレビューボタンとシーン登録ボタン
シーン区間を決定したら、図[PreviewRegist]のプレビューボタンを押して、指定したシーン区間が自分にとって適切であるかどうかを確認する。修正が必要であった場合には修正して再度プレビューを行うことを繰り返し、問題がなくなれば登録ボタンを押す。すると、登録用ダイアログが表示される。
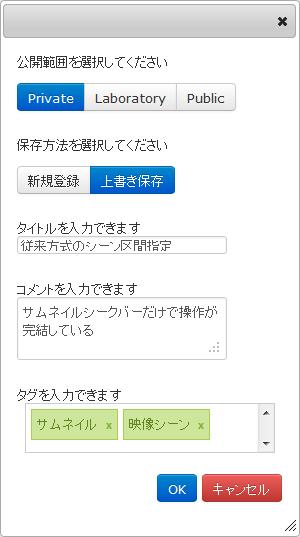
図3.5: 登録ダイアログ
図[RegistDialog]に登録用のダイアログの例を示す。ここでは、公開範囲の選択、保存方法の選択、シーンタイトル、シーンコメント(キャプション)、シーンタグの入力が可能である。公開範囲の選択では非公開(Private)・研究室内のみ公開(Laboratory)・外部公開(Public)の3つの公開範囲を設定できる。ただし、コンテンツそのものが外部に公開されていない場合には、作成したシーンを外部に公開することはできない。保存に関しては、自分が以前作成したシーンを読み込んでいる場合に限り、以前登録した情報を更新するか、あるいは別のシーンとして新規に登録するか選択できる。他のユーザのシーンを読み込んでいる場合には、変更後のシーンは新規に登録される。
3.2.1 チェックポイントシークバー
シーンの作成を行うユーザはまず、チェックポイントシークバー(図[CheckSeek2])、およびチェックポイントへの移動ボタンを用いて、チェックポイントとして登録されたタイムコード周辺のシークを行う。シーンを作成する映像コンテンツが短い場合や目的のシーンがコンテンツの始めにある場合には、シーン作成の際にチェックポイントの参照を行う必要は必ずしもないが、そうでない場合にはチェックポイントを参考にシークを行った方が、目的のシーンを探すための時間を短縮できると考えられる。

図3.6: シーン作成ページのチェックポイントシークバー
チェックポイントシークバーの利用方法は、コンテンツ視聴ページと同様に、シークバー上に表示されているチェックポイント(赤ライン)を参考にながら、つまみをドラッグするか、シークバー内の任意の場所をクリックすることによってシークを行うことである。手動でシーク位置を指定するため、ずれが生じやすいという欠点はあるが、任意の時間に対してシークを行うことができる利点により、チェックポイントよりも少し手前の時間にシークを行うことができることや、シークを行う際の操作が通常のプレイヤーの操作と類似しているため、使用方法が分かりやすいといった利点が挙げられる。
チェックポイント付近へのシークを行うためのもう1つの方法として、次、もしくは前のチェックポイントへのシークを行うためのボタンを用意した。このボタンによるシークは、保存されたタイムコードを利用してシークを行うため、前述の手動でのシークと比べてシークの精度が高い特徴がある。また、これらのボタンによってシークを行った場合、チェックポイントシークバー上の該当するチェックポイントは太く強調して表示されるようになっており、シークバー上のアナログ操作によるシークと異なり、どのチェックポイントを利用したのかをユーザに示すことができる。
チェックポイントシークバーには、シーンの区間として指定された範囲を、水色にハイライト表示することによってユーザに示す役割もある。このハイライト表示によって、ユーザは指定しているシーンがコンテンツ中のだいたいどのくらいの時間に存在しているのか、およびコンテンツ全体の長さと対比して、シーンの長さがどの程度かを容易に把握できる。
チェックポイントの情報は、シーン作成のためだけに保存されているわけではないが、チェックポイントを過剰に作成しすぎた場合や、まちがって登録してしまった場合、あるいはシーンを作成したことでそのチェックポイントがもう役割を終えたと考えられる場合のために、チェックポイントをユーザが削除できるようにした。ユーザがチェックポイントの削除を行いたい場合には、削除したいチェックポイントを選択状態(太く強調された状態)にして、「チェックポイントを削除」ボタンを押す。
3.2.2 サムネイルシークバー
サムネイルシークバー(3.2節の図[CreateScene]の上部と右側の赤枠部分)では、映像から切りだした画像が水平および垂直に並んでいる。水平サムネイルシークバーは1秒ごとのサムネイルから構成されており、サムネイルをクリックすることで、クリックされた画像をシーンの代表サムネイルに指定するとともに、その画像の付近の映像にシークを行うことができる。
水平サムネイルシークバーは通常は中央のプレイヤーの映像に合わせて自動的にスクロールされるが、ドラッグしてスクロールすることでオートスクロールが一時的に停止し、手動でのスクロールに変更される。水平サムネイルシークバーのオートスクロールが停止している間もプレイヤーの再生は続いているため、一時的に同期が解除されることになるが、シークを行うと再び同期的にスクロールされる。
垂直サムネイルシークバーは機械処理によって検出されたカットごとのサムネイルにより構成されており、こちらは常にプレイヤーの再生位置と同期している。このサムネイルをクリックすることによって、そのカットの開始時間にシークすることが可能であり、シークバーをドラッグしてスクロールすれば、スクロールを終了した位置に合ったカットにシークが行われる。また、カット検出がうまくいかなかった場合には、映像を等間隔に分割した上でそれぞれの先頭フレームのサムネイルから垂直サムネイルシークバーを構成することも可能になっている。ビデオスクラップブックのシーン作成においては、おおまかなシークはチェックポイントによって行われる前提であるが、チェックポイントが登録されていない点をおおまかに探す際には、この垂直サムネイルシークバーが利用できる。
このサムネイルシークバーはSynvieのシーン作成インタフェース[2](2.2節の図[synvie2])の影響を大きく受け、機能を引き継いでいるが、変更されている点も存在する。それは再生プレイヤーをサムネイルシークバーから分離して、中央の大きい空間に配置したことある。Synvieのシーン区間指定インタフェースは、複数のコンテンツからのシーン引用を可能にするため、サムネイルシークバーを多層に表示する必要があった。また、シーンの作成と同時に引用先コンテンツの作成も同じ画面内で行う前提であったため、テキスト執筆スペースを確保しておく必要もあった。そのため、コンテンツ1つあたりに充てることのできるプレイヤーの領域は、水平サムネイルシークバーと垂直サムネイルシークバーが交差するわずかな領域のみであった。一方、ビデオスクラップブックにおけるシーンの取り扱いでは、シーンはあらかじめ作成しておき、必要に応じて後で利用するものであるため、シーン作成インタフェースにおいては1つのコンテンツのみからシーンを作成する。そのため、プレイヤーの領域を中央に大きくとることが可能になり、映像を見ながらのシーン区間の指定をより容易にした。
もう1つの変更点として、右クリックやコントロールキーといった、複雑な操作を極力減らした点が挙げられる。これは、用途を明確に表したボタンを用意することで、覚える必要のある操作を減らすとともに、初見のユーザでも最低限の機能は利用できるようにすることが目的であるが、まだ分かり辛い部分は多いと考えられるので、今後も改善する必要がある。また、操作がマウスの移動と左クリック操作のみになったことで、iPadなどのタブレット型デバイスでの利用も可能になっている。
3.3 コンテンツとシーンの整理・表示機能
映像シーンは、誰かに公開するためであれ、自分だけのためであれ、ユーザが何らかの利用目的をもって作成される。しかし、作成されたシーンが何の規則性も持たずに並べられていては、ユーザが視聴したいシーンにアクセスすることが困難になる。
そこで、ビデオスクラップブックのシステムでは、ユーザが作成したシーンをコンテンツごとにまとめ、かつ検索可能な状態にすることで、その問題の解決を図っている。それがユーザごとのコンテンツとシーンの整理・表示機能(以降マイページと呼ぶ)である。このマイページに関しては、3.3.1項にて詳細に述べる。
次の3.3.2項では、各ユーザが作成したシーンの他のユーザへの公開に関して述べる。これは、他のユーザが公開したシーンを視聴したユーザが、そのシーンの内容を受けて関連するシーンを作成するなどのソーシャルなシーン作成活動が行われることを狙ったものである。また、ユーザの作成したシーンを他のユーザが利用することで、各ユーザの手間を削減することや、同一シーンが検索結果として複数表示されることを防ぎ、それらのシーンに対するアノテーションを1つのシーンに関するものとして扱いやすくする目的もある。
3.3.3項では、共有されているシーンの一覧表示と、その中から目的のシーンに到達するための仕組みについて述べる。システムが十分に活用されていれば、全ユーザによって共有状態にされたシーンの総数は、各ユーザ個人が作成したシーンの総数と比べると膨大な量になると考えられる。そこで、ユーザマイページのものよりも検索機能を多く持たせることで、その膨大なシーンの中から目的のシーンを検索できるようにした。
3.3.4項では、シーン作成のインタフェースに関して、Synvieのシーン作成インタフェースと比較して、主観評価を行った。
3.3.1 ユーザマイページ
ビデオスクラップブックのユーザマイページでは、各ユーザがチェックポイントを登録したコンテンツと、そのユーザによってシーンが作成されたコンテンツが一覧表示される(図[scrap1])。このページでは、各コンテンツからユーザが作成した映像シーンの数の確認と、作成されたシーン一覧への移動が可能である。また、このコンテンツ一覧からすぐにコンテンツを探すことも可能である。

図3.7: ビデオスクラップブックに登録されたコンテンツ一覧
ビデオスクラップブックに登録されているコンテンツが増加すると、目的のコンテンツを探し出すのが難しくなる。そこで、検索インタフェースを用意して、登録されたコンテンツの中から目的のコンテンツを簡単に探し出せるようにした。提供している検索機能は、カテゴリ検索、更新日時検索、キーワード検索である。
カテゴリ検索では、コンテンツごとに1つ設定されているカテゴリタグを指定して、該当するコンテンツのみを表示することができる。また、各カテゴリごとにいくつのコンテンツが登録されているかが表示される。更新日時検索では、大まかな期間(今週、先週、今月など)を指定することで、その期間にチェックポイントが登録されるかシーンを作成されるかしたコンテンツが表示される。キーワード検索ではオートコンプリート方式を採用して、登録コンテンツあるいはシーンに付けられたタグを1文字入力ごとに表示する。また、キーワード検索ではタグだけでなくコンテンツタイトルやシーンタイトル、シーンコメントの部分一致によっても検索が可能で、複数キーワードを指定することもできるので、柔軟にコンテンツを絞り込むことができる。
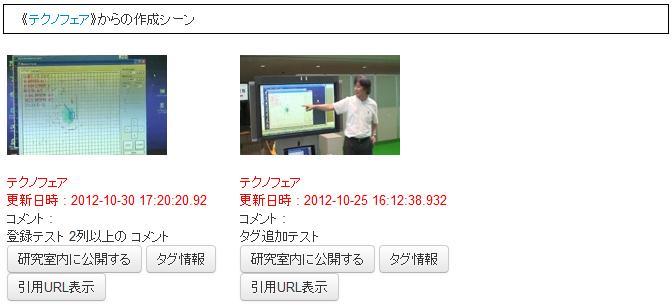
図3.8: コンテンツごとのシーン一覧
また、シーンを再編集・再視聴する場合には、登録コンテンツごとに作成されたシーン一覧(図[scrap2])を利用する。シーン一覧においては、登録時にユーザが入力したシーンタイトルとシーンコメントが表示される。また、各シーンを作成・更新した日時も表示されるため、1つのコンテンツから複数シーンを作成していても、比較的容易に目的のシーンが発見できる。キーワード検索を行った場合には、コンテンツのタイトルや投稿者コメント、およびタグと、入力されたキーワードと照合するものがあるか調査され、照合するものがあった場合には、該当コンテンツ一覧と、該当コンテンツごとの作成されたすべてのシーンが一覧表示される。キーワードと照合するコンテンツがなかった場合には、シーンタイトル・シーンコメント・シーンタグを検索対象に追加して、キーワードと照合したシーンの元のコンテンツの一覧と、コンテンツごとの照合したシーンが一覧表示される。そのため、シーンに付与されているタグなどのアノテーションを検索に用いることによって複数のシーンから目的のシーンを絞り込むことができる。
3.3.2 映像シーンの公開
映像シーンの公開範囲は、ビデオスクラップブックのユーザマイページと、映像シーン作成時の登録ダイアログから変更することができる。実際にシーンが公開される状況としては、再生時間が長いコンテンツに関して重要なシーンだけでも見てもらいたい、というようなものや、繰り返してループ再生したいようなシーンを他のユーザに広めたい、などの目的が考えられる。一方で、自分が作成したシーンや、それに付与したアノテーションを他のユーザには見られたくない、というユーザも多く存在していると考えられる。そこで、本システムでは公開するかどうか、およびその範囲を設定できるようにした。現時点では、非公開(Private)・研究室内のみ公開(Laboratory)・外部公開(Public)の3つの範囲しか選択できないが、将来的には公開できるグループの種類を選択できるようにする必要があると思われる。
シーン公開機能の目的は、作成したシーンが別ユーザに視聴・評価されることで、各ユーザのシーン作成に対するモチベーションを高めることである。また、シーンが他のユーザに検索・視聴されることを意識することで、シーン区間の指定や付与されるアノテーションの質が高まることも期待している。
3.3.3 共有シーンの視聴
3.3.2項で述べたように、ビデオスクラップブックでは、作成したシーンを別ユーザにも公開することで、シーンの共有が可能である。ここでは、共有されているシーン一覧に関して述べる。
他のユーザの共有シーンに関しては、すべてのユーザのシーンがそれぞれの元となったコンテンツごとに整理して表示される。シーン一覧ではシーンタイトルと更新日時に加えて、作成したユーザの名前も表示されるため、それを参考にして視聴あるいは利用するシーンを選択できる。コンテンツごとに表示されることによって、ユーザは元のコンテンツから大まかにシーンを選別することが可能になる。また、不特定多数のユーザが用いるWebサービスである性質上、シーンに対して、検索にヒットさせるためにシーンの内容とは無関係なテキストをタグに追加されるような場合が想像されるが、コンテンツのタイトルを参考にすることでユーザは本当に目的に合ったシーンかどうかを大まかに予測することができる。

図3.9: 共有シーンの検索インタフェース
共有シーンの絞り込みや検索は、図[SharedScraps]に示すインタフェースを用いて行うことができる。ユーザ自身が作成したシーンを検索する場合のインタフェースと比較すると、ユーザ名による検索が可能な点で異なっている。これは、不特定多数のユーザにより作成され、共有されるシーンの数は、ユーザ自身が作成したシーンの数よりも多数となることが容易に予想されるため、その中から目的のシーンに迅速にたどり着くための仕組みが必要だと考えられたためである。シーンを作成したユーザ名によってシーン検索することで、お互いのユーザ名を知っているユーザ同士でシーンを紹介しあう、といったことが容易になる。しかし、将来的にユーザ数が増えた場合には、ユーザを任意のグループに分けた上でそのグループの中からユーザを検索する、といった工夫を施す必要があると考えられる。
ユーザ名による検索とは別に共有シーンを利用する際に重要になるのが、共有シーンに対するブックマーク機能である。共有されたシーンは、コンテンツ数やユーザ数が増加するにつれて、次第に目的のものを絞り込むためのコストが大きくなることが予想される。そこで、気に入ったシーンをブックマークに登録することによって、そのシーンに対するアクセス性を高めることが可能である。シーンに対するブックマークは、共有シーンの一覧のボタンをクリックすることで簡単に登録でき、同様の操作で簡単に解除することが可能である。
この映像シーンの共有が、各ユーザがシーンを作成・公開する強いきっかけになることを筆者は期待している。
3.4 評価
従来システムであるSynvie[2]においては、シーンの作成は目的ではなく、あくまでもシーン引用のための過程であった。そのため、ビデオスクラップブックシステムの評価に関しては、4章において述べるシーン引用に関する評価と同時に行われた。しかし、ビデオスクラップブックシステムにおいては、シーンの作成とシーンの利用は全く別の機能であるため、この節ではシーン作成時のインタフェースに関する主観評価とその結果に関してのみ述べる。
なお、引用前にあらかじめシーンを作成し引用可能にしておけることの優位性の評価に関しては、4章で述べる。
詳細な評価方法について3.4.1項にて述べ、その結果について3.4.2項にて述べる。
3.4.1 評価方法
研究室の学生11名に実際にSynvieによるシーン作成と、今回開発したビデオスクラップブックシステムによるシーン作成の両方を行ってもらい、比較実験を行った。また、その後、システムの大きな違いであるチェックポイントシークバーの有無と、全体的なUIの使いやすさの2つの観点から、5段階評価のアンケートによる主観評価を行ってもらった。また、数値による評価のみでなく、自由記述形式による意見なども集めることで、今後のシステム改善などにつなげることも本実験の目的とした。
実際の主観評価の内容は、「チェックポイントシークバーはシーンを作成する際に参考になったか」と「シーン作成時のタイトルやコメント、タグといった入力は苦痛に感じたか」、「従来(Synvie)のシーン作成インタフェースと比較して使いやすかったか」の3つである。また、被験者にはあらかじめ両システムの利用方法を伝えており、無理なくシーンの作成が行える状態とした。
実験の流れとしては、まずは実験の対象とする映像コンテンツを視聴し、チェックポイントの登録を行ってもらった。次に、1週間ほど時間をおいたのち、登録されたチェックポイントを参考にして提案システムでシーンを作成してもらった。最後に、Synvieによってシーンを引用してドキュメントを生成してもらい、その過程におけるシーンの作成と比較して主観評価を行ってもらった。結果を次項にて述べる。
3.4.2 結果と考察
まず、「シーンを作成する際にチェックポイントは参考になったか」という問いに対する主観評価の結果を表[qid17]に示す。なお、点数は1の「参考にならなかった」から5の「参考になった」までの5段階評価によるものである。この結果から、コンテンツ視聴時に登録したチェックポイントは、シーンを作成する際の参考になることが示された。また、アンケートの自由記述欄には、「動画をすべて見る必要がなくなったため役に立った」や「映像のシークするのに役に立った」といった意見がみられた。また、「チェックポイントの前後にシーンの開始点と終了点がくるようにすると便利」という意見が得られたため、チェックポイントの前後何秒くらいにシーンの始点や終点が指定されやすいかを調査して、その結果とコンテンツに付与されたアノテーションを活用することで暫定的なシーンを提示できるように改良する予定である。一方で、「はじめからシーンを作りたいという意図がなければ、シーンの開始位置や終了位置前後にチェックポイントが登録されることは少なく、動画の最後か本当にいいと思った部分に対してチェックがされるのではないか」という意見も寄せられた。シーンが作成されるのはコンテンツ視聴時にユーザがいいと感じた部分の周辺だという想定でチェックポイントをシークに活用しているが、そうでない場合がどれくらいあるのか、今後もシステムを運用して調査する必要がある。
| 点数 | 1 | 2 | 3 | 4 | 5 |
| 人数 | 0 | 0 | 1 | 6 | 4 |
| 平均点 | 4.273 |
次に、「シーンタイトルやシーンコメント、シーンタグの入力は手間だと感じたか」という問いに対する主観評価の結果を表[qid21]に示す。なお、点数は1の「手間だと感じた」から5の「手間とは感じなかった」までの5段階評価によるものである。実験の際には、必ずそれらのアノテーションを入力するように指示をしてあり、その上でも点数が4以上のユーザが多かった。高い評価をつけた被験者の自由記述欄には、「特に手間と感じるほどのことではない」や「何らかの意図を持ってシーンを作成するのでタイトルなども自然と決まった」などの肯定的な意見が見られた。一方で、評価2を付けた、すなわち「少しは手間に感じた」被験者も2人見られた。また、別の被験者の自由記述欄において「シーンを複数作成するときにどれくらい手間かは分からない」や「それほど大変ではないがタイトルだけで十分な気もした」といった意見もあった。これらのことから、やはりタグに関してはタイトルやコメントなどを参考にして候補となる語を提示するなどの工夫が必要になると思われる。
| 点数 | 1 | 2 | 3 | 4 | 5 |
| 人数 | 0 | 2 | 3 | 4 | 2 |
| 平均点 | 3.545 |
最後に、「Synvieのシーン引用UIのシーン作成部分と比較してシーンの作成は楽になったと感じたか」という問いに対する主観評価の結果を表[qid39]に示す。なお、点数は1の「楽になったとは感じなかった」から5の「楽になったと感じた」までの5段階評価によるものである。この結果から、シーンの作成のためのUIとして、従来のシーン作成よりも容易になったという評価が得られたことが分かる。これは、SynvieのUIはあくまでもシーンの引用のためのUIであり、シーンの作成のための機能に大きく画面上の空間を占めることができなかったことに由来する部分が大きいと考えられる。そのため、シーン作成に特化したことによってその問題点を改善できたと思われる。自由記述欄から得られた意見としては、「チェックポイントの情報がある分シークがしやすかった」や「始点や終点の調節が容易であった」といったものがあった。一方で、「従来のインタフェースの方がシーンの開始点と終了点の位置が直感的に分かりやすかった」という意見も得られたので、従来のものを参考にしながらより分かりやすくシーン区間の情報を提示する必要がある。
| 点数 | 1 | 2 | 3 | 4 | 5 |
| 人数 | 0 | 0 | 2 | 5 | 4 |
| 平均点 | 4.182 |
4 映像シーン引用の応用
映像シーン引用とは、映像シーンを他のコンテンツに引用できるようにするための仕組みである。具体的に映像シーンの引用に適したコンテンツとしては、ブログのような、著者の興味のある情報を収集し、情報の発信源となるものや、4.1節で述べるマルチメディア論文など、さまざまなものが考えられる。そのようなコンテンツに、ビデオスクラップブックで作成したシーンを引用できるようにすることによって、ユーザのシーン作成に対するモチベーションが高まることが期待される。また、シーンを引用して作成されたコンテンツには、そのシーンの内容を説明するテキストが含まれると考えられるため、シーン引用は映像シーンに対するアノテーションの獲得方法としても大きな意味を持っている。
ビデオスクラップブックシステムにおいては、シーン作成時にユーザによって、タイトル・コメント・タグのようなアノテーションが付与できるようになっており、それらを用いてシーンを検索することが可能である。しかし、それらのアノテーションの付与はユーザの任意によるものであるため、必ずしも十分なアノテーションが付与されるとは限らず、シーンの作成者のみがアノテーションを付与するため、シーン作成者の知識以上のアノテーションは付与されない。自ら作成した、あるいは他者によって作成・共有されたシーンを他のコンテンツに引用できるようにすることで、引用先のコンテンツから、より高度なシーンの検索やコンテンツの俯瞰支援に活用できる、新たなアノテーションを獲得できる機会が増える。
従来のSynvieにおいては、映像シーンを引用したブログエントリの作成が可能であった。しかし、ブログエントリを作成する際には、まずはシーンの作成を行った後で、ブログテキストの執筆に取りかかる必要があった。そのため、シーンの内容のみに関する記述する場合には問題ないが、シーンの内容を踏まえて他の話につなげる、といった場合にはシーンを作成している間にコンテンツに記すべき内容を忘れてしまう恐れがあった。ビデオスクラップブックシステムにおいては、シーンの作成はあらかじめ行っておくことができるため、シーンを引用してドキュメントを作成する際には、そのドキュメントの作成に集中することができる。
今回の研究では、シーンの引用先としてマルチメディア論文に着目し、実際に映像シーンを引用したマルチメディア論文を執筆できる仕組みを開発した。4.1節では、映像シーンのマルチメディア論文への引用について詳しく述べる。4.2節では、論文以外のコンテンツなどへのシーン引用に関する展望を述べる。
4.1 論文への引用
2.3節で述べたように、映像シーンと論文部分を関連付けることによって、論文テキストを映像シーンアノテーションとして利用することができる。また、論文の部分に関連する映像を視聴することによって、論文への理解を高めることもできる。しかし、論文の執筆者と映像シーンを関連付ける人が異なる場合、関連付けられたシーンが適切なシーンであるかどうかは必ずしも判断できない。また、ユーザが論文の部分と映像シーンとの関連付けを行う理由に乏しいという問題があった。
そこで、完成した論文に対して映像シーンを関連付けるのではなく、論文執筆者によって映像シーンを論文中に引用してもらうという方式で論文部分と映像シーンとの関連付けを行うことによって、上記の問題を解決できるのではないかと考え、それを実現するためのシステムを開発した。論文中に映像シーンが引用される場合には、シーンを引用してテキストを記述するのは論文執筆者であるため、引用されたシーンの適切さは保証されるだろう。また、シーン引用を行う動機付けに関しても、現状では論文に映像を埋め込むという行為は一般的なものではないが、図の埋め込みは一般的に行われているため、将来的には自然な行為として、論文への映像シーン引用が行われる可能性は十分に考えられる。
筆者が所属している研究室では、論文執筆中に、参照するコンテンツの部分要素間に関連付けを行うことのできる、TDEditor[6]が利用されている。詳細に関しては4.1.1項にて述べるが、これは、論文の章や節などの構成要素に対してコンテンツを関連付けることによって、論文に必要な情報を整理して、論文の執筆を補助するためのシステムである。
映像シーンの論文への引用のために、ビデオスクラップブックシステムによって作成した映像シーンを参照・引用できるよう、TDEditorの機能を拡張した。4.1.1項では、まずこのTDEditorに関して述べる。次に4.1.2項においてTDEditorで映像シーンを引用する方法を述べる。最後に4.1.3項で、実際にTDEditorを用いてシーン引用を行ってもらった評価実験の内容と結果に関して述べる。
4.1.1 論文作成支援システムTDEditor
TDEditorは筆者が所属している研究室で開発・運用されている論文作成支援システムである。日常的な研究活動の中から必要な情報を検索・参照・引用可能な仕組みをユーザに提供することによって、論文執筆に必要な情報の可視化を行い、執筆作業を効率化することを目的としている。
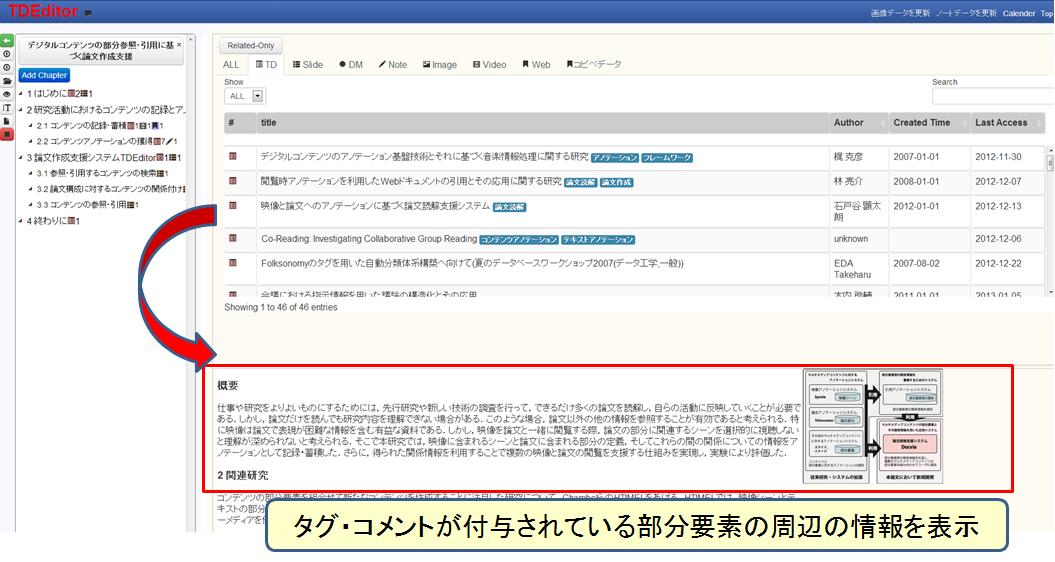
図4.1: TDEditorのコンテンツ検索インタフェース
図[TDEditorContents]がTDEditorにおいて論文に参照・引用するコンテンツを検索するためのインタフェースである。この画面では、研究活動の中でユーザが閲覧・作成してきたコンテンツのタイトルが、著者や閲覧・作成日時とともに一覧で表示されている。コンテンツは種類ごとに区別して表示することが可能であり、表示の順番を並べ替えることも可能である。コンテンツの並べ替えによって、最近閲覧したコンテンツなどは、容易に発見できる。また、コンテンツの数が多く、参照・引用したいコンテンツがなかなか見つからない場合には、キーワード検索も可能である。
一覧におけるコンテンツのタイトルにマウスカーソルをあてることで、一覧の下の領域に、ユーザがそのコンテンツに対してアノテーションを付与した部分とその前後の一部の情報が表示される。論文の場合にはユーザが2.3節で説明したTDAnnotatorを用いてタグやコメントを付与した部分のテキストとその周辺の画像が表示され、スライドの場合には、アノテーションが付与されたページのサムネイル画像が表示される。これらの表示によって、ユーザはコンテンツの内容を大まかに把握することができ、参照・引用するべきコンテンツかどうか判断することができる。
TDEditorでは、論文構成(目次案)に対して、検索したコンテンツの部分要素の関連付けが可能である。関連付けを行うことによって、論文の章や節ごとに参照・引用可能なコンテンツを整理することができ、大まかに論文執筆に必要な情報の量を把握することができる。また、その章や節に関連付けられたコンテンツの部分要素のみを参照することができるため、実際に論文を執筆する際には、効率良く関連付けられたコンテンツの部分とアノテーションを参照することができる。
4.1.2 映像シーンスクラップの論文への引用
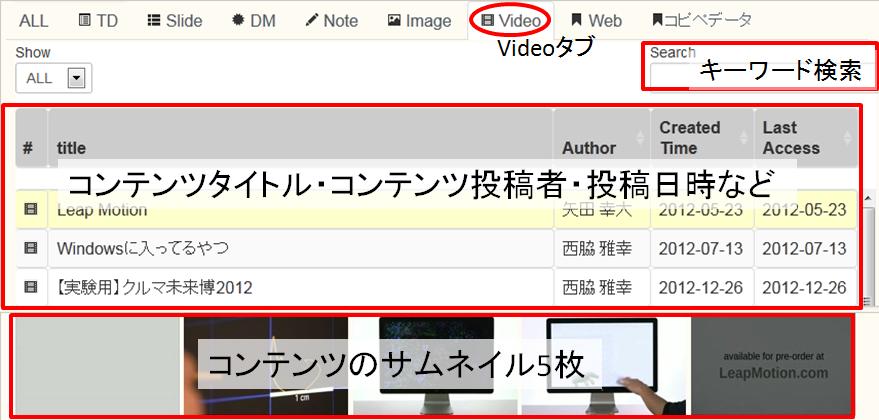
図4.2: TDEditorでの映像コンテンツ一覧
ビデオスクラップブックシステムで作成したシーンをTDEditorで論文に引用するためには、まずはリソース一覧のVideoタブをクリックする(図[TDContents])。そうすると、ユーザがシーンを作成したコンテンツや投稿したコンテンツのタイトル・投稿者・投稿日時などが一覧表示される。下のスペースにはマウスカーソルが当たっているコンテンツのサムネイルが5枚等間隔に表示され、引用するシーンを含むコンテンツかどうか確認できる。また、一覧に表示されるコンテンツ数が多い場合には、キーワード検索によって目的のコンテンツを絞り込むことが可能である。
コンテンツのタイトルをクリックすると、自分自身がそのコンテンツから作成したシーンが一覧表示される。このシーン一覧では、各シーンごとにシーンタイトル・シーンコメント・シーンタグが表示されるとともに、シーン区間の映像に含まれるサムネイルが5枚表示される。シーン作成時に指定した代表サムネイルの他に、シーン区間内の複数のサムネイルを表示することによって、ユーザはそのシーンがどのようなシーンか大まかに把握することができる。
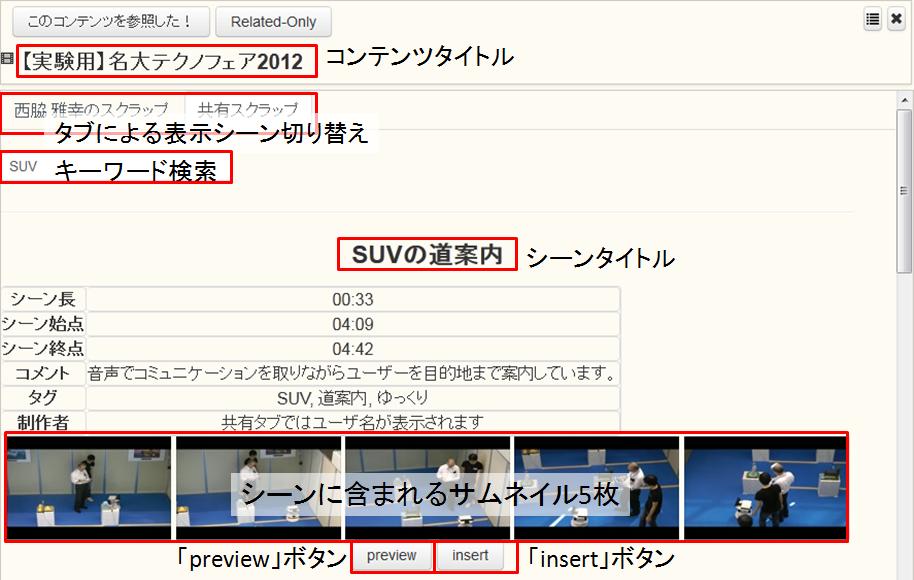
図4.3: 参照・引用シーンの選択
また、ユーザは自分自身が作成したシーン以外に、他のユーザによって作成された共有シーンも参照・引用することができる(図[TDSceneSelect])。タブを切り替えることで、そのコンテンツからユーザが作成したシーン一覧と、他のユーザによって作成された共有シーンの一覧が切り替わって表示される。共有シーンの一覧においては、シーンタイトル・シーンコメント・シーンタグに加えて、シーンを作成したユーザ名も一覧に表示される。また、これらのシーン一覧においても、複数のシーンの中から参照・引用するシーンを検索するために、キーワード検索を行うことができる。
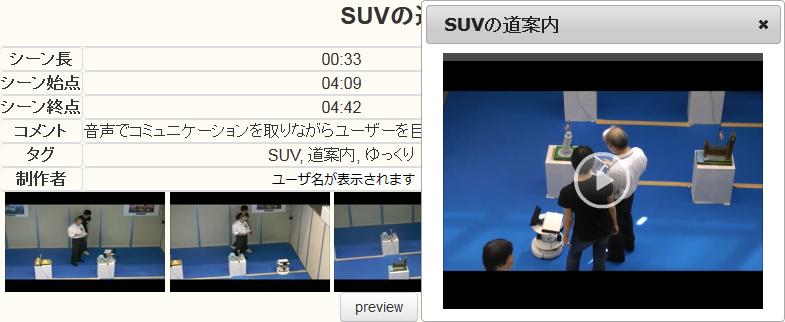
図4.4: TDEditor上でのシーンプレビュー
図のインタフェースにおいて「preview」ボタンを押すと、シーン再生用のダイアログとプレイヤーが表示され、その映像シーンの再生が開始される(図[TDPreviewDialog])。論文に引用されるシーンに限らず、現在執筆中の内容に関連する映像シーンを視聴することによって、執筆するべき内容を整理・確認できるようになり、論文執筆の効率化につなげることができる。また、シーン引用を行う際に引用シーンを視聴することで、そのシーンが引用するべき内容として適切か確認する役割もある。
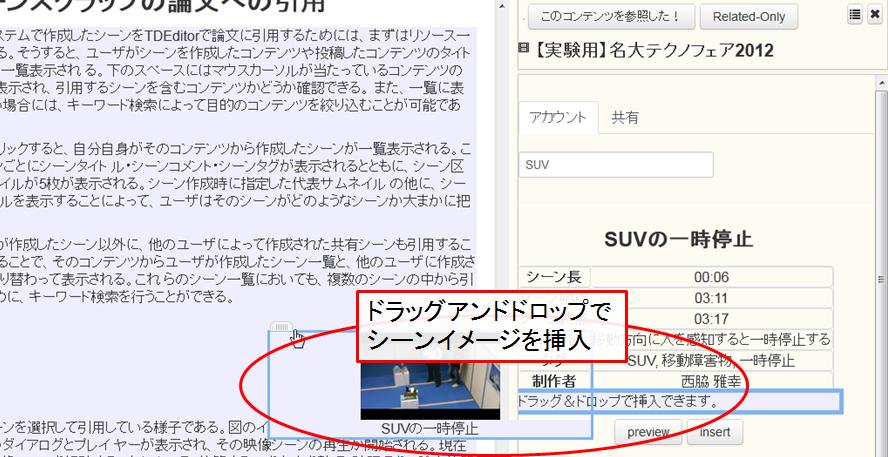
図4.5: TDEditorによるシーン引用
引用するシーンが決まったら、「insert」ボタンを押すと、表示されていたシーンのサムネイル5枚が、代表サムネイル1枚に置き換わる。この代表サムネイルを取り囲むブロックのつまみの部分をつかみ、論文中の引用するべき部分にドラッグアンドドロップすることで、サムネイルと図のキャプションを論文に引用することが可能である(図[tdScene])。引用したシーン(の代表サムネイル)にカーソルを合わせ右クリックをすると、そのシーンのラベルを入力することができる。シーンの内容に関わるテキストを記述した場合には、図の場合と同じように、ラベルを参照することによって、そのテキストがどのシーンに対するものであるかを明示することができる。
引用したシーンは、紙面の論文として発行する際にはイメージとして表示されるが、Web上でマルチメディア論文として論文を閲覧する際には、映像シーンとして視聴することができる。執筆された内容に関連する映像シーンを視聴することにより、論文の閲覧者はシーンによって補足されている部分の内容をより容易に理解することができると考えられる。
4.1.3 評価と考察
3.4節では映像シーンの作成に関する主観評価について述べたが、ここでは映像シーンの引用に関する主観評価について述べる。研究室の学生11名に、TDEditorによるビデオスクラップブックシステムで作成したシーンの引用と、Synvieによるシーン引用を行ってもらい(図[Difference])、シーンの作成とドキュメントの作成のステップが分かれていることに関して5段階で評価してもらった。なお、本実験においては、引用するのは指定した実験用のコンテンツであり、作成してもらったドキュメントは真面目な内容のものではあるが、論文ではない。また、Synvieのシーン引用に関しては、比較のための仕様として、ブログエントリではなくドキュメントを作成できるように変更して実験を行った。
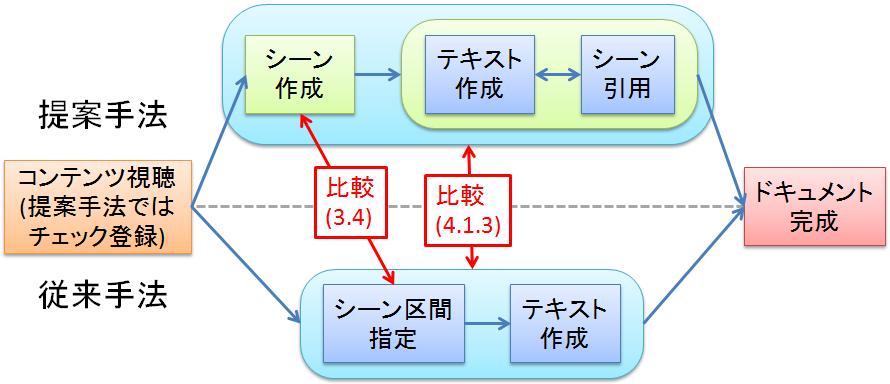
図4.6: 実験の流れ
ビデオスクラップブックシステムにおいて作成したシーンを引用して、TDEditorを用いてドキュメントを作成すること(作業1と呼ぶ)と、Synvieを用いて、引用するシーンをその場で決定しながらドキュメントを作成すること(作業2と呼ぶ)とを比較するため、グループをAとBの2つに分けて、グループAでは作業1を先にやってもらい、グループBでは作業2を先にやってもらった。こうして両方の手法によってシーン引用ドキュメントを作成してもらった後、「あらかじめシーンを作成しておけることは文書作成時にシーンを指定することと比較して有意義だと思ったか」という質問に対して主観評価で答えてもらった。表[qid41]にその結果を示す。
| 点数 | 1 | 2 | 3 | 4 | 5 |
| 人数 | 0 | 1 | 1 | 6 | 3 |
| 平均点 | 4 |
結果としては、有意義だと思うとの評価が多く集まったが、2や3といった評価も含まれているため、今後もシステムの運用を続けて、より使いやすくなるように改善する必要がある。今回の実験では、あらかじめドキュメントを作成する前提でシーンを作成してもらったため、シーンの作成とドキュメントの作成が分かれている意義が分かり辛かったことが低評価につながった可能性も考えられる。自由記述の解答に関しては、「先にシーンを作っておけるとシーンを作成している間に書こうとしている内容を忘れることがない」や「事前にシーンを作成している場合には大体の内容を把握しておけるので、内容や流れに一致する文章が書きやすい」などの回答が得られた。一方で、「初めからドキュメントの作成を目的としてシーンを作成する場合にはシーンの作成と引用でフェイズが分かれていることを煩わしく感じるかもしれない」といった意見も得られた。
ビデオスクラップブックによるシーン作成では、シーンを作成する際にはそのシーンを引用することは必ずしも想定されておらず、映像の特定部分の視聴や他のユーザへの紹介などの目的でシーンが作成されることも考えられる。そのようなシーンも含めて、以前作成した、あるいは共有されたシーンを引用することができるという機能を持ったシステムであるため、シーンの作成と引用ドキュメントの作成は完全に別々のものとなっている。しかし、はじめから作成するシーンとドキュメントの内容が決まっている場合や、逆にテキストのみがすでに作成されている状態からシーンを作成する、といった場合も考えられるため、TDEditorとビデオスクラップブックのシーン作成ページに相互リンクを提供するなどして、ユーザの任意のタイミングでシーンを作成して引用できるようにシステムを改善する必要があると考えられる。
4.1.4 引用論文からのシーンアノテーションの獲得
2.3節で述べたように、論文に引用された映像シーンに対して、引用先の論文テキストを用いることによって、高度なアノテーションが得られることが確認されている。TDEditorでの映像シーンの引用は、そのようなアノテーションを、論文執筆を通じて獲得することを目的としたものである。ユーザが行うのは、論文執筆という自分自身の活動である。そのような自然な活動の中からアノテーションを獲得することで、ユーザにアノテーションを行っていることを意識させずにアノテーションを集めることが可能になるはずである。
論文中に図が引用される場合には、基本的にはその図にラベルがつけられ、テキスト中において図○では、といったように図とテキストに対応が付けられる。映像シーンの引用であっても、同じように対応を付けることが自然であり、その対応を利用して、引用した映像シーンを参照している論文テキストや、その周囲のテキストをアノテーションとして取得することができる。
ラベルによってシーンを引用したことが明記されている論文テキストは、そのシーンの内容に関する内容を含むことがほぼ明らかであるため、テキストそのものをシーンに関する説明文として利用することができる。また、そのテキストを形態素解析して得られたタグは、比較的信用度の高いタグとして重み付けを行うことができると考えられる。
また、ラベルの貼られたテキストと同じ段落に含まれるテキストは、直接的にシーンの内容を記していなくても、背景であったり、展望であったりを記していることも考えられるので、こちらもシーンに関連する文章として利用することが可能である。このテキストからタグを抽出する場合には、シーンとは間接的にしか関わりのないタグが含まれる可能性は高いが、シーンを視聴しただけの人には作成できないタグを付与することができるので、このタグを検索に利用することには十分に意味があると考えられる。
4.2 展望
4.1節ではTDEditorを用いた論文への引用と、引用論文からのアノテーションテキストの獲得に関して述べた。しかし、獲得したアノテーションは実際に有効活用しなければ意味をなさない。そこで、まずは2.3章の研究でも行われたように、獲得した論文テキストを用いた映像シーンの俯瞰支援を行うことが考えられる。そうすることで、映像シーンの内容の理解がより容易になるとともに、関連する論文の閲覧ページにリンクできるようになる。また、同じ論文で引用された別のシーンの情報や、そのシーンを引用した別の論文を容易に閲覧できるようにするなどの工夫を加えることも考えられる。1つのシーンから様々な関連論文や関連シーンを検索できるようになれば、ユーザは様々な知識をより容易に得ることができるようになる。
論文へのシーン引用から得られるアノテーションの活用の幅を広げるだけでなく、作成したシーンを引用できるコンテンツの種類を増やしていく必要もある。HTMLタグの埋め込みという手法であれば、あらゆるWebコンテンツに対して映像シーンを引用することはそれほど難しくないが、引用先のコンテンツからうまくアノテーションを集めるためには何らかの工夫が必要になってくる。論文への引用は、専門的な知識を持った研究者による引用であるため、質がある程度保証されるが、一方で限られた映像コンテンツのさらに限られた部分でなければ引用されることがない。より一般的なコンテンツにも映像シーンを引用可能にすることによって、広い範囲のユーザが作成するコンテンツからアノテーションを獲得できるようになる。
論文以外の、シーンを引用して作成すべきコンテンツとして、電子新聞が考えられる。新聞は、文章と図という、静的な情報のみで構成されているため、読者が自分自身のペースで内容を理解することが可能な一方で、内容を理解し辛い場合があるという側面を持っている。そこで、電子新聞において図の代わりに映像シーンを用いることによって、閲覧者による内容の理解がより容易になると考えられる。映像と音声というリアルタイム性の高い媒体ですべてを伝えることの多いテレビのニュースなどとは異なり、テキストを主体とした上で映像を用いて理解を促すという形式となるため、自分のペースで内容を理解することができるという新聞の特徴を損なわぬまま、内容の理解を促すことができる。また、新聞に記述されているテキストは、読者に記事の内容を伝えるための文章として作成されているため、映像シーンに対するアノテーションとして十分に利用できると考えられる。また、現実にあった出来事を扱っているため、翌日の新聞などで再びその出来事に関連する新たな内容が記されることも多く、そのような場合には、単語の一致などを用いてそれらを検索するのが比較的容易であるため、複数のシーン間、複数のテキストと関連付けられたアノテーションを獲得できることも、新聞へのシーン引用の可能性の1つである。
また、掲示板やチャットといったネットワークコミュニケーションの場に映像シーンを引用するための仕組みを提供することも考えられる。そのような場で交わされるコミュニケーションを目的としたテキストは、おそらく映像シーンに対するアノテーションとしての質が高いものではないだろう。しかし、コミュニケーションから獲得されるアノテーションを直接的には利用できないとしても、作成した映像シーンがコミュニケーションの題材となる場を提供することによって、映像シーン作成に対するモチベーションを高める効果を期待することができる。コミュニケーションの場で高い評価を受けたシーンの作成者や元となった映像コンテンツの作成者に、その評価に応じて特典を与えるようなサービスを行えば、映像コンテンツやシーンの作成がより行われやすいものになり、作成されるシーンやシーン作成時のアノテーションの質も高まることが期待できる。また、シーンを引用して行われた掲示板やチャットのログを利用することによって、アノテーションとして適切な情報や検索の手掛かりを抽出できる可能性もある。
現在考えられる映像シーン引用には、映像シーンに対するアノテーションの獲得手段という側面や、シーン作成に対するモチベーションを向上させるきっかけという側面が考えられるが、今後引用できるコンテンツの種類を増やしていくことによって、また新しい側面が見えてくる可能性もある。そのため、作成したシーンをより幅広く利用できるようにする必要があると考えられる。
5 関連研究
5.1 映像シーンの検出に関する研究
ビデオスクラップブックシステムにおいては、シーン区間はユーザによって指定される。そのため、作成されたシーンは意味的なまとまりのある部分であることが予想される。また、ユーザ自身が任意のシーン区間を指定するため、柔軟なシーン区間が指定できるという利点も挙げられる。一方で、シーン区間の指定は、チェックポイントやサムネイルシークバーなどによる支援を利用しても、ユーザにとって手間のかかる行為であることは否定できない。そこで、機械処理によってシーンの転換点やシーン候補を抽出し、ユーザがそれらの情報を任意で利用できるようにすることが考えられる。この節では、そのために必要となる、シーンの抽出やインデキシングなどを行った研究事例を挙げる。
ニュース番組のインデキシングに関する研究が、以前から行われてきた。ニュース番組においては、ニュースの内容を表すテロップが映像中に出現するため、そのテロップの内容を文字認識することでニュース中の個別の記事に対してインデキシングを行う研究が茂木らによって行われた[7]。この研究においては、解析されたテロップの内容を形態素解析することによってキーワードを抽出し、キーワードを用いてニュース記事の分類も行われた。
また、近年では、小林らによってニュース番組やその他の報道番組の音声を認識し、その結果を映像・音声とともにサーバに蓄える研究も行われている[8]。この研究においては、インタビューなどの自由発話に対しては誤り率が高いとしているが、原稿の読み上げを多く含むニュース番組に関しては、高い精度の認識が可能となった。これらのデータの蓄積によって、任意のキーワードによる発話内容の検索が可能となり、対応する映像部分の検索も可能になる。
関口らは野球中継の映像を映像と音情報を用いて自動的にインデキシングする研究を行った[9]。この研究においては、まずは投球シーンの検出が行われた。その後、検出された投球シーンに対して、テロップの認識により得られた打席結果や選手名などが索引情報として自動的に付与された。これによって、特定の選手が打席に立っているシーンなどを容易に検索することが可能になった。さらに、音声を用いて盛り上がりシーンの検出が行われた。盛り上がりシーンの検出時には、アナウンサーや解説者の音声を分離して、観客の歓声を集めることによって、盛り上がりシーンの特定の質を向上させている。このように、映像コンテンツ自体に定型性を持つものに対しては、それぞれの形式に合わせた手法を用いることで、自動的な処理のみで精度の高いシーン抽出やインデキシングが可能となる。しかし、それぞれのコンテンツの種類ごとに手法を変更する必要があるため、一般のコンテンツに対して適用することは難しい。
また、映画やドラマなどのニュース映像やスポーツ映像と比較すると定型性の少ない映像コンテンツからハイライトシーンを抽出する研究も鶴田らによって行われている[10]。ここでいうハイライトシーンは、映像コンテンツの要約映像を構成するシーンを意味している。この研究においては、映像コンテンツの音響の波形解析を利用した音声特徴の抽出・FFT(高速フーリエ変換)による会話シーンの抽出・映像のフロー解析を利用した動画抽出の3つの手法によってシーン分割図が作成された。その後、それぞれの分割図を組み合わせることでハイライトシーンとして使用するシーンが決定された。この研究において作成されたシーン分割図の組み合わせによって、機械的なハイライトシーンの抽出が行われたが、シーン分割図を用いてユーザによるシーン区間指定の補助を行うことも可能だと考えられる。また、ハイライトシーンのデータを容易に利用できるようにすることで、ユーザはそのシーンを微調節して自分のシーンスクラップとして容易に登録できるようになると考えられる。
5.2 ソーシャルブックマークにおけるタグの構造化に関する研究
ビデオスクラップブックシステムにおいては、オンラインで不特定多数のユーザによってシーンが作成されることが想定されている。シーン作成のプロセスに含まれるユーザによるシーンタグの入力は、ソーシャルブックマークサービスにおけるタグの付与とよく似た側面を持っていると考えられる。そこで、本節では、ソーシャルブックマークサービスによって集められたタグをより利用しやすく整えるための研究を紹介する。
ソーシャルブックマークサービスにおいては、ユーザによって付与されたタグを一覧する方法として、頻繁にタグクラウドが用いられている。しかし、タグクラウド内におけるタグの並び順は、50音順のように意味的なつながりを持たないことが多い。そのため、タグクラウドを利用して情報を検索しようとした場合に、似たようなタグを何度も探して試すことが必要な場合がある。江田らはPLSI(Probabilistic Latent Semantic Indexing)と呼ばれる手法を用いて、タグに対して索引付けを行い、それぞれのタグの特徴ベクトルを利用して、より便利なタグの分類・表示体系を提案した[11]。この研究では、まずタグのグループ分けを行い、意味の近いタグを同じグループにまとめて表示することによって、タグクラウド全体の並びを直感的に理解することを可能にした。次に、機械処理によってタグ間に親子関係を付与することで、その親子関係を辿ることによって徐々に抽象度を下げるという、直感的な理解が容易なタグの一覧表示が可能になった。最後に、これら2つの工程を組み合わせることによって、分類基準としてふさわしくないと考えられる「あとで」などのタグを削除し、同義タグの混在を防いだ、洗練された自動カテゴリが作成された。
また、ソーシャルブックマークサービスにおいては、ユーザがタグを自由に設定できるため、同じ意味を表す言葉が別の表現で登録される、タグの表記ゆれが生じる場合がある。タグの表記ゆれはソーシャルブックマークサービスのみでなく、動画共有サイトにおいても現れており、どちらの場合においても、同じ意味を表すタグが別のタグとして扱われるため、検索の際に有益な情報が検索結果から漏れてしまう問題が発生する。安藤らはタグ同士の類似度を求めることで似た話題をもつタグを集約し、この問題を解決する研究を行った[12]。この研究では、まず、同一のタグが付与された文章群において特に共通して出現する単語が、そのタグの特徴語の候補として抽出された。次に、すべての文章において共通して出現することの多い単語が一般語として抽出され、特徴語の候補から一般語として抽出された語を取り除くことで、タグの特徴語が決定された。こうして得られたタグの特徴語に特徴ベクトルが設定され、設定された特徴ベクトルを用いてタグ間の類似度が求められた。この研究においては、実際に検索インタフェースが開発されたわけではないが、話題がある程度絞り込まれたタグに関してはタグの類似度を推定することが可能になったため、これを利用することでタグの表記ゆれ問題の解決が可能になると考えられる。
5.3 映像シーンの引用に関する研究
ビデオスクラップブックシステムにおいて作成したシーンの応用法として、本研究では論文へのシーン引用を行った。しかし、4.2節において述べたように、シーンの引用先として考えられるのは論文のみではない。本節では、シーン引用に関連する研究について述べる。
宮下らは視聴者が映像視聴を通して気付き考察した内容を複数シーンの引用とコメントの記述で表現する研究を行った[13]。この研究において、映像シーンとコメントが記述されたフィールドはトピックと呼ばれる。トピックにはその閲覧者の意見や疑問を追加することも可能であり、トピック内で議論を行うことによって、映像と議論から得られる知識を深めることができる。複数のシーンを1つのトピックに引用することができるため、引用された各シーンの比較や俯瞰を含めた議論を行うことが可能である。また、トピックの作成者は作成トピックの内容に合わせて引用シーンの再生速度の制御やスナップショットの作成が可能となっている。そのため、トピックの閲覧者は、そのトピックの作成者の意図に合った再生速度での映像の視聴が可能であり、記述された内容をより深く理解できる。この研究の主な目的は映像からの知識の発見・共有であり、アノテーション(コメント)の収集はその過程として行われている。しかし、1つのトピックに同時に引用されたシーン間の関係や複数のシーンに関わる議論を含むアノテーションは、貴重なメタデータとして映像シーンの検索などにも利用できると考えられる。
映像シーンからの知識の発見・共有を目的とした複数人による議論から得られるアノテーションは、論文テキストと比較して、幅の広い語や表現を含んでいると考えられる。ただし、論文テキストのように、文法的な正確さは保障されないため、機械的な解析のみでは有効なタグを必ずしも抽出できない。また、議論の過程で、比喩などの目的で引用シーン群とは関係しない語や表現などが表れることもあると考えられる。そのため、検索のためのアノテーションとして利用するためには、人手による修正や選別が必要になると考えられる。
6 まとめと今後の課題
6.1 まとめ
本研究では、映像コンテンツから、ユーザが後で利用するシーンを作成し、それらを効率よく検索できるように整理することができるシステムである、ビデオスクラップブックシステムを提案・開発した。
ビデオスクラップブックシステムでは、シーンの作成を容易にするために、コ ンテンツ視聴時に作成するマーキング情報(チェックポイント)をシーン区間の指定時に参考にできるようにした。また、シーン区間の調整・決定のインタフェースを工夫して、シーンの作成を容易に行えるようにした。作成したシーンの登録時には、ユーザが簡単なアノテーションを行えるようにすることで、ユーザが後にシーンを利用する際の検索が容易になるようにした。
本システムでは、作成したシーンをコンテンツごとに整理し、検索可能にする ことで、映像シーンの視聴・引用などの利用も容易にしている。検索の際にはシーン作成時にユーザによって付与されたアノテーションの他に、シーンの元になったコンテンツの情報を利用することで、目的のシーンを容易に探し出せるようにした。さらに、カテゴリや更新日時などを用いた手軽な検索機能も使用できるようにした。
また、作成したシーンを他のユーザと共有することを可能にした。他のユーザのシーンを利用可能にすることによって、ユーザは同じシーンを自分で作成する必要がなくなり、そのシーンをそのまま利用できるようになる。他のユーザが作成したシーンを視聴できるようにすることで、そのシーンに影響されて新たにシーンを作成するなどシーンを介したコミュニケーションが行われ、それによってシーン作成と共有のモチベーションが向上することも期待している。
作成したシーンの応用として、映像シーンのマルチメディア論文への引用を可能にした。論文の閲覧者は引用された映像シーンを視聴することで、論文の内容への理解を深めることができる。また、論文にコンテンツを引用することによって、引用先の論文のテキストを映像シーンアノテーションとして利用することができる。
最後に、映像シーンの作成と引用に関して被験者実験を行い、提案システムの有効性を確認した。
6.2 今後の課題
6.2.1 引用論文から得られたアノテーションの評価と利用
本研究においては、ビデオスクラップブックシステムを用いて作成した映像シーンの論文への引用を行った。しかし、論文への引用によって得られたテキストの分析や、アノテーションの利用方法を考察することができなかった。今後は論テキストを解析して、映像シーンに対するタグ付けを行うとともに、得られたタグの内容に関して、偏り具合や共起タグの数などの観点から分析を行い、論文へのシーン引用によって得られたタグの有効性を示す予定である。
6.2.2 ビデオスクラップブックシステムの改善
本研究では、3.4節で述べたように、ビデオスクラップブックのシーン作成インタフェースに関してアンケート調査による主観評価を行った。評価点については概ね高い評価を得られたが、自由記述欄にはシステムの問題点や改善案も多く指摘されていた。特に、チェックポイントの利用方法に関して、実験で得られたデータを分析し、シーンの作成をより容易にするように改善する。
シーン作成時のシーンタグの入力に関しては、入力の補助をするシステムを提供していなかったため、低い評価も見られた。また、自由記述欄にも、シーンを多く作成するようになると、負担に感じるのではないか、などの懸念が表れていた。この問題を解決するための方法としては、シーンの元となるコンテンツや複する部分のあるシーンに付与されたタグを候補として提示したり、シーンタトルやシーンコメントを形態素解析して得られた語をタグの候補とする、などの方法が考えられる。
6.2.3 シーン作成に対するモチベーションの評価
本研究では、ユーザが特定のシーンを何度も繰り返し視聴したい、という要がシーン作成のモチベーションになると考えた。そして、そのモチベーションを低下させないように、シーンの作成をより容易に行えるようにインタフェースを工夫した。また、ユーザがシーンを作成するモチベーションを向上させるための仕組みとして、シーンの共有や引用を可能にした。しかし、これらの仕組みが実際にモチベーションの維持・向上につながるかどうかは確認できていない。シーンの作成や引用は、アノテーション獲得の観点から見て重要であるため、現在のシステムがシーン作成のモチベーションを向上させることができているかを見極める必要がある。また、他にもシーン作成のモチベーションを高めることのでる仕組みがないか詳しく調査し、そのような仕組みを実現していく必要がある。
また、シーンの作成時に付与されるシーンタイトル・シーンコメント・シーンタグという直接的なシーンアノテーションに関して、質の良いアノテーションを付与することに対するモチベーションを高める方法も考える予定である。例えば、付与されたアノテーションを、他のユーザが気軽に評価できる仕組みを提供し、高い評価を得たアノテーションの作成者に得点を与えるなどの方法を考えている。
6.2.4 高度な検索システムの実現
ビデオスクラップブックのシステムにおいては、検索の対象となるシーンは自分が作成したシーンと、共有されている、他のユーザが作成したシーンに限らる。しかし、シーンが積極的に作成され、共有されるようになると、単純な検索のみでは有効な検索ができなくなることが容易に予想される。そのため、タグを1つ選択するごとに、関連する可能性が高いタグを提示するような高度な検索システムを実現する必要がある。提示する関連タグとしては、1つのシーンに同時に付与されたタグや、シーンの元のコンテンツのタグ、引用先の論文テキスト内共起したタグなどが考えられる。そのような検索システムを実装することによって、シーンの数が増大しても目的に応じたシーンを容易に検索できるようになりシーン引用システムをより利用されやすいものに改善できると考えられる。
謝辞
本研究を進めるにあたって、指導教員である長尾確教授には、研究の心構えといった基礎的なことや、研究のテーマ設定から論文の執筆まで、多くのご指導・ご意見を頂き、大変お世話になりました。心よりお礼申し上げます。
松原茂樹准教授には、ゼミを通して、研究の考え方や研究に必要なことを数多く教わりました。心よりお礼申し上げます。
大平茂輝助教には、プロジェクトミーティングを中心に、研究活動に関して数多くのご指導・ご指摘を頂くとともに、論文の執筆などにおいても多くのご支援を頂きました。心よりお礼申し上げます。
石戸谷顕太朗さんには、研究や実装のことに関して、的確なアドバイスやご指導を頂きました。ありがとうございました。
コンテンツアノテーション班のメンバーである、竹島亮さん、棚瀬達央さんには、プログラミングやスライド作成、研究に関する相談など、非常に多くの面でご支援頂きました。ありがとうございました。
渡邉賢さん、尾崎宏樹さん、川西康介さん、矢田幸大さんには、ゼミを通して貴重なご意見を頂くとともに、忙しい中実験にも積極的に協力して頂きました。ありがとうございました。
馮思萌さん、井上慧さん、小林尚哉さん、久保田芙衣さん、高雨蘇さんには、実験に協力して頂くとともに、研究室での生活において様々な面でお世話になりました。ありがとうございました。
長尾研究室秘書の鈴木美苗さん、土井ひとみさんには、研究室での生活において様々な面でご支援をして頂き、大変お世話になりました。ありがとうございました。
最後に、毎日の生活を支えて頂いた家族に、心より感謝いたします。ありがとうございました。
7 謝辞
本研究を進めるにあたって、指導教員である長尾確教授には、研究の心構えといった基礎的なことや、研究のテーマ設定から論文の執筆まで、多くのご指導・ご意見を頂き、大変お世話になりました。心よりお礼申し上げます。
松原茂樹准教授には、ゼミを通して、研究の考え方や研究に必要なことを数多く教わりました。心よりお礼申し上げます。
大平茂輝助教には、プロジェクトミーティングを中心に、研究活動に関して数多くのご指導・ご指摘を頂くとともに、論文の執筆などにおいても多くのご支援を頂きました。心よりお礼申し上げます。
石戸谷顕太朗さんには、研究や実装のことに関して、的確なアドバイスやご指導を頂きました。ありがとうございました。
コンテンツアノテーション班のメンバーである、竹島亮さん、棚瀬達央さんには、プログラミングやスライド作成、研究に関する相談など、非常に多くの面でご支援頂きました。ありがとうございました。
渡邉賢さん、尾崎宏樹さん、川西康介さん、矢田幸大さんには、ゼミを通して貴重なご意見を頂くとともに、忙しい中実験にも積極的に協力して頂きました。ありがとうございました。
馮思萌さん、井上慧さん、小林尚哉さん、久保田芙衣さん、高雨蘇さんには、実験に協力して頂くとともに、研究室での生活において様々な面でお世話になりました。ありがとうございました。
長尾研究室秘書の鈴木美苗さん、土井ひとみさんには、研究室での生活において様々な面でご支援をして頂き、大変お世話になりました。ありがとうございました。
最後に、毎日の生活を支えて頂いた家族に、心より感謝いたします。ありがとうございました。